lion pytorch
0.2.3
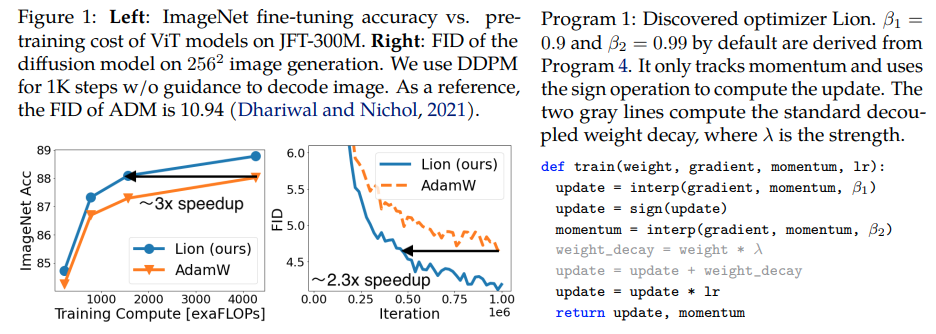
Lion、Evo L ved S i gn M omentum 、Google Brain によって発見された、Pytorch の Adam(w) よりも優れているとされる新しいオプティマイザー。これは、ここからのほぼそのままのコピーですが、いくつかの小さな変更が加えられています。
これは非常にシンプルなので、本当に機能するのであれば、すぐに誰もがアクセスして、いくつかの優れたモデルをトレーニングするために使用できるようにしてもよいでしょうか?
学習率と重みの減衰: 著者らはセクション 5 で書いています。 Based on our experience, a suitable learning rate for Lion is typically 3-10x smaller than that for AdamW. Since the effective weight decay is lr * λ, the value of decoupled weight decay λ used for Lion is 3-10x larger than that for AdamW in order to maintain a similar strength.学習率スケジュールの初期値、ピーク値、および終了値は、AdamW と比較して同じ比率で同時に変更される必要があることが研究者によって証明されています。
学習率スケジュール: 著者は、論文の中で AdamW と同じ学習率スケジュールを Lion に対して使用します。それにもかかわらず、コサイン減衰スケジュールを使用して ViT をトレーニングすると、逆数平方根スケジュールと比較して、より大きなゲインが観察されます。
β1 と β2: 著者はセクション 5 で書いています - The default values for β1 and β2 in AdamW are set as 0.9 and 0.999, respectively, with an ε of 1e−8, while in Lion, the default values for β1 and β2 are discovered through the program search process and set as 0.9 and 0.99, respectively.安定性を向上させるために AdamW で β2 を 0.99 以下に減らし、ε を 1e-6 に増やす方法と同様に、Lion でβ1=0.95, β2=0.98使用することもトレーニング中の不安定性を軽減するのに役立つ可能性があると著者らは示唆しています。これは研究者によって裏付けられました。
更新: 私のローカル enwik8 自己回帰言語モデリングでは機能するようです。
アップデート 2: 実験は、学習率が一定に保たれた場合、アダムよりもはるかに悪いようです。
アップデート 3: 学習率を 3 で割ると、初期の結果は Adam よりも優れています。おそらくアダムは10年近く経って王位を追われたのかもしれない。
アップデート 4: 論文にある 10 倍小さい学習率の経験則を使用すると、実行結果が最悪になりました。なので、まだ少し調整が必要だと思います。
以前の更新の要約: 実験で示されているように、学習率が 3 分の 1 である Lion が Adam を上回っています。学習率が 10 分の 1 より小さいと結果が悪くなるため、まだ少し調整が必要です。
アップデート 5: これまでのところ、言語モデリングが正しく行われた場合、すべての肯定的な結果が得られています。また、多少の調整が必要ですが、重要なテキストから画像へのトレーニングでも肯定的な結果が得られたと聞きました。否定的な結果は、RL、フィードフォワード ネットワーク、LSTM + 畳み込みなどを使用した奇妙なハイブリッド アーキテクチャなど、論文で評価されたもの以外の問題やアーキテクチャに関係しているようです。否定的な事例データは、この手法がバッチ サイズ、データ量 / 拡張の影響を受けやすいことも裏付けています。 。最適な学習率スケジュールがどのようなものであるか、またクールダウンが結果に影響を与えるかどうかは未定です。また、興味深いことに、オープンクリップではプラスの結果が得られますが、モデル サイズが拡大されるとマイナスになりました (ただし、解決できる可能性があります)。
アップデート 6: オープン クリップの問題は、初期温度を高く設定することで作者によって解決されました。
アップデート 7: このオプティマイザーは、高いバッチ サイズ (64 以上) の設定でのみ推奨されます。
$ pip インストール lion-pytorch
あるいは、conda を使用します。
$ conda インストール lion-pytorch
# おもちゃのモデルimport torchfrom torch import nnmodel = nn.Linear(10, 1)# Lion をインポートし、lion_pytorch からパラメータを使用してインスタンス化します import Lionopt = Lion(model.parameters(), lr=1e-4,weight_decay=1e-2)# forward and backwardsloss = model(torch.randn(10))loss.backward()# オプティマイザーstepopt.step()opt.zero_grad()
パラメータの更新に融合カーネルを使用するには、まずpip install triton -U --pre 、次に
opt = Lion(model.parameters(),lr=1e-4,weight_decay=1e-2,use_triton=True # Triton lang (Tillet et al) で cuda カーネルを使用するには、これを True に設定します)
Stability.ai は、最先端の人工知能研究をオープンソースで行うための寛大なスポンサーシップを提供しています
@misc{https://doi.org/10.48550/arxiv.2302.06675,url = {https://arxiv.org/abs/2302.06675},author = {Chen、Xiangning、Liang、Chen、Huang、Da、Real、エステバンとワン、カイユアンとリウ、ヤオとファム、ヒエウとドン、スアンイーとLuong、Thang および Hsieh、Cho-Jui および Lu、Yifeng および Le、Quoc V.}、title = {最適化アルゴリズムの象徴的な発見}、出版社 = {arXiv}、年 = {2023}} @article{Tillet2019TritonAI,title = {Triton: タイル型ニューラル ネットワーク計算用の中間言語およびコンパイラ},author = {Philippe Tillet、H. Kung、D. Cox}、journal = {第 3 回 ACM SIGPLAN International Workshop on Machine の議事録言語の学習とプログラミング}、年 = {2019}} @misc{Schaipp2024、著者 = {Fabian Schaipp}、url = {https://fabian-sp.github.io/posts/2024/02/decoupling/}} @inproceedings{Liang2024CautiousOI、title = {慎重なオプティマイザー: 1 行のコードでトレーニングを改善}、著者 = {Kaizhao Liang、Lizhang Chen、Bo Liu、Qiang Liu}、year = {2024}、url = {https://api .semanticscholar.org/CorpusID:274234738}} 

