meshgpt pytorch
1.8.1
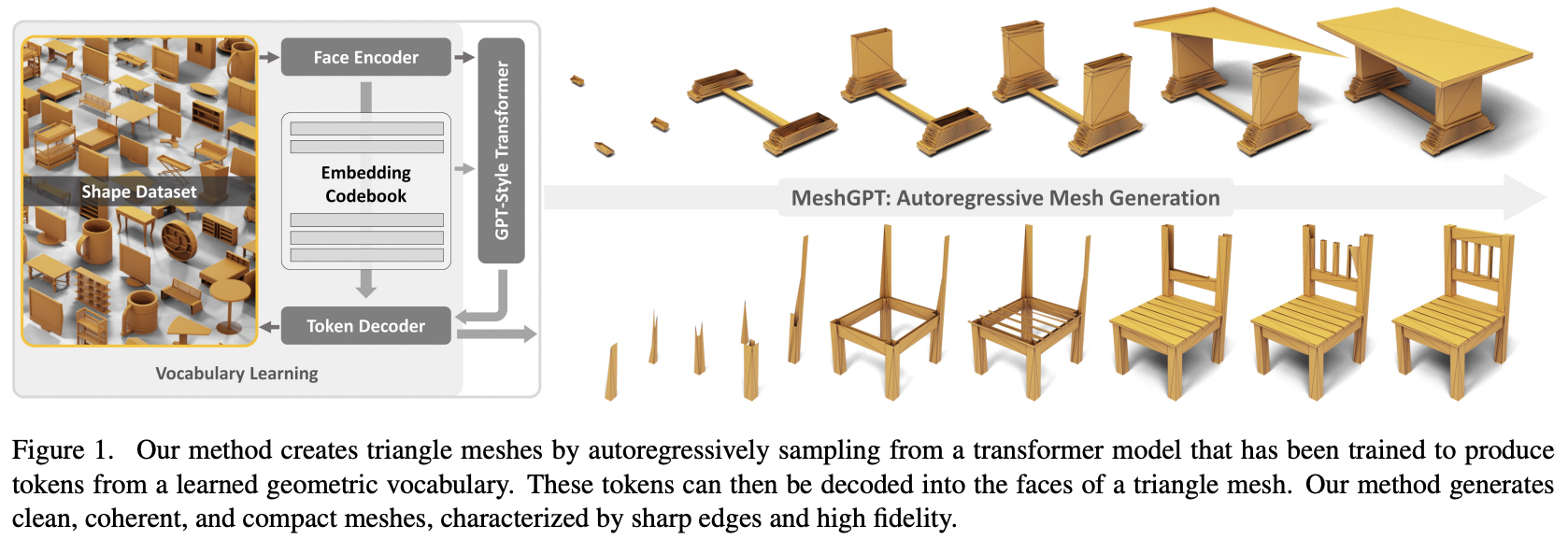
Pytorchでのアテンションを使用したSOTAメッシュ生成、MeshGPTの実装
最終的にテキストを 3D アセットに変換するためのテキストコンディショニングも追加します
他の人と協力してこの作品を再現することに興味がある場合は、ぜひご参加ください。
更新: Marcus は作業モデルをトレーニングし、? にアップロードしました。ハグフェイス!
StabilityAI、A16Z オープンソース AI 助成プログラム、そして ?現在の人工知能研究をオープンソース化する独立性を私に与えてくれた寛大なスポンサーと他のスポンサーに感謝します。
私の生活を楽にしてくれたEinops
Marcus が最初のコード レビュー (不足している派生機能のいくつかを指摘) と、最初に成功したエンドツーエンドの実験を実行してくれました。
ラベルに条件付けされた形状のコレクションのトレーニングに初めて成功した Marcus
自動 EOS 処理で多数のバグを検出する Quexi Ma
空間ラベル平滑化のための位置のガウスぼかしに関するバグを発見してくれた Yingtian
Marcus は、システムを三角形から四角形に拡張できることを検証する実験を実行してくれました。
Marcus はテキストのコンディショニングに関する問題を特定し、その問題の解決につながるすべての実験を実行してくれました。
$ pip install meshgpt-pytorch import torch
from meshgpt_pytorch import (
MeshAutoencoder ,
MeshTransformer
)
# autoencoder
autoencoder = MeshAutoencoder (
num_discrete_coors = 128
)
# mock inputs
vertices = torch . randn (( 2 , 121 , 3 )) # (batch, num vertices, coor (3))
faces = torch . randint ( 0 , 121 , ( 2 , 64 , 3 )) # (batch, num faces, vertices (3))
# make sure faces are padded with `-1` for variable lengthed meshes
# forward in the faces
loss = autoencoder (
vertices = vertices ,
faces = faces
)
loss . backward ()
# after much training...
# you can pass in the raw face data above to train a transformer to model this sequence of face vertices
transformer = MeshTransformer (
autoencoder ,
dim = 512 ,
max_seq_len = 768
)
loss = transformer (
vertices = vertices ,
faces = faces
)
loss . backward ()
# after much training of transformer, you can now sample novel 3d assets
faces_coordinates , face_mask = transformer . generate ()
# (batch, num faces, vertices (3), coordinates (3)), (batch, num faces)
# now post process for the generated 3d assetテキスト条件付き 3D 形状合成の場合は、 MeshTransformerでcondition_on_text = Trueを設定し、 textsキーワード引数として説明のリストを渡します。
元。
transformer = MeshTransformer (
autoencoder ,
dim = 512 ,
max_seq_len = 768 ,
condition_on_text = True
)
loss = transformer (
vertices = vertices ,
faces = faces ,
texts = [ 'a high chair' , 'a small teapot' ],
)
loss . backward ()
# after much training of transformer, you can now sample novel 3d assets conditioned on text
faces_coordinates , face_mask = transformer . generate (
texts = [ 'a long table' ],
cond_scale = 8. , # a cond_scale > 1. will enable classifier free guidance - can be placed anywhere from 3. - 10.
remove_parallel_component = True # from https://arxiv.org/abs/2410.02416
)マルチモーダル トランスフォーマーで使用するためにメッシュをトークン化したい場合は、オートエンコーダーで.tokenize呼び出すだけです (または、指数関数的に平滑化されたモデルのオートエンコーダー トレーナー インスタンスで同じメソッド)。
mesh_token_ids = autoencoder . tokenize (
vertices = vertices ,
faces = faces
)
# (batch, num face vertices, residual quantized layer) プロジェクトのルートで次を実行します。
$ cp .env.sample .envオートエンコーダ
face_edges面と頂点から直接自動導出する方法を理解するトランス
H Accelerate を備えたトレーナー ラッパー
独自の CFG ライブラリを使用したテキスト コンディショニング
階層型トランスフォーマー (RQ トランスフォーマーを使用)
他のリポジトリのシンプルなゲートループ層のキャッシュを修正
地元の注目
2 段階の階層トランスフォーマーの kv キャッシュを修正 - 7 倍高速になり、元の非階層トランスフォーマーよりも高速になりました
ゲートループ層のキャッシュを修正
細かいアテンション ネットワークと粗いアテンション ネットワークのモデル次元のカスタマイズが可能
オートエンコーダーが本当に必要かどうかを判断する - それは必要です、アブレーションは論文にあります
変圧器を効率的にする
投機的デコードオプション
文書作成に 1 日を費やす
@inproceedings { Siddiqui2023MeshGPTGT ,
title = { MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers } ,
author = { Yawar Siddiqui and Antonio Alliegro and Alexey Artemov and Tatiana Tommasi and Daniele Sirigatti and Vladislav Rosov and Angela Dai and Matthias Nie{ss}ner } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265457242 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Leviathan2022FastIF ,
title = { Fast Inference from Transformers via Speculative Decoding } ,
author = { Yaniv Leviathan and Matan Kalman and Y. Matias } ,
booktitle = { International Conference on Machine Learning } ,
year = { 2022 } ,
url = { https://api.semanticscholar.org/CorpusID:254096365 }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Lee2022AutoregressiveIG ,
title = { Autoregressive Image Generation using Residual Quantization } ,
author = { Doyup Lee and Chiheon Kim and Saehoon Kim and Minsu Cho and Wook-Shin Han } ,
journal = { 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 11513-11522 } ,
url = { https://api.semanticscholar.org/CorpusID:247244535 }
} @inproceedings { Katsch2023GateLoopFD ,
title = { GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling } ,
author = { Tobias Katsch } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265018962 }
}

