se3 transformer pytorch
0.9.0
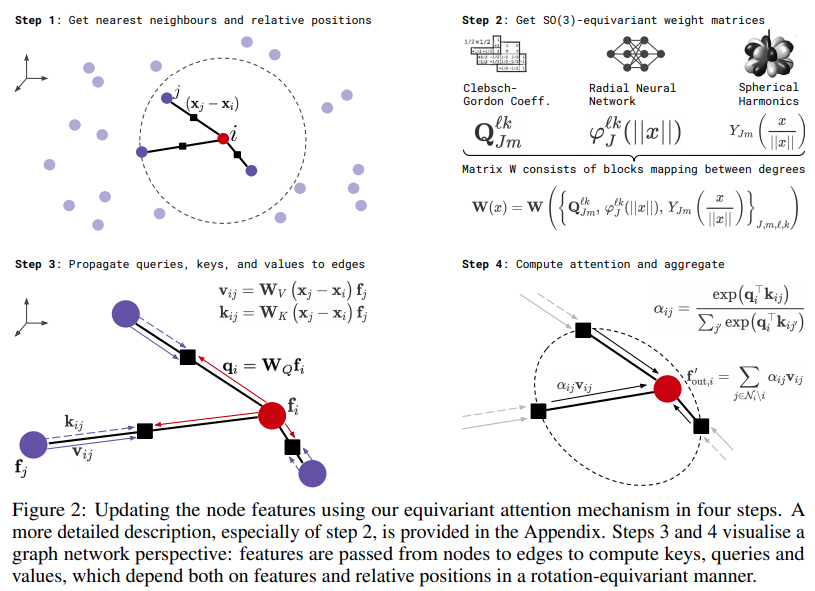
Pytorch での等変セルフアテンションのための SE3-Transformers の実装。 Alphafold2 の結果や他の創薬アプリケーションを再現するために必要になる場合があります。
等分散性の例
バージョン 0.6.0 より前の SE3 Transformers のバージョンを使用していた場合は、更新してください。隣接スパースネイバー設定を使用せず、最近傍機能に依存していた場合、巨大なバグが @MattMcPartlon によって発見されました。
更新: 代わりに Equiformer を使用することをお勧めします
$ pip install se3-transformer-pytorch import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 512 ,
heads = 8 ,
depth = 6 ,
dim_head = 64 ,
num_degrees = 4 ,
valid_radius = 10
)
feats = torch . randn ( 1 , 1024 , 512 )
coors = torch . randn ( 1 , 1024 , 3 )
mask = torch . ones ( 1 , 1024 ). bool ()
out = model ( feats , coors , mask ) # (1, 1024, 512)Alphafold2 での使用例(ここで概説)
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 2 ,
input_degrees = 1 ,
num_degrees = 2 ,
output_degrees = 2 ,
reduce_dim_out = True ,
differentiable_coors = True
)
atom_feats = torch . randn ( 2 , 32 , 64 )
coors = torch . randn ( 2 , 32 , 3 )
mask = torch . ones ( 2 , 32 ). bool ()
refined_coors = coors + model ( atom_feats , coors , mask , return_type = 1 ) # (2, 32, 3)また、基本トランスフォーマー クラスに、渡されるタイプ 0 の機能の埋め込みを処理させることもできます。それらがアトムであると仮定します。
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
num_tokens = 28 , # 28 unique atoms
dim = 64 ,
depth = 2 ,
input_degrees = 1 ,
num_degrees = 2 ,
output_degrees = 2 ,
reduce_dim_out = True
)
atoms = torch . randint ( 0 , 28 , ( 2 , 32 ))
coors = torch . randn ( 2 , 32 , 3 )
mask = torch . ones ( 2 , 32 ). bool ()
refined_coors = coors + model ( atoms , coors , mask , return_type = 1 ) # (2, 32, 3)ネットが位置エンコーディングからさらに恩恵を受けると思われる場合は、次のように空間内の位置を特徴付けて渡すことができます。
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 2 ,
input_degrees = 2 ,
num_degrees = 2 ,
output_degrees = 2 ,
reduce_dim_out = True # reduce out the final dimension
)
atom_feats = torch . randn ( 2 , 32 , 64 , 1 ) # b x n x d x type0
coors_feats = torch . randn ( 2 , 32 , 64 , 3 ) # b x n x d x type1
# atom features are type 0, predicted coordinates are type 1
features = { '0' : atom_feats , '1' : coors_feats }
coors = torch . randn ( 2 , 32 , 3 )
mask = torch . ones ( 2 , 32 ). bool ()
refined_coors = coors + model ( features , coors , mask , return_type = 1 ) # (2, 32, 3) - equivariant to input type 1 features and coordinates SE3 Transformer にエッジ情報 (原子間の結合タイプなど) を提供するには、初期化時にさらに 2 つのキーワード引数を渡すだけです。
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
num_tokens = 28 ,
dim = 64 ,
num_edge_tokens = 4 , # number of edge type, say 4 bond types
edge_dim = 16 , # dimension of edge embedding
depth = 2 ,
input_degrees = 1 ,
num_degrees = 3 ,
output_degrees = 1 ,
reduce_dim_out = True
)
atoms = torch . randint ( 0 , 28 , ( 2 , 32 ))
bonds = torch . randint ( 0 , 4 , ( 2 , 32 , 32 ))
coors = torch . randn ( 2 , 32 , 3 )
mask = torch . ones ( 2 , 32 ). bool ()
pred = model ( atoms , coors , mask , edges = bonds , return_type = 0 ) # (2, 32, 1)エッジの連続値を渡したい場合は、 num_edge_tokens設定しないことを選択し、離散結合タイプをエンコードして、それをこれらの連続値のフーリエ特徴に連結することができます。
import torch
from se3_transformer_pytorch import SE3Transformer
from se3_transformer_pytorch . utils import fourier_encode
model = SE3Transformer (
dim = 64 ,
depth = 1 ,
attend_self = True ,
num_degrees = 2 ,
output_degrees = 2 ,
edge_dim = 34 # edge dimension must match the final dimension of the edges being passed in
)
feats = torch . randn ( 1 , 32 , 64 )
coors = torch . randn ( 1 , 32 , 3 )
mask = torch . ones ( 1 , 32 ). bool ()
pairwise_continuous_values = torch . randint ( 0 , 4 , ( 1 , 32 , 32 , 2 )) # say there are 2
edges = fourier_encode (
pairwise_continuous_values ,
num_encodings = 8 ,
include_self = True
) # (1, 32, 32, 34) - {2 * (2 * 8 + 1)}
out = model ( feats , coors , mask , edges = edges , return_type = 1 )ポイントの接続性がわかっている場合 (分子を操作している場合など)、隣接行列をブール マスクの形式で渡すことができます ( True接続性を示します)。
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 32 ,
heads = 8 ,
depth = 1 ,
dim_head = 64 ,
num_degrees = 2 ,
valid_radius = 10 ,
attend_sparse_neighbors = True , # this must be set to true, in which case it will assert that you pass in the adjacency matrix
num_neighbors = 0 , # if you set this to 0, it will only consider the connected neighbors as defined by the adjacency matrix. but if you set a value greater than 0, it will continue to fetch the closest points up to this many, excluding the ones already specified by the adjacency matrix
max_sparse_neighbors = 8 # you can cap the number of neighbors, sampled from within your sparse set of neighbors as defined by the adjacency matrix, if specified
)
feats = torch . randn ( 1 , 128 , 32 )
coors = torch . randn ( 1 , 128 , 3 )
mask = torch . ones ( 1 , 128 ). bool ()
# placeholder adjacency matrix
# naively assuming the sequence is one long chain (128, 128)
i = torch . arange ( 128 )
adj_mat = ( i [:, None ] <= ( i [ None , :] + 1 )) & ( i [:, None ] >= ( i [ None , :] - 1 ))
out = model ( feats , coors , mask , adj_mat = adj_mat ) # (1, 128, 512)追加のキーワードnum_adj_degreesを 1 つ使用して、ネットワークに N 次近傍を自動的に導出させることもできます。システムにエッジ情報として近傍の次数を区別させたい場合は、さらにゼロ以外のadj_dimを渡します。
import torch
from se3_transformer_pytorch . se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 1 ,
attend_self = True ,
num_degrees = 2 ,
output_degrees = 2 ,
num_neighbors = 0 ,
attend_sparse_neighbors = True ,
num_adj_degrees = 2 , # automatically derive 2nd degree neighbors
adj_dim = 4 # embed 1st and 2nd degree neighbors (as well as null neighbors) with edge embeddings of this dimension
)
feats = torch . randn ( 1 , 32 , 64 )
coors = torch . randn ( 1 , 32 , 3 )
mask = torch . ones ( 1 , 32 ). bool ()
# placeholder adjacency matrix
# naively assuming the sequence is one long chain (128, 128)
i = torch . arange ( 128 )
adj_mat = ( i [:, None ] <= ( i [ None , :] + 1 )) & ( i [:, None ] >= ( i [ None , :] - 1 ))
out = model ( feats , coors , mask , adj_mat = adj_mat , return_type = 1 )各タイプのディメンション性を細かく制御するには、 hidden_fiber_dictキーワードとout_fiber_dictキーワードを使用して、キー/値としてディメンション値の次数をディクショナリに渡すことができます。
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
num_tokens = 28 ,
dim = 64 ,
num_edge_tokens = 4 ,
edge_dim = 16 ,
depth = 2 ,
input_degrees = 1 ,
num_degrees = 3 ,
output_degrees = 1 ,
hidden_fiber_dict = { 0 : 16 , 1 : 8 , 2 : 4 },
out_fiber_dict = { 0 : 16 , 1 : 1 },
reduce_dim_out = False
)
atoms = torch . randint ( 0 , 28 , ( 2 , 32 ))
bonds = torch . randint ( 0 , 4 , ( 2 , 32 , 32 ))
coors = torch . randn ( 2 , 32 , 3 )
mask = torch . ones ( 2 , 32 ). bool ()
pred = model ( atoms , coors , mask , edges = bonds )
pred [ '0' ] # (2, 32, 16)
pred [ '1' ] # (2, 32, 1, 3) 近隣マスクを渡すことで、どのノードを考慮できるかをさらに制御できます。すべてのFalse値は考慮されずにマスクされます。
import torch
from se3_transformer_pytorch . se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 16 ,
dim_head = 16 ,
attend_self = True ,
num_degrees = 4 ,
output_degrees = 2 ,
num_edge_tokens = 4 ,
num_neighbors = 8 , # make sure you set this value as the maximum number of neighbors set by your neighbor_mask, or it will throw a warning
edge_dim = 2 ,
depth = 3
)
feats = torch . randn ( 1 , 32 , 16 )
coors = torch . randn ( 1 , 32 , 3 )
mask = torch . ones ( 1 , 32 ). bool ()
bonds = torch . randint ( 0 , 4 , ( 1 , 32 , 32 ))
neighbor_mask = torch . ones ( 1 , 32 , 32 ). bool () # set the nodes you wish to be masked out as False
out = model (
feats ,
coors ,
mask ,
edges = bonds ,
neighbor_mask = neighbor_mask ,
return_type = 1
)この機能を使用すると、他のすべてのノードから認識されるグローバル ノードとして表示できるベクトルを渡すことができます。このアイデアは、グラフをいくつかの特徴ベクトルにプールし、ネットワーク内のすべてのアテンション レイヤー全体のキー/値に投影することです。すべてのノードは、最近傍ノードや隣接関係の計算に関係なく、グローバル ノード情報に完全にアクセスできます。
import torch
from torch import nn
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 1 ,
num_degrees = 2 ,
num_neighbors = 4 ,
valid_radius = 10 ,
global_feats_dim = 32 # this must be set to the dimension of the global features, in this example, 32
)
feats = torch . randn ( 1 , 32 , 64 )
coors = torch . randn ( 1 , 32 , 3 )
mask = torch . ones ( 1 , 32 ). bool ()
# naively derive global features
# by pooling features and projecting
global_feats = nn . Linear ( 64 , 32 )( feats . mean ( dim = 1 , keepdim = True )) # (1, 1, 32)
out = model ( feats , coors , mask , return_type = 0 , global_feats = global_feats )トド:
フラグを 1 つ追加するだけで SE3 Transformers を自動回帰的に使用できます
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 512 ,
heads = 8 ,
depth = 6 ,
dim_head = 64 ,
num_degrees = 4 ,
valid_radius = 10 ,
causal = True # set this to True
)
feats = torch . randn ( 1 , 1024 , 512 )
coors = torch . randn ( 1 , 1024 , 3 )
mask = torch . ones ( 1 , 1024 ). bool ()
out = model ( feats , coors , mask ) # (1, 1024, 512) おもちゃのノイズ除去タスクでは、(ペアごとの畳み込みではなく) 線形に投影されたキーを使用すると問題ないようであることがわかりました。これにより、メモリが 25% 節約されます。この機能を試すには、 linear_proj_keys = Trueを設定します。
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 1 ,
num_degrees = 4 ,
num_neighbors = 8 ,
valid_radius = 10 ,
splits = 4 ,
linear_proj_keys = True # set this to True
). cuda ()
feats = torch . randn ( 1 , 32 , 64 ). cuda ()
coors = torch . randn ( 1 , 32 , 3 ). cuda ()
mask = torch . ones ( 1 , 32 ). bool (). cuda ()
out = model ( feats , coors , mask , return_type = 0 )トランスフォーマーには、クエリのすべてのヘッドで 1 つのキー/値のヘッドを共有できる、比較的知られていない手法があります。 NLP での私の経験では、これは通常パフォーマンスの低下につながりますが、より深い深さまたはより高い次数を求めてメモリをトレードオフする必要がある場合には、これが良い選択肢になる可能性があります。
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 8 ,
num_degrees = 4 ,
num_neighbors = 8 ,
valid_radius = 10 ,
splits = 4 ,
one_headed_key_values = True # one head of key / values shared across all heads of the queries
). cuda ()
feats = torch . randn ( 1 , 32 , 64 ). cuda ()
coors = torch . randn ( 1 , 32 , 3 ). cuda ()
mask = torch . ones ( 1 , 32 ). bool (). cuda ()
out = model ( feats , coors , mask , return_type = 0 )キーと値を結び付ける (同じにする) こともでき、メモリを半分に節約できます。
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 8 ,
num_degrees = 4 ,
num_neighbors = 8 ,
valid_radius = 10 ,
splits = 4 ,
tie_key_values = True # set this to True
). cuda ()
feats = torch . randn ( 1 , 32 , 64 ). cuda ()
coors = torch . randn ( 1 , 32 , 3 ). cuda ()
mask = torch . ones ( 1 , 32 ). bool (). cuda ()
out = model ( feats , coors , mask , return_type = 0 )これは EGNN の実験版であり、(座標の) 1 つよりも高い型とより大きな次元で機能します。既存のロジックを再利用するため、クラス名はSE3Transformerままです。後でクリーンアップするまで、今は無視してください。
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 32 ,
num_neighbors = 8 ,
num_edge_tokens = 4 ,
edge_dim = 4 ,
num_degrees = 4 , # number of higher order types - will use basis on a TCN to project to these dimensions
use_egnn = True , # set this to true to use EGNN instead of equivariant attention layers
egnn_hidden_dim = 64 , # egnn hidden dimension
depth = 4 , # depth of EGNN
reduce_dim_out = True # will project the dimension of the higher types to 1
). cuda ()
feats = torch . randn ( 2 , 32 , 32 ). cuda ()
coors = torch . randn ( 2 , 32 , 3 ). cuda ()
bonds = torch . randint ( 0 , 4 , ( 2 , 32 , 32 )). cuda ()
mask = torch . ones ( 2 , 32 ). bool (). cuda ()
refinement = model ( feats , coors , mask , edges = bonds , return_type = 1 ) # (2, 32, 3)
coors = coors + refinement # update coors with refinement上位の型ごとに個別の次元を指定したい場合は、辞書がnum_degreesの代わりに {<degree>:<dim>} の形式になっているhidden_fiber_dictを渡すだけです。
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 32 ,
num_neighbors = 8 ,
hidden_fiber_dict = { 0 : 32 , 1 : 16 , 2 : 8 , 3 : 4 },
use_egnn = True ,
depth = 4 ,
egnn_hidden_dim = 64 ,
egnn_weights_clamp_value = 2 ,
reduce_dim_out = True
). cuda ()
feats = torch . randn ( 2 , 32 , 32 ). cuda ()
coors = torch . randn ( 2 , 32 , 3 ). cuda ()
mask = torch . ones ( 2 , 32 ). bool (). cuda ()
refinement = model ( feats , coors , mask , return_type = 1 ) # (2, 32, 3)
coors = coors + refinement # update coors with refinement このセクションでは、SE3 Transformer のスケールをもう少し改善するための継続的な取り組みをリストします。
まず、可逆ネットワークを追加しました。これにより、通常のメモリの障害に遭遇する前に、もう少し深みを加えることができます。等分散性の保存はテストで実証されます。
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
num_tokens = 20 ,
dim = 32 ,
dim_head = 32 ,
heads = 4 ,
depth = 12 , # 12 layers
input_degrees = 1 ,
num_degrees = 3 ,
output_degrees = 1 ,
reduce_dim_out = True ,
reversible = True # set reversible to True
). cuda ()
atoms = torch . randint ( 0 , 4 , ( 2 , 32 )). cuda ()
coors = torch . randn ( 2 , 32 , 3 ). cuda ()
mask = torch . ones ( 2 , 32 ). bool (). cuda ()
pred = model ( atoms , coors , mask = mask , return_type = 0 )
loss = pred . sum ()
loss . backward ()まずsidechainnetをインストールします
$ pip install sidechainnet次に、タンパク質バックボーンのノイズ除去タスクを実行します。
$ python denoise.pyデフォルトでは、基底ベクトルはキャッシュされます。ただし、キャッシュをクリアする必要がある場合は、スクリプトの開始時に環境フラグCLEAR_CACHE何らかの値に設定するだけで済みます。
$ CLEAR_CACHE=1 python train.pyまたは、次の場所に存在するはずのキャッシュ ディレクトリを削除してみることもできます。
$ rm -rf ~ /.cache.equivariant_attentionデフォルトのディレクトリに権限の問題がある可能性がある場合に備えて、キャッシュを保存する独自のディレクトリを指定することもできます。
CACHE_PATH=./path/to/my/cache python train.py$ python setup.py pytestこのライブラリは主に Fabian の公式リポジトリの移植ですが、DGL ライブラリは含まれていません。
@misc { fuchs2020se3transformers ,
title = { SE(3)-Transformers: 3D Roto-Translation Equivariant Attention Networks } ,
author = { Fabian B. Fuchs and Daniel E. Worrall and Volker Fischer and Max Welling } ,
year = { 2020 } ,
eprint = { 2006.10503 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { satorras2021en ,
title = { E(n) Equivariant Graph Neural Networks } ,
author = { Victor Garcia Satorras and Emiel Hoogeboom and Max Welling } ,
year = { 2021 } ,
eprint = { 2102.09844 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { gomez2017reversible ,
title = { The Reversible Residual Network: Backpropagation Without Storing Activations } ,
author = { Aidan N. Gomez and Mengye Ren and Raquel Urtasun and Roger B. Grosse } ,
year = { 2017 } ,
eprint = { 1707.04585 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { shazeer2019fast ,
title = { Fast Transformer Decoding: One Write-Head is All You Need } ,
author = { Noam Shazeer } ,
year = { 2019 } ,
eprint = { 1911.02150 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.NE }
}

