algebraic nnhw
1.0.0
このリポジトリには、同じ出力を生成しながら、ほぼ半分の乗算を安価な低ビット幅の加算と交換する代替内積アルゴリズムを実行することにより、同じパフォーマンスを達成するためにほぼ半分の数の乗算器ユニットを必要とする ML ハードウェア アーキテクチャのソース コードが含まれています。従来の内積と同様です。これにより、ML アクセラレータの理論上のスループットと計算効率の限界が向上します。詳細については、次の雑誌出版物を参照してください。
TE Pogue と N. Nicolici、「ディープ ニューラル ネットワーク アクセラレータのための高速内積アルゴリズムとアーキテクチャ」、IEEE Transactions on Computers、vol. 73、いいえ。 2、495-509 ページ、2024 年 2 月、土井: 10.1109/TC.2023.3334140。
記事URL:https://ieeexplore.ieee.org/document/10323219
オープンアクセス版: https://arxiv.org/abs/2311.12224
要約: 1968 年に Winograd によって提案された、まだ研究されていない高速内積アルゴリズム (FIP) を改善する、Free-pipeline Fast Inner Product (FFIP) と呼ばれる新しいアルゴリズムとそのハードウェア アーキテクチャを紹介します。畳み込み層と同様に、FIP は、主に行列乗算に分解できるすべての機械学習 (ML) モデル層に適用できます。これには、全結合、畳み込み、リカレント、およびアテンション/トランスレイヤー。 ML アクセラレータに初めて FIP を実装し、FIP のクロック周波数を本質的に向上させ、その結果、同様のハードウェア コストでスループットを向上させる FFIP アルゴリズムと一般化されたアーキテクチャを紹介します。最後に、FIP および FFIP のアルゴリズムとアーキテクチャに対する ML 固有の最適化に貢献します。 FFIP を従来の固定小数点シストリック アレイ ML アクセラレータにシームレスに組み込んで、積和演算 (MAC) ユニットの半分の数で同じスループットを達成できること、またはデバイスに適合できる最大シストリック アレイ サイズを 2 倍にできることを示します。固定のハードウェア予算。 8 ~ 16 ビットの固定小数点入力を備えた非スパース ML モデル用の FFIP 実装は、同じタイプの計算プラットフォーム上のクラス最高の従来のソリューションよりも高いスループットと計算効率を実現します。
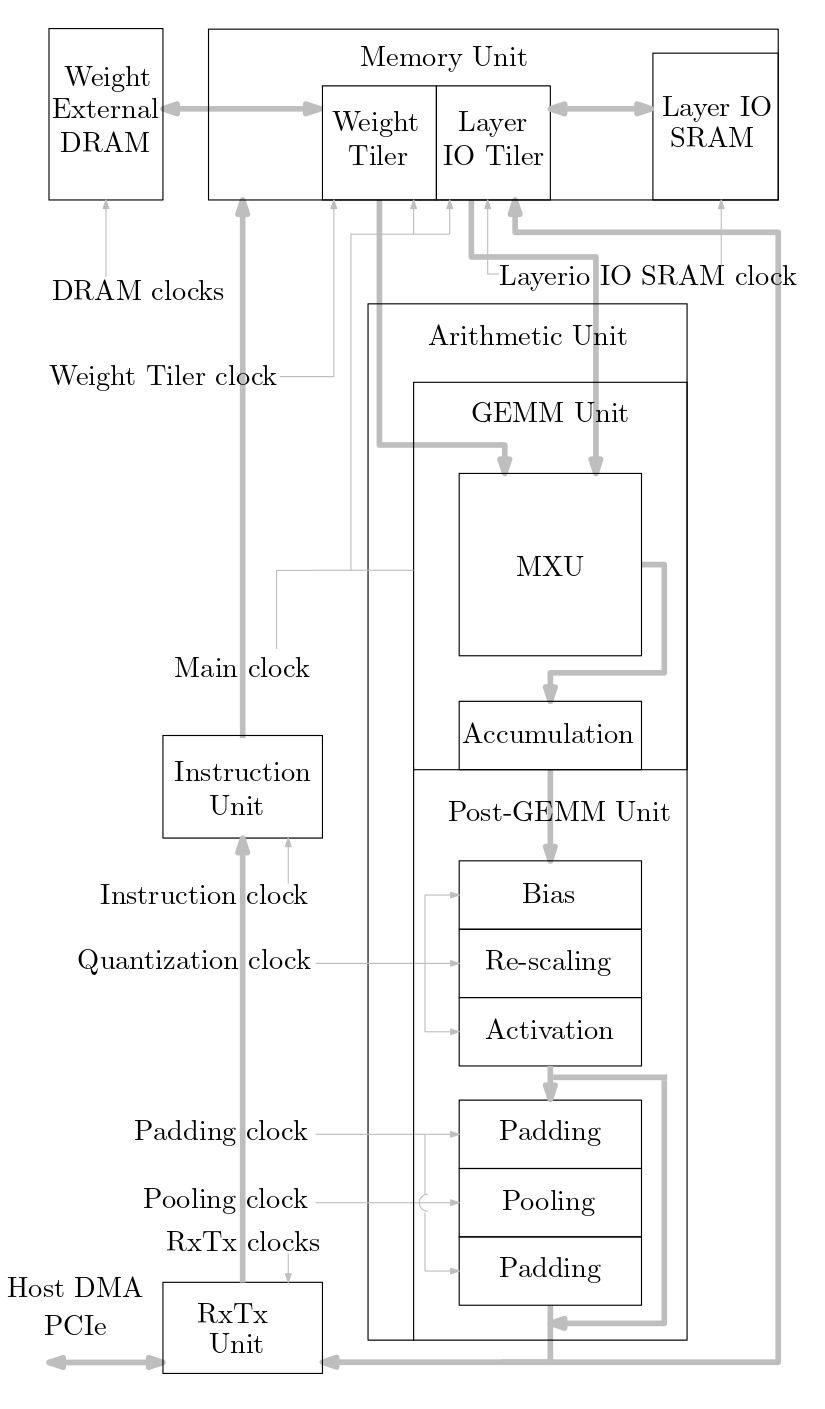
次の図は、このソース コードに実装されている ML アクセラレータ システムの概要を示しています。
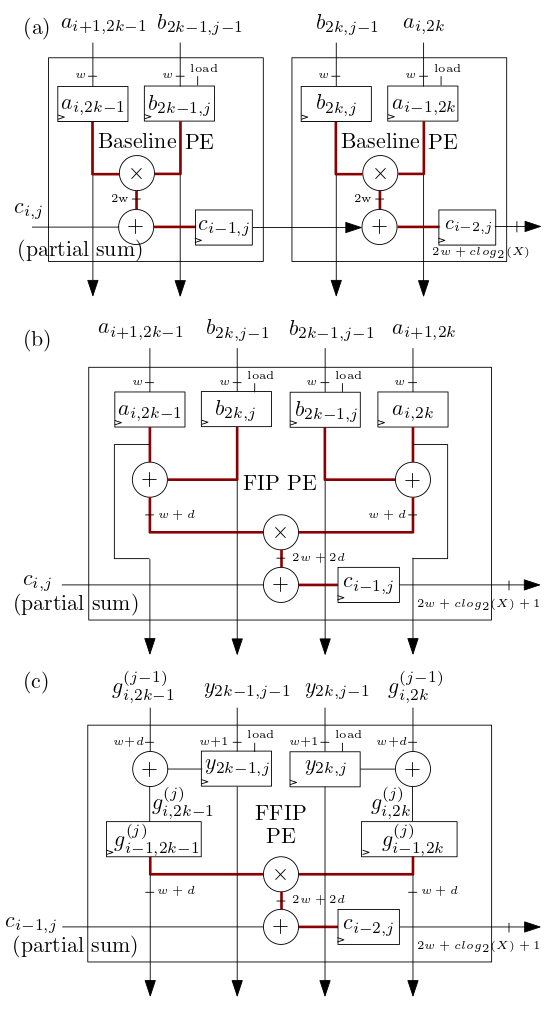
以下の (b) および (c) に示す FIP および FFIP シストリック アレイ/MXU プロセッシング エレメント (PE) は、FIP および FFIP 内積アルゴリズムを実装し、それぞれが個別に、( (b) および (c) に示す 2 つのベースライン PE と同じ有効な計算能力を提供します) a) 以前のシストリック アレイ ML アクセラレータと同様にベースライン内積を実装するものを組み合わせたもの:
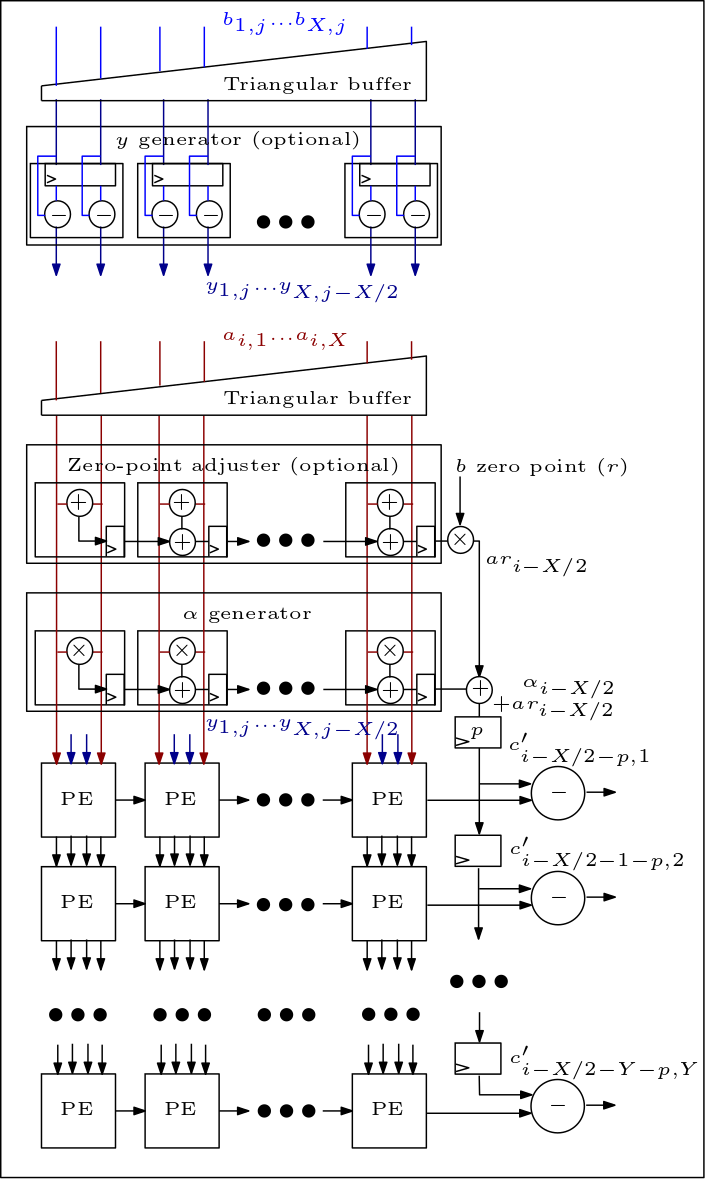
以下は MXU/シストリック アレイの図であり、PE がどのように接続されているかを示しています。
ソースコードの構成は次のとおりです。
ファイル rtl/top/define.svh および rtl/top/pkg.sv には、シストリック アレイ タイプ (ベースライン、FIP、または FFIP) を定義する define.svh 内の FIP_METHOD、シストリック配列の高さ/幅、および入力ビット幅を定義する LAYERIO_WIDTH/WEIGHT_WIDTH。
ディレクトリ rtl/arith には、ベースライン、FIP、および FFIP シストリック アレイ アーキテクチャ (パラメータ FIP_METHOD の値に応じて) の RTL を含む mxu.sv および mac_array.sv が含まれています。


