lumiere pytorch
0.0.24
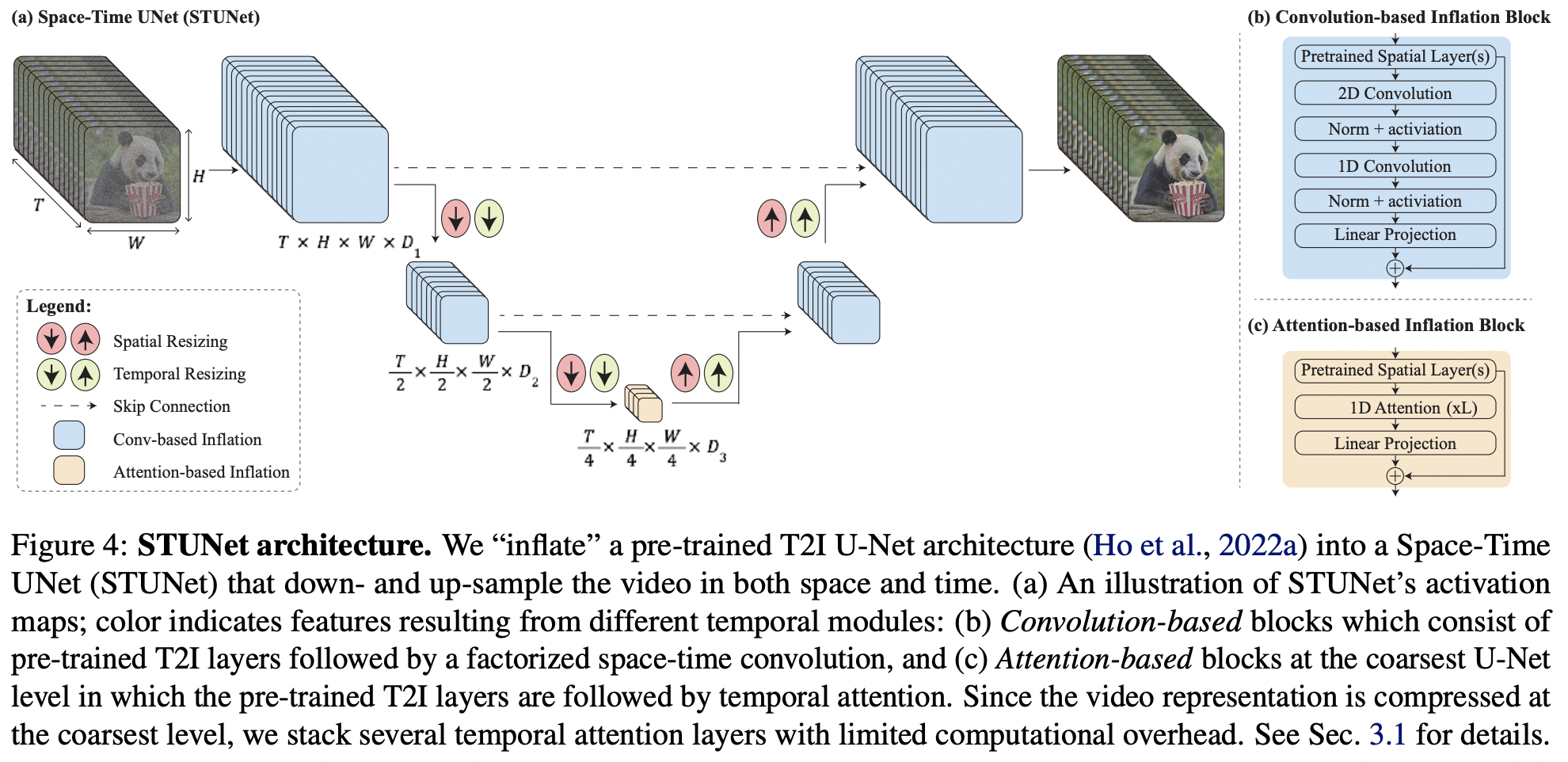
Google Deepmind からの SOTA テキストからビデオへの生成である Lumiere の Pytorch での実装
ヤニックの論文レビュー
このペーパーはほとんどがテキストから画像へのモデルに基づいたいくつかの重要なアイデアにすぎないため、さらに一歩進めて、このリポジトリ内のビデオに新しい Karras U-net を拡張します。
$ pip install lumiere-pytorch import torch
from lumiere_pytorch import MPLumiere
from denoising_diffusion_pytorch import KarrasUnet
karras_unet = KarrasUnet (
image_size = 256 ,
dim = 8 ,
channels = 3 ,
dim_max = 768 ,
)
lumiere = MPLumiere (
karras_unet ,
image_size = 256 ,
unet_time_kwarg = 'time' ,
conv_module_names = [
'downs.1' ,
'ups.1' ,
'downs.2' ,
'ups.2' ,
],
attn_module_names = [
'mids.0'
],
upsample_module_names = [
'ups.2' ,
'ups.1' ,
],
downsample_module_names = [
'downs.1' ,
'downs.2'
]
)
noised_video = torch . randn ( 2 , 3 , 8 , 256 , 256 )
time = torch . ones ( 2 ,)
denoised_video = lumiere ( noised_video , time = time )
assert noised_video . shape == denoised_video . shape すべての時間レイヤーを追加する
学習用に一時パラメータのみを公開し、それ以外はすべて凍結します
一時的なダウンサンプリング後の時間条件付けに対処する最適な方法を見つけます。最初に pytree 変換を行う代わりに、おそらくすべてのモジュールにフックしてバッチ サイズを検査する必要があります。
(batch, seq, dim)として出力形状を持つ可能性がある中間モジュールを処理します。
Tero Karras の結論に従って、マグニチュードを保存した 4 つのモジュールの変形を即興で作成する
imagen-pytorch でテストしてみる
マルチ拡散を調べて、単純なラッパーにできるかどうかを確認してください
@inproceedings { BarTal2024LumiereAS ,
title = { Lumiere: A Space-Time Diffusion Model for Video Generation } ,
author = { Omer Bar-Tal and Hila Chefer and Omer Tov and Charles Herrmann and Roni Paiss and Shiran Zada and Ariel Ephrat and Junhwa Hur and Yuanzhen Li and Tomer Michaeli and Oliver Wang and Deqing Sun and Tali Dekel and Inbar Mosseri } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:267095113 }
} @article { Karras2023AnalyzingAI ,
title = { Analyzing and Improving the Training Dynamics of Diffusion Models } ,
author = { Tero Karras and Miika Aittala and Jaakko Lehtinen and Janne Hellsten and Timo Aila and Samuli Laine } ,
journal = { ArXiv } ,
year = { 2023 } ,
volume = { abs/2312.02696 } ,
url = { https://api.semanticscholar.org/CorpusID:265659032 }
}

