ChatGPT_WeChat
ChatGPT_WeChat_VoiceChat
導入:
未認証の WeChat 公開アカウントが chatgpt に接続され、Flask ベースの新しい音声チャット (英会話) が追加され、個人の WeChat 公開アカウント (認証なし) が ChatGPT に接続されます
--更新手順:
V1.1.0: (2023.04.13)
- リクエストのタイムアウトの問題をある程度軽減するために、新しいストリーミング応答 (ストリーム) を追加しました。 Python パッケージをインストールする必要があります: sseclient-py==1.7.2;
ストリーミング応答が有効になった後、最初に接続 (myrequest) が確立され、次に (SSEClient) を使用して生成されたテキストを 1 文字ずつ取得し、最後に取得されたテキスト リストが応答テキストに結合されます。接続を確立する時間は max_tokens の影響を受けるため、max_tokens を大きくしすぎることはお勧めできません。リクエストのタイムアウトを軽減する鍵は、接続の確立にかかる時間が 1 回の返信にかかる時間よりも短いことです。したがって、一定時間内に接続が正常に確立されていれば、基本的にコンテンツを返すことができます。返されるコンテンツの長さは接続時間の影響を受けます。
- リクエストが失敗するかタイムアウトになった後、次の返信でのエラーを避けるために、ユーザーが送信した最新のメッセージを削除します。
V1.0.1:
- IP 検出を有効にするオプションを追加しました (DOS 攻撃を防止するため)。
- 注: wechat-ip_detection と azure-trans_to_voice のいずれかが true の場合、appid と Secret の両方を入力する必要があります。
V1.0:
- 新しいボイス チャット機能、Microsoft クラウド テキスト読み上げサービス (無料アクセス) にアクセスし、音声会話 (中国語と英語) を実現します。
- 英語学習テンプレートが内蔵されており、テンプレートメッセージに返信することで英語をテーマにした会話ができます。
- Doss 攻撃などを防ぐために、WeChat バックグラウンド ホワイトリスト IP 検出を追加しました。
- 悪意のあるメッセージスパムを防ぐためにユーザーメッセージの頻度制限を追加しました。
- 一時音声ファイルを自動的にクリーンアップします。
- WeChat バックグラウンドでアップロードされた一時的な音声素材を自動的にクリーンアップします。
-パフォーマンスを最適化し、バグを修正します。
背景:
最近、ChatGPT が API インターフェイスを提供していることを知りました。たまたまサーバーとパブリック アカウントを持っているので、チャットボットを作成してみませんか。ただし、未認証の個人公式アカウントは 1 つだけです (リソースは限られています?)。この公式アカウントの制限は次のとおりです。
1. ユーザーが公式アカウントにメッセージを送信できるのは受動的にのみであり、サーバーはこのリクエストに対して 1 つのメッセージにのみ返信でき、追加のメッセージ (カスタマー サービス メッセージ) には返信できません。
2. 各メッセージは 15 秒以内に応答する必要があります。公式アカウント プラットフォームはサーバーにリクエストを送信した後、5 秒以内に応答を受信しない場合は、別のリクエストを送信し、リクエストがまだである場合は 5 秒間待機します。受信されなかった場合は、最後のリクエストが送信されるため、サーバーは 15 秒以内にメッセージ全体を処理する必要があります。
具体的な処理方法についてはコードを参照してください。これは初心者のプロジェクトです。欠点があれば修正を歓迎します。ありがとうございます~
必要:
サーバー (openai インターフェースにアクセスできる必要があります。海外にある必要がある場合もあります~)
テキスト読み上げサービスを有効にする必要がある場合は、Azure のテキスト読み上げサービスを登録する必要があります。このサービスの登録と使用は無料です。詳しくは、AZURE の Web サイトを参照してください。
WeChat 公開アカウント: 個人タイプで十分です
デモ:
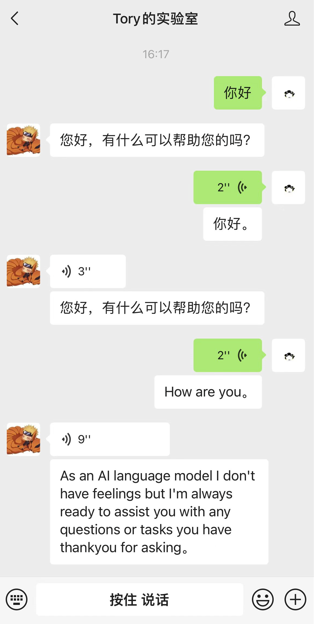
公開アカウント: トリーの研究室、フォローしてメッセージを送って体験してください。
公開アカウントのツイートの概要:
1. はじめに: ChatGPT が接続されました
2. 音声サービスの使い方の紹介: 音声サービスが接続されました
使用方法:
config で config.yml パラメータを設定します。
# 微信相关设置
wechat :
token : " **** "
# 是否获取微信公众平台的ip白名单(用于防止doss检测)
ip_detection : false
# 如果上面的选项为true,下面两项内容必填;如要开启后面文本转语音服务,下面两项内容必填
appid : " **** "
secret : " **** "
# openai相关设置
openai :
#填写openai的api_keys时,要注意前面要加上:Bearer, 可以填写多个,因为单个账号有速率的限制
api_keys :
- " Bearer sk-**** "
# - "Bearer sk-****"
# - "Bearer sk-****"
# 单条消息的长度,这个参数对回复速度有非常大的影响,请不要填太大~
max_tokens : 120
# 模型
model : " gpt-3.5-turbo-0301 "
# temperature,越大随机性越强
temperature : 0.8
# 有时候文本长度超过150,用该参数限制长度避免超过微信能发送的最长消息
rsize : 500
# 对话的保存历史
save_history : 21
# azure文本转语音设置
azure :
# 是否开启文本转语音服务
trans_to_voice : false
# 如上面的选项为false,下面的内容不用填写
# 新定义文本长度,开启后增加处理时间,避免文本太长,处理时间过久,超过15s
max_token : 80
# 是否开启流式响应
stream_response : true
# 密钥
subscription : " **** "
region : " koreacentral "
# 中文语音模型
zh_model : " zh-CN-XiaoyanNeural "
# 英文语音模型
en_model : " en-US-AriaNeural "フラスコを開始します
export FLASK_APP=myflask
flask run --host=0.0.0.0 --port=80
# 或者
nohup flask run --host=0.0.0.0 --port=80 >> /home/jupyter/flask/log/wechat.log 2>&1 &知らせ:
1. openai の api_keys を入力するときは、必ず「Bearer」を前に追加してください。 1 つのアカウントにはレート制限があるため、複数の api_key を入力できます。
2.max_tokens は返信速度に大きな影響を与えるため、あまり大きく入力しないでください。


