ChatGPT WechatBot using OpenAI API via Wechty
1.0.0
ChatGPT-WechatBot は、OpenAI 公式 API に基づく対話モデルを使用して実装された chatGPT 類似のロボットであり、Wechaty フレームワークを通じて WeChat 上に配置され、ロボット チャットを実現します。
ChatGPT WechatBot は、OpenAI 公式 API に基づいており、対話モデルを使用して、Wechat フレームワークを通じて WeChat 上に展開され、ロボット チャットを実現します。
注: このプロジェクトはローカル Win10 実装であり、サーバーのデプロイメントは必要ありません (サーバーのデプロイメントが必要な場合は、Docker をサーバーにデプロイできます)
(1)、Windows10
(2)、ドッカー 20.10.21
(3)、Python3.9
(4)、Wechaty 0.10.7
1.Dockerをダウンロードする
https://www.docker.com/products/docker-desktop/ Docker をダウンロードする
2. Win10仮想化をオンにする
以下の図に示すように、cmd に control と入力してコントロール パネルを開き、プログラムに入ります。
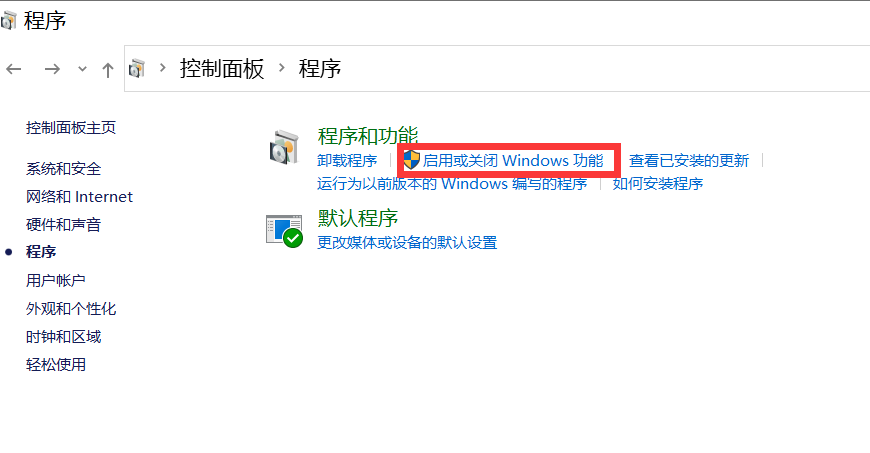
「Windows の機能をオンまたはオフにし、 Hyper-V をオンにする」に移動します。
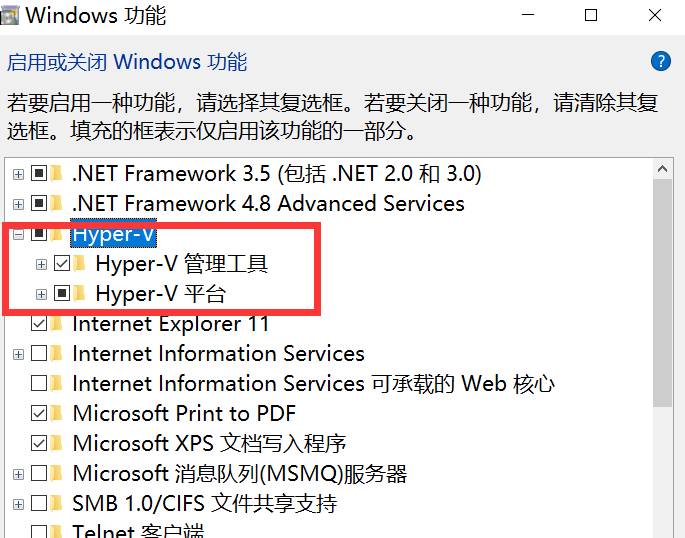
注: コンピュータに Hyper-V が搭載されていない場合は、次の操作を実行する必要があります。
テキスト ドキュメントを作成し、次のコードを入力し、 Hyper.cmd という名前を付けます。
pushd " %~dp0 "
dir /b %SystemRoot% s ervicing P ackages * Hyper-V * .mum > hyper-v.txt
for /f %%i in ( ' findstr /i . hyper-v.txt 2^>nul ' ) do dism /online /norestart /add-package: " %SystemRoot%servicingPackages%%i "
del hyper-v.txt
Dism /online /enable-feature /featurename:Microsoft-Hyper-V-All /LimitAccess /ALL次に、このファイルを管理者として実行します。スクリプトの実行が完了したら、コンピューターを再起動するとHyper-Vノードが表示されます。
3. Docker を実行する
注: Docker を初めて実行するときに次のような状況が発生した場合:
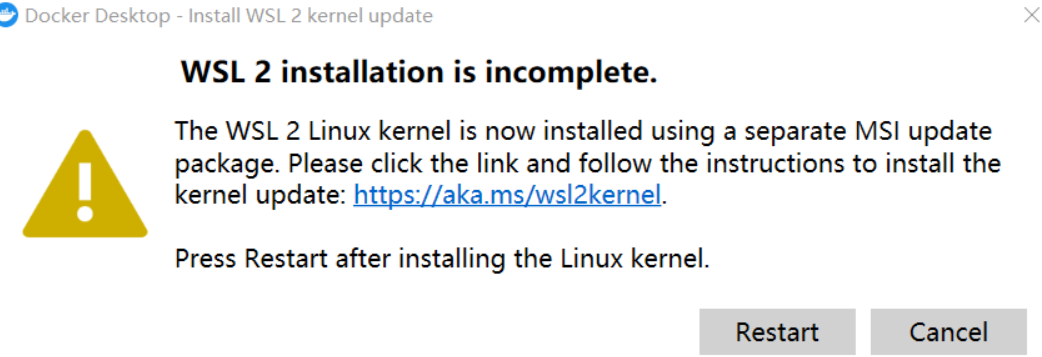
最新の WSL 2 パッケージをダウンロードする必要があります
https://wslstorestorage.blob.core.windows.net/wslblob/wsl_update_x64.msi
更新後、メイン ページに入り、Docker エンジンの設定を変更して、イメージを Alibaba Cloud の国内イメージに置き換えることができます。
{
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"debug": false,
"experimental": false,
"features": {
"buildkit": true
},
"insecure-registries": [],
"registry-mirrors": [
"https://9cpn8tt6.mirror.aliyuncs.com"
]
}これでミラーを引き出すのが早くなります(国内ユーザー向け)
4. Wechaty イメージをプルします。
docker pull wechaty:0 . 65テスト中に、wechaty のバージョン 0.65 が最も安定していることが判明したためです。
イメージをプルした後:
Puppet : Wechat ロボットを開発する場合は、WeChat の動作を制御するミドルウェア Puppet を使用する必要があります。Puppet の正式な翻訳は現在、さまざまなバージョンが存在します。 Puppet の特徴は、実現できるさまざまなロボット機能です。たとえば、ロボットにグループ チャットからユーザーを追い出したい場合は、Pad プロトコルで Puppet を使用する必要があります。
接続申請:http://pad-local.com/#/login
注: アカウントを申請すると、7 日間のトークンが届きます。
トークンを適用した後、cmd ウィンドウで次のコマンドを実行します。
docker run - it - d -- name wechaty_test - e WECHATY_LOG="verbose" - e WECHATY_PUPPET="wechaty - puppet - padlocal" - e WECHATY_PUPPET_PADLOCAL_TOKEN="yourtoken" - e WECHATY_PUPPET_SERVER_PORT="8080" - e WECHATY_TOKEN="1fe5f846 - 3cfb - 401d - b20c - sailor==" - p "8080:8080" wechaty/wechaty:0 . 65
パラメータの説明:
WECHATY_PUPPET_PADLOCAL_TOKEN : 適切なトークンを申請します
**WECHATY_TOKEN **: 一意であることが保証されたランダムな文字列を書き込むだけです
WECHATY_PUPPET_SERVER_PORT : Dockerサーバーポート
wechaty/wechaty:0.65 : wechaty画像のバージョン
注: - 「8080:8080」* はローカル マシンと Docker サーバーのポートです。Docker サーバーのポートは WECHATY_PUPPET_SERVER_PORT と一致している必要があることに注意してください。
実行後、Docker デスクトップ パネルでコンテナーを表示します。
ログ インターフェイスに入ります。
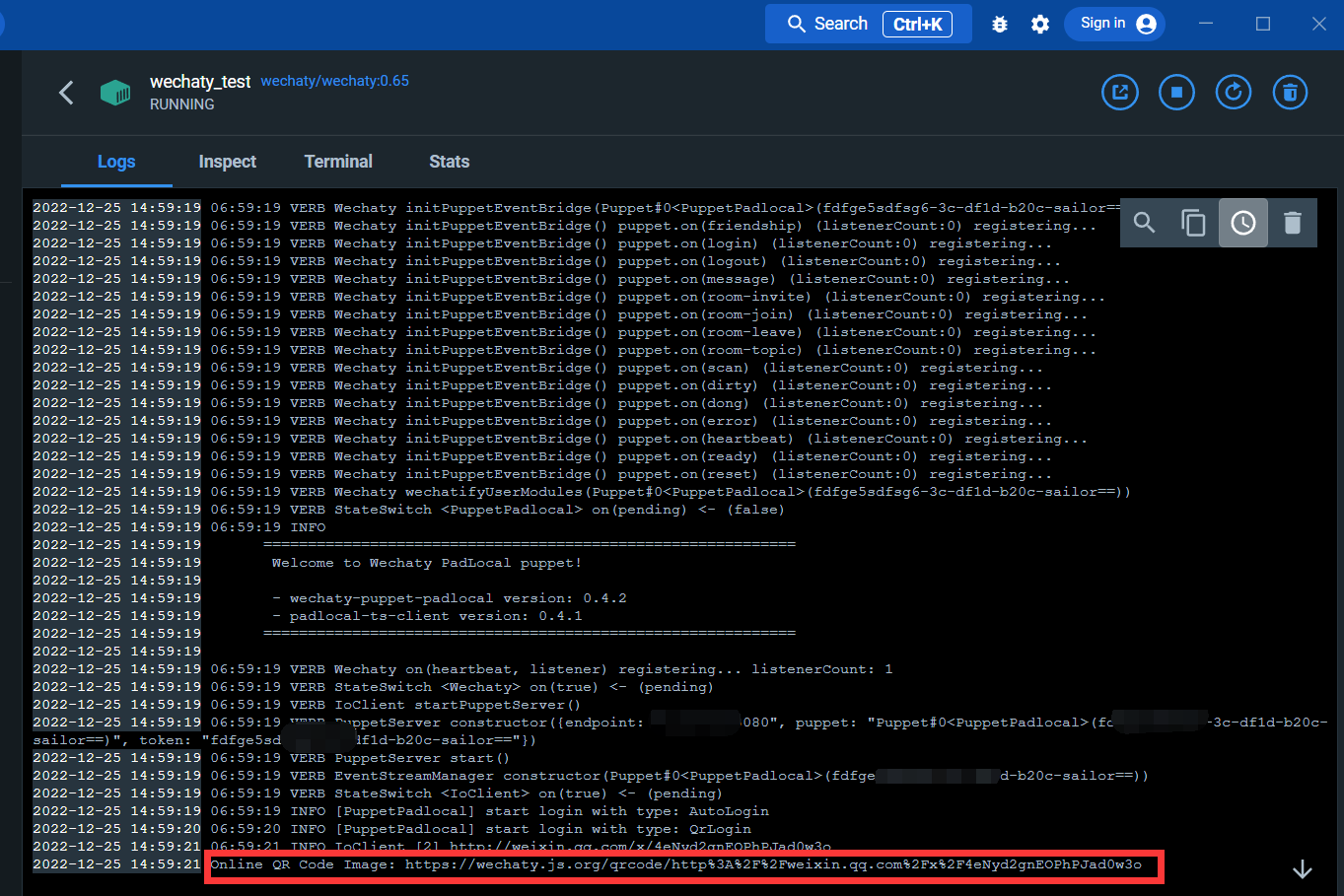
以下のリンクから QR コードをスキャンして WeChat にログインできます
ログイン後、docker サービスが完了します。
wechatyおよびopenaiライブラリをインストールする
cmd を開き、次のコマンドを実行します。
pip install wechaty
pip install openaiopenAIにログイン
https://beta.openai.com/
「API キーを表示」をクリックします
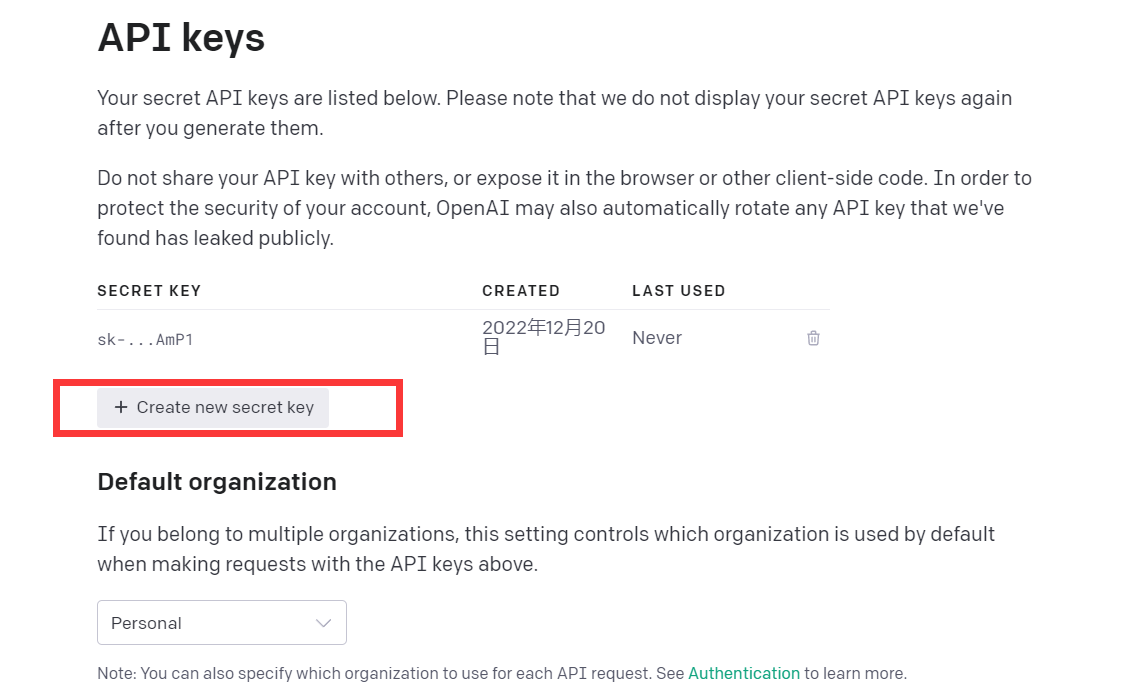
API キーを取得するだけです
この時点で環境は整っています
このデモコードを読んでみてください
import openai
openai . api_key = "your API-KEY"
start_sequence = "A:"
restart_sequence = "Q: "
while True :
print ( restart_sequence , end = "" )
prompt = input ()
if prompt == 'quit' :
break
else :
try :
response = openai . Completion . create (
model = "text-davinci-003" ,
prompt = prompt ,
temperature = 0.9 ,
max_tokens = 2000 ,
frequency_penalty = 0 ,
presence_penalty = 0
)
print ( start_sequence , response [ "choices" ][ 0 ][ "text" ]. strip ())
except Exception as exc :
print ( exc )
このコードは、chatGPT と同じモデルである CPT-3 モデルを呼び出しており、応答効果も良好です。
openAI の GPT-3 モデルは次のように紹介されます。
当社の GPT-3 モデルは、自然言語を理解して生成できます。さまざまなタスクに適したさまざまなレベルの 4 つの主要なモデルが提供されています。Davinci が最も高性能なモデルであり、Ada が最も高速です。
| 最新モデル | 説明 | 最大リクエスト | トレーニングデータ |
|---|---|---|---|
| テキスト-ダヴィンチ-003 | 最も有能な GPT-3 モデル。他のモデルが実行できるあらゆるタスクを実行でき、多くの場合、より高品質で、より長い出力が得られ、テキスト内での補完の挿入もサポートされます。 | 4,000トークン | 2021年6月まで |
| テキスト-キュリー-001 | 非常に有能ですが、Davinci よりも高速で低コストです。 | 2,048トークン | 2019年10月まで |
| テキスト-バベッジ-001 | 単純なタスクを非常に高速に実行でき、コストも低くなります。 | 2,048トークン | 2019年10月まで |
| テキスト-ADA-001 | 非常に単純なタスクを実行でき、通常は GPT-3 シリーズの中で最も高速なモデルであり、コストが最も低くなります。 | 2,048トークン | 2019年10月まで |
一般に Davinci が最も有能ですが、他のモデルは特定のタスクを非常にうまく実行でき、速度やコストが大幅に向上します。たとえば、Curie は Davinci と同じタスクの多くを、より高速かつ 10 分の 1 のコストで実行できます。
Davinci を使用すると最良の結果が得られるため、実験中には Davinci を使用することをお勧めします。作業が完了したら、他のモデルを試して、より低いレイテンシで同じ結果が得られるかどうかを確認することをお勧めします。また、他のモデルも改善できる可能性があります。特定のタスクに合わせてモデルを微調整することで、モデルのパフォーマンスを向上させます。
つまり、最も強力なGPT-3モデルです。他のモデルが実行できることはすべて実行でき、通常は高品質、より長い出力、より適切な指示に従います。テキストへの補完の挿入もサポートされています。
text-davinci-003 モデルを直接使用すると、chatGPT の単一ラウンドの対話効果を実現できますが、chatGPT と同じマルチラウンドの対話効果をより適切に実現するために、対話モデルを設計できます。
基本原則: text-davinci-003 モデルに現在の会話のコンテキストを伝える
実装方法: 現在の対話の最初のk回の対話を保存する対話メモリ キューを設計し、質問する前に最初のk回の対話の内容をtext-davinci-003 モデルに伝え、現在の回答を取得します。 text-davinci-003 モデルコンテンツを通じて
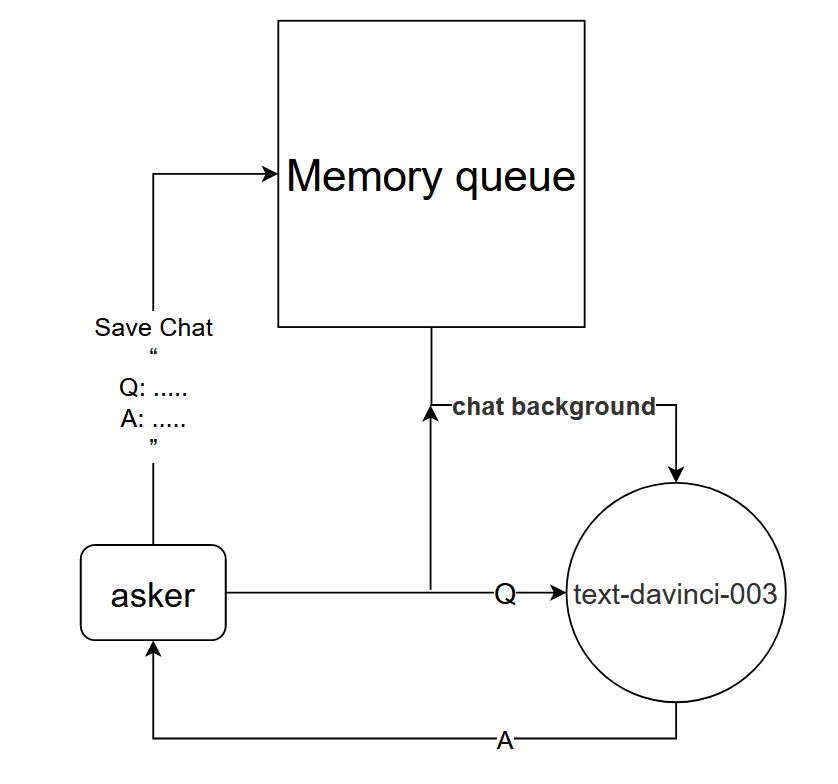
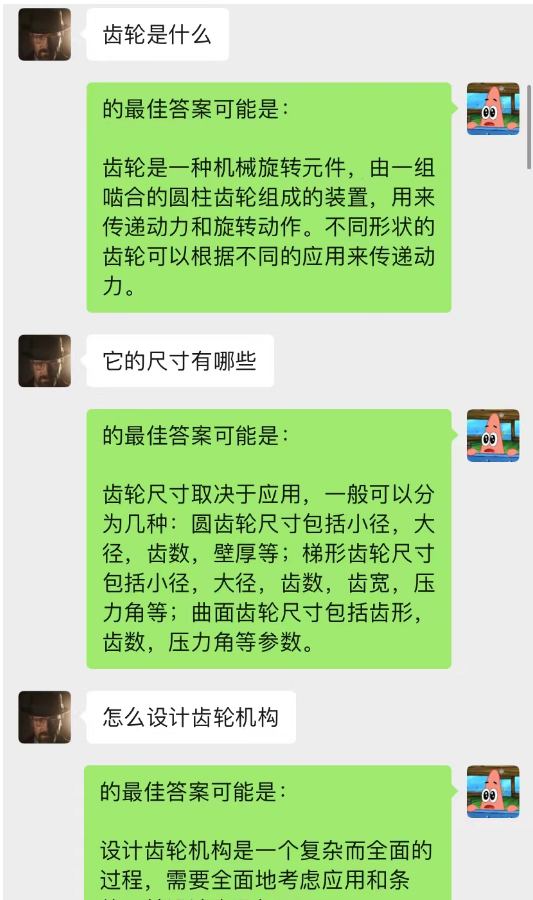
この方法は驚くほどうまくいきます!チャットの記録をいくつか与える
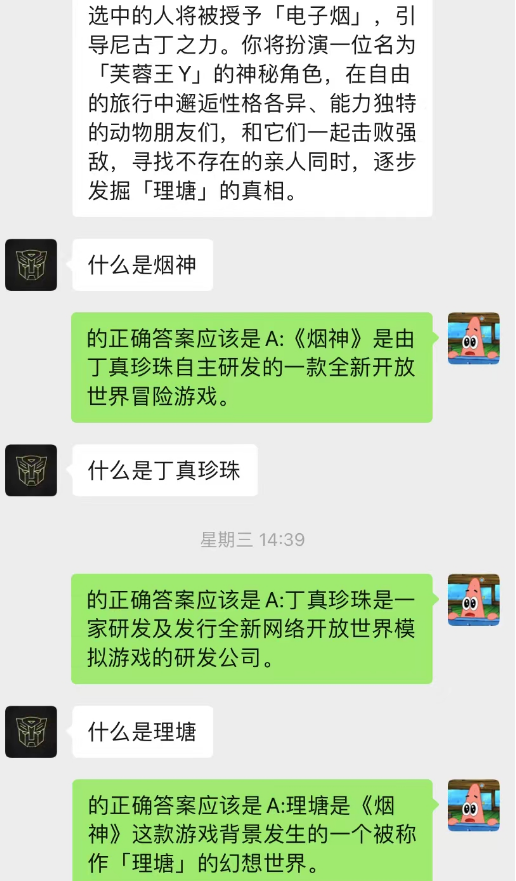
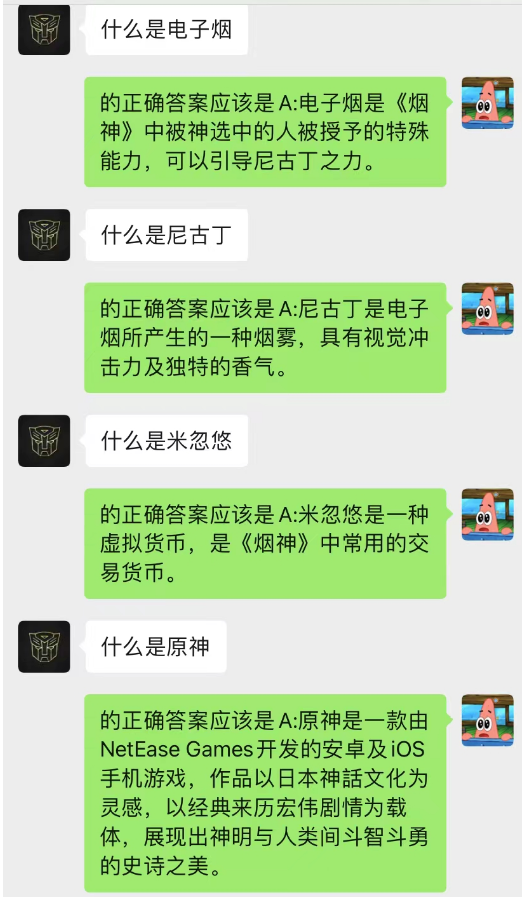
AI はチャットバックグラウンドを通じて状況学習を完了することもできることがわかります。
それだけでなく、chatGPT と同じガイド付き記事作成も実現できます。
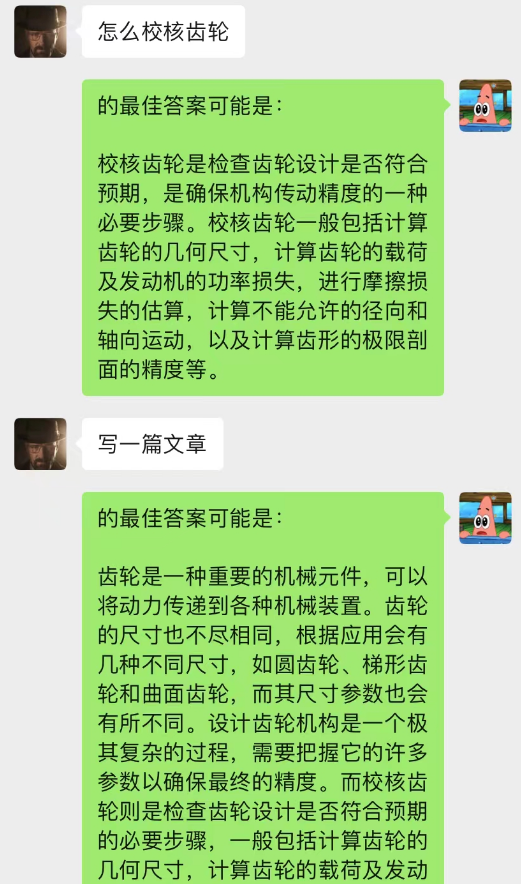
このモデルは、チャット背景対話モデルを最適化するために現在考えている手法であり、基本的なロジックは N が動的に変更され、現在の対話関係を予測するためにマルコフ プロパティが追加される点が異なります。チャット背景のセクションが最も重要であると判断し、text-davinci-003 モデルを使用して、現在の問題と組み合わせた最も重要な記憶された対話内容に基づいて回答を提供します。以前のチャット コンテンツを使用して、チャット中に AI に実行させることもできます)
このモデルの実装にはトレーニング用に大量のデータが必要ですが、コードはまだ完成していません。
------掘り下げ: コードの実装後、詳細な手順のこの部分を更新します。
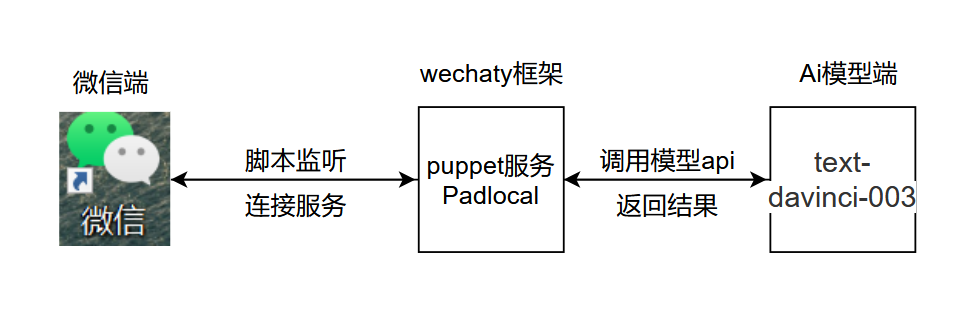
プロジェクトの基本的なロジックは次の図に示すとおりです。
 .py、表示された場所に chatGPT.py を追加して開き、秘密キーを追加して、表示された場所で環境変数を構成します
.py、表示された場所に chatGPT.py を追加して開き、秘密キーを追加して、表示された場所で環境変数を構成します

コードの説明:
os . environ [ "WECHATY_PUPPET_SERVICE_TOKEN" ] = "填入你的Puppet的token" os . environ [ 'WECHATY_PUPPET' ] = 'wechaty-puppet-padlocal' #保证与docker中相同即可 os.environ['WECHATY_PUPPET_SERVICE_ENDPOINT'] = '主机ip:端口号'
正常に実行されました
1. docker にログインします。Python では wechaty ログインを使用しないでください。
2. コードにtime.sleep()を設定して、ユーザーがメッセージに返信する速度をシミュレートします。
3. テスト時には大きなサイズを使用しないことをお勧めします。AI テスト専用の小さなサイズを作成することをお勧めします。
このプロジェクトの内容は技術研究と科学の普及のみを目的としており、いかなる商用アプリケーションの認可も提供するものではなく、いかなる行為に対しても責任を負いません。
~~メール: [email protected]


