whisper.cpp
v1.7.2
安定:v1.7.2 /ロードマップ|よくある質問
Openaiのささやき自動音声認識(ASR)モデルの高性能推論:
サポートされているプラットフォーム:
モデルの高レベルの実装全体は、whisper.hおよびwhisper.cppに含まれています。コードの残りの部分は、 ggml機械学習ライブラリの一部です。
モデルのこのような軽量の実装を使用すると、さまざまなプラットフォームやアプリケーションに簡単に統合できます。例として、ここにiPhone 13デバイスでモデルを実行するビデオがあります - 完全にオフライン、オンデバイス:whisper.objc
また、独自のオフライン音声アシスタントアプリケーションを簡単に作成することもできます:コマンド
Apple Siliconでは、推論は金属経由でGPUで完全に実行されます。
または、ブラウザ:talk.wasmでまっすぐに実行することもできます
テンソル演算子は、Apple Silicon CPUのために重く最適化されています。計算サイズに応じて、ARM Neon Simd IntrinsicsまたはCBLAS Accelerate Frameworkルーチンが使用されます。後者は、Accelerate Frameworkが最新のApple製品で利用可能な特殊なAMXコプロセッサを利用しているため、より大きなサイズに特に効果的です。
最初にリポジトリをクローンします:
git clone https://github.com/ggerganov/whisper.cpp.gitディレクトリに移動します。
cd whisper.cpp
次に、 ggml形式で変換されたささやきモデルの1つをダウンロードします。例えば:
sh ./models/download-ggml-model.sh base.en主な例を作成し、次のようなオーディオファイルを転写します。
# build the main example
make -j
# transcribe an audio file
./main -f samples/jfk.wav簡単なデモのために、単にmake base.en実行するだけです:
$ make -j base.en
cc -I. -O3 -std=c11 -pthread -DGGML_USE_ACCELERATE -c ggml.c -o ggml.o
c++ -I. -I./examples -O3 -std=c++11 -pthread -c whisper.cpp -o whisper.o
c++ -I. -I./examples -O3 -std=c++11 -pthread examples/main/main.cpp whisper.o ggml.o -o main -framework Accelerate
./main -h
usage: ./main [options] file0.wav file1.wav ...
options:
-h, --help [default] show this help message and exit
-t N, --threads N [4 ] number of threads to use during computation
-p N, --processors N [1 ] number of processors to use during computation
-ot N, --offset-t N [0 ] time offset in milliseconds
-on N, --offset-n N [0 ] segment index offset
-d N, --duration N [0 ] duration of audio to process in milliseconds
-mc N, --max-context N [-1 ] maximum number of text context tokens to store
-ml N, --max-len N [0 ] maximum segment length in characters
-sow, --split-on-word [false ] split on word rather than on token
-bo N, --best-of N [5 ] number of best candidates to keep
-bs N, --beam-size N [5 ] beam size for beam search
-wt N, --word-thold N [0.01 ] word timestamp probability threshold
-et N, --entropy-thold N [2.40 ] entropy threshold for decoder fail
-lpt N, --logprob-thold N [-1.00 ] log probability threshold for decoder fail
-debug, --debug-mode [false ] enable debug mode (eg. dump log_mel)
-tr, --translate [false ] translate from source language to english
-di, --diarize [false ] stereo audio diarization
-tdrz, --tinydiarize [false ] enable tinydiarize (requires a tdrz model)
-nf, --no-fallback [false ] do not use temperature fallback while decoding
-otxt, --output-txt [false ] output result in a text file
-ovtt, --output-vtt [false ] output result in a vtt file
-osrt, --output-srt [false ] output result in a srt file
-olrc, --output-lrc [false ] output result in a lrc file
-owts, --output-words [false ] output script for generating karaoke video
-fp, --font-path [/System/Library/Fonts/Supplemental/Courier New Bold.ttf] path to a monospace font for karaoke video
-ocsv, --output-csv [false ] output result in a CSV file
-oj, --output-json [false ] output result in a JSON file
-ojf, --output-json-full [false ] include more information in the JSON file
-of FNAME, --output-file FNAME [ ] output file path (without file extension)
-ps, --print-special [false ] print special tokens
-pc, --print-colors [false ] print colors
-pp, --print-progress [false ] print progress
-nt, --no-timestamps [false ] do not print timestamps
-l LANG, --language LANG [en ] spoken language ('auto' for auto-detect)
-dl, --detect-language [false ] exit after automatically detecting language
--prompt PROMPT [ ] initial prompt
-m FNAME, --model FNAME [models/ggml-base.en.bin] model path
-f FNAME, --file FNAME [ ] input WAV file path
-oved D, --ov-e-device DNAME [CPU ] the OpenVINO device used for encode inference
-ls, --log-score [false ] log best decoder scores of tokens
-ng, --no-gpu [false ] disable GPU
sh ./models/download-ggml-model.sh base.en
Downloading ggml model base.en ...
ggml-base.en.bin 100%[========================>] 141.11M 6.34MB/s in 24s
Done! Model 'base.en' saved in 'models/ggml-base.en.bin'
You can now use it like this:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
===============================================
Running base.en on all samples in ./samples ...
===============================================
----------------------------------------------
[+] Running base.en on samples/jfk.wav ... (run 'ffplay samples/jfk.wav' to listen)
----------------------------------------------
whisper_init_from_file: loading model from 'models/ggml-base.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 512
whisper_model_load: n_audio_head = 8
whisper_model_load: n_audio_layer = 6
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 512
whisper_model_load: n_text_head = 8
whisper_model_load: n_text_layer = 6
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 2
whisper_model_load: mem required = 215.00 MB (+ 6.00 MB per decoder)
whisper_model_load: kv self size = 5.25 MB
whisper_model_load: kv cross size = 17.58 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 140.60 MB
whisper_model_load: model size = 140.54 MB
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:11.000] And so my fellow Americans, ask not what your country can do for you, ask what you can do for your country.
whisper_print_timings: fallbacks = 0 p / 0 h
whisper_print_timings: load time = 113.81 ms
whisper_print_timings: mel time = 15.40 ms
whisper_print_timings: sample time = 11.58 ms / 27 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 266.60 ms / 1 runs ( 266.60 ms per run)
whisper_print_timings: decode time = 66.11 ms / 27 runs ( 2.45 ms per run)
whisper_print_timings: total time = 476.31 ms
コマンドは、カスタムggml形式に変換されたbase.enモデルをダウンロードし、フォルダーsamples内のすべての.wavサンプルの推論を実行します。
詳細な使用手順については、実行: ./main -h
主な例は現在、16ビットWAVファイルでのみ実行されているため、ツールを実行する前に入力を変換するようにしてください。たとえば、次のようにffmpeg使用できます。
ffmpeg -i input.mp3 -ar 16000 -ac 1 -c:a pcm_s16le output.wav追加のオーディオサンプルを再生する必要がある場合は、単に実行してください。
make -j samples
これにより、ウィキペディアからさらにいくつかのオーディオファイルをダウンロードし、 ffmpegを介して16ビットWAV形式に変換します。
次のように、他のモデルをダウンロードして実行できます。
make -j tiny.en
make -j tiny
make -j base.en
make -j base
make -j small.en
make -j small
make -j medium.en
make -j medium
make -j large-v1
make -j large-v2
make -j large-v3
make -j large-v3-turbo
| モデル | ディスク | メム |
|---|---|---|
| 小さい | 75ミブ | 〜273 Mb |
| ベース | 142ミブ | 〜388 MB |
| 小さい | 466ミブ | 〜852 MB |
| 中くらい | 1.5ギブ | 〜2.1 gb |
| 大きい | 2.9ギブ | 〜3.9 gb |
whisper.cpp whisper ggmlモデルの整数の量子化をサポートしています。量子化されたモデルは、メモリとディスクのスペースを減らす必要があり、ハードウェアに応じてより効率的に処理できます。
定量化されたモデルを作成して使用する手順は次のとおりです。
# quantize a model with Q5_0 method
make -j quantize
./quantize models/ggml-base.en.bin models/ggml-base.en-q5_0.bin q5_0
# run the examples as usual, specifying the quantized model file
./main -m models/ggml-base.en-q5_0.bin ./samples/gb0.wavAppleシリコンデバイスでは、エンコーダーの推論は、Core MLを介してApple Neural Engine(ANE)で実行できます。これにより、CPUのみの実行と比較してx3を超えるx3を超える可能性があります。コアMLモデルを生成し、 whisper.cppで使用するための指示を次に示します。
コアMLモデルの作成に必要なPython依存関係をインストールします。
pip install ane_transformers
pip install openai-whisper
pip install coremltoolscoremltoolsが正しく動作するようにするには、xcodeがインストールされていることを確認し、 xcode-select --install実行して、インストールしてコマンドラインツールをインストールしてください。conda create -n py310-whisper python=3.10 -yconda activate py310-whisperくださいコアMLモデルを生成します。たとえば、 base.enモデルを生成するには、以下を使用してください。
./models/generate-coreml-model.sh base.enこれにより、フォルダーmodels/ggml-base.en-encoder.mlmodelcが生成されます
コアMLサポートを使用してwhisper.cpp構築します:
# using Makefile
make clean
WHISPER_COREML=1 make -j
# using CMake
cmake -B build -DWHISPER_COREML=1
cmake --build build -j --config Release通常どおり例を実行します。例えば:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
...
whisper_init_state: loading Core ML model from 'models/ggml-base.en-encoder.mlmodelc'
whisper_init_state: first run on a device may take a while ...
whisper_init_state: Core ML model loaded
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 | COREML = 1 |
...
ANEサービスがコアMLモデルをいくつかのデバイス固有の形式にコンパイルするため、デバイスでの最初の実行は遅いです。次の実行はより速いです。
コアML実装の詳細については、PR#566を参照してください。
OpenVinoをサポートするプラットフォームでは、エンコーダー推論は、X86 CPUおよびIntel GPU(統合および離散)を含むOpenVinoサポートデバイスで実行できます。
これにより、エンコーダのパフォーマンスが大幅に高速化される可能性があります。 OpenVinoモデルを生成し、 whisper.cppで使用するための指示は次のとおりです。
まず、Python Virtual envをセットアップします。 Python依存関係をインストールします。 Python 3.10をお勧めします。
Windows:
cd models
python - m venv openvino_conv_env
openvino_conv_envScriptsactivate
python - m pip install -- upgrade pip
pip install - r requirements - openvino.txtLinuxとMacOS:
cd models
python3 -m venv openvino_conv_env
source openvino_conv_env/bin/activate
python -m pip install --upgrade pip
pip install -r requirements-openvino.txt OpenVinoエンコーダーモデルを生成します。たとえば、 base.enモデルを生成するには、以下を使用してください。
python convert-whisper-to-openvino.py --model base.en
これにより、GGML-Base.en-Encoder-Openvino.xml/.bin IRモデルファイルが生成されます。これらをggmlモデルと同じフォルダーに再配置することをお勧めします。これは、OpenVino拡張機能が実行時に検索するデフォルトの場所であるためです。
OpenVinoサポートを使用してwhisper.cpp構築します:
リリースページからOpenVinoパッケージをダウンロードします。使用する推奨バージョンは2023.0.0です。
開発システムにパッケージをダウンロードして抽出した後、SetupVarsスクリプトを調達することにより、必要な環境を設定します。例えば:
Linux:
source /path/to/l_openvino_toolkit_ubuntu22_2023.0.0.10926.b4452d56304_x86_64/setupvars.shWindows(CMD):
C:PathTow_openvino_toolkit_windows_2023. 0.0 . 10926. b4452d56304_x86_64 setupvars.bat次に、cmakeを使用してプロジェクトを構築します。
cmake -B build -DWHISPER_OPENVINO=1
cmake --build build -j --config Release通常どおり例を実行します。例えば:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
...
whisper_ctx_init_openvino_encoder: loading OpenVINO model from 'models/ggml-base.en-encoder-openvino.xml'
whisper_ctx_init_openvino_encoder: first run on a device may take a while ...
whisper_openvino_init: path_model = models/ggml-base.en-encoder-openvino.xml, device = GPU, cache_dir = models/ggml-base.en-encoder-openvino-cache
whisper_ctx_init_openvino_encoder: OpenVINO model loaded
system_info: n_threads = 4 / 8 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 | COREML = 0 | OPENVINO = 1 |
...
OpenVinoフレームワークがIR(中間表現)モデルをデバイス固有の「BLOB」にコンパイルするため、OpenVinoデバイスでの最初の実行は遅いです。このデバイス固有のブロブは、次の実行のためにキャッシュされます。
コアML実装の詳細については、PR#1037を参照してください。
NVIDIAカードを使用すると、モデルの処理は、CublasとカスタムCUDAカーネルを介してGPUで効率的に行われます。まず、 cuda :https://developer.nvidia.com/cuda-downloadsをインストールしていることを確認してください
ここで、cudaサポートでwhisper.cpp構築します:
make clean
GGML_CUDA=1 make -j
GPUのワークロードを加速できるクロスベンダーソリューション。まず、グラフィックカードドライバーがVulkan APIのサポートを提供していることを確認してください。
vulkanサポートでwhisper.cpp構築します:
make clean
make GGML_VULKAN=1 -j
エンコーダー処理は、Openblasを介してCPUで加速できます。まず、 openblasをインストールしていることを確認してください:https://www.openblas.net/
ここで、 whisper.cpp Openblasサポートで作成します。
make clean
GGML_OPENBLAS=1 make -j
エンコーダー処理は、IntelのMath KernelライブラリのBLAS互換インターフェイスを介してCPUで加速できます。まず、IntelのMKLランタイムと開発パッケージをインストールしていることを確認してください:https://www.intel.com/content/www/us/en/developer/tools/oneapi/onemkl-download.html
今度は、Intel MKL BLASサポートでwhisper.cpp構築します。
source /opt/intel/oneapi/setvars.sh
mkdir build
cd build
cmake -DWHISPER_MKL=ON ..
WHISPER_MKL=1 make -j
Ascend NPUは、 CANNおよびAIコアを介して推論加速を提供します。
まず、Ascend NPUデバイスがサポートされているかどうかを確認してください。
検証済みのデバイス
| NPUを上昇します | 状態 |
|---|---|
| ATLAS 300T A2 | サポート |
次に、 CANN toolkitインストールしていることを確認してください。 Cannの最後のバージョンが推奨されます。
ここで、cannサポートでwhisper.cpp構築します:
mkdir build
cd build
cmake .. -D GGML_CANN=on
make -j
例えば、通常どおり推論の例を実行します。
./build/bin/main -f samples/jfk.wav -m models/ggml-base.en.bin -t 8
注:
Verified devices更新を手伝ってください。 このプロジェクトで利用可能な2つのDocker画像があります。
ghcr.io/ggerganov/whisper.cpp:main :この画像には、メインの実行可能ファイルとcurlとffmpegが含まれています。 (プラットフォーム: linux/amd64 、 linux/arm64 )ghcr.io/ggerganov/whisper.cpp:main-cuda : mainと同じですが、CUDAサポートが編集されています。 (プラットフォーム: linux/amd64 ) # download model and persist it in a local folder
docker run -it --rm
-v path/to/models:/models
whisper.cpp:main " ./models/download-ggml-model.sh base /models "
# transcribe an audio file
docker run -it --rm
-v path/to/models:/models
-v path/to/audios:/audios
whisper.cpp:main " ./main -m /models/ggml-base.bin -f /audios/jfk.wav "
# transcribe an audio file in samples folder
docker run -it --rm
-v path/to/models:/models
whisper.cpp:main " ./main -m /models/ggml-base.bin -f ./samples/jfk.wav " Whisper.cpp用に事前に構築されたバイナリをインストールするか、Conanを使用してソースから作成できます。次のコマンドを使用します。
conan install --requires="whisper-cpp/[*]" --build=missing
コナンの使用方法に関する詳細な手順については、コナンのドキュメントを参照してください。
Macbook M1 Proで約30分で3:24分のスピーチmedium.en転写した別の例を示します。
$ ./main -m models/ggml-medium.en.bin -f samples/gb1.wav -t 8
whisper_init_from_file: loading model from 'models/ggml-medium.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 1024
whisper_model_load: n_audio_head = 16
whisper_model_load: n_audio_layer = 24
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 1024
whisper_model_load: n_text_head = 16
whisper_model_load: n_text_layer = 24
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 4
whisper_model_load: mem required = 1720.00 MB (+ 43.00 MB per decoder)
whisper_model_load: kv self size = 42.00 MB
whisper_model_load: kv cross size = 140.62 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 1462.35 MB
whisper_model_load: model size = 1462.12 MB
system_info: n_threads = 8 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/gb1.wav' (3179750 samples, 198.7 sec), 8 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:08.000] My fellow Americans, this day has brought terrible news and great sadness to our country.
[00:00:08.000 --> 00:00:17.000] At nine o'clock this morning, Mission Control in Houston lost contact with our Space Shuttle Columbia.
[00:00:17.000 --> 00:00:23.000] A short time later, debris was seen falling from the skies above Texas.
[00:00:23.000 --> 00:00:29.000] The Columbia's lost. There are no survivors.
[00:00:29.000 --> 00:00:32.000] On board was a crew of seven.
[00:00:32.000 --> 00:00:39.000] Colonel Rick Husband, Lieutenant Colonel Michael Anderson, Commander Laurel Clark,
[00:00:39.000 --> 00:00:48.000] Captain David Brown, Commander William McCool, Dr. Kultna Shavla, and Ilan Ramon,
[00:00:48.000 --> 00:00:52.000] a colonel in the Israeli Air Force.
[00:00:52.000 --> 00:00:58.000] These men and women assumed great risk in the service to all humanity.
[00:00:58.000 --> 00:01:03.000] In an age when space flight has come to seem almost routine,
[00:01:03.000 --> 00:01:07.000] it is easy to overlook the dangers of travel by rocket
[00:01:07.000 --> 00:01:12.000] and the difficulties of navigating the fierce outer atmosphere of the Earth.
[00:01:12.000 --> 00:01:18.000] These astronauts knew the dangers, and they faced them willingly,
[00:01:18.000 --> 00:01:23.000] knowing they had a high and noble purpose in life.
[00:01:23.000 --> 00:01:31.000] Because of their courage and daring and idealism, we will miss them all the more.
[00:01:31.000 --> 00:01:36.000] All Americans today are thinking as well of the families of these men and women
[00:01:36.000 --> 00:01:40.000] who have been given this sudden shock and grief.
[00:01:40.000 --> 00:01:45.000] You're not alone. Our entire nation grieves with you,
[00:01:45.000 --> 00:01:52.000] and those you love will always have the respect and gratitude of this country.
[00:01:52.000 --> 00:01:56.000] The cause in which they died will continue.
[00:01:56.000 --> 00:02:04.000] Mankind is led into the darkness beyond our world by the inspiration of discovery
[00:02:04.000 --> 00:02:11.000] and the longing to understand. Our journey into space will go on.
[00:02:11.000 --> 00:02:16.000] In the skies today, we saw destruction and tragedy.
[00:02:16.000 --> 00:02:22.000] Yet farther than we can see, there is comfort and hope.
[00:02:22.000 --> 00:02:29.000] In the words of the prophet Isaiah, "Lift your eyes and look to the heavens
[00:02:29.000 --> 00:02:35.000] who created all these. He who brings out the starry hosts one by one
[00:02:35.000 --> 00:02:39.000] and calls them each by name."
[00:02:39.000 --> 00:02:46.000] Because of His great power and mighty strength, not one of them is missing.
[00:02:46.000 --> 00:02:55.000] The same Creator who names the stars also knows the names of the seven souls we mourn today.
[00:02:55.000 --> 00:03:01.000] The crew of the shuttle Columbia did not return safely to earth,
[00:03:01.000 --> 00:03:05.000] yet we can pray that all are safely home.
[00:03:05.000 --> 00:03:13.000] May God bless the grieving families, and may God continue to bless America.
[00:03:13.000 --> 00:03:19.000] [Silence]
whisper_print_timings: fallbacks = 1 p / 0 h
whisper_print_timings: load time = 569.03 ms
whisper_print_timings: mel time = 146.85 ms
whisper_print_timings: sample time = 238.66 ms / 553 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 18665.10 ms / 9 runs ( 2073.90 ms per run)
whisper_print_timings: decode time = 13090.93 ms / 549 runs ( 23.85 ms per run)
whisper_print_timings: total time = 32733.52 ms
これは、マイクからオーディオでリアルタイム推論を実行する素朴な例です。ストリームツールは、半秒ごとにオーディオをサンプリングし、転写を継続的に実行します。詳細については、第10号で入手できます。
make stream -j
./stream -m ./models/ggml-base.en.bin -t 8 --step 500 --length 5000--print-colors引数を追加すると、実験的なカラーコーディング戦略を使用して転写されたテキストが印刷され、自信が高いか低い単語を強調します。
./main -m models/ggml-base.en.bin -f samples/gb0.wav --print-colors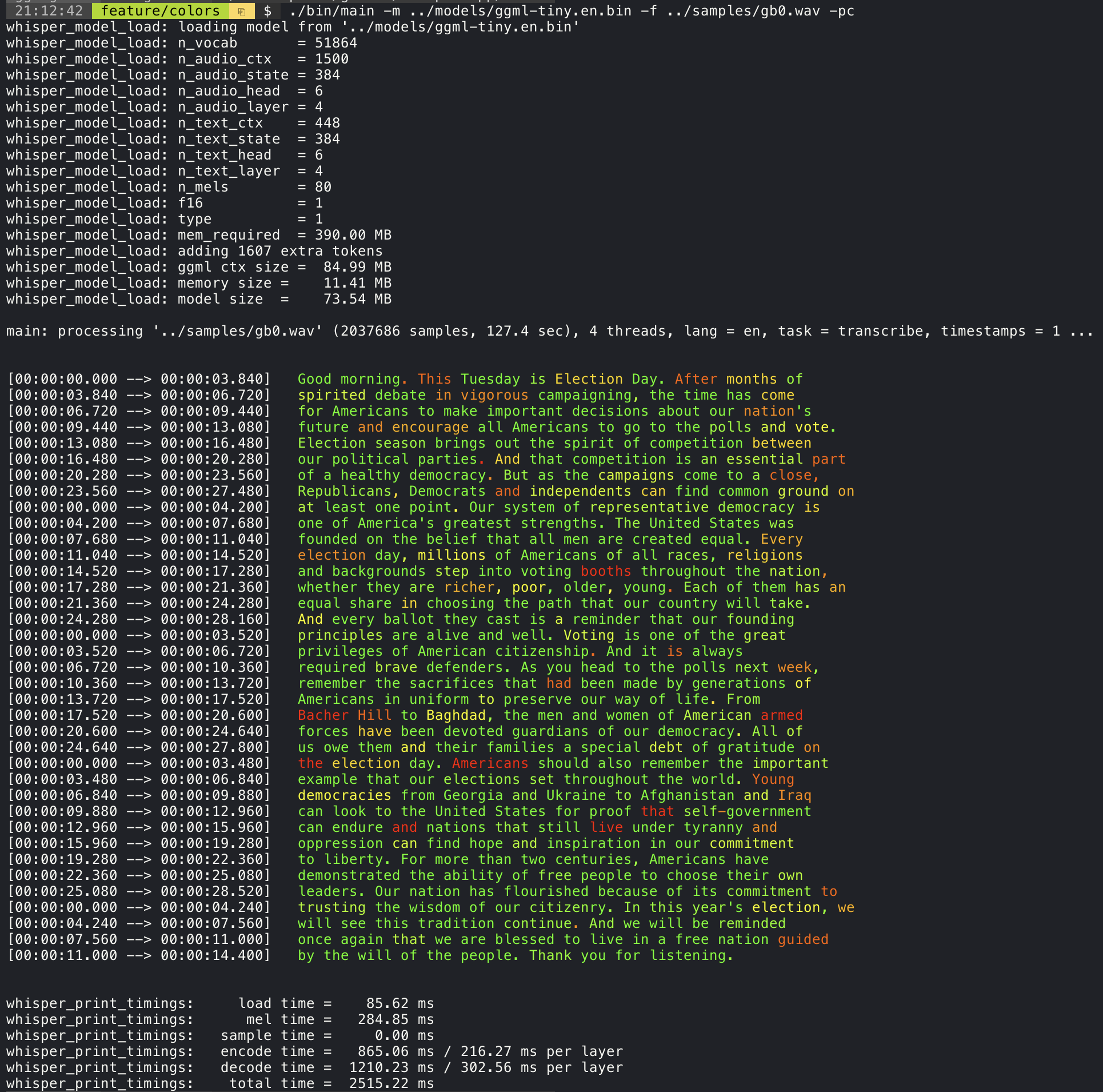
たとえば、ラインの長さを最大16文字に制限するには、 -ml 16を追加するだけです。
$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 16
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.850] And so my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:04.140] Americans, ask
[00:00:04.140 --> 00:00:05.660] not what your
[00:00:05.660 --> 00:00:06.840] country can do
[00:00:06.840 --> 00:00:08.430] for you, ask
[00:00:08.430 --> 00:00:09.440] what you can do
[00:00:09.440 --> 00:00:10.020] for your
[00:00:10.020 --> 00:00:11.000] country.
--max-len引数を使用して、単語レベルのタイムスタンプを取得できます。 -ml 1使用するだけです。
$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 1
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.320]
[00:00:00.320 --> 00:00:00.370] And
[00:00:00.370 --> 00:00:00.690] so
[00:00:00.690 --> 00:00:00.850] my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:02.850] Americans
[00:00:02.850 --> 00:00:03.300] ,
[00:00:03.300 --> 00:00:04.140] ask
[00:00:04.140 --> 00:00:04.990] not
[00:00:04.990 --> 00:00:05.410] what
[00:00:05.410 --> 00:00:05.660] your
[00:00:05.660 --> 00:00:06.260] country
[00:00:06.260 --> 00:00:06.600] can
[00:00:06.600 --> 00:00:06.840] do
[00:00:06.840 --> 00:00:07.010] for
[00:00:07.010 --> 00:00:08.170] you
[00:00:08.170 --> 00:00:08.190] ,
[00:00:08.190 --> 00:00:08.430] ask
[00:00:08.430 --> 00:00:08.910] what
[00:00:08.910 --> 00:00:09.040] you
[00:00:09.040 --> 00:00:09.320] can
[00:00:09.320 --> 00:00:09.440] do
[00:00:09.440 --> 00:00:09.760] for
[00:00:09.760 --> 00:00:10.020] your
[00:00:10.020 --> 00:00:10.510] country
[00:00:10.510 --> 00:00:11.000] .
このアプローチの詳細については、こちらをご覧ください:#1058
サンプルの使用法:
# download a tinydiarize compatible model
. / models / download - ggml - model . sh small . en - tdrz
# run as usual, adding the "-tdrz" command-line argument
. / main - f . / samples / a13 . wav - m . / models / ggml - small . en - tdrz . bin - tdrz
...
main : processing './samples/a13.wav' ( 480000 samples , 30.0 sec ), 4 threads , 1 processors , lang = en , task = transcribe , tdrz = 1 , timestamps = 1 ...
...
[ 00 : 00 : 00.000 - - > 00 : 00 : 03.800 ] Okay Houston , we ' ve had a problem here . [ SPEAKER_TURN ]
[ 00 : 00 : 03.800 - - > 00 : 00 : 06.200 ] This is Houston . Say again please . [ SPEAKER_TURN ]
[ 00 : 00 : 06.200 - - > 00 : 00 : 08.260 ] Uh Houston we ' ve had a problem .
[ 00 : 00 : 08.260 - - > 00 : 00 : 11.320 ] We ' ve had a main beam up on a volt . [ SPEAKER_TURN ]
[ 00 : 00 : 11.320 - - > 00 : 00 : 13.820 ] Roger main beam interval . [ SPEAKER_TURN ]
[ 00 : 00 : 13.820 - - > 00 : 00 : 15.100 ] Uh uh [ SPEAKER_TURN ]
[ 00 : 00 : 15.100 - - > 00 : 00 : 18.020 ] So okay stand , by thirteen we ' re looking at it . [ SPEAKER_TURN ]
[ 00 : 00 : 18.020 - - > 00 : 00 : 25.740 ] Okay uh right now uh Houston the uh voltage is uh is looking good um .
[ 00 : 00 : 27.620 - - > 00 : 00 : 29.940 ] And we had a a pretty large bank or so .主な例は、現在発音されている単語が強調表示されているカラオケスタイルの映画の出力をサポートしています。 -wts引数を使用して、生成されたbashスクリプトを実行します。これには、 ffmpegインストールする必要があります。
ここにいくつかの「典型的な」例があります:
./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -owts
source ./samples/jfk.wav.wts
ffplay ./samples/jfk.wav.mp4./main -m ./models/ggml-base.en.bin -f ./samples/mm0.wav -owts
source ./samples/mm0.wav.wts
ffplay ./samples/mm0.wav.mp4./main -m ./models/ggml-base.en.bin -f ./samples/gb0.wav -owts
source ./samples/gb0.wav.wts
ffplay ./samples/gb0.wav.mp4スクリプト/Bench-WTS.SHスクリプトを使用して、次の形式でビデオを生成します。
./scripts/bench-wts.sh samples/jfk.wav
ffplay ./samples/jfk.wav.all.mp4さまざまなシステム構成にわたる推論のパフォーマンスを客観的に比較するために、ベンチツールを使用します。このツールは、単にモデルのエンコーダー部分を実行し、実行するのにどれくらいの時間がかかったかを印刷します。結果は、次のGitHub問題にまとめられています。
ベンチマークの結果
さらに、さまざまなモデルとオーディオファイルを使用してwhisper.cppを実行するスクリプトがbench.pyを提供されます。
次のコマンドで実行できます。デフォルトでは、モデルフォルダーの標準モデルに対して実行されます。
python3 scripts/bench.py -f samples/jfk.wav -t 2,4,8 -p 1,2これは、ベンチマークのユースケースのために簡単に変更して拡張できることを意図して、Pythonで書かれています。
ベンチマークの結果とともにCSVファイルを出力します。
ggml形式元のモデルは、カスタムバイナリ形式に変換されます。これにより、必要なすべてを単一のファイルに詰めることができます。
モデル/ダウンロード-GGML-Model.shスクリプトを使用して、またはここから手動で変換されたモデルをダウンロードできます。
詳細については、変換スクリプトモデル/Convert-PT-to-Ggml.pyまたはModels/readme.mdを参照してください。
例フォルダーには、さまざまなプロジェクトにライブラリを使用するなど、さまざまな例があります。いくつかの例は、WebAssemblyを使用してブラウザで実行するように移植されています。それらをチェックしてください!
| 例 | ウェブ | 説明 |
|---|---|---|
| 主要 | whisper.wasm | ささやきを使用してオーディオを翻訳および転写するためのツール |
| ベンチ | Bench.wasm | マシンでささやきのパフォーマンスをベンチマークします |
| ストリーム | stream.wasm | 生のマイクキャプチャのリアルタイム転写 |
| 指示 | コマンドワム | マイクから音声コマンドを受信するための基本的な音声アシスタントの例 |
| wchess | wchess.wasm | 音声制御チェス |
| 話す | talk.wasm | GPT-2ボットと話してください |
| Talk-llama | ラマボットと話してください | |
| whisper.objc | whisper.cppを使用したiOSモバイルアプリケーション | |
| whisper.swiftui | whisper.cppを使用したswiftui ios / macosアプリケーション | |
| whisper.android | whisper.cppを使用したAndroidモバイルアプリケーション | |
| whisper.nvim | Neovimの音声からテキストへのプラグイン | |
| Generate-karaoke.sh | ヘルパースクリプト生のオーディオキャプチャのカラオケビデオを簡単に生成する | |
| livestream.sh | ライブストリームオーディオ転写 | |
| yt-wsp.sh | ダウンロード +転写および/またはVOD(オリジナル)の翻訳 | |
| サーバ | OAIのようなAPIを備えたHTTP転写サーバー |
このプロジェクトについて何らかのフィードバックがある場合は、ディスカッションセクションを使用して新しいトピックを開きます。ショーアンドテルカテゴリを使用して、 whisper.cpp使用する独自のプロジェクトを共有できます。質問がある場合は、よくある質問(#126)のディスカッションを確認してください。


