リポジトリは、Pytorchに実装され、MNISTデータセットで訓練されたVQ-VAEで構成されています。
VQ-Vaeは、変分自動エンコーダー(VAE)の背後と同じ基本概念に従います。 VQ-VAEは、変分自動エンコーダーに個別の潜在埋め込みを使用します。つまり、Z(潜在ベクトル)の各寸法は、入力をエンコードする際に一般的に使用される連続正規分布ではなく、離散整数です。
Vaesは3つの部分で構成されています。
さて、VQ-Vaesがテーブルにもたらす違いについて尋ねることができます。それらをリストしましょう:
多くの重要な現実世界のオブジェクトは個別です。たとえば、「猫」、「車」などのカテゴリがあるかもしれませんが、これらのカテゴリを補間することは意味がないかもしれません。離散表現もモデル化しやすいです。
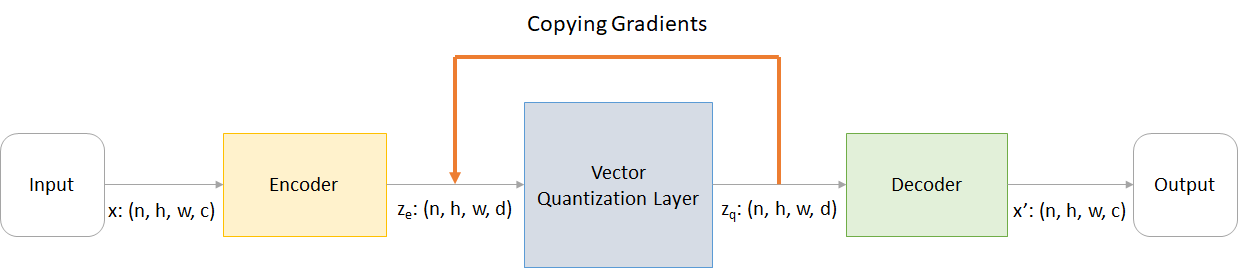
どこ:
n :バッチサイズh :画像の高さw :画像幅c :入力画像のチャネルの数d :隠された状態のチャネルの数VQ-Vaeネットワークの動作の簡単な概要を次に示します。
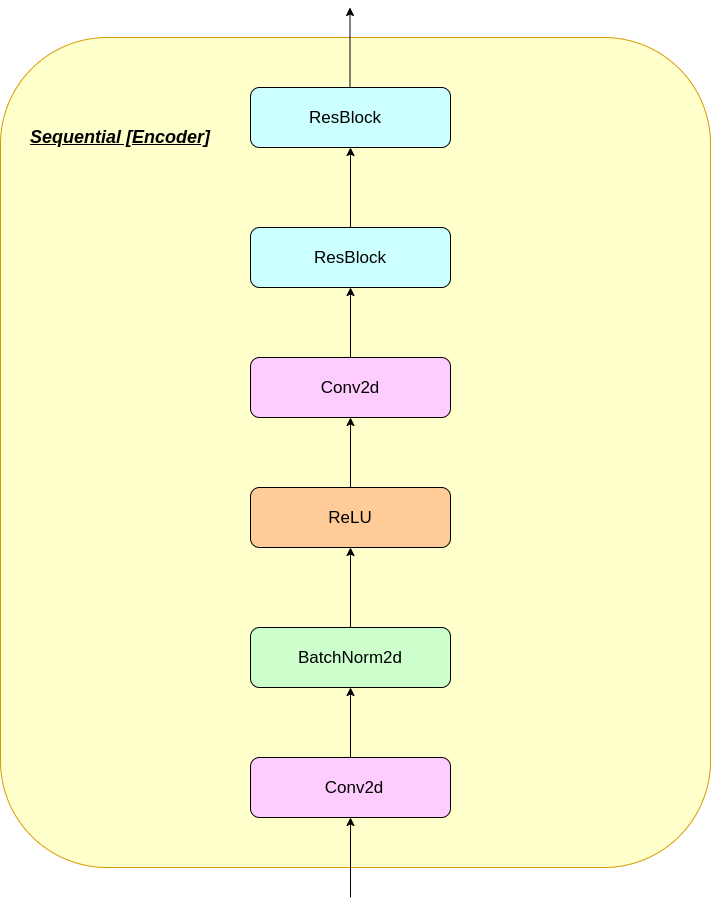
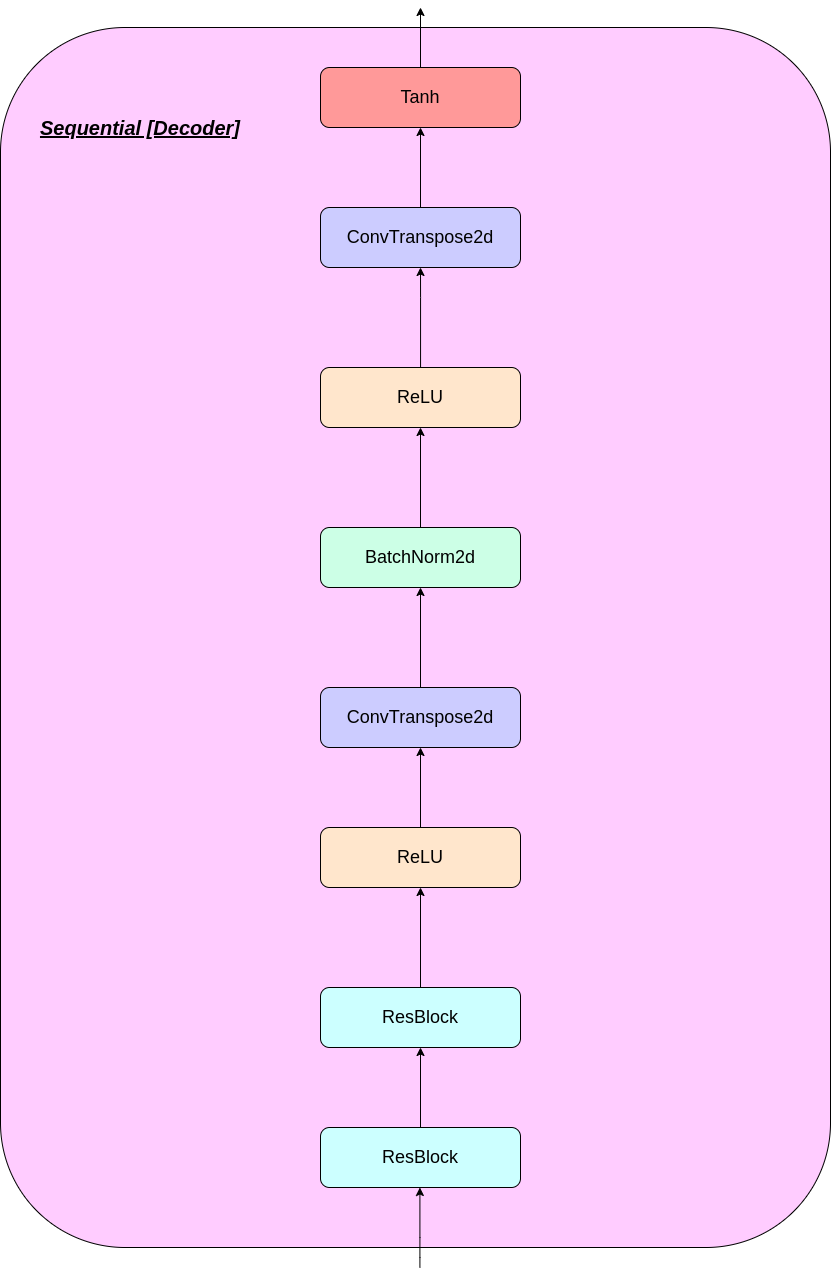
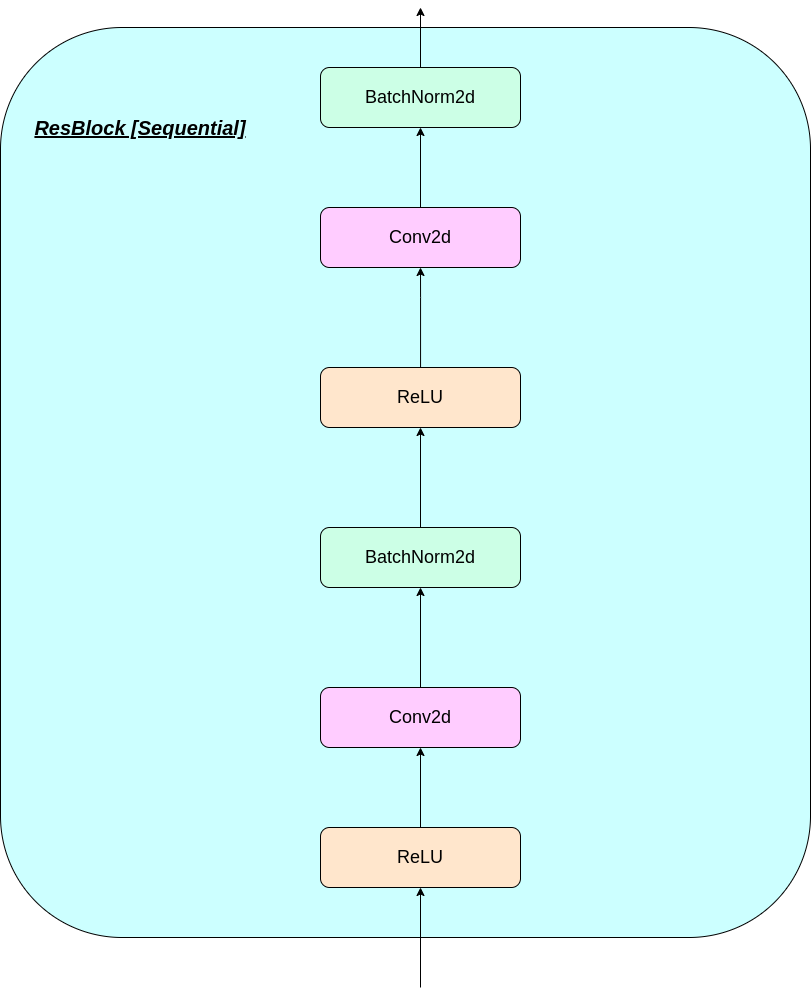
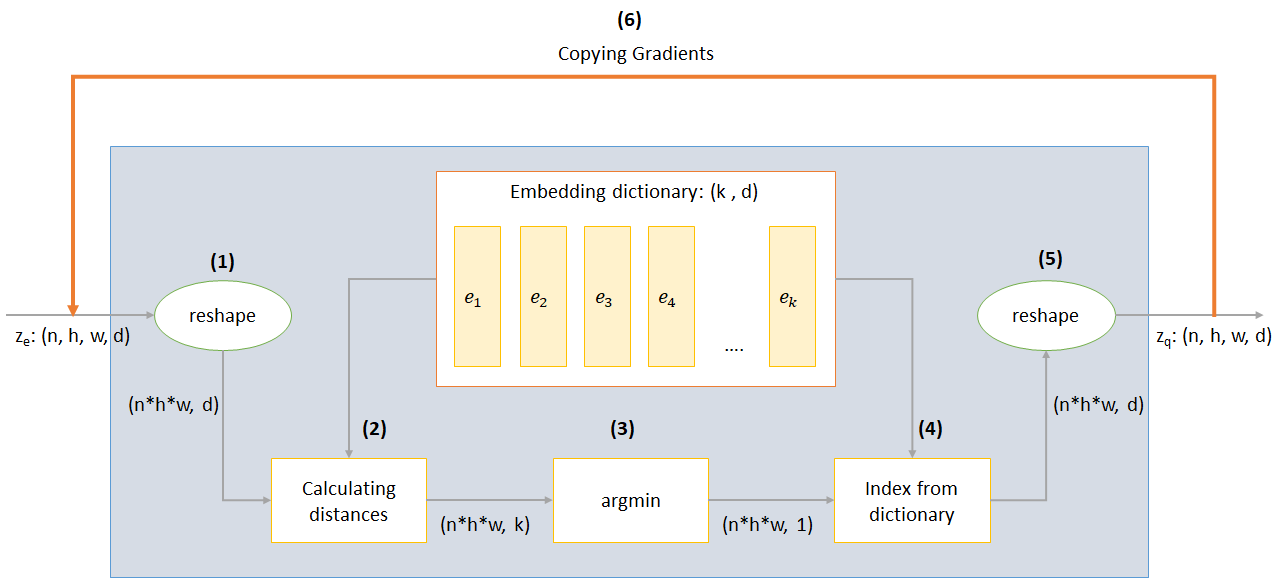
VQレイヤーの動作は、図に番号が付けられているように、6つのステップで説明できます。
VQ-Vaeは3つの損失を使用して、トレーニング中の総損失を計算します。
再構築損失:デコーダーとエンコーダーをVAEとして最適化します。つまり、入力画像と再構成の違いを最適化します。
reconstruction_loss = -log( p(x|z_q) )
コードブックの損失:勾配が埋め込みをバイパスするという事実により、 L2エラーを使用して埋め込みベクターE_Iをエンコーダー出力に移動する辞書学習アルゴリズムが使用されます。
codebook_loss = ‖ sg[z_e(x)]− e ‖^2
(SGは、適用されているものは何でも勾配が流れないことを意味する停止勾配演算子を表します)
コミットメントの損失:埋め込みスペースのボリュームは無次元であるため、埋め込みe_iがエンコーダーパラメーターほど速く訓練しない場合、エンコーダーが埋め込みにコミットすることを確認するためにコミットメントの損失が追加されます。
commitment_loss = β‖ z_e(x)− sg[e] ‖^2
(βは、他のコンポーネントと比較してコミットメントの損失を比較検討したい量を制御するハイパーパラメーターです)
CMDプロンプトで以下を実行して、レポをダウンロードするか、クローンを作成できます
https://github.com/praeclarumjj3/VQ-VAE-on-MNIST.git
次のコマンドでモデルをゼロからトレーニングできます(Google Colab)
! python3 VQ-VAE.py --output-folder [NAME_OF_OUTPUT_FOLDER] --data-folder [PATH_TO_MNIST_dataset] --device ['cpu' or 'cuda' ] --hidden-size [SIZE] --k [NUMBER] --batch-size [BATCH_SIZE] --num_epoch [NUMBER_OF_EPOCHS] --lr [LEARNING_RATE] --beta [VALUE] --num-workers [NUMBER_OF_WORKERS]
output-folder - データフォルダーの名前data-folder - データフォルダーの名前device - デバイスを設定します(CPUまたはCUDA、デフォルト:CPU)hidden-size - 潜在ベクトルのサイズ(デフォルト:40)k潜在ベクトルの数(デフォルト:512)batch-size - バッチサイズ(デフォルト:128)num-epochsエポックの数(デフォルト:10)lr -Adam Optimizerの学習率(デフォルト:2E -4)beta - 0.1〜2.0のコミットメント損失の貢献(デフォルト:1.0)num-workers軌跡のサンプリングの労働者の数(デフォルト:cpu_count() - 1)このプログラムは、Mnistデータセットを自動的にダウンロードし、 PATH_TO_MNIST_datasetフォルダーに保存します(このフォルダーを作成する必要があります)。これは一度だけ起こります。
また、 logsフォルダーとmodelsフォルダーを作成し、その内部には、ログとモデルチェックポイントをそれぞれ保存するために名前が渡されたフォルダーを作成します。
ユニットのガウスからランダムにサンプリングされたZから新しい画像を生成するには、次のコマンドを実行します(Google Colabで):
! python3 generate.py --model [SAVED_MODEL_FILENAME] --input [MNIST_or_random] --device ['cpu' or 'cuda' ] --hidden-size [SIZE] --k [NUMBER] --filename [SAVING_NAME]
model - モデルを含むファイル名input -Mnistまたはランダムdevice - デバイスを設定します(CPUまたはCUDA、デフォルト:CPU)hidden-size - 潜在ベクトルのサイズ(デフォルト:40)k潜在ベクトルの数(デフォルト:512)filename保存するファイルの名前generatedImagesという名前のフォルダーに保存されている画像の10*10グリッドを生成します。
model.txtのリンクからダウンロードすることにより、事前に訓練されたモデルを使用できます。
リポジトリには、次のファイルが含まれています
modules.pyモデルの作成に使用されるさまざまなモジュールが含まれていますVQ-VAE.py VQ-Vaeモデルをトレーニングするための関数とコードが含まれていますvector_quantizer.pyベクトル量子化クラスはこのファイルで定義されていますgenerate-py事前に訓練されたモデルから新しい画像を生成しますmodel.txt事前に訓練されたモデルへのリンクが含まれていますREADME.md -readmeリポジトリの概要を示していますreferences.txtこのレポを作成中に使用される参照readme_images readme用のさまざまな画像がありますMNISTジップされたMNISTデータセットが含まれています(ただし、必要に応じて自動的にダウンロードされます)Training track for VQ-VAE.txt - VQ-Vaeモデルのトレーニング中に損失値が含まれていますlogs_VQ-VAE VQ-Vaeモデル用のジップテンソルボードログが含まれています(プログラムによって自動的に作成されました)testers.py定義されたモジュールをテストするためのいくつかの関数が含まれていますTensorboardを実行するコマンド(Google Colab):
%load_ext tensorboard
%tensordboard --logdir [path_to_folder_with_logs]
トレーニング画像
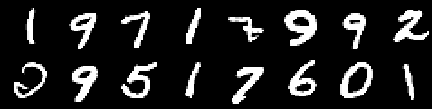
0番目のエポックからの画像

第2エポックからの画像
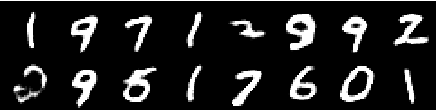
第4時代の画像
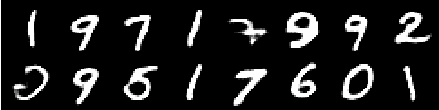
第6時代の画像
8番目のエポックからの画像
10番目のエポックからの画像
再構成は改善を続け、最後に損失値に反映されるトレーニング_set画像にほぼ似ています( Training track for VQ-VAE.txtをチェックします)。
再建損失
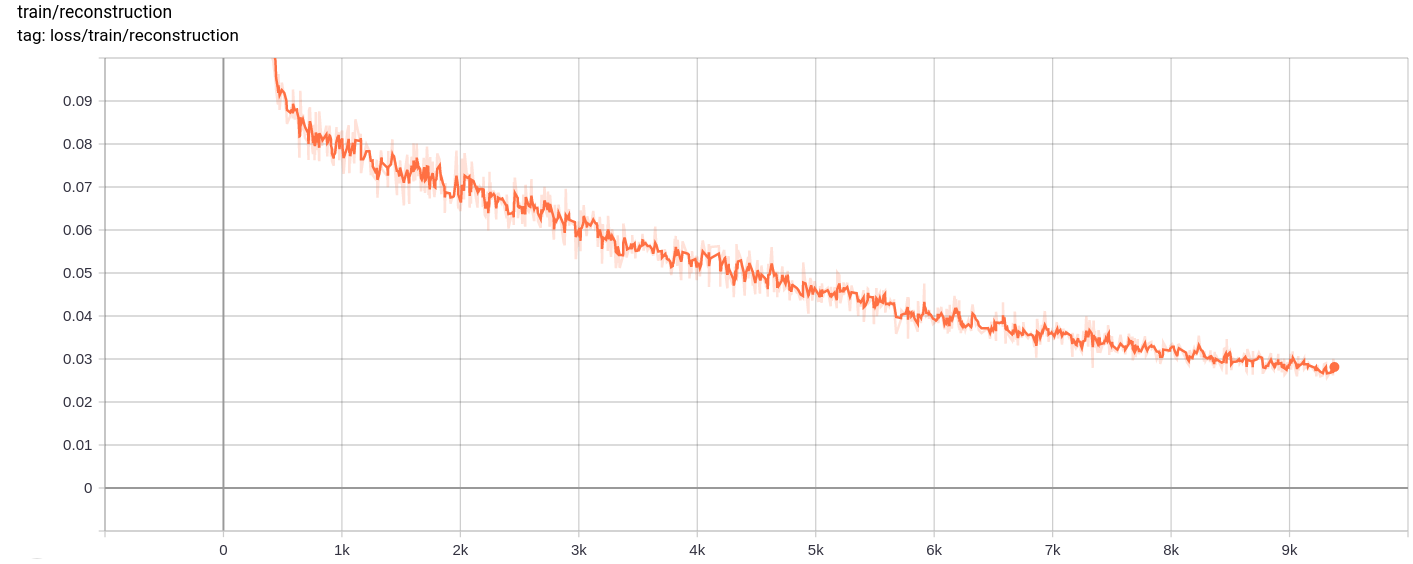
量子化損失
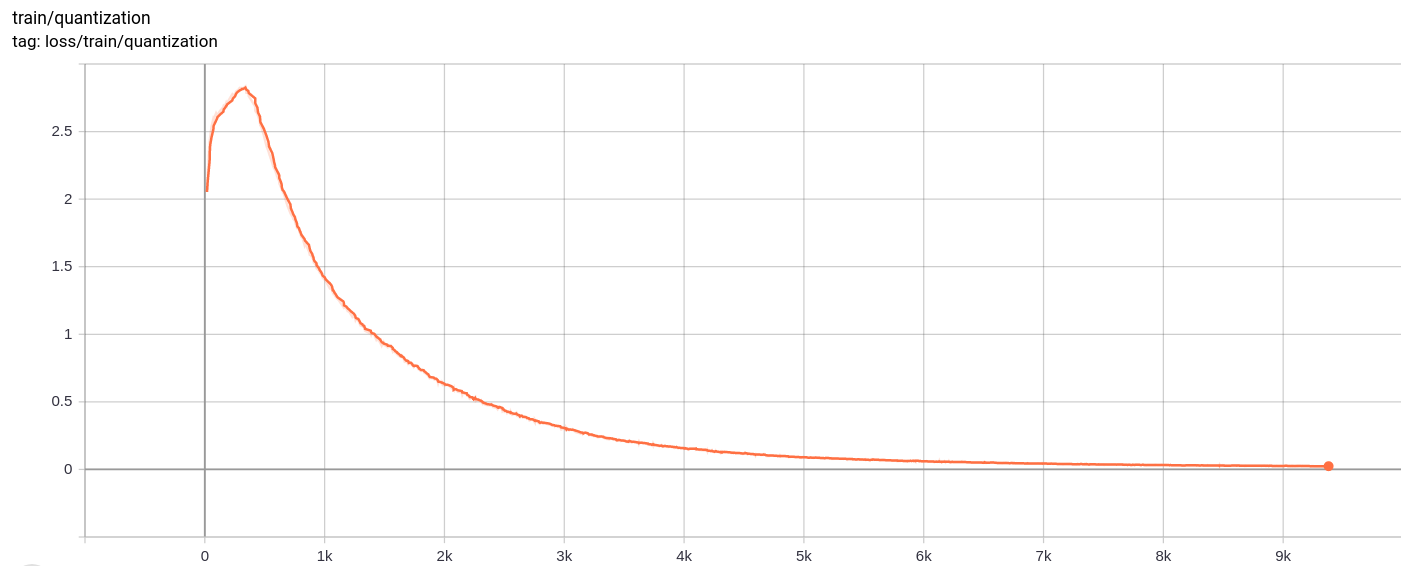
Total_loss
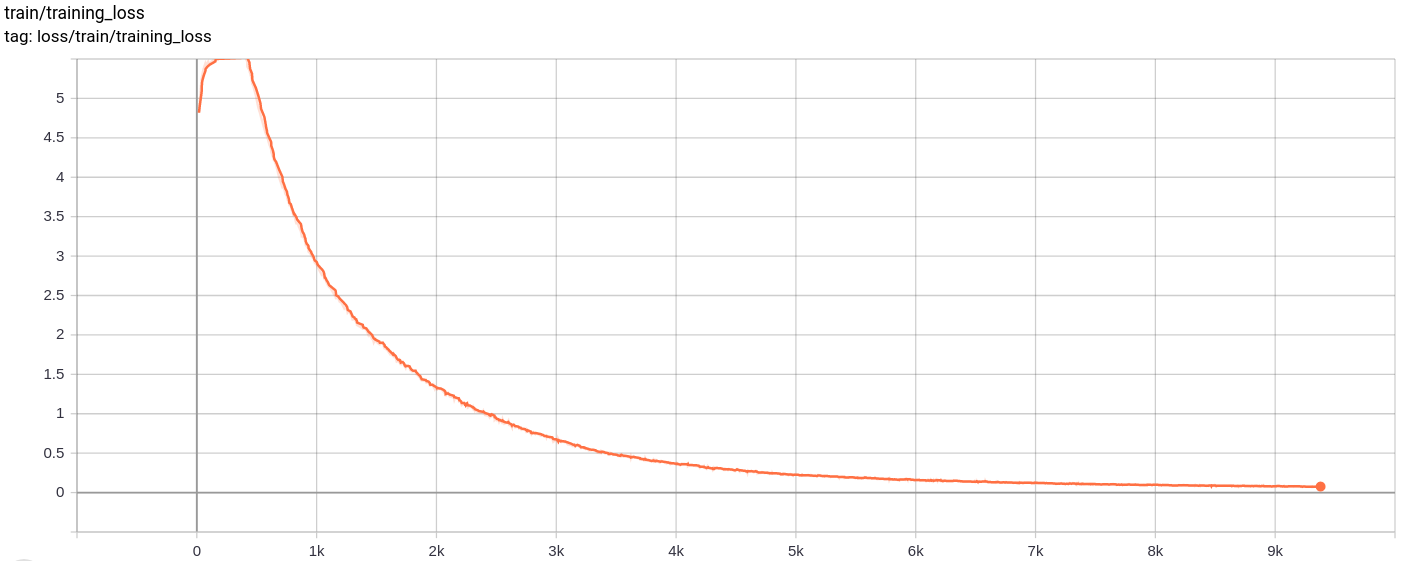
総損失、再建損失、量子化損失は、予想どおり均一に減少します。
testing_loss
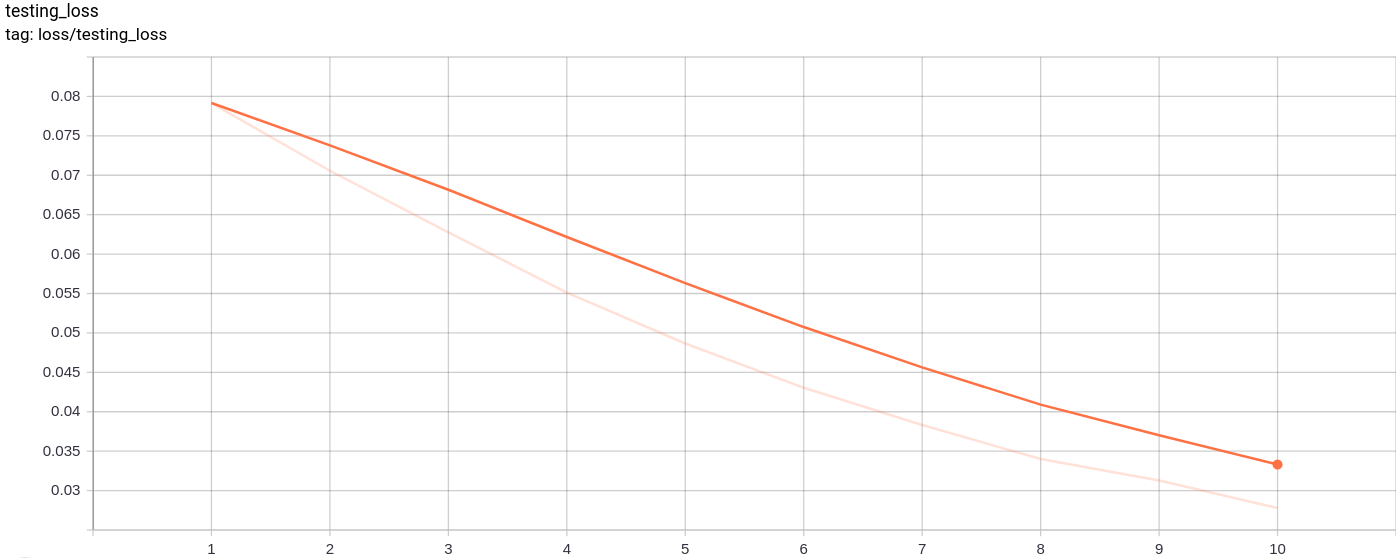
テスト損失は、予想どおり均一に減少します。
次の画像グリッドは、MNIST画像を入力として渡した後に生成されました。

世代はかなり良いです。
次の画像グリッドは、モデルへの入力としてユニットガウスからランダムにサンプリングされたAZを渡した後に生成され、デコーダーを通過しました


画像は完璧に見えません。潜在スペースの寸法を調整する、ベクターの埋め込みの数などは、より良いランダム画像を生成するのに役立ちます。
このモデルは、バッチサイズ128の10エポックでGoogle Colabでトレーニングされました。
トレーニング後、モデルは入力画像を非常にうまく再構築することができ、生成された画像はあまり良くありませんが、新しい画像を生成することもできました。
トレーニングとテストの損失も、ほぼ単調に減少し続けました。
10〜20以上のエポックのモデルをトレーニングすると、モデルに過剰留まる可能性のある兆候が示唆された結果が得られることを観察しました。また、LatedNT空間のさまざまな寸法を実験し、最終的なdimension = 40で最良の結果を生み出しました。ディメンションに最適な範囲は16〜42になりました。
次の情報源は、このリポジトリを作るのに大いに役立ちました


