REST APIを開発して、SEQ2SEQモデルを使用して機械翻訳を実行します。モデルの展開は、Google Canプラットフォームを使用して行われます。
プロジェクトは次のように作成されます:
このプロジェクトのデータは、データソースのテキストファイルとして入手できます。各行には、カンナダに文があり、スペースデリミタを使用して英語で翻訳します。ランダムにランダムに検証して、各例が理にかなっていることを確認しました。
最初に、Gru RNNを使用した注意メカニズムを使用して、エンコーダデコーダーモデルを構築します。トレーニングは、ここで入手可能なPythonスクリプトを使用して行われました
アドレスhttp://127.0.0.1:5000/predictでローカルマシンからアクセスできるフラスコアプリケーションを構築します。
スクリプトを使用してモデルをトレーニングします。モデルをトレーニングした後、モデルの重みを.ptファイルに保存し、Googleクラウドストレージに保存します。また、各単語を数字にインデックス化して漬けて、語彙辞書を構築します。これらのピクルスファイルは、ストレージファイルにも保存されます。これらのファイルが設置されたら、ここにアクセスできます。以下の手順に従って展開を実行できます
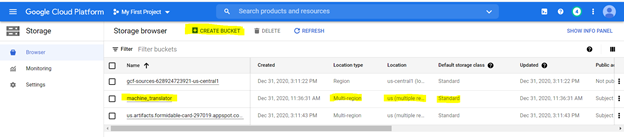
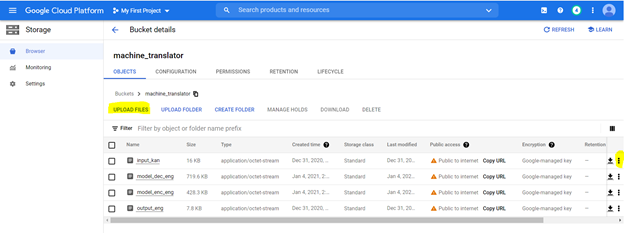
ストレージバケットにファイルをアップロードします。次の仕様で強調表示されているように、次のオプションを使用してバケツを作成するには
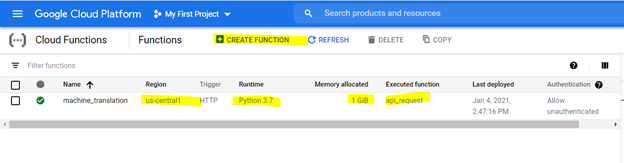
クラウド関数を作成するには、GCPプラットフォームでそれを参照し、以下に強調表示されているオプションを使用して関数を作成します。
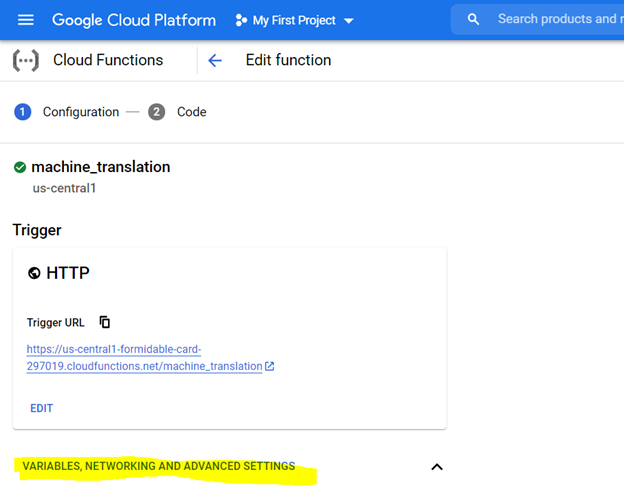
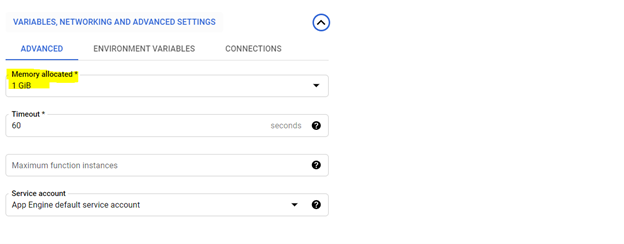
*1つのGIBメモリの割り当てをお勧めします。設定したら、[次へ]をクリックして、クラウド関数コンソールにコードを展開します。
コードを展開するには、まず以下の強調表示された設定でコンソールを構成し、要件ファイルを使用して環境を準備します(これは以下に説明するPIPインストールに相当します)、
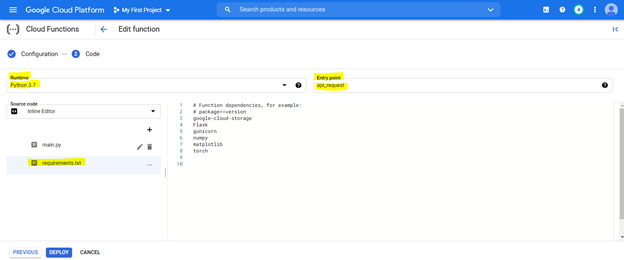
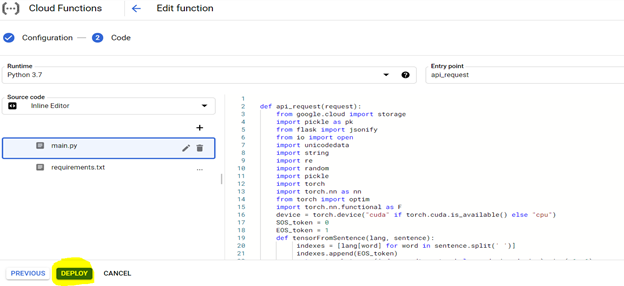

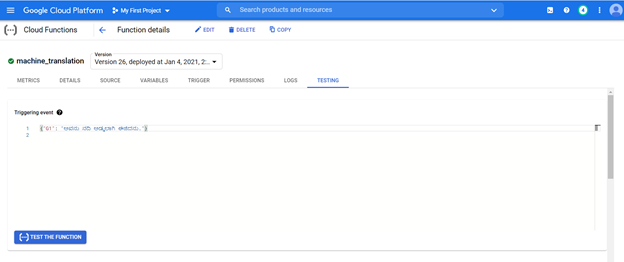

展開されたモデルには、任意のシステムからURLからアクセスして、カンナダ文を英語に変換できます。


