
グラフ上のクロスドメインクロスタスクファンデーションモデルであるGFTの公式実装。ロゴはDall・E 3によって生成されます。
Zehong Wang、Zheyuan Zhang、Nitesh v Chawla、Chuxu Zhang、Yanfang Yeが執筆。
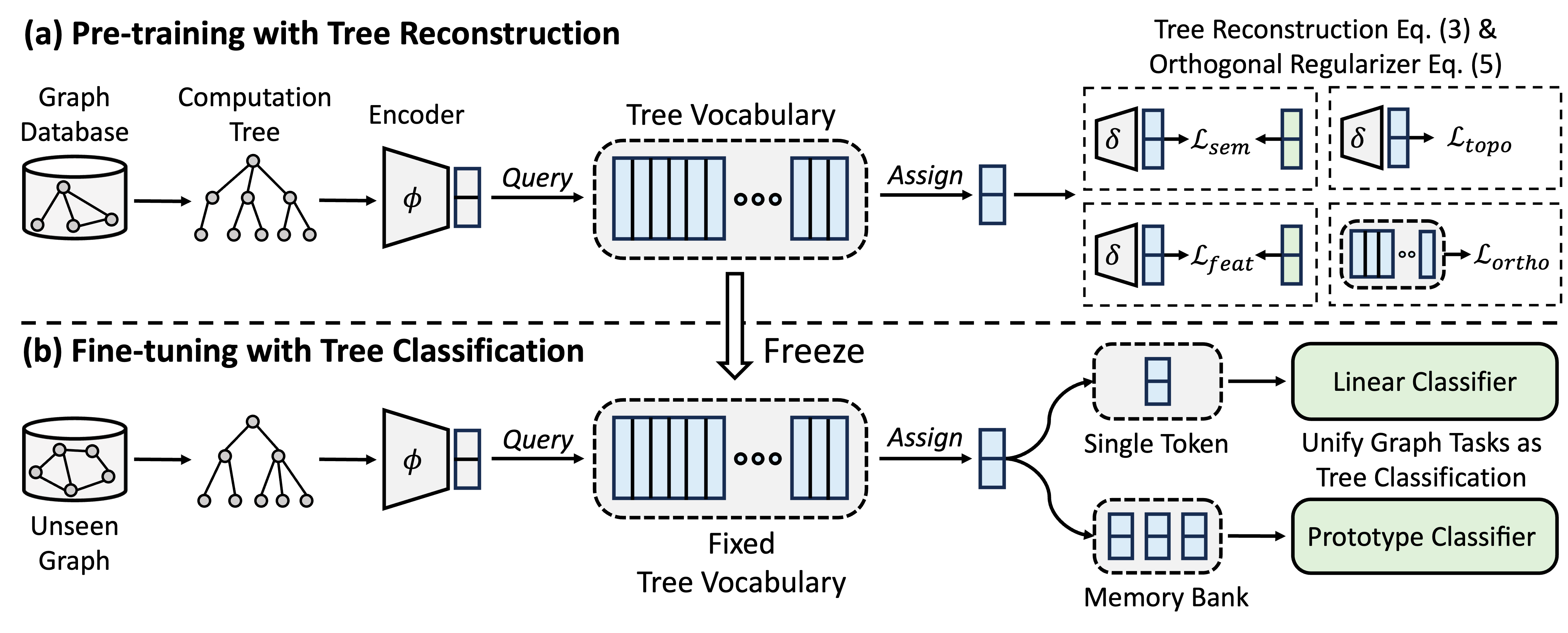
GFTはクロスドメインとクロスタスクグラフファンデーションモデルであり、計算ツリーを転送可能なパターンとして扱い、転送可能なツリーの語彙を取得します。さらに、GFTは、グラフ関連のタスクを調整するための統一されたフレームワークを提供し、単一のグラフモデル(GNN)がノードレベル、エッジレベル、およびグラフレベルのタスクを共同で処理できるようにします。
トレーニング前に、モデルはグラフデータベースからツリー再構成タスクを介してツリーの語彙に一般的な知識をエンコードします。微調整では、学習したツリーの語彙が適用され、グラフ関連のタスクをツリー分類タスクとして統合し、取得した一般的な知識を特定のタスクに適応させます。
環境をインストールするためにコンドラを使用できます。次のスクリプトを実行してください。すべての実験を単一のA40 48G GPUで実行しますが、24Gメモリを備えたGPUでは、すべてのデータセットをミニバッチで処理するのに十分です。
conda env create -f environment.yml
conda activate GFT
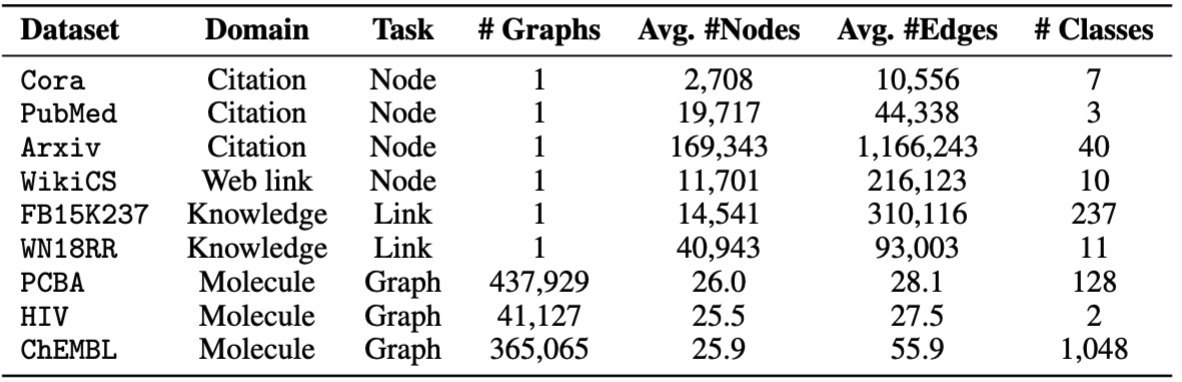
OFAが提供するデータセットを使用します。 pretrain.py実行して、デフォルトで/dataフォルダーにダウンロードされるデータセットを自動的にダウンロードできます。パイプラインは、テキストの説明をテキスト埋め込みに変換することにより、データセットを自動的に前処理します。
または、 /dataフォルダーに前処理されたデータセットとUNZIPをダウンロードすることもできます。
GFTのコードは、フォルダー/GFTに表示されます。構造は次のとおりです。
└── GFT
├── pretrain.py
├── finetune.py
├── dataset
│ ├── ...
│ └── process_datasets.py
├── model
│ ├── encoder.py
│ ├── vq.py
│ ├── pt_model.py
│ └── ft_model.py
├── task
│ ├── node.py
│ ├── link.py
│ └── graph.py
└── utils
├── args.py
├── loader.py
└── ...
基本的な微調整または少数の学習を備えた特定のダウンストリームタスクに適応するために、広範囲のグラフとfinetune.pyで前pretrain.py実行することができます。
結果を再現するために、それぞれconfig/pretrain.yamlとconfig/finetune.yamlで維持されている、事前トレーニングとFinetuningの両方の詳細なハイパーパラメーターを提供します。デフォルトのハイパーパラメーターを活用するために、プレトレインとFinetuneの両方にコマンド--use_paramsを提供します。
# Pretraining with default hyper-parameters
python GFT/pretrain.py --use_params
# Finetuning on Cora with default hyper-parameters
python GFT/finetune.py --use_params --dataset cora
# Few-shot learning on Cora with default hyper-parameters
python GFT/finetune.py --use_params --dataset cora --setting few_shot
Finetuningには、 cora 、 pubmed 、 wikics 、 arxiv 、 WN18RR 、 FB15K237 、 chemhiv 、 chempcbaなどの8つのデータセットを提供します。
または、スクリプトを実行して実験を再現することもできます。
# Pretraining with default hyper-parameters
sh script/pretrain.sh
# Finetuning on all datasets with default hyper-parameters
sh script/finetune.sh
# Few-shot learning on all datasets with default hyper-parameters
sh script/few_shot.sh
注:延期されたモデルは、デフォルトでckpts/pretrain_model/に保存されます。
# The basic command for pretraining GFT
python GFT/pretrain.py
pretrain.py実行すると、事前削除データセットとハイパーパラメーターをカスタマイズできます。
--pretrain_dataset (or --pt_data )を使用して、使用されているプレレインデータセットと対応する重みを設定できます。事前定義されたデータ構成は、次の構造を備えたconfig/pt_data.yamlにあります。
all:
cora: 5
pubmed: 5
arxiv: 5
wikics: 5
WN18RR: 5
FB15K237: 10
chemhiv: 1
chemblpre: 0.1
chempcba: 0.1
...
上記の場合、 all設定の名前であり、つまり、すべてのデータセットが事前トレーニングで使用されています。各データセットには、キー価値のペアがあり、キーはデータセット名で、値はサンプリング重量です。たとえば、 cora: 5 、 coraデータセットが単一のエポックで5回サンプリングされることを意味します。 GFTを前処理するための独自のデータセットの組み合わせを設計できます。
エンコーダー、ベクトル量子化、モデルトレーニングのハイパーパラメーターを変更することにより、事前トレーニングフェーズをカスタマイズできます。
--pretrain_dataset :事前削除データセットを示します。上記と同じです。--use_params :事前に定義されたハイパーパラメーターを使用します。--seed :事前トレーニングに使用される種子。--hidden_dim :GNNSの隠された層の寸法。--num_layers :GNNレイヤー。--activation :活性化関数。--backbone :バックボーンGNN。--normalize :正規化レイヤー。--dropout :GNNレイヤーのドロップアウト。--code_dim :語彙の各コードの次元。--codebook_size :語彙のコードの数。--codebook_head :コードブックの長の数。数値が1より大きい場合、複数の語彙を共同で使用します。--codebook_decay :コードの減衰率。--commit_weight :コミットメント期間の重み。--pretrain_epochs :エポックの数。--pretrain_lr :学習率。--pretrain_weight_decay :L2 Reglemalizerの重量。--pretrain_batch_size :バッチサイズ。--feat_p :機能の破損率。--edge_p :エッジ/構造の破損率。--topo_recon_ratio :エッジの比率を再構築する必要があります。--feat_lambda :機能損失の重み。--topo_lambda :トポロジ損失の重量。--topo_sem_lambda :再構成エッジの特徴におけるトポロジ損失の重み。--sem_lambda :セマンティック損失の重み。--sem_encoder_decay :セマンティックエンコーダのモメンタム更新レート。 # The basic command for adapting GFT on downstream tasks via finetuning.
python GFT/finetune.py
--dataset設定して下流のデータセットを示すことができ、 --use_params各データセットに事前に定義されたハイパーパラメーターを使用します。あなたが示すことができる他のハイパーパラメーターは、次のように示されています。
1つの事前定義された分割を持つグラフの場合、複数の実験を行うために--repeat設定できます。
--hidden_dim :GNNSの隠された層の寸法。--num_layers :GNNレイヤー。--activation :活性化関数。--backbone :バックボーンGNN。--normalize :正規化レイヤー。--dropout :GNNレイヤーのドロップアウト。--code_dim :語彙の各コードの次元。--codebook_size :語彙のコードの数。--codebook_head :コードブックの長の数。数値が1より大きい場合、複数の語彙を共同で使用します。--codebook_decay :コードの減衰率。--commit_weight :コミットメント期間の重み。--finetune_epochs :エポックの数。--finetune_lr :学習率。--early_stop :最大早期停止エポック。--batch_size :0に設定されている場合は、完全なグラフトレーニングを実施します。--lambda_proto :Finetuningにおけるプロトタイプ分類器の重量。
--lambda_act :Finetuningの線形分類器の重み。
--trade_off :プロトタイプClassierを使用するか、推論で線形分類器を使用することとのトレードオフ。
--no_lin_clfまたは--no_proto_clfを追加して、それぞれ線形分類器またはプロトタイプ分類子を使用しないようにします。注意してください。少なくとも1つの分類子を使用する必要があるため、これらの2つの用語は競合です。
# The basic command for adaptation GFT on downstream tasks via few-shot learning.
python GFT/finetune.py --setting few_shot
--dataset設定してダウンストリームデータセットを示すことができ、 --use_params各データセットに事前に定義されたハイパーパラメーターを使用します。あなたが示すことができる他のハイパーパラメーターは、次のように示されています。
少数のショット学習に専念するハイパーパラメーターはそうです
--n_train :モデルを微調整するためのクラスごとのトレーニングインスタンスの数。 Small n_train望ましいパフォーマンスを達成することに注意してください--n_task :サンプリングされたタスクの数。--n_way :方法の数。--n_query :Wayごとにクエリセットのサイズ。--n_shot :ウェイごとのサポートセットのサイズ。--hidden_dim :GNNSの隠された層の寸法。--num_layers :GNNレイヤー。--activation :活性化関数。--backbone :バックボーンGNN。--normalize :正規化レイヤー。--dropout :GNNレイヤーのドロップアウト。--code_dim :語彙の各コードの次元。--codebook_size :語彙のコードの数。--codebook_head :コードブックの長の数。数値が1より大きい場合、複数の語彙を共同で使用します。--codebook_decay :コードの減衰率。--commit_weight :コミットメント期間の重み。--finetune_epochs :エポックの数。--finetune_lr :学習率。--early_stop :最大早期停止エポック。--batch_size :0に設定されている場合は、完全なグラフトレーニングを実施します。--lambda_proto :Finetuningにおけるプロトタイプ分類器の重量。
--lambda_act :Finetuningの線形分類器の重み。
--trade_off :プロトタイプClassierを使用するか、推論で線形分類器を使用することとのトレードオフ。
--no_lin_clfまたは--no_proto_clfを追加して、それぞれ線形分類器またはプロトタイプ分類子を使用しないようにします。注意してください。少なくとも1つの分類子を使用する必要があるため、これらの2つの用語は競合です。
実験結果は、前oraining前のランダム化初期化により異なる場合があります。ランダム初期化の潜在的な影響を示すために、事前化中の異なるランダムシード(つまり、1-5)を使用して実験結果を提供します。
| コラ | PubMed | wiki-cs | arxiv | WN18RR | FB15K237 | HIV | PCBA | 平均 | |
|---|---|---|---|---|---|---|---|---|---|
| シード= 1 | 78.58±0.90 | 77.55±1.54 | 79.38±0.57 | 72.24±0.16 | 91.56±0.33 | 89.67±0.35 | 72.69±1.93 | 78.24±0.23 | 79.99 |
| シード= 2 | 78.27±1.26 | 76.41±1.36 | 79.36±0.62 | 72.13±0.24 | 91.72±0.19 | 89.66±0.31 | 71.62±2.45 | 78.20±0.33 | 79.67 |
| シード= 3 | 78.16±1.62 | 76.28±1.37 | 79.32±0.65 | 72.13±0.30 | 91.57±0.44 | 89.78±0.23 | 71.58±2.28 | 78.12±0.37 | 79.62 |
| シード= 4 | 78.42±1.37 | 75.76±1.58 | 79.44±0.62 | 72.36±0.34 | 91.70±0.24 | 89.73±0.21 | 72.57±2.46 | 78.34±0.27 | 79.79 |
| シード= 5 | 78.56±1.62 | 76.49±2.00 | 79.27±0.55 | 72.18±0.26 | 91.47±0.39 | 89.80±0.19 | 72.27±0.93 | 78.31±0.34 | 79.79 |
| 報告されています | 78.62±1.21 | 77.19±1.99 | 79.39±0.42 | 71.93±0.12 | 91.91±0.34 | 89.72±0.20 | 72.67±1.38 | 77.90±0.64 | 79.92 |
再現性をより適切に確保するために、このリンクでシード= 1のチェックポイントを提供します。平均パフォーマンスが最も得られるため、これを選択します。 Path ckpts/pretrain_model/でダウンロードしたファイルを解凍し、 finetune.py使用して提供されたチェックポイントを繊細に活用するときに--pt_seed 1設定できます。
[email protected]に連絡するか、質問がある場合は問題を開きます。
リポジトリが研究に役立つ場合は、元の論文を適切に引用してください。
@inproceedings { wang2024gft ,
title = { GFT: Graph Foundation Model with Transferable Tree Vocabulary } ,
author = { Wang, Zehong and Zhang, Zheyuan and Chawla, Nitesh V and Zhang, Chuxu and Ye, Yanfang } ,
booktitle = { The Thirty-eighth Annual Conference on Neural Information Processing Systems } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=0MXzbAv8xy }
}このリポジトリは、OFA、PYG、OGB、およびVQのコードベースに基づいています。共有してくれてありがとう!


