flash attention
v2.7.0
このリポジトリは、次の論文からFlashattentionとFlashattention-2の公式実装を提供します。
Flashattention:IO認識を伴う高速およびメモリ効率の高い正確な注意
Tri Dao、Daniel Y. Fu、Stefano Ermon、Atri Rudra、ChristopherRé
論文:https://arxiv.org/abs/2205.14135
Flashattentionを使用したMLPERF 2.0ベンチマークへの提出に関するIEEEスペクトル記事。 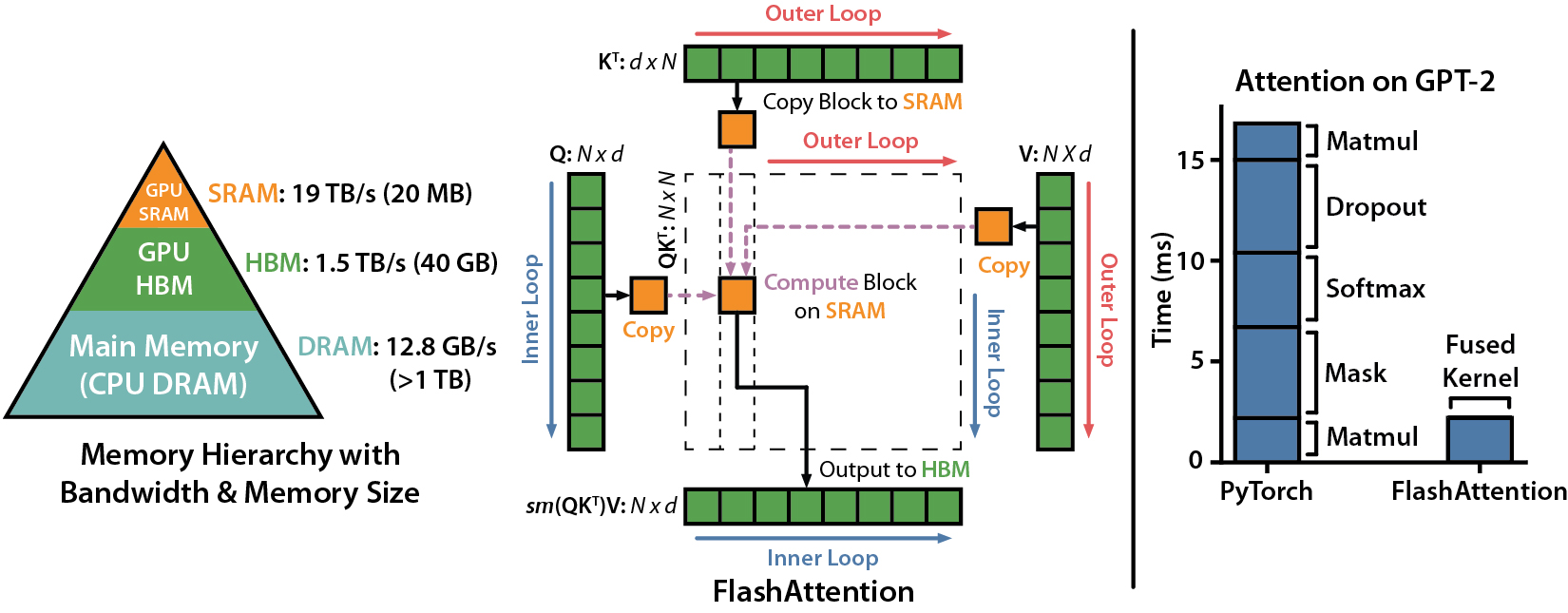
Flashattention-2:より良い並列処理と作業分割により、より速い注意
トライダオ
論文:https://tridao.me/publications/flash2/flash2.pdf

Flashattentionがリリース後すぐに広く採用されていることを非常に嬉しく思います。このページには、Flashattentionが使用されている場所の部分的なリストが含まれています。
FlashattentionとFlashattention-2は自由に使用および変更できます(ライセンスを参照)。 Flashattentionを使用する場合は、引用してクレジットしてください。
Flashattention-3は、Hopper GPU(H100など)に最適化されています。
blogpost:https://tridao.me/blog/2024/flash3/
論文:https://tridao.me/publications/flash3/flash3.pdf
これは、それを残りのリポジトリと統合する前に、テスト /ベンチマークのベータリリースです。
現在リリース:
要件:H100 / H800 GPU、CUDA> = 12.3。
今のところ、最高のパフォーマンスにはCuda 12.3を強くお勧めします。
インストールするには:
cd hopper
python setup.py installテストを実行するには:
export PYTHONPATH= $PWD
pytest -q -s test_flash_attn.py要件:
packaging Pythonパッケージ( pip install packaging )ninja Pythonパッケージ( pip install ninja ) * * ninjaがインストールされ、それが正しく機能することを確認してください(例: ninja --version then echo $?出口コード0を返す必要があります)。そうでない場合( ninja --version 、 echo $?非ゼロ出口コードを返すこともあります)、アンインストールしてからninja ( pip uninstall -y ninja && pip install ninja )を再インストールします。 ninjaがなければ、コンパイルは複数のCPUコアを使用しないため、非常に長い時間(2H)かかることがあります。 ninjaコンパイルを使用すると、CUDAツールキットを使用して64コアマシンで3〜5分かかります。
インストールするには:
pip install flash-attn --no-build-isolationまたは、ソースからコンパイルできます。
python setup.py installマシンに96GB未満のRAMと多くのCPUコアがある場合、 ninja RAMの量を使い果たす可能性のある並列コンピレーションジョブが多すぎる可能性があります。並列コンピレーションジョブの数を制限するには、環境変数MAX_JOBSを設定できます。
MAX_JOBS=4 pip install flash-attn --no-build-isolationインターフェイス: src/flash_attention_interface.py
要件:
Flashattentionをインストールするために必要なすべてのツールを備えたNvidiaのPytorchコンテナをお勧めします。
CUDAのFlashattention-2は現在サポートしています。
ROCMバージョンは、composable_kernelをバックエンドとして使用します。 Flashattention-2の実装を提供します。
要件:
ROCMのPytorchコンテナをお勧めします。ROCMには、Flashattentionをインストールするために必要なすべてのツールがあります。
ROCMを使用したFlashattention-2は現在サポートしています。
メイン関数は、スケーリングされたDOT製品の注意を実装しています(softMax(q @ k^t * softmax_scale) @ v):
from flash_attn import flash_attn_qkvpacked_func , flash_attn_func flash_attn_qkvpacked_func ( qkv , dropout_p = 0.0 , softmax_scale = None , causal = False ,
window_size = ( - 1 , - 1 ), alibi_slopes = None , deterministic = False ):
"""dropout_p should be set to 0.0 during evaluation
If Q, K, V are already stacked into 1 tensor, this function will be faster than
calling flash_attn_func on Q, K, V since the backward pass avoids explicit concatenation
of the gradients of Q, K, V.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between [i - window_size[0], i + window_size[1]] inclusive.
Arguments:
qkv: (batch_size, seqlen, 3, nheads, headdim)
dropout_p: float. Dropout probability.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of (-alibi_slope * |i - j|) is added to
the attention score of query i and key j.
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
which is slightly slower and uses more memory. The forward pass is always deterministic.
Return:
out: (batch_size, seqlen, nheads, headdim).
""" flash_attn_func ( q , k , v , dropout_p = 0.0 , softmax_scale = None , causal = False ,
window_size = ( - 1 , - 1 ), alibi_slopes = None , deterministic = False ):
"""dropout_p should be set to 0.0 during evaluation
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
Arguments:
q: (batch_size, seqlen, nheads, headdim)
k: (batch_size, seqlen, nheads_k, headdim)
v: (batch_size, seqlen, nheads_k, headdim)
dropout_p: float. Dropout probability.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
is added to the attention score of query i and key j.
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
which is slightly slower and uses more memory. The forward pass is always deterministic.
Return:
out: (batch_size, seqlen, nheads, headdim).
""" def flash_attn_with_kvcache (
q ,
k_cache ,
v_cache ,
k = None ,
v = None ,
rotary_cos = None ,
rotary_sin = None ,
cache_seqlens : Optional [ Union [( int , torch . Tensor )]] = None ,
cache_batch_idx : Optional [ torch . Tensor ] = None ,
block_table : Optional [ torch . Tensor ] = None ,
softmax_scale = None ,
causal = False ,
window_size = ( - 1 , - 1 ), # -1 means infinite context window
rotary_interleaved = True ,
alibi_slopes = None ,
):
"""
If k and v are not None, k_cache and v_cache will be updated *inplace* with the new values from
k and v. This is useful for incremental decoding: you can pass in the cached keys/values from
the previous step, and update them with the new keys/values from the current step, and do
attention with the updated cache, all in 1 kernel.
If you pass in k / v, you must make sure that the cache is large enough to hold the new values.
For example, the KV cache could be pre-allocated with the max sequence length, and you can use
cache_seqlens to keep track of the current sequence lengths of each sequence in the batch.
Also apply rotary embedding if rotary_cos and rotary_sin are passed in. The key @k will be
rotated by rotary_cos and rotary_sin at indices cache_seqlens, cache_seqlens + 1, etc.
If causal or local (i.e., window_size != (-1, -1)), the query @q will be rotated by rotary_cos
and rotary_sin at indices cache_seqlens, cache_seqlens + 1, etc.
If not causal and not local, the query @q will be rotated by rotary_cos and rotary_sin at
indices cache_seqlens only (i.e. we consider all tokens in @q to be at position cache_seqlens).
See tests/test_flash_attn.py::test_flash_attn_kvcache for examples of how to use this function.
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
If causal=True, the causal mask is aligned to the bottom right corner of the attention matrix.
For example, if seqlen_q = 2 and seqlen_k = 5, the causal mask (1 = keep, 0 = masked out) is:
1 1 1 1 0
1 1 1 1 1
If seqlen_q = 5 and seqlen_k = 2, the causal mask is:
0 0
0 0
0 0
1 0
1 1
If the row of the mask is all zero, the output will be zero.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
Note: Does not support backward pass.
Arguments:
q: (batch_size, seqlen, nheads, headdim)
k_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no block_table,
or (num_blocks, page_block_size, nheads_k, headdim) if there's a block_table (i.e. paged KV cache)
page_block_size must be a multiple of 256.
v_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no block_table,
or (num_blocks, page_block_size, nheads_k, headdim) if there's a block_table (i.e. paged KV cache)
k [optional]: (batch_size, seqlen_new, nheads_k, headdim). If not None, we concatenate
k with k_cache, starting at the indices specified by cache_seqlens.
v [optional]: (batch_size, seqlen_new, nheads_k, headdim). Similar to k.
rotary_cos [optional]: (seqlen_ro, rotary_dim / 2). If not None, we apply rotary embedding
to k and q. Only applicable if k and v are passed in. rotary_dim must be divisible by 16.
rotary_sin [optional]: (seqlen_ro, rotary_dim / 2). Similar to rotary_cos.
cache_seqlens: int, or (batch_size,), dtype torch.int32. The sequence lengths of the
KV cache.
block_table [optional]: (batch_size, max_num_blocks_per_seq), dtype torch.int32.
cache_batch_idx: (batch_size,), dtype torch.int32. The indices used to index into the KV cache.
If None, we assume that the batch indices are [0, 1, 2, ..., batch_size - 1].
If the indices are not distinct, and k and v are provided, the values updated in the cache
might come from any of the duplicate indices.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
rotary_interleaved: bool. Only applicable if rotary_cos and rotary_sin are passed in.
If True, rotary embedding will combine dimensions 0 & 1, 2 & 3, etc. If False,
rotary embedding will combine dimensions 0 & rotary_dim / 2, 1 & rotary_dim / 2 + 1
(i.e. GPT-NeoX style).
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
is added to the attention score of query i and key j.
Return:
out: (batch_size, seqlen, nheads, headdim).
"""これらの関数がマルチヘッドの注意層(QKV投影、出力投影を含む)でどのように使用されているかを確認するには、MHAの実装を参照してください。
Flashattention(1.x)からFlashattention-2へのアップグレード
これらの関数は名前が付けられています。
flash_attn_unpadded_func > flash_attn_varlen_funcflash_attn_unpadded_qkvpacked_func > flash_attn_varlen_qkvpacked_funcflash_attn_unpadded_kvpacked_func > flash_attn_varlen_kvpacked_func入力が同じバッチで同じシーケンスの長さを持っている場合、これらの機能を使用するのはよりシンプルで高速です。
flash_attn_qkvpacked_func ( qkv , dropout_p = 0.0 , softmax_scale = None , causal = False ) flash_attn_func ( q , k , v , dropout_p = 0.0 , softmax_scale = None , causal = False )seqlen_q!= seqlen_kおよび因果関係= trueの場合、因果マスクは、左上コーナーの代わりに、注意マトリックスの右下隅に並べられます。
たとえば、seqlen_q = 2およびseqlen_k = 5の場合、因果マスク(1 =キープ、0 =マスクアウト)は次のとおりです。
V2.0:
1 0 0 0 0
1 1 0 0 0
v2.1:
1 1 1 1 0
1 1 1 1 1
seqlen_q = 5およびseqlen_k = 2の場合、因果マスクは次のとおりです。
V2.0:
1 0
1 1
1 1
1 1
1 1
v2.1:
0 0
0 0
0 0
1 0
1 1
マスクの行がすべてゼロの場合、出力はゼロになります。
クエリのシーケンス長が非常に小さい場合(例:クエリシーケンス長= 1)、推論(反復デコード)に最適化します。ここのボトルネックは、できるだけ速くKVキャッシュをロードすることであり、結果を結合するために別のカーネルでさまざまなスレッドブロックに負荷を分割します。
関数flash_attn_with_kvcacheを参照してください。推論のためのより多くの機能(ロータリー埋め込み、KVキャッシュの更新を実行します)。
このコラボレーションをしてくれたXformersチーム、特にDaniel Hazizaに感謝します。
スライドウィンドウの注意を実装します(つまり、局所的な注意)。 Mistral AI、特にこの貢献についてTimothéeLacroixに感謝します。スライドウィンドウは、Mistral 7Bモデルで使用されました。
Alibiを実装します(Press et al。、2021)。この貢献についてカカオ・ブレインのサングン・チョーに感謝します。
決定論的なバックワードパスを実装します。この貢献についてMeituanのエンジニアに感謝します。
Paged KVキャッシュ(つまり、Pagedattention)をサポートします。この貢献をしてくれた@beginlnerに感謝します。
Gemma-2およびGROKモデルで使用されるように、ソフトキャッピングで注意をサポートします。この貢献について@narsilと@lucidrainsに感謝します。
この貢献について @ANI300に感謝します。
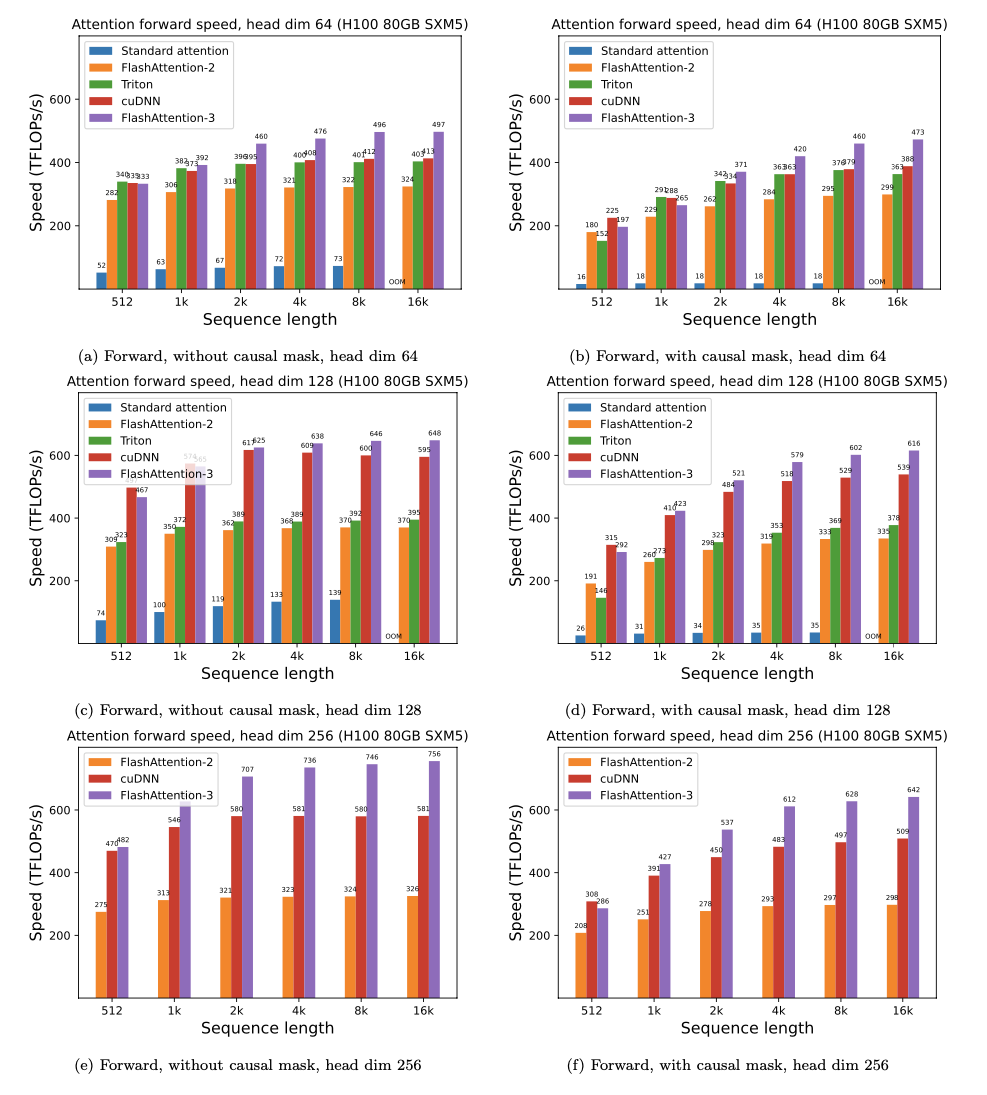
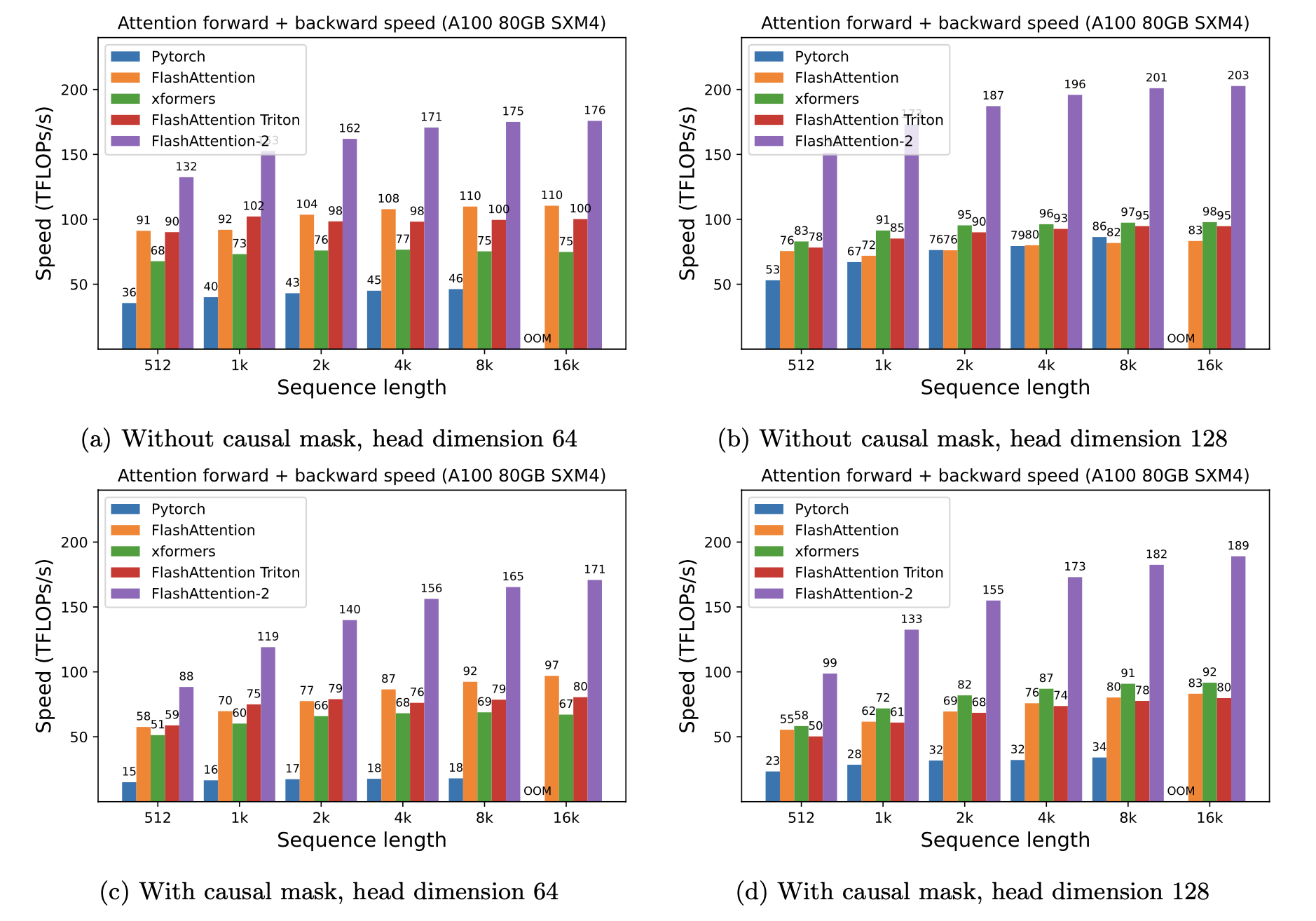
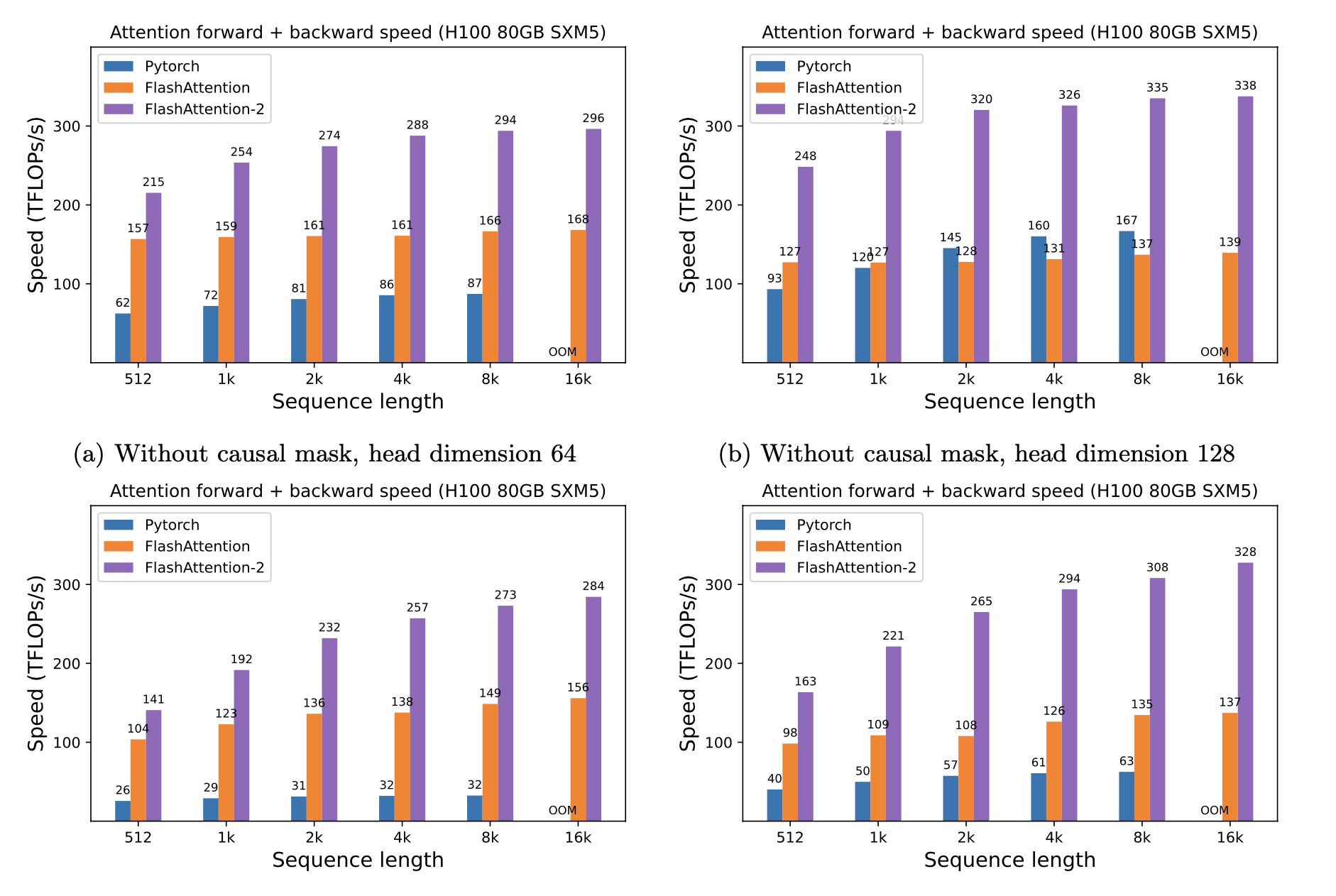
予想されるスピードアップ(フォワード +バックワードパスを組み合わせて)と、シーケンスの長さに応じて、Pytorch標準の注意に対するフラッシュアットを使用することによるメモリの節約は、異なるGPU(メモリ帯域幅に依存します - より遅いGPUメモリでより多くのスピードアップが表示されます)。
現在、これらのGPUのベンチマークがあります。
これらのパラメーターを使用してフラッシュアッテンションのスピードアップを表示します。
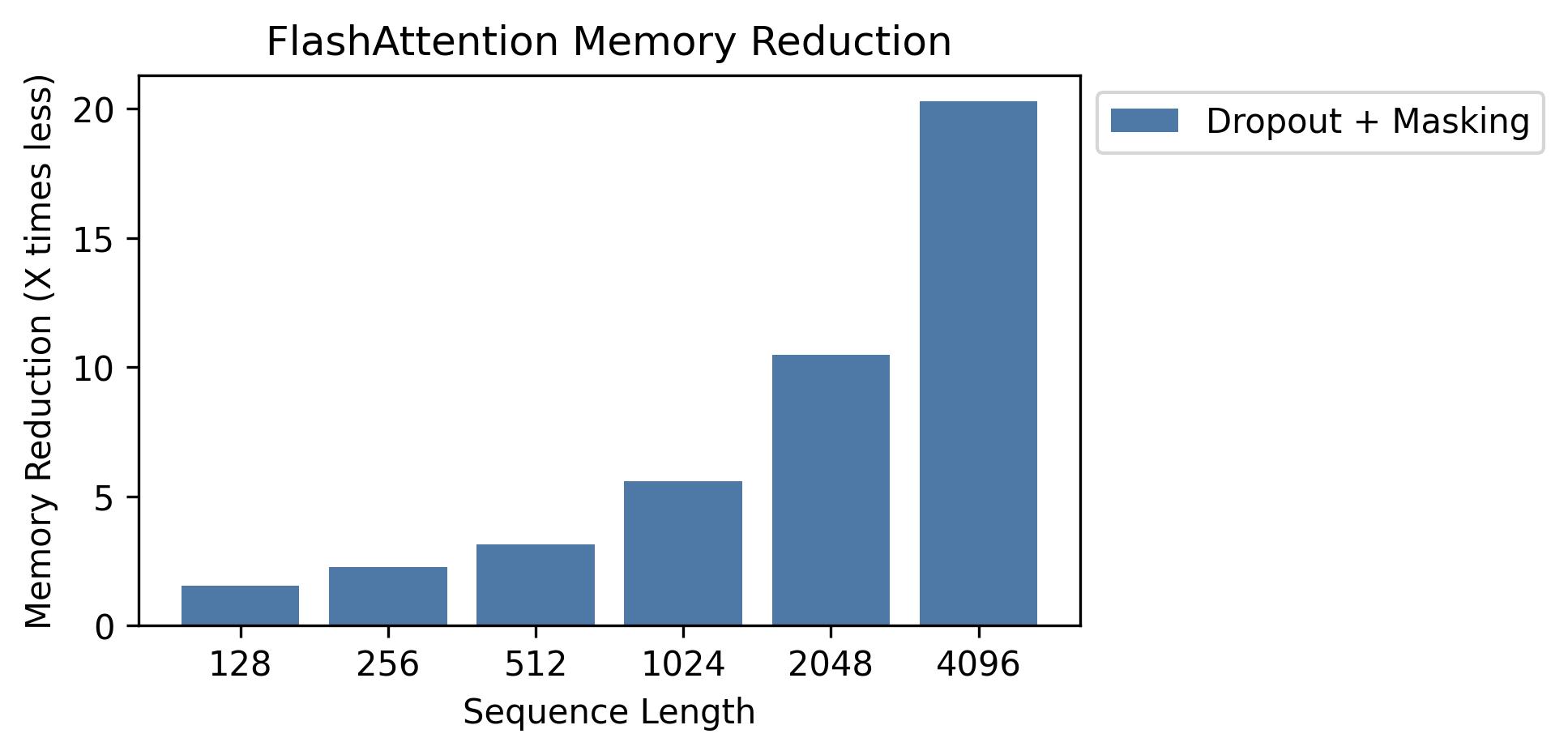
このグラフにメモリの節約が表示されます(ドロップアウトやマスキングを使用しても、メモリフットプリントは同じであることに注意してください)。メモリの節約はシーケンスの長さに比例します - 標準的な注意のメモリはシーケンスの長さが二次的であるため、フラッシュ放送のメモリはシーケンスの長さが線形です。シーケンスの長さ2Kで10倍のメモリの節約、4Kで20xが見られます。その結果、Flashattentionは、より長いシーケンスの長さまでスケーリングできます。
完全なGPTモデルの実装をリリースしました。また、他のレイヤーの最適化された実装(MLP、Layernorm、交差エントロピー損失、回転埋め込み)も提供します。全体として、これにより、Huggingfaceからのベースラインの実装と比較してトレーニングが3〜5倍になり、A100あたり最大225 TFLOPS/SECに達します。
また、OpenWebtextでGPT2を訓練し、杭でGPT3をトレーニングするトレーニングスクリプトも含めます。
Phil Tuchet(Openai)は、Tritonでフラッシュアットの実験的実装を持っています:https://github.com/openai/triton/blob/master/python/tutorials/06-fused-attention.py
TritonはCUDAよりも高レベルの言語であるため、理解して実験する方が簡単かもしれません。 Tritonの実装の表記は、私たちの論文で使用されているものに近いものでもあります。
また、Tritonで注意バイアス(Alibiなど)をサポートする実験的実装もあります:https://github.com/dao-ailab/flash-attention/blob/main/flash_attn/flash_attn.py
Flashattentionは、数値耐性まで、参照実装と同じ出力と勾配を生成することをテストします。特に、Flashattentionの最大数値誤差は、Pytorchのベースライン実装の数値誤差の最大2倍であることを確認します(異なるヘッド寸法、入力DTYPE、シーケンス長、因果 /非因果関係)。
テストを実行するには:
pytest -q -s tests/test_flash_attn.pyFlashattention-2のこの新しいリリースは、主にA100 GPUでいくつかのGPTスタイルモデルでテストされています。
バグが発生した場合は、GitHubの問題を開いてください!
テストを実行するには:
pytest tests/test_flash_attn_ck.pyこのコードベースを使用する場合、または他の方法で私たちの作品が価値があるとわかった場合は、引用してください。
@inproceedings{dao2022flashattention,
title={Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness},
author={Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2022}
}
@inproceedings{dao2023flashattention2,
title={Flash{A}ttention-2: Faster Attention with Better Parallelism and Work Partitioning},
author={Dao, Tri},
booktitle={International Conference on Learning Representations (ICLR)},
year={2024}
}


