vision_transformer
1.0.0
このリポジトリでは、論文からモデルをリリースします
モデルは、ImagenetおよびImagenet-21Kデータセットで事前に訓練されていました。 Jax/Flaxでリリースされたモデルを微調整するためのコードを提供します。
このコードベースのモデルは、もともとhttps://github.com/google-research/big_vision/でトレーニングされました。 /vit_i21k.py vitの事前トレーニングの場合、またはモデルを転送するためのconfigs/transfer.py)。
目次:
コラブの下では、GPUとTPU(8コア、データの並列性)の両方で実行されます。
最初のcolabは、Jax of Vision TransformersとMLPミキサーを示しています。このColabを使用すると、リポジトリのファイルをColab UIで直接編集でき、コードを段階的に順を追って説明するコラブセルに注釈を付け、データと対話できます。
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/vit_jax.ipynb
2番目のColabを使用すると、3番目の論文のデータを生成するために使用された> 50kの視覚変圧器とハイブリッドチェックポイントを探索できます。 Colabには、チェックポイントを探索および選択し、このレポのJaxコードを使用して推論を行うコードが含まれています。また、これらのチェックポイントも直接ロードできる人気のtimm Pytorchライブラリを使用します。 TF-Hub:Sayakpaul/Collections/Vision_Transformer(Sayak Paulによる外部貢献)から直接入手できるモデルもいくつかあることに注意してください。
また、2番目のColabを使用すると、TFDSデータセットと独自のデータセットのチェックポイントを個々のJPEGファイルの例を微調整できます(オプションでGoogleドライブから直接読み取ります)。
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/vit_jax_augreg.ipynb
注:今のところ(6/20/21)Google Colabは単一のGPU(Nvidia Tesla T4)のみをサポートしており、TPU(現在はTPUV2-8)は間接的にコラブVMに接続され、スローネットワーク上で通信します。悪いトレーニング速度。通常、微調整するためのわずかな量のデータがある場合は、通常、専用マシンをセットアップする必要があります。詳細については、Cloud On Cloudセクションの実行を参照してください。
マシンにPython>=3.10がインストールされていることを確認してください。
実行して、JaxおよびPython依存関係をインストールします。
# If using GPU:
pip install -r vit_jax/requirements.txt
# If using TPU:
pip install -r vit_jax/requirements-tpu.txt
JAXの新しいバージョンについては、ここにリンクされている対応するリポジトリに記載されている指示に従ってください。 CPU、GPU、およびTPUのインストール手順はわずかに異なることに注意してください。
Flaxformerをインストールし、ここにリンクされている対応するリポジトリに記載されている指示に従ってください。
詳細については、以下のクラウドで実行されているセクションを参照してください。
関心のあるデータセットでダウンロードされたモデルの微調整を実行できます。すべてのモデルは、同じコマンドラインインターフェイスを共有しています。
たとえば、CIFAR10でVIT-B/16(ImagENET21Kで事前に訓練された)を微調整する場合(構成の引数としてb16,cifar10を指定する方法、およびGCSバケツからモデルに直接アクセスするようにコードに指示する方法最初にローカルディレクトリにダウンロードする代わりに):
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/vit.py:b16,cifar10
--config.pretrained_dir= ' gs://vit_models/imagenet21k 'CIFAR10でミキサーB/16(ImagENET21Kで事前に訓練された)を微調整するため:
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/mixer_base16_cifar10.py
--config.pretrained_dir= ' gs://mixer_models/imagenet21k ' 「VITを訓練する方法?...」紙は、 configs/augreg.py configで微調整できる> 50kのチェックポイントを追加しました。モデル名( configs/model.pyのconfig.name値)のみを指定する場合、上流の検証精度(「推奨」チェックポイント、ペーパーのセクション4.5を参照)で最適なi21kチェックポイント(「推奨」チェックポイントを参照)が選択されます。どのモデルを使用したいかを決心するには、論文の図3をご覧ください。また、別のチェックポイントを選択し(Colab vit_jax_augreg.ipynbを参照)、 gs://vit_models/augregディレクトリの.npzなしでファイル名に対応するfilenameまたはadapt_filename列から値を指定することもできます。
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/augreg.py:R_Ti_16
--config.dataset=oxford_iiit_pet
--config.base_lr=0.01現在、コードはCIFAR-10およびCIFAR-100データセットを自動的にダウンロードします。 Tensorflow Datasetsライブラリを使用して、他のパブリックまたはカスタムデータセットを簡単に統合できます。また、追加されたデータセットに関するいくつかのパラメーターを指定するには、 vit_jax/input_pipeline.pyを更新する必要があることに注意してください。
当社のコードは、微調整に利用可能なすべてのGPU/TPUを使用していることに注意してください。
利用可能なすべてのフラグの詳細なリストを表示するには、 python3 -m vit_jax.train --help 。
メモリに関するメモ:
--config.accum_steps=8の値を増やすことができます - あるいは、 --config.batch=512を減少させることもあります(およびそれに応じて--config.base_lrを減少させます)。--config.shuffle_buffer=50000減らすことができます。 Alexey Dosovitskiy*†、Lucas Beyer*、Alexander Kolesnikov*、Dirk Weissenborn*、Xiaohua Zhai*、Thomas Unterthiner、Mostafa Dehghani、Matthias Minderer、Georg heigold、Sylvain Gelly、Jakob UszkoreittiTetitet
(*)平等な技術貢献、(†)等しいアドバイス。
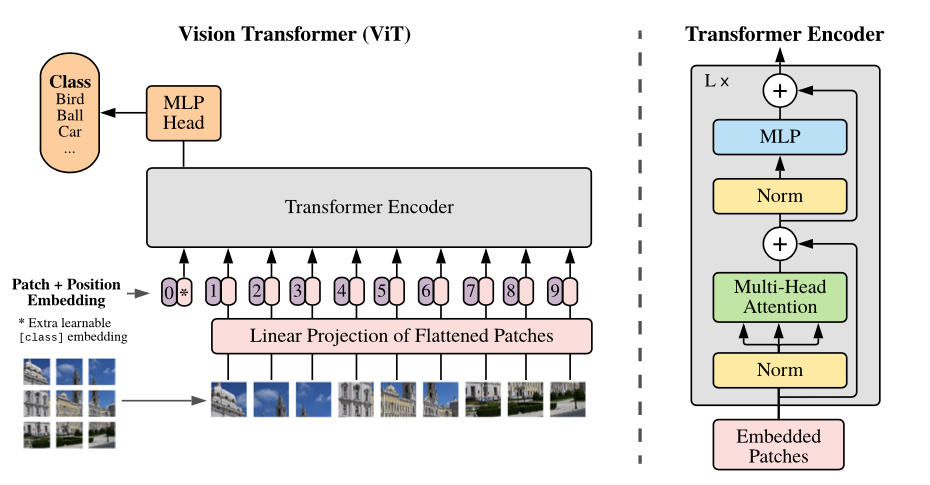
モデルの概要:画像を固定サイズのパッチに分割し、それぞれを線形に埋め込み、埋め込みを追加し、結果のベクトルのシーケンスを標準トランスエンコーダーにフィードします。分類を実行するために、シーケンスに追加の学習可能な「分類トークン」を追加する標準的なアプローチを使用します。
さまざまなGCSバケットでさまざまなVITモデルを提供しています。モデルは、例えば、ダウンロードできます。
wget https://storage.googleapis.com/vit_models/imagenet21k/ViT-B_16.npz
モデルファイル名( .npz拡張機能なし) config.model_name in vit_jax/configs/models.pyに対応しています
gs://vit_models/imagenet21k -ImagENET-21Kで事前に訓練されたモデル。gs://vit_models/imagenet21k+imagenet2012 -ImagENET-21Kで事前トレーニングされ、Imagenetで微調整されたモデル。gs://vit_models/augreg -imagenet-21kで事前に訓練されたモデル、さまざまな量のaugregを適用します。パフォーマンスの向上。gs://vit_models/samサムとのイメージネットで事前に訓練されたモデル。gs://vit_models/gsam GSAMを使用してImagenetで事前に訓練されたモデル。以下のチェックポイントを使用することをお勧めします。これは、トレーニング前の最高のメトリックを備えたAugregでトレーニングします。
| モデル | 事前に訓練されたチェックポイント | サイズ | 微調整されたチェックポイント | 解決 | IMG/SEC | Imagenet精度 |
|---|---|---|---|---|---|---|
| L/16 | gs://vit_models/augreg/L_16-i21k-300ep-lr_0.001-aug_strong1-wd_0.1-do_0.0-sd_0.0.npz | 1243ミブ | gs://vit_models/augreg/L_16-i21k-300ep-lr_0.001-aug_strong1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 50 | 85.59% |
| b/16 | gs://vit_models/augreg/B_16-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.0-sd_0.0.npz | 391ミブ | gs://vit_models/augreg/B_16-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 138 | 85.49% |
| S/16 | gs://vit_models/augreg/S_16-i21k-300ep-lr_0.001-aug_light1-wd_0.03-do_0.0-sd_0.0.npz | 115ミブ | gs://vit_models/augreg/S_16-i21k-300ep-lr_0.001-aug_light1-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 300 | 83.73% |
| R50+L/32 | gs://vit_models/augreg/R50_L_32-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.1-sd_0.1.npz | 1337ミブ | gs://vit_models/augreg/R50_L_32-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.1-sd_0.1--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 327 | 85.99% |
| R26+S/32 | gs://vit_models/augreg/R26_S_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0.npz | 170ミブ | gs://vit_models/augreg/R26_S_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 560 | 83.85% |
| Ti/16 | gs://vit_models/augreg/Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0.npz | 37ミブ | gs://vit_models/augreg/Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 610 | 78.22% |
| b/32 | gs://vit_models/augreg/B_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0.npz | 398ミブ | gs://vit_models/augreg/B_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 955 | 83.59% |
| S/32 | gs://vit_models/augreg/S_32-i21k-300ep-lr_0.001-aug_none-wd_0.1-do_0.0-sd_0.0.npz | 118ミブ | gs://vit_models/augreg/S_32-i21k-300ep-lr_0.001-aug_none-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 2154 | 79.58% |
| R+Ti/16 | gs://vit_models/augreg/R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0.npz | 40ミブ | gs://vit_models/augreg/R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 2426 | 75.40% |
元のVITペーパー(https://arxiv.org/abs/2010.11929)の結果はgs://vit_models/imagenet21kのモデルを使用して再現されています。
| モデル | データセット | ドロップアウト= 0.0 | ドロップアウト= 0.1 |
|---|---|---|---|
| R50+VIT-B_16 | CIFAR10 | 98.72%、3.9H(A100)、TB.Dev | 98.94%、10.1H(V100)、TB.Dev |
| R50+VIT-B_16 | CIFAR100 | 90.88%、4.1H(A100)、TB.Dev | 92.30%、10.1H(V100)、TB.Dev |
| R50+VIT-B_16 | Imagenet2012 | 83.72%、9.9H(A100)、TB.Dev | 85.08%、24.2H(V100)、TB.Dev |
| VIT-B_16 | CIFAR10 | 99.02%、2.2H(A100)、TB.Dev | 98.76%、7.8H(V100)、TB.Dev |
| VIT-B_16 | CIFAR100 | 92.06%、2.2H(A100)、TB.Dev | 91.92%、7.8H(V100)、TB.Dev |
| VIT-B_16 | Imagenet2012 | 84.53%、6.5H(A100)、TB.Dev | 84.12%、19.3H(V100)、TB.Dev |
| VIT-B_32 | CIFAR10 | 98.88%、0.8H(A100)、TB.Dev | 98.75%、1.8H(V100)、TB.Dev |
| VIT-B_32 | CIFAR100 | 92.31%、0.8H(A100)、TB.Dev | 92.05%、1.8H(V100)、TB.Dev |
| VIT-B_32 | Imagenet2012 | 81.66%、3.3H(A100)、TB.Dev | 81.31%、4.9H(V100)、TB.Dev |
| VIT-L_16 | CIFAR10 | 99.13%、6.9H(A100)、TB.Dev | 99.14%、24.7H(V100)、TB.Dev |
| VIT-L_16 | CIFAR100 | 92.91%、7.1H(A100)、TB.Dev | 93.22%、24.4H(V100)、TB.Dev |
| VIT-L_16 | Imagenet2012 | 84.47%、16.8H(A100)、TB.Dev | 85.05%、59.7H(V100)、TB.Dev |
| VIT-L_32 | CIFAR10 | 99.06%、1.9H(A100)、TB.Dev | 99.09%、6.1H(V100)、TB.Dev |
| VIT-L_32 | CIFAR100 | 93.29%、1.9H(A100)、TB.Dev | 93.34%、6.2H(V100)、TB.Dev |
| VIT-L_32 | Imagenet2012 | 81.89%、7.5H(A100)、TB.Dev | 81.13%、15.0H(V100)、TB.Dev |
また、短いトレーニングスケジュールで高品質の結果を達成できることを強調し、コードのユーザーがハイパーパラメータで再生して、正確性と計算予算をトレードオフするように促すことを強調したいと考えています。 CIFAR-10/100データセットの例を以下の表に示します。
| 上流 | モデル | データセット | total_steps / warmup_steps | 正確さ | 壁2時間 | リンク |
|---|---|---|---|---|---|---|
| ImagENET21K | VIT-B_16 | CIFAR10 | 500 /50 | 98.59% | 17m | tensorboard.dev |
| ImagENET21K | VIT-B_16 | CIFAR10 | 1000 /100 | 98.86% | 39m | tensorboard.dev |
| ImagENET21K | VIT-B_16 | CIFAR100 | 500 /50 | 89.17% | 17m | tensorboard.dev |
| ImagENET21K | VIT-B_16 | CIFAR100 | 1000 /100 | 91.15% | 39m | tensorboard.dev |
Ilya Tolstikhin*、Neil Houlsby*、Alexander Kolesnikov*、Lucas Beyer*、Xiaohua Zhai、Thomas Unterthiner、Jessica Yung、Andreas Steiner、Daniel Keysers、Jakob Uszkoreit、Mario Lucic、Alexey Dosovitskiy。
(*)平等な貢献。
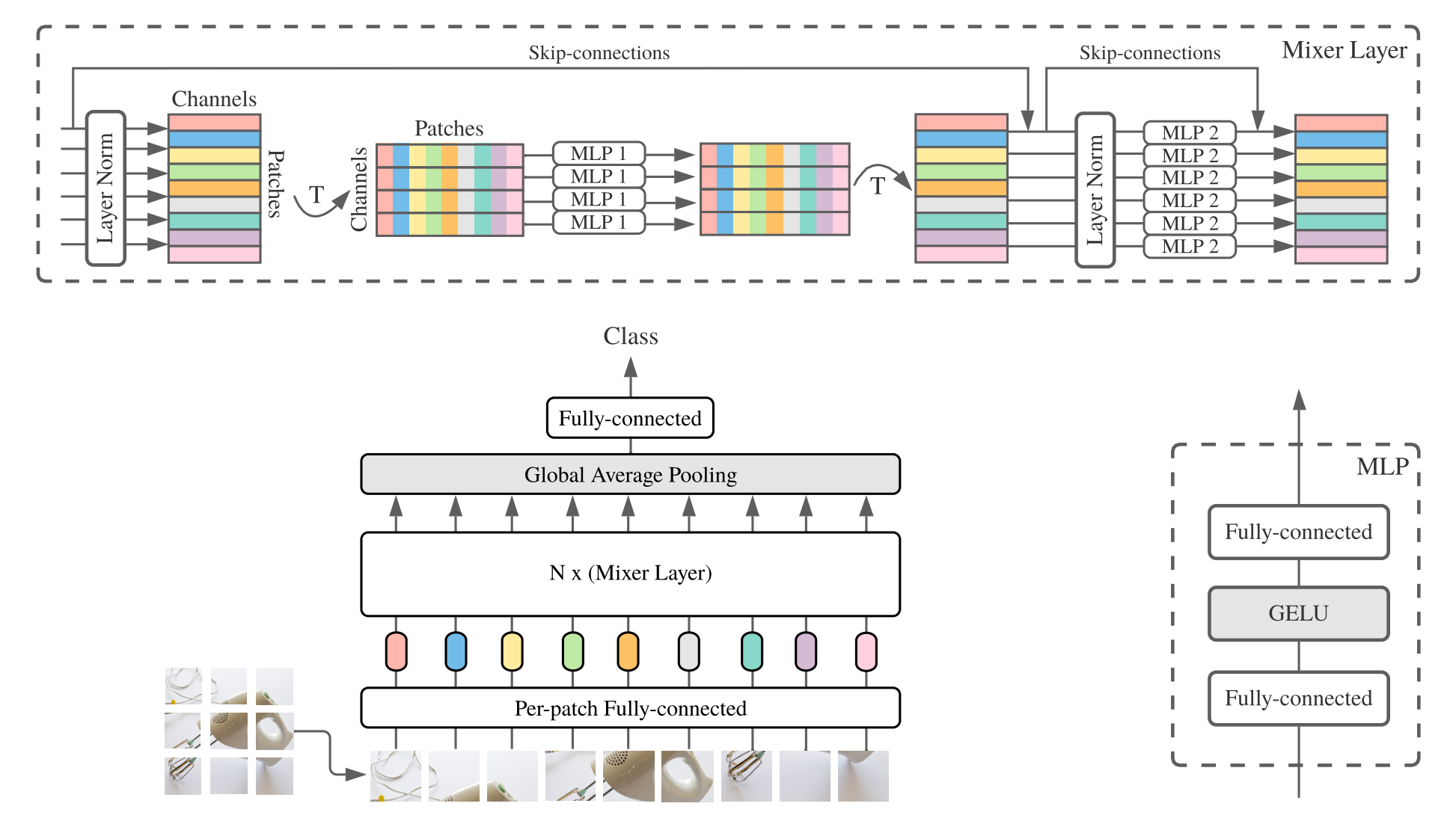
MLP-Mixer(略してミキサー)は、パッチあたりの線形埋め込み、ミキサー層、および分類器ヘッドで構成されています。ミキサー層には、1つのトークンミキシングMLPと1つのチャネル混合MLPが含まれており、それぞれが2つの完全に接続された層とGeluの非線形性で構成されています。その他のコンポーネントには、スキップ接続、ドロップアウト、線形分類器ヘッドが含まれます。
インストールについては、上記と同じ手順に従ってください。
Mixer-B/16およびMixer-L/16モデルを、ImagenetおよびImagenet-21Kデータセットで事前に訓練します。詳細は、ミキサーペーパーの表3にあります。すべてのモデルは次のように見つけることができます:
https://console.cloud.google.com/storage/mixer_models/
これらのモデルは、TF-Hub:Sayakpaul/Collections/MLP-Mixer(Sayak Paulによる外部貢献)から直接入手できることに注意してください。
このリポジトリのデフォルトの適応パラメーターを備えた4つのV100 GPUを使用して、Googleクラウドマシンで微調整コードを実行しました。結果は次のとおりです。
| 上流 | モデル | データセット | 正確さ | wall_clock_time | リンク |
|---|---|---|---|---|---|
| Imagenet | ミキサー-B/16 | CIFAR10 | 96.72% | 3.0H | tensorboard.dev |
| Imagenet | ミキサー-L/16 | CIFAR10 | 96.59% | 3.0H | tensorboard.dev |
| Imagenet-21K | ミキサー-B/16 | CIFAR10 | 96.82% | 9.6H | tensorboard.dev |
| Imagenet-21K | ミキサー-L/16 | CIFAR10 | 98.34% | 10.0H | tensorboard.dev |
詳細については、Google AIのブログ投稿を参照してください。LIT:Image Modelsに言語理解を追加するか、CVPRペーパー「LIT:Locked-imageテキストチューニングを使用したゼロショット転送」(https://arxiv.org/abs/2111.07991 )。
イメージネットゼロショット精度が72.1%のトランスB/16ベースモデルと、イメージネットゼロショット精度が75.7%のL/16-Largeモデルを公開しました。これらのモデルの詳細については、LITモデルカードを参照してください。
インタラクティブな使用のための小さなテキストエンコーダーを備えたブラウザー内デモを提供します(最小モデルは最新の携帯電話でも実行される必要があります):
https://google-research.github.io/vision_transformer/lit/
そして最後に、画像エンコーダーとテキストエンコーダーの両方でJAXモデルを使用するコラブ:
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/lit.ipynb
上記のモデルはまだ多言語入力をサポートしていないことに注意してください。ただし、そのようなモデルの公開に取り組んでおり、利用可能になったらこのリポジトリを更新することに注意してください。
このリポジトリには、LITモデルの評価コードのみが含まれています。 big_visionリポジトリでトレーニングコードを見つけることができます。
https://github.com/google-research/big_vision/tree/main/big_vision/configs/proj/image_text
予想されるZeroshotは、 model_cards/lit.mdの結果です(Zeroshot評価は、コラブの単純化された評価とはわずかに異なることに注意してください):
| モデル | B16B_2 | L16L |
|---|---|---|
| Imagenet Zero-Shot | 73.9% | 75.7% |
| Imagenet V2ゼロショット | 65.1% | 66.6% |
| CIFAR100ゼロショット | 79.0% | 80.5% |
| PETS37ゼロショット | 83.3% | 83.3% |
| Resisc45ゼロショット | 25.3% | 25.6% |
| MS-COCOキャプション画像からテキストの検索 | 51.6% | 48.5% |
| MS-COCOキャプションテキストから画像の検索 | 31.8% | 31.1% |
上記のコラブは始めるのにかなり便利ですが、通常、より強力な加速器を備えたより大きなマシンでトレーニングしたいと思うでしょう。
次のコマンドを使用して、GoogleクラウドでGPUを使用してVMをセットアップできます。
# Set variables used by all commands below.
# Note that project must have accounting set up.
# For a list of zones with GPUs refer to
# https://cloud.google.com/compute/docs/gpus/gpu-regions-zones
PROJECT=my-awesome-gcp-project # Project must have billing enabled.
VM_NAME=vit-jax-vm-gpu
ZONE=europe-west4-b
# Below settings have been tested with this repository. You can choose other
# combinations of images & machines (e.g.), refer to the corresponding gcloud commands:
# gcloud compute images list --project ml-images
# gcloud compute machine-types list
# etc.
gcloud compute instances create $VM_NAME
--project= $PROJECT --zone= $ZONE
--image=c1-deeplearning-tf-2-5-cu110-v20210527-debian-10
--image-project=ml-images --machine-type=n1-standard-96
--scopes=cloud-platform,storage-full --boot-disk-size=256GB
--boot-disk-type=pd-ssd --metadata=install-nvidia-driver=True
--maintenance-policy=TERMINATE
--accelerator=type=nvidia-tesla-v100,count=8
# Connect to VM (after some minutes needed to setup & start the machine).
gcloud compute ssh --project $PROJECT --zone $ZONE $VM_NAME
# Stop the VM after use (only storage is billed for a stopped VM).
gcloud compute instances stop --project $PROJECT --zone $ZONE $VM_NAME
# Delete VM after use (this will also remove all data stored on VM).
gcloud compute instances delete --project $PROJECT --zone $ZONE $VM_NAMEまたは、次の同様のコマンドを使用して、TPUが接続されたクラウドVMをセットアップすることもできます(TPUチュートリアルからコピーされたコマンド以下):
PROJECT=my-awesome-gcp-project # Project must have billing enabled.
VM_NAME=vit-jax-vm-tpu
ZONE=europe-west4-a
# Required to set up service identity initially.
gcloud beta services identity create --service tpu.googleapis.com
# Create a VM with TPUs directly attached to it.
gcloud alpha compute tpus tpu-vm create $VM_NAME
--project= $PROJECT --zone= $ZONE
--accelerator-type v3-8
--version tpu-vm-base
# Connect to VM (after some minutes needed to setup & start the machine).
gcloud alpha compute tpus tpu-vm ssh --project $PROJECT --zone $ZONE $VM_NAME
# Stop the VM after use (only storage is billed for a stopped VM).
gcloud alpha compute tpus tpu-vm stop --project $PROJECT --zone $ZONE $VM_NAME
# Delete VM after use (this will also remove all data stored on VM).
gcloud alpha compute tpus tpu-vm delete --project $PROJECT --zone $ZONE $VM_NAMEそして、通常どおりリポジトリとインストール依存関係(TPUサポート付きのjaxlibを含む)を取得します。
git clone --depth=1 --branch=master https://github.com/google-research/vision_transformer
cd vision_transformer
# optional: install virtualenv
pip3 install virtualenv
python3 -m virtualenv env
. env/bin/activateGPUが接続されたVMに接続されている場合は、次のコマンドでJAXおよびその他の依存関係をインストールします。
pip install -r vit_jax/requirements.txtTPUが添付されたVMに接続されている場合は、次のコマンドでJAXおよびその他の依存関係をインストールします。
pip install -r vit_jax/requirements-tpu.txtFlaxformerをインストールし、ここにリンクされている対応するリポジトリに記載されている指示に従ってください。
GPUとTPUの両方について、JAXがコマンドを使用して接続された加速器に接続できることを確認します。
python -c ' import jax; print(jax.devices()) '最後に、モデルを微調整するセクションで記載されているコマンドの1つを実行します。
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
@article{tolstikhin2021mixer,
title={MLP-Mixer: An all-MLP Architecture for Vision},
author={Tolstikhin, Ilya and Houlsby, Neil and Kolesnikov, Alexander and Beyer, Lucas and Zhai, Xiaohua and Unterthiner, Thomas and Yung, Jessica and Steiner, Andreas and Keysers, Daniel and Uszkoreit, Jakob and Lucic, Mario and Dosovitskiy, Alexey},
journal={arXiv preprint arXiv:2105.01601},
year={2021}
}
@article{steiner2021augreg,
title={How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers},
author={Steiner, Andreas and Kolesnikov, Alexander and and Zhai, Xiaohua and Wightman, Ross and Uszkoreit, Jakob and Beyer, Lucas},
journal={arXiv preprint arXiv:2106.10270},
year={2021}
}
@article{chen2021outperform,
title={When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations},
author={Chen, Xiangning and Hsieh, Cho-Jui and Gong, Boqing},
journal={arXiv preprint arXiv:2106.01548},
year={2021},
}
@article{zhuang2022gsam,
title={Surrogate Gap Minimization Improves Sharpness-Aware Training},
author={Zhuang, Juntang and Gong, Boqing and Yuan, Liangzhe and Cui, Yin and Adam, Hartwig and Dvornek, Nicha and Tatikonda, Sekhar and Duncan, James and Liu, Ting},
journal={ICLR},
year={2022},
}
@article{zhai2022lit,
title={LiT: Zero-Shot Transfer with Locked-image Text Tuning},
author={Zhai, Xiaohua and Wang, Xiao and Mustafa, Basil and Steiner, Andreas and Keysers, Daniel and Kolesnikov, Alexander and Beyer, Lucas},
journal={CVPR},
year={2022}
}
逆年代順に:
2022-08-18:画像側(LIT_B16B:768)に線形ヘッドなしで60Kステップ(LIT_B16B:30K)でトレーニングされたLIT-B16B_2モデルを追加し、パフォーマンスが向上しました。
2022-06-09:強力なデータ増強なしでImagenetでGSAMを使用してゼロから訓練されたVITおよびミキサーモデルを追加しました。結果として生じるvitsは、Adamw OptimizerまたはOriginal Samアルゴリズムを使用して訓練された同様のサイズのVITよりも優れています。
2022-04-14:LITモデルにモデルとコラブを追加しました。
2021-07-29:VIT-B/8 AUGREGモデルを追加しました(3つの上流のチェックポイントと解像度= 224の適応)。
2021-07-02:「Vision TransformersがResnetを上回るとき...」という論文を追加しました
2021-07-02:SAM(Sharpness-Aware Minimization)最適化されたVITおよびMLPミキサーチェックポイントを追加しました。
2021-06-20:「VITを訓練する方法?... ...」紙と、紙に記載されている50k以上の事前訓練と微調整されたチェックポイントを探索するための新しいコラブを追加しました。
2021-06-18:このリポジトリは、Flax Linen APIおよびml_collections.ConfigDictを使用するように書き換えられました。
2021-05-19:「あなたのVITを訓練する方法?...」の出版により、さまざまな程度のデータ増強とモデルの正規化を備えたImagenetおよびImagenet-21Kで事前に訓練された50K VITおよびハイブリッドモデルを追加しました、およびImagenet、Pets37、Kitti-Distance、CIFAR-100、およびResisc45で微調整されています。 vit_jax_augreg.ipynbをチェックして、このモデルの宝庫をナビゲートしてください!たとえば、そのコラブを使用して、論文の表3のi21k_300列から推奨される事前に訓練された微調整されたチェックポイントのファイル名を取得できます。
2020-12-01:R50+VIT-B/16ハイブリッドモデルを追加しました(ResNet-50バックボーンの上にVIT-B/16)。 ImagENET21Kで事前に削除されると、このモデルは、計算的な微調整コストの半分未満でL/16モデルのほぼパフォーマンスを達成します。 「R50」はb/16バリアントに多少変更されていることに注意してください。元のResnet-50には[3,4,6,3]ブロックがあり、それぞれが画像の解像度を2倍に減らします。 ResNet STEMと組み合わせて、これにより32倍が減少するため、(1,1)のパッチサイズであっても、VIT-B/16バリアントを実現できなくなります。このため、代わりにR50+B/16バリアントに[3,4,9]ブロックを使用します。
2020-11-09:VIT-L/16モデルを追加しました。
2020-10-29:Imagenet-21Kで前処理されたVIT-B/16およびVIT-L/16モデルを追加し、224x224解像度(デフォルト384x384の代わりに)でImagenetで微調整しました。これらのモデルには、名前の接尾辞「-224」があります。それらは、それぞれ81.2%と82.7%のTOP-1精度を達成することが期待されています。
Andreas Steinerが作成したオープンソースリリース。
注:このリポジトリは、Google-Research/Big_Transferからフォークされ、変更されました。
これは公式のGoogle製品ではありません。


