Awesome LLM 3D
1.0.0
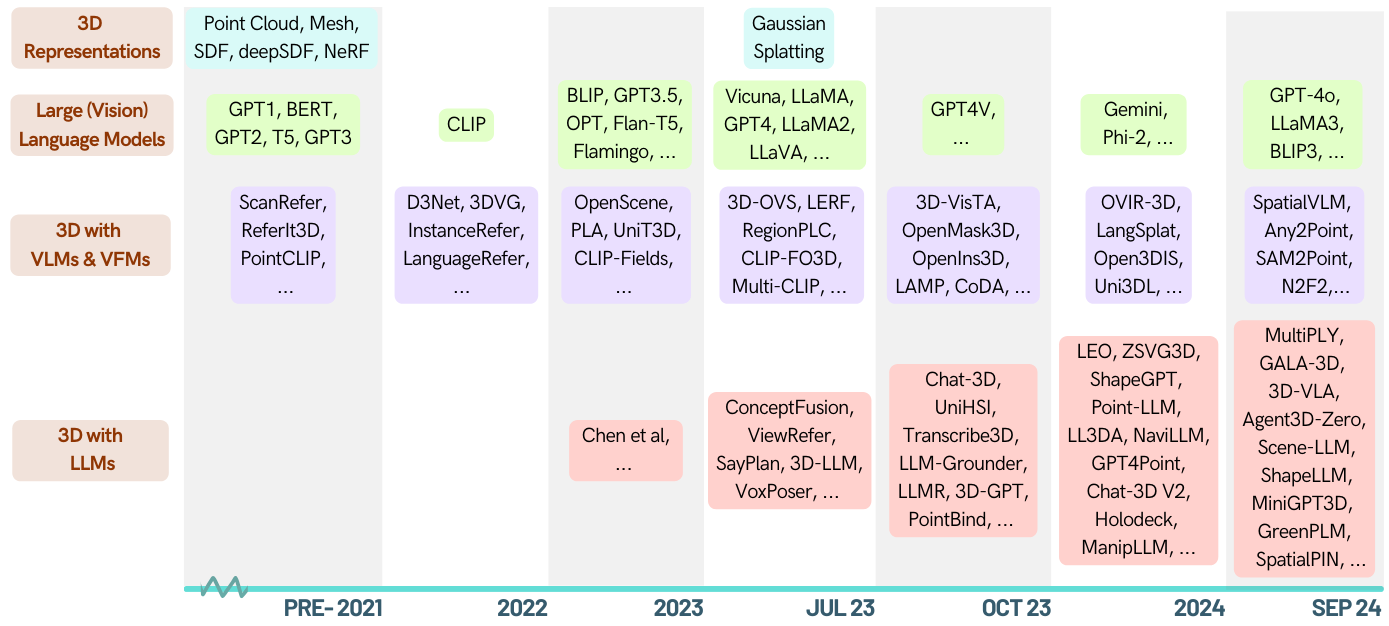
これは、大規模な言語モデル(LLM)に力を与えた3D関連のタスクに関する論文のキュレーションリストです。 3Dの理解、推論、生成、具体化されたエージェントなど、さまざまなタスクが含まれています。また、このエリアの全体像には、他の基礎モデル(Clip、SAM)を含めます。
これはアクティブなリポジトリであり、最新の進歩に従うことができます。便利だと思われる場合は、このレポを主演させて、紙を引用してください。
[2024-05-16]? 3D-LLMドメインの最初の調査論文をご覧ください:LLMSが3Dワールドに足を踏み入れるとき:マルチモーダル大手言語モデルを介した3Dタスクの調査とメタ分析
[2024-01-06] Runsen Xuは年代順の情報を追加し、Xianzheng Maは最新の進歩をより良く追跡するためにZA順序で再編成しました。
[2023-12-16] Xianzheng MaとYash Bhalgatはこのリストをキュレーションし、最初のバージョンを公開しました。
Awesome-llm-3d
3D理解(LLM)
3D理解(その他の基礎モデル)
3D推論
3D世代
3D具体化されたエージェント
3Dベンチマーク
貢献
| 日付 | キーワード | 研究所(最初) | 紙 | 出版 | その他 |
|---|---|---|---|---|---|
| 2024-10-12 | 状況3d | uiuc | 3Dビジョン言語の推論では、状況認識が重要です | CVPR '24 | プロジェクト |
| 2024-09-28 | llava-3d | HKU | LLAVA-3D:3D認識でLMMに力を与えるためのシンプルで効果的な経路 | arxiv | プロジェクト |
| 2024-09-08 | MSR3D | ビガイ | 3Dシーンでのマルチモーダルの位置の推論 | Neurips '24 | プロジェクト |
| 2024-08-28 | greenplm | ハスト | より多くのテキスト、より少ないポイント:3Dデータ効率の良いポイント言語理解に向けて | arxiv | github |
| 2024-06-17 | llana | unibo | Llana:大手言語とnerfアシスタント | Neurips '24 | プロジェクト |
| 2024-06-07 | SpatialPin | オックスフォード | SPATIALPIN:3D Priorsのプロンプトと相互作用による視覚言語モデルの空間推論能力の向上 | Neurips '24 | プロジェクト |
| 2024-06-03 | spatialrgpt | ucsd | SpatialRgpt:ビジョン言語モデルにおける接地された空間推論 | Neurips '24 | github |
| 2024-05-02 | Minigpt-3d | ハスト | Minigpt-3d:2D Priorsを使用して3Dポイントクラウドを大規模な言語モデルで効率的に整列させる | ACM MM '24 | プロジェクト |
| 2024-02-27 | shapellm | xjtu | Shapellm:具体化された相互作用のためのユニバーサル3Dオブジェクトの理解 | arxiv | プロジェクト |
| 2024-01-22 | SpatialVlm | Google DeepMind | SpatialVlm:空間推論機能を備えた視覚言語モデルを吸着させる | CVPR '24 | プロジェクト |
| 2023-12-21 | lidar-llm | PKU | lidar-llm:3D Lidarの理解のための大規模な言語モデルの可能性を探る | arxiv | プロジェクト |
| 2023-12-15 | 3DAP | 上海AIラボ | 3DaxiesPrompts:GPT-4Vの3D空間タスク機能を解き放ちます | arxiv | プロジェクト |
| 2023-12-13 | チャットシーン | Zju | チャットシーン:オブジェクト識別子を備えた3Dシーンと大規模な言語モデルのブリッジ | Neurips '24 | github |
| 2023-12-5 | gpt4point | HKU | gpt4point:ポイント言語の理解と生成のための統一されたフレームワーク | arxiv | github |
| 2023-11-30 | ll3da | フダン大学 | LL3DA:OMNI-3Dの理解、推論、および計画のための視覚的なインタラクティブな指導チューニング | arxiv | github |
| 2023-11-26 | ZSVG3D | Cuhk(SZ) | ゼロショットの視覚プログラミングの視覚プログラミングオープンボキャブラリー3D視覚接地 | arxiv | プロジェクト |
| 2023-11-18 | レオ | ビガイ | 3D世界で具体化されたジェネラリストエージェント | arxiv | github |
| 2023-10-14 | jm3d-llm | Xiamen大学 | JM3D&JM3D-LLM:ジョイントマルチモーダルキューで3D表現を高める | ACM MM '23 | github |
| 2023-10-10 | uni3d | バイ | UNI3D:大規模な統一された3D表現の調査 | ICLR '24 | プロジェクト |
| 2023-9-27 | - | カウスト | ゼロショット3D形状の対応 | シググラフアジア'23 | - |
| 2023-9-21 | LLMグラウンド | u-mich | LLM-Grounder:エージェントとしての大規模な言語モデルを使用したオープンボキャブラリー3D視覚的接地 | ICRA '24 | github |
| 2023-9-1 | ポイントバインド | cuhk | Point-bind&Point-llm:3Dの理解、生成、および指示のためのマルチモダリティとポイントクラウドを調整する | arxiv | github |
| 2023-8-31 | Pointllm | cuhk | Pointllm:大規模な言語モデルにポイントクラウドを理解できるようになります | ECCV '24 | github |
| 2023-8-17 | チャット-3d | Zju | チャット-3D:3Dシーンのユニバーサルダイアログのための大規模な言語モデルを効率的にチューニングする | arxiv | github |
| 2023-8-8 | 3d-vista | ビガイ | 3D-vista:3D視力とテキストアライメントのための事前に訓練された変圧器 | ICCV '23 | github |
| 2023-7-24 | 3d-llm | UCLA | 3D-LLM:3Dの世界を大規模な言語モデルに注入します | ニューリップス'23 | github |
| 2023-3-29 | ViewRefer | cuhk | ViewRefer:3D視覚接地のマルチビュー知識を把握します | ICCV '23 | github |
| 2022-9-12 | - | mit | ロボット3Dシーンの理解のための大きな(視覚的な)言語モデルを活用する | arxiv | github |
| id | キーワード | 研究所(最初) | 紙 | 出版 | その他 |
|---|---|---|---|---|---|
| 2024-10-12 | lexicon3d | uiuc | lexicon3d:複雑な3Dシーンの理解のための視覚的基礎モデルの調査 | Neurips '24 | プロジェクト |
| 2024-10-07 | diff2scene | CMU | テキストからイメージまでの拡散モデルを使用したオープンホキャジ3Dセマンティックセグメンテーション | ECCV 2024 | プロジェクト |
| 2024-04-07 | Any2point | 上海AIラボ | any2point:効率的な3D理解のために、あらゆるモダリティの大規模モデルを強化します | ECCV 2024 | github |
| 2024-03-16 | N2F2 | Oxford-VGG | N2F2:ネストされた神経特徴フィールドを使用した階層シーンの理解 | arxiv | - |
| 2023-12-17 | sai3d | PKU | SAI3D:3Dシーンの任意のインスタンスをセグメント化します | arxiv | プロジェクト |
| 2023-12-17 | open3dis | vinai | Open3DIS:2Dマスクガイダンスを備えたオープンボキャブラリー3Dインスタンスセグメンテーション | arxiv | プロジェクト |
| 2023-11-6 | ovir-3d | ラトガーズ大学 | OVIR-3D:3Dデータのトレーニングなしでオープンボキャブラリー3Dインスタンス検索 | Corl '23 | github |
| 2023-10-29 | OpenMask3d | ETH | OpenMask3D:オープンボキャブラリー3Dインスタンスセグメンテーション | ニューリップス'23 | プロジェクト |
| 2023-10-5 | オープンフュージョン | - | オープンフュージョン:リアルタイムのオープンボキャブラリー3Dマッピングとクエリのシーン表現 | arxiv | github |
| 2023-9-22 | ov-3ddet | hkust | CODA:オープンボキャブラリー3Dオブジェクト検出のための共同斬新なボックスの発見とクロスモーダルアラインメント | ニューリップス'23 | github |
| 2023-9-19 | ランプ | - | 言語から3D世界へ:ポイントクラウド知覚のための言語モデルの適応 | OpenReview | - |
| 2023-9-15 | Opennerf | - | Opennerf:Pixel-Wise機能とレンダリングされた斬新なビューを使用した3Dニューラルシーンセグメンテーションをオープンセット | OpenReview | github |
| 2023-9-1 | openins3d | ケンブリッジ | OpenINS3D:3Dオープンボキャブラリーインスタンスセグメンテーションのスナップと検索 | arxiv | プロジェクト |
| 2023-6-7 | 対照的なリフト | Oxford-VGG | コントラストリフト:遅い速度対照融合による3Dオブジェクトインスタンスセグメンテーション | ニューリップス'23 | github |
| 2023-6-4 | マルチクリップ | ETH | マルチクリップ:3Dシーンでのタスクに答える質問のための対照的なビジョン言語トレーニング | arxiv | - |
| 2023-5-23 | 3D-ovs | NTU | 弱く監視されている3Dオープンボキャブラリーセグメンテーション | ニューリップス'23 | github |
| 2023-5-21 | VLフィールド | エジンバラ大学 | VL-fields:言語接地された神経暗黙の空間表現に向けて | ICRA '23 | プロジェクト |
| 2023-5-8 | Clip-fo3d | ツィンガ大学 | Clip-Fo3d:2D密度のクリップから無料のオープンワールド3Dシーン表現を学習する | ICCVW '23 | - |
| 2023-4-12 | 3D-VQA | ETH | 3Dシーンでの質問に答えるためのクリップ誘導ビジョン言語事前トレーニング | CVPRW '23 | github |
| 2023-4-3 | RegionPlc | HKU | RegionPLC:オープンワールドの3Dシーンの理解のための地域のポイント言語対照学習 | arxiv | プロジェクト |
| 2023-3-20 | CG3D | jhu | Clip Goes 3D:言語に基づいた3D認識のためのプロンプトチューニングを活用する | arxiv | github |
| 2023-3-16 | lerf | UCバークレー | LERF:言語埋め込み放射輝度フィールド | ICCV '23 | github |
| 2023-2-14 | コンセプトフュージョン | mit | ConceptFusion:オープンセットマルチモーダル3Dマッピング | RSS '23 | プロジェクト |
| 2023-1-12 | Clip2cene | HKU | Clip2cene:クリップによるラベル効率の高い3Dシーンの理解に向けて | CVPR '23 | github |
| 2022-12-1 | Unit3d | tum | UNIT3D:3D密度の高いキャプションと視覚的接地のための統一された変圧器 | ICCV '23 | github |
| 2022-11-29 | プラ | HKU | PLA:言語主導のオープンボキャブラリー3Dシーンの理解 | CVPR '23 | github |
| 2022-11-28 | openscene | ethz | OpenScene:オープンな語彙を使用した3Dシーンの理解 | CVPR '23 | github |
| 2022-10-11 | クリップフィールド | NYU | クリップフィールド:ロボットメモリ用の弱く監視されたセマンティックフィールド | arxiv | プロジェクト |
| 2022-7-23 | セマンティック抽象化 | コロンビア | セマンティック抽象化:2Dビジョン言語モデルからのオープンワールド3Dシーンの理解 | Corl '22 | プロジェクト |
| 2022-4-26 | scannet200 | tum | 野生の言語屋内3Dセマンティックセグメンテーション | ECCV '22 | プロジェクト |
| 日付 | キーワード | 研究所(最初) | 紙 | 出版 | その他 |
|---|---|---|---|---|---|
| 2023-5-20 | 3D-CLR | UCLA | マルチビュー画像からの3Dコンセプトの学習と推論 | CVPR '23 | github |
| - | Transcribe3d | TTI、シカゴ | Transcribe3d:自己修正されたFinetuningを使用した3D参照推論の転写情報を使用したLLMSの接地LLMS | Corl '23 | github |
| 日付 | キーワード | 研究所 | 紙 | 出版 | その他 |
|---|---|---|---|---|---|
| 2023-11-29 | Shapegpt | フダン大学 | ShapeGpt:統一されたマルチモーダル言語モデルを備えた3Dシェイプ生成 | arxiv | github |
| 2023-11-27 | meshgpt | tum | meshgpt:デコーダーのみの変圧器を使用して三角形メッシュを生成します | arxiv | プロジェクト |
| 2023-10-19 | 3d-gpt | anu | 3D-GPT:大きな言語モデルを使用した手続き上の3Dモデリング | arxiv | github |
| 2023-9-21 | LLMR | mit | LLMR:大規模な言語モデルを使用したインタラクティブな世界のリアルタイムプロンプト | arxiv | - |
| 2023-9-20 | dreamllm | Megvii | Dreamllm:相乗的なマルチモーダルの理解と創造 | arxiv | github |
| 2023-4-1 | チャタバタル | Deemos Tech | Dreamface:テキストガイダンスの下でアニメーション可能な3D顔の進歩的な世代 | ACM TOG | Webサイト |
| 日付 | キーワード | 研究所 | 紙 | 出版 | その他 |
|---|---|---|---|---|---|
| 2024-01-22 | SpatialVlm | deepmind | SpatialVlm:空間推論機能を備えた視覚言語モデルを吸着させる | CVPR '24 | プロジェクト |
| 2023-11-27 | dobb-e | NYU | ロボットを家に持ち帰ることで | arxiv | github |
| 2023-11-26 | スティーブ | Zju | 仮想環境で具体化されたエージェントを参照してください | arxiv | github |
| 2023-11-18 | レオ | ビガイ | 3D世界で具体化されたジェネラリストエージェント | arxiv | github |
| 2023-9-14 | Unihsi | 上海AIラボ | 迅速なチェーンコンタクトを介した統一されたヒトセーン相互作用 | arxiv | github |
| 2023-7-28 | RT-2 | Google Deepmind | RT-2:Vision-Language-activeモデルは、Web知識をロボットコントロールに転送します | arxiv | github |
| 2023-7-12 | プランを言う | QUTロボットセンター | SayPlan:スケーラブルなロボットタスク計画のために3Dシーングラフを使用した大きな言語モデルの接地 | Corl '23 | github |
| 2023-7-12 | voxposer | スタンフォード | Voxposer:言語モデルを使用したロボット操作用の合成可能な3D値マップ | arxiv | github |
| 2022-12-13 | RT-1 | グーグル | RT-1:大規模な現実世界制御用のロボティクス変圧器 | arxiv | github |
| 2022-12-8 | LLMプランナー | オハイオ州立大学 | LLM-Planner:大規模な言語モデルを持つ具体化されたエージェントの少数の根拠のある計画 | ICCV '23 | github |
| 2022-10-11 | クリップフィールド | NYU、メタ | クリップフィールド:ロボットメモリ用の弱く監視されたセマンティックフィールド | RSS '23 | github |
| 2022-09-20 | nlmap-saycan | グーグル | 現実世界の計画のためのオープンクライブ可能なクエリ可能なシーン表現 | ICRA '23 | github |
| 日付 | キーワード | 研究所 | 紙 | 出版 | その他 |
|---|---|---|---|---|---|
| 2024-09-08 | MSQA / MSNN | ビガイ | 3Dシーンでのマルチモーダルの位置の推論 | Neurips '24 | プロジェクト |
| 2024-06-10 | 3Dグランド / 3Dポープ | ウミッチ | 3D-grand:グラウンドが良く、幻覚が少ない3D-llmsの100万スケールのデータセット | arxiv | プロジェクト |
| 2024-06-03 | spatialrgpt-bench | ucsd | SpatialRgpt:ビジョン言語モデルにおける接地された空間推論 | Neurips '24 | github |
| 2024-1-18 | シーンバース | ビガイ | Sceneverse:根拠のあるシーンの理解のための3Dビジョン言語学習のスケーリング | arxiv | github |
| 2023-12-26 | EmbodiedScan | 上海AIラボ | EmbodiedScan:具体化されたAIに向けた全体的なマルチモーダル3D認識スイート | arxiv | github |
| 2023-12-17 | m3dbench | フダン大学 | M3DBench:マルチモーダル3Dプロンプトを使用して大規模なモデルに指示しましょう | arxiv | github |
| 2023-11-29 | - | deepmind | 3Dオブジェクトのスコアベースのマルチプローブ注釈のVLMの評価 | arxiv | github |
| 2023-09-14 | クロスコヒーレンス | unibo | 注意を払って言葉とポイントを見る:テキストからシェイプの一貫性のベンチマーク | ICCV '23 | github |
| 2022-10-14 | SQA3D | ビガイ | SQA3D:3Dシーンでの状況に応じた質問 | ICLR '23 | github |
| 2021-12-20 | scanqa | riken aip | SCANQA:空間シーンの理解のための3D質問の回答 | CVPR '23 | github |
| 2020-12-3 | scan2cap | tum | scan2cap:RGB-Dスキャンでのコンテキスト対応の密なキャプション | CVPR '21 | github |
| 2020-8-23 | 参照3d | スタンフォード | referit3d:現実世界のシーンでの細かい3Dオブジェクト識別のニューラルリスナー | ECCV '20 | github |
| 2019-12-18 | スキャンリーファー | tum | スキャンリーファー:自然言語を使用したRGB-Dスキャンへの3Dオブジェクトのローカリゼーション | ECCV '20 | github |
あなたの貢献はいつでも大歓迎です!
3D LLMSに素晴らしいかどうかわからない場合は、プルリクエストを開いたままにします。追加することで投票できますか?彼らに。
この意見のあるリストについてご質問がある場合は、[email protected]またはwechat id:mxz1997112にご連絡ください。
このリポジトリが便利だと思う場合は、この論文を引用することを検討してください。
@misc{ma2024llmsstep3dworld,
title={When LLMs step into the 3D World: A Survey and Meta-Analysis of 3D Tasks via Multi-modal Large Language Models},
author={Xianzheng Ma and Yash Bhalgat and Brandon Smart and Shuai Chen and Xinghui Li and Jian Ding and Jindong Gu and Dave Zhenyu Chen and Songyou Peng and Jia-Wang Bian and Philip H Torr and Marc Pollefeys and Matthias Nießner and Ian D Reid and Angel X. Chang and Iro Laina and Victor Adrian Prisacariu},
year={2024},
journal={arXiv preprint arXiv:2405.10255},
}このレポは、Awesome-llmに触発されています


