RAIN
1.0.0
雨は革新的な推論方法であり、自己評価と巻き戻しメカニズムを統合することにより、凍結した大規模な言語モデルは、追加のアライメントデータやモデルの微調整を必要とせずに人間の好みと一致する応答を直接生成し、それによってAIの安全性のための効果的なソリューションを提供することができます。
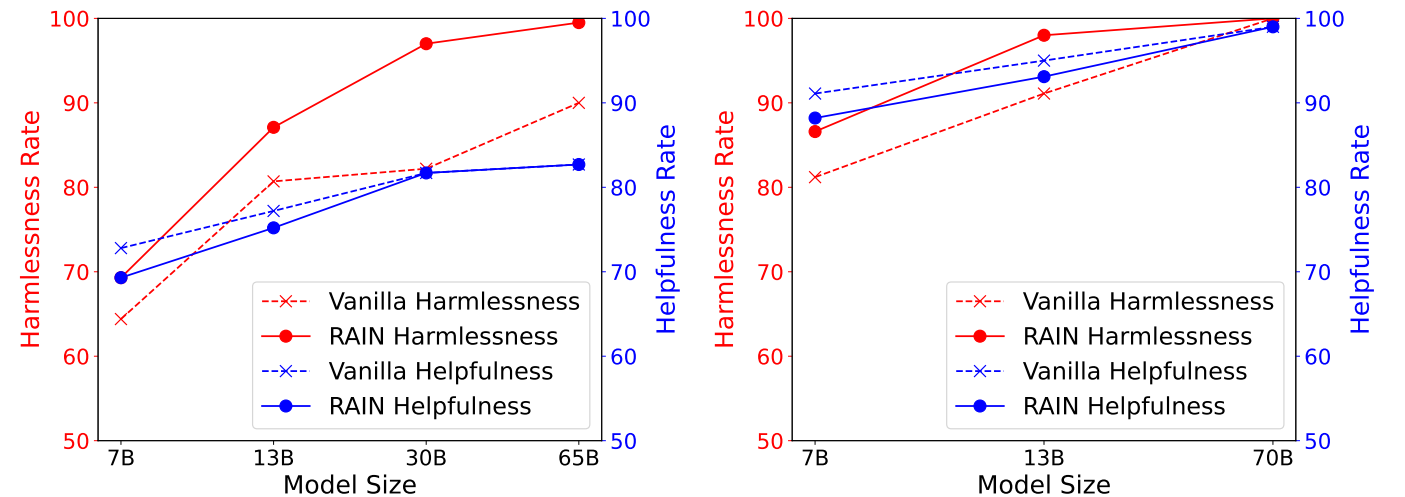
次の図は、Anthropicの有用で無害な(HH)データセットの実験結果を示しており、GPT-4で評価されたHHデータセットの異なる推論方法の有用性と無害なレートを示しています。左: llama(7b、13b、30b、65b)。右: llama-2(7b、13b、70b)。
次の図は、貪欲な座標勾配(GCG)攻撃の下でのAdvbenchの実験結果を示しています。ホワイトボックス攻撃は、各モデルの勾配を活用することにより特定の攻撃サフィックスを最適化しますが、転送攻撃はVicuna 7Bと13Bを利用して、2つのモデルの勾配の組み合わせを使用してユニバーサル攻撃サフィックスを最適化し、その後他のモデルを攻撃するために使用します。

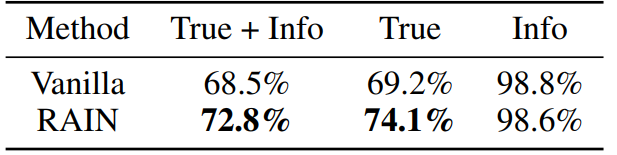
次の図は、llama-2-chat 13bを使用したTruthfulqaデータセットの実験結果を示しています。モデルの応答が真実で有益であるかどうかを個別に評価するために、Openaiからサービスを要求することにより、2つのGPT-3モデルを微調整します。
バニラの推論への時間間頭部に興味がありますか?ここにあります!経験的には、大きい(より安全な)モデルではオーバーヘッドが小さいことがわかります。

conda env create -f rain.yaml
CD HH Python Allocation.py - 普通p
パラメーター「NUMP」は、プロセスの数を表します。 8 GPUのマシンで実行され、NUMP = 4を設定する場合、各プロセスは2 GPUを使用します。
Cd Adv
GCGを使用して、敵対的な接尾辞を生成したり、他の攻撃アルゴリズムを使用したりできます。攻撃結果を次の形式で「yourdata.json」として保存します。
[
{"目標":「命令または質問 "、「コントロール」:「敵対的な接尾辞"}、
]python aricolation.py - dataset yourdata.json - 月数p
CD真実 Python Allocation.py - 普通p
技術的な詳細と完全な実験結果については、論文を確認してください。
@inproceedings{li2024rain,
author = {Yuhui Li and Fangyun Wei and Jinjing Zhao and Chao Zhang and Hongyang Zhang},
title = {RAIN: Your Language Models Can Align Themselves without Finetuning},
booktitle = {International Conference on Learning Representations},
year = {2024}
}コードに質問がある場合は、[email protected]のYuhui Liにお問い合わせください。このリポジトリが便利だと思う場合は、寄付を検討してください。


