streaming
v0.9.1
クラウドストレージからの大規模なデータセットに関するトレーニングを可能な限り速く、安く、スケーラブルにするために、StreamingDatasetを構築しました。
マルチノードのために特別に設計されており、大規模なモデル向けの分散トレーニングを行います。これは、正確性の保証、パフォーマンス、および使いやすさを最大化することです。これで、トレーニングデータの場所とは無関係に、どこでも効率的にトレーニングできます。必要なときに必要なデータをストリーミングするだけです。 StreamingDatasetを作成した理由の詳細については、発表ブログをお読みください。
StreamingDatasetは、画像、テキスト、ビデオ、マルチモーダルデータなど、任意のデータタイプと互換性があります。
主要なクラウドストレージプロバイダー(AWS、OCI、GCS、Azure、DataBricks、およびCloudFlare R2、CoreWeave、Backblaze B2などのS3互換オブジェクトストア)のサポートを提供し、Pytorch IterabedAtasetクラスのドロップイン交換として設計されています、StreamingDatasetは、既存のトレーニングワークフローにシームレスに統合されます。

ストリーミングはpipでインストールできます。
PIPインストールMOSAICML-STREAMING
RAWデータセットをサポートされているストリーミング形式の1つに変換します。
PythonオブジェクトをエンコードしてデコードできるMDS(モザイクデータシャード)形式
CSV / TSV
jsonl
nppilとしてnumpyをインポートします。インポート画像フロムストリーミングmdswriter#ローカルまたはリモートディレクトリをインポートします。 、 'class': 'int'}#shard圧縮、chompression = 'zstd'の場合はシャード圧縮、mdswriterwith mdswriter(out = data_dir、列=列、圧縮=圧縮)を使用してサンプルとしてサンプルを保存します:範囲(1000000(1000000)の場合):sample = {'image':image.fromarray(np.random.randint(0、256、(32、32、3)、np.uint8))、 'class':np.random.randint(10)、
} out.write(サンプル)ストリーミングデータセットを選択したクラウドストレージ(AWS、OCI、またはGCP)にアップロードします。以下は、AWS CLIを使用してディレクトリをS3バケットにアップロードする例です。
$ AWS S3 CP-Recursive Path-to-Dataset S3:// my-bucket/path-to-dataset
Torch.utils.dataからImport Import dataloaderfromストリーミングインポートストリーミングdataset#完全なデータセットが持続的に保存されているリモートパス/path-to-dataset '#datasetdataset = streamingdataset(local = local、remote = remote、shuffle = true)#spreamingdataset = streamingdataset(sample#1337 ... sample = dataset [1337] img = sample [' image ['image)を見てみましょう'] cls = sample [' class ']#pytorch dataloaderdataloader = dataloader(dataset)を作成します
ガイド、例、API参照、その他の有用な情報を開始することは、ドキュメントに記載されています。
次のモデルをトレーニングするためのエンドツーエンドのチュートリアルがあります。
CIFAR-10
facesynthetics
Syntheticnlp
また、以下の一般的なデータセットのスターターコードもあります。これは、 streamingディレクトリにあります。
| データセット | タスク | 読む | 書く |
|---|---|---|---|
| laion-400m | テキストと画像 | 読む | 書く |
| WebVid | テキストとビデオ | 読む | 書く |
| C4 | 文章 | 読む | 書く |
| エンウィキ | 文章 | 読む | 書く |
| パイル | 文章 | 読む | 書く |
| ADE20K | 画像セグメンテーション | 読む | 書く |
| CIFAR10 | 画像分類 | 読む | 書く |
| ココ | 画像分類 | 読む | 書く |
| Imagenet | 画像分類 | 読む | 書く |
これらのデータセットのトレーニングを開始するには:
convert Directoryから対応するスクリプトを使用して、RAWデータを.MDS形式に変換します。
例えば:
$ python -m streaming.multimodal.convert.webvid - in <csv file> -out <mds outputディレクトリ>
データセットクラスをインポートして、モデルのトレーニングを開始します。
Streaming.Multimodal Importing StreamingInsideWebVidDataset = StreamingInsideDadeWebvid(local = local、remote、shuffle = true)
データセットの混合物をStreamと簡単に実験してください。データセットサンプリングは、相対(比率)または絶対(繰り返しまたはサンプル用語)で制御できます。ストリーミング中、さまざまなデータセットがストリーミング、シャッフル、シームレスにジャストインタイムを混合します。
# mix C4, github code, and internal datasets streams = [ Stream(remote='s3://datasets/c4', proportion=0.4), Stream(remote='s3://datasets/github', proportion=0.1), Stream(remote='gcs://datasets/my_internal', proportion=0.5), ] dataset = StreamingDataset( streams=streams, samples_per_epoch=1e8, )
私たちのソリューションのユニークな機能:サンプルは、GPU、ノード、またはCPUワーカーの数に関係なく同じ順序です。これにより、以下が簡単になります。
トレーニングの実行とデバッグの実行と損失の急増
64 GPUでトレーニングされたチェックポイントをロードし、再現性のある8 GPUでデバッグ
以下の図を参照してください - 1、8、16、32、または64 GPUのモデルをトレーニングすると、まったく同じ損失曲線が得られます(浮動小数点数学の制限まで!)
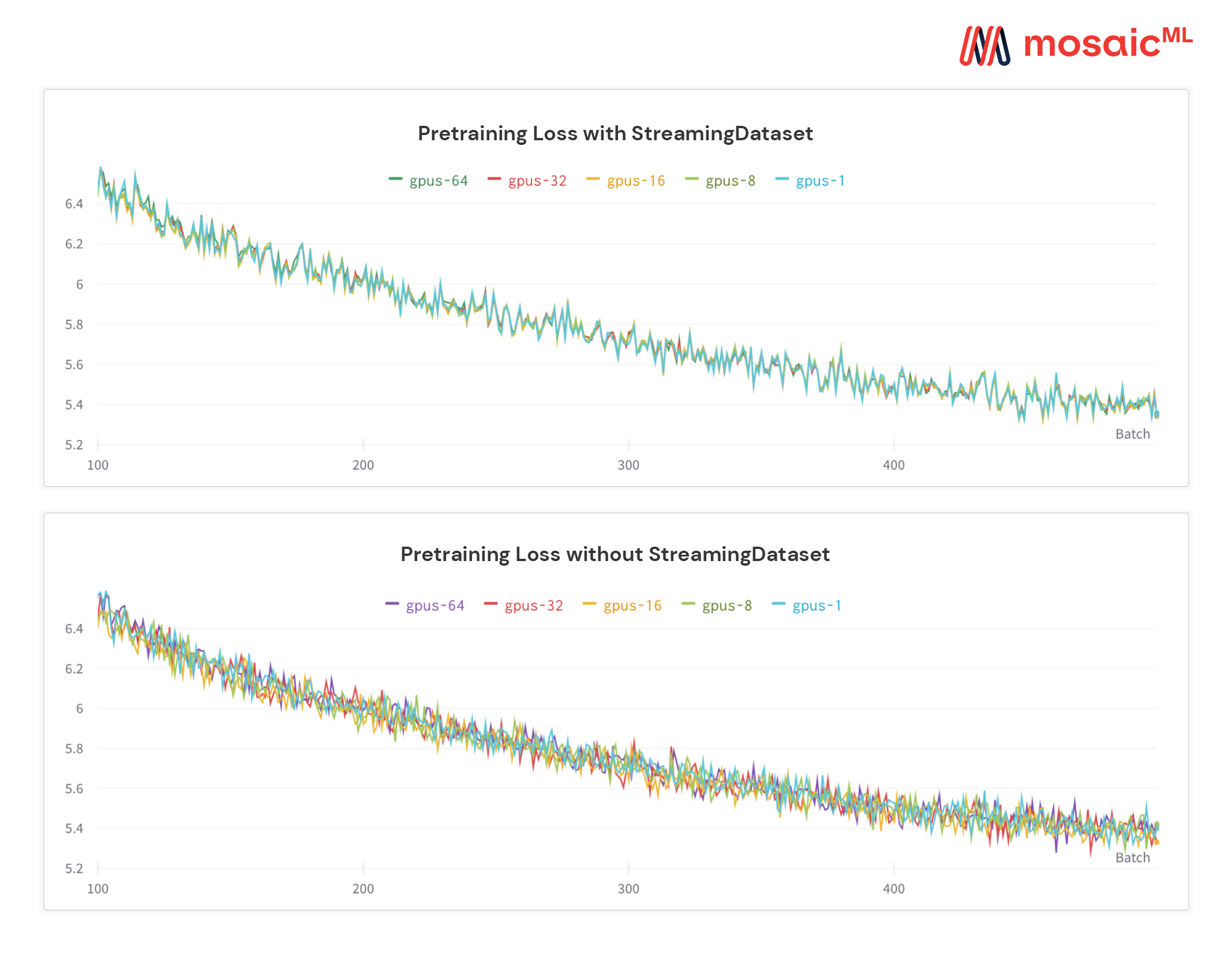
ハードウェアの障害または損失のスパイクの後にデータローダーが回転している間、あなたの仕事が再開するのを待つのは高価であり、迷惑です。決定論的なサンプルの注文のおかげで、StreamingDatasetを使用すると、長いトレーニングの途中で、数時間ではなく数秒でトレーニングを再開できます。
再開の遅延を最小限に抑えると、既存のソリューションと比較して、出口料金とアイドルGPU計算時間で数千ドルを節約できます。
当社のMDS形式は、骨に無関係な作業を削減するため、Dataloaderがボトルネックしたワークロードの代替品と比較して、超低サンプルレイテンシとより高いスループットをもたらします。
| 道具 | スループット |
|---|---|
| StreamingDataset | 〜19000 IMG/Sec |
| ImageFolder | 〜18000 IMG/Sec |
| webdataset | 〜16000 IMG/Sec |
結果は、データが最初のエポックの後にキャッシュされた後、5回以上の繰り返しを収集したImagenet + Resnet-50トレーニングからのものです。
StreamingDatasetの使用からのモデルの収束は、シャッフルアルゴリズムのおかげで、ローカルディスクを使用するのと同じくらい優れています。
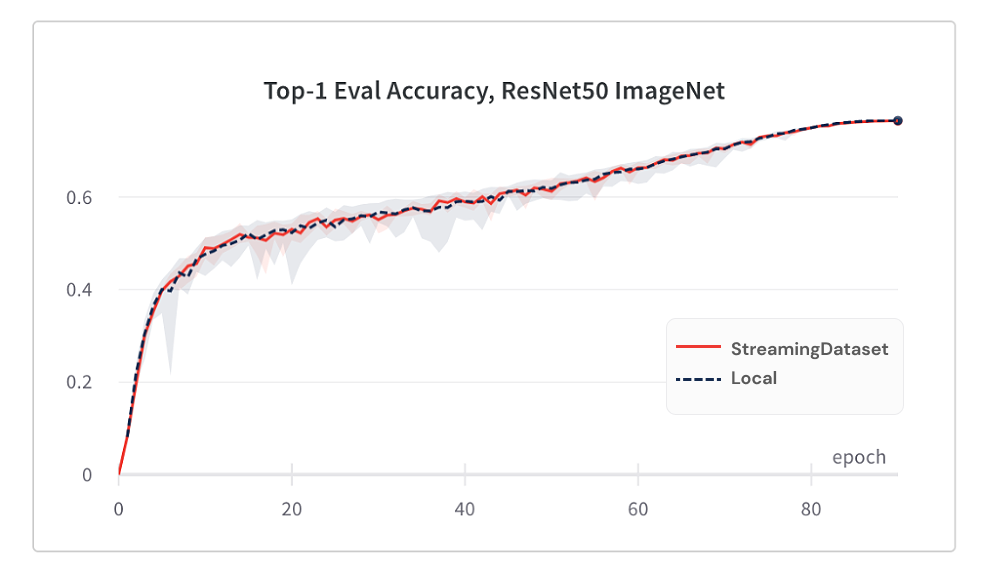
以下は、5回以上の繰り返しを収集したImagenet + Resnet-50トレーニングの結果です。
| 道具 | Top-1の精度 |
|---|---|
| StreamingDataset | 76.51%+/- 0.09 |
| ImageFolder | 76.57%+/- 0.10 |
| webdataset | 76.23%+/- 0.17 |
StreamingDatasetは、ノードに割り当てられたすべてのサンプルでシャッフルしますが、代替ソリューションは小さなプール内のサンプルのみをシャッフルします(単一のプロセス内)。より広いプールをシャッフルすると、隣接するサンプルがさらに広がります。さらに、シャッフルアルゴリズムは、ドロップしたサンプルを最小限に抑えます。これらのシャッフル機能は両方とも、モデルの収束に有利です。
必要なときに必要なデータにアクセスします。
サンプルがまだダウンロードされていない場合でも、 dataset[i]にアクセスしてサンプルi取得できます。ダウンロードはすぐに開始され、結果は完了すると返されます - マップスタイルのPytorchデータセットと同様に、サンプルは任意の順序で番号が付けられ、アクセス可能です。
データセット= streamingdataset(...)sample = dataset [19543]
StreamingDatasetは、任意の数のサンプルを喜んで反復します。サンプルを永久に削除する必要はありません。そうすれば、データセットが焼き込められたデバイスで分割されます。代わりに、各エポックの異なる選択のサンプルが繰り返され(ドロップされていません)、各デバイスが同じカウントを処理するようにします。
DataSet = StreamingDataset(...)dl = dataloader(dataset、num_workers = ...)
指定された制限の下でディスク使用を維持するために、最近使用されていないシャードを動的に削除します。これは、StreamingDataSet引数cache_limit設定することにより有効になります。詳細については、シャッフルガイドをご覧ください。
dataset = StreamingDataset( cache_limit='100gb', ... )
StreamingDatasetを使用したプロジェクトと実験を次に示します。追加するものがありますか? [email protected]にメールするか、コミュニティのSlackに参加してください。
Biomedlm:MOSAICMLおよびSTANFORD CRFMによるバイオメディシンのドメイン固有の大型言語モデル
モザイク拡散モデル:ゼロから安定した拡散をトレーニングするコスト<$ 160K
Mosaic LLMS:GPT-3 <50万ドルの品質
モザイクリセネット:モザイクリセネットと作曲家を使用したぼんやりと速いコンピュータービジョントレーニング
MOSAIC DEEPLABV3:MOSAICMLレシピを使用した5倍高速な画像セグメンテーショントレーニング
…もっと来て!乞うご期待!
貢献、プルリクエスト、または問題を歓迎します。
貢献を開始するには、貢献ページを参照してください。
PS:私たちは雇っています!
このプロジェクトが気に入ったら、スターを教えて、他のプロジェクトをチェックしてください。
作曲家 -スケーラブルで効率的なニューラルネットワークトレーニングを簡単にする最新のPytorchライブラリ
MOSAICMLの例- MLモデルを迅速にトレーニングし、高精度をトレーニングするための参照例-GPT /大手言語モデル、安定した拡散、BERT、ResNet -50、およびDeepLabvv3のスターターコードを特徴とする
MOSAICMLクラウド- LLMS、拡散モデル、およびその他の大規模なモデルのトレーニングコストを最小限に抑えるために構築されたトレーニングプラットフォーム - マルチクラウドオーケストレーション、楽なマルチノードスケーリング、トレーニング時間を高速化するためのフード下の最適化
@misc{mosaicml2022streaming,
author = {The Mosaic ML Team},
title = {streaming},
year = {2022},
howpublished = {url{<https://github.com/mosaicml/streaming/>}},
} 

