Huawei UK University Challenge Competition 2021
1.0.0

チームプレゼンター: Kahraman Kostas
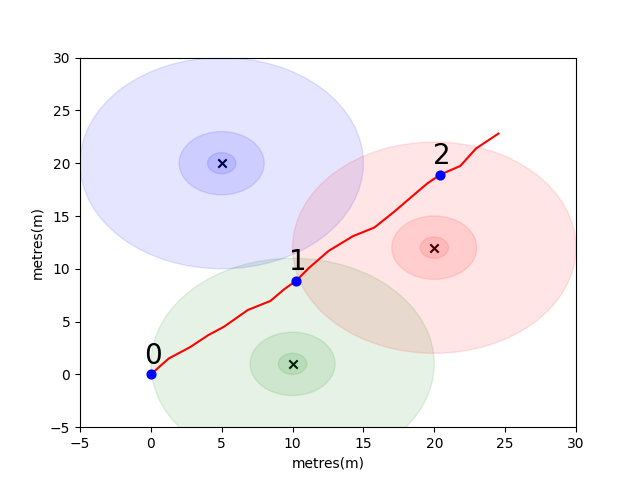
開始するために、単純な問題をまとめて、いくつかの重要な屋内ポジショニングの概念を紹介します。次の環境を検討してください。ユーザーは、3つのWiFiエミッターの存在下でオープンスペースを移動しています(このユーザーが作成したデータを軌跡と呼びます)。各エミッタには一意のMACアドレスがあります。ユーザーには、WiFi環境を定期的にスキャンし、検出された各Mac(DB)のRSSIを記録するスマートフォンが装備されています。
このモデルでは、各エミッターに標準のログロス自由空間伝播モデルを使用しました。これは、自由空間でうまく機能する単純なモデルですが、より複雑な方法で信号を跳ね返すことができる壁やその他の障害物を備えた実際の屋内環境で壊れます。一般に、放出アンテナからの固定エネルギーが波が伝播するにつれて増加している領域に広がるため、距離にわたってRSSIの急な低下が見られることを期待しています。下の図では、各円は10dBのドロップを示します。
ユーザーはポイント(0,0)から北東に歩いており、そこで電話が環境を3回スキャンします。各スキャンで記録されたデータを以下に示します。
scan 0 -> {'green': -60, 'blue': -66, 'red': -67}
scan 1 -> {'green': -58, 'blue': -61, 'red': -60}
scan 2 -> {'green': -66, 'blue': -62, 'red': -59}
WiFi環境の複雑で局所的にユニークな特性により、屋内ポジショニングシステムに非常に役立ちます。たとえば、以下の画像では、3つのエミッターのほぼ重心でデータを測定scan 1 、この環境には、同様のRSSI値を登録する読み取りを受けることができる他の場所はありません。独立した軌跡からの一連のスキャンまたは「指紋」を考えると、これは実際の空間にどれだけ近いかを示すため、WiFi空間でどれだけ似ているかを計算することに興味があります。
最初の課題は、上記で紹介したサンプル軌道の各スキャン間のユークリッド距離とマンハッタンの距離メトリックを計算する関数を記述することです。単一の軌道からのデータを使用することは、歩行者の死んだ計算で使用される電話のインターティアル測定ユニット(IMU)からのデータを使用して、真の距離のかなり正確な推定値を取得できるため、類似性メトリックの品質をテストする良い方法です。 (PDR)モジュール。
def euclidean ( fp1 , fp2 ):
raise NotImplementedError
def manhattan ( fp1 , fp2 ):
raise NotImplementedError # solution of the above functions
from scipy . spatial import distance
def euclidean ( fp1 , fp2 ):
fp1 = list ( fp1 . values ())
fp2 = list ( fp2 . values ())
return distance . euclidean ( fp1 , fp2 )
def manhattan ( fp1 , fp2 ):
fp1 = list ( fp1 . values ())
fp2 = list ( fp2 . values ())
return distance . cityblock ( fp1 , fp2 ) import json
import numpy as np
import matplotlib . pyplot as plt
from metrics import eval_dist_metric
with open ( "intro_trajectory_1.json" ) as f :
traj = json . load ( f )
## Pre-calculate the pair indexes we are interested in
keys = []
for fp1 in traj [ 'fps' ]:
for fp2 in traj [ 'fps' ]:
# only calculate the upper triangle
if fp1 [ 'step_index' ] > fp2 [ 'step_index' ]:
keys . append (( fp1 [ 'step_index' ], fp2 [ 'step_index' ]))
## Get the distances from PDR
true_d = {}
for step1 in traj [ 'steps' ]:
for step2 in traj [ 'steps' ]:
key = ( step1 [ 'step_index' ], step2 [ 'step_index' ])
if key in keys :
true_d [ key ] = abs ( step1 [ 'di' ] - step2 [ 'di' ])
euc_d = {}
man_d = {}
for fp1 in traj [ 'fps' ]:
for fp2 in traj [ 'fps' ]:
key = ( fp1 [ 'step_index' ], fp2 [ 'step_index' ])
if key in keys :
euc_d [ key ] = euclidean ( fp1 [ 'profile' ], fp2 [ 'profile' ])
man_d [ key ] = manhattan ( fp1 [ 'profile' ], fp2 [ 'profile' ])
print ( "Euclidean Average Error" )
print ( f' { eval_dist_metric ( euc_d , true_d ):.2f } ' )
print ( "Manhattan Average Error" )
print ( f' { eval_dist_metric ( man_d , true_d ):.2f } ' ) Euclidean Average Error
9.29
Manhattan Average Error
4.90
関数を正しく実装した場合、ユークリッドメトリックの平均誤差は9.29であるのに対し、マンハッタンはわずか4.90であることがわかりました。したがって、このデータの場合、マンハッタンの距離は真の距離のより良い推定値です。
もちろん、これは非常に単純なモデルです。実際、この方法では、RSSI値と自由空間距離の間に直接的な関係はありません。通常、距離の独自の推定値を作成すると、軌道内から既知のPDR距離を使用して、数値スコアを物理距離推定に適合させます。
主な課題のために、WiFiの指紋のみに基づいて、2つのスキャン間の実際の距離を推定するために、独自のメトリックを開発してください。 2021年の初めに1つのモールから収集された実際のクラウドソーシングデータを提供します。データには、114661の指紋スキャンとスキャン間の879824距離が含まれます。距離は、私たちが考慮に入れる追加情報を与えられた真の距離の最良の見積もりになります。
指紋ペアのテストセットを提供し、それらがどれだけ離れているかを示す関数を書く必要があります。
この関数は、さまざまな状況で異なるMACアドレス(またはMacアドレスの組み合わせ)を異なる方法で重み付けすることを学ぶ完全な機械学習ソリューションと同じように、上記で紹介したメトリックの1つのバリエーションと同じくらい簡単です。
考慮すべきいくつかの最終ポイント:
データは3つのファイルとして組み立てられます。
task1_fingerprints.jsonは、問題のすべての指紋情報が含まれています。つまり、各エントリは、モールのエリアにあるWiFiエミッターの実際のスキャンを表しています。同じMACアドレスが多くの指紋に存在することがわかります。
task1_train.csvには、アルゴリズムの設計/トレーニングに役立つ有効なトレーニングペアが含まれています。各id1-id2ペアには、ラベルが付いたグラウンドトゥルース距離(メートル)があり、各IDはtask1_fingerprints.jsonの指紋に対応しています。
task1_test.csvは、 task1_train.csvと同じ形式ですが、変位は含まれていません。これらは、生の指紋情報を使用して予測してほしいものです。
import csv
import json
import os
from tqdm import tqdm
path_to_data = "for_contestants"
with open ( os . path . join ( path_to_data , "task1_fingerprints.json" )) as f :
fps = json . load ( f )
with open ( os . path . join ( path_to_data , "task1_train.csv" )) as f :
train_data = []
train_h = csv . DictReader ( f )
for pair in tqdm ( train_h ):
train_data . append ([ pair [ 'id1' ], pair [ 'id2' ], float ( pair [ 'displacement' ])])
with open ( os . path . join ( path_to_data , "task1_test.csv" )) as f :
test_h = csv . DictReader ( f )
test_ids = []
for pair in tqdm ( test_h ):
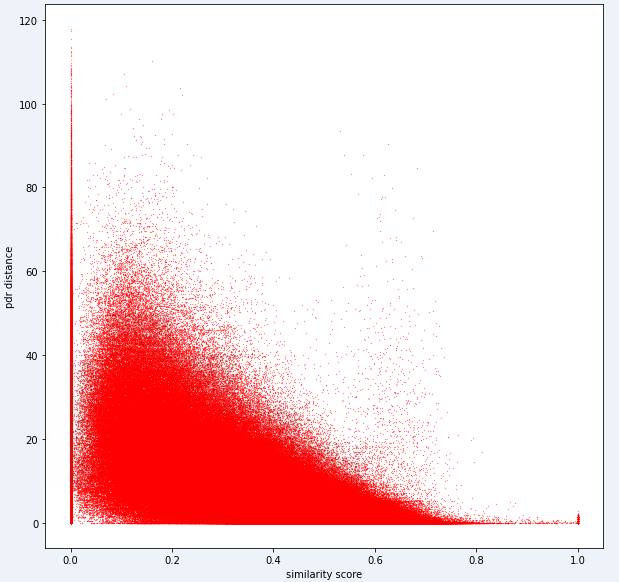
test_ids . append ([ pair [ 'id1' ], pair [ 'id2' ]])最終的に、理想的なモデルでは、高次元の指紋スペース(1本指紋には多くの測定値が含まれる可能性がある)と1次元距離空間の間の正確なマッピングを見つけることができるはずです。計算された類似性メトリックに対してPDR距離(トレーニングデータから)をプロットして、メトリックが明らかな傾向を明らかにするかどうかを確認することは有用です。高い類似性は、低距離と相関するはずです。
以下は、このタスクに内部で使用する距離メトリックの1つです。このメトリックでも、かなりの量のノイズがあることがわかります。
このレベルのノイズにより、タスク1のスコアリングメトリックはリコールよりも精度に偏っています
提出物は、 test1_test.csvファイルからの正確なIDを使用し、その指紋ペアの推定距離(メーター)に3番目の(現在空の)変位列を入力する必要があります。
def my_distance_function ( fp1 , fp2 ):
raise NotImplementedError output_data = [[ "id1" , "id2" , "displacement" ]]
for id1 , id2 in tqdm ( test_ids ):
fp1 = fps [ id1 ]
fp2 = fps [ id2 ]
distance_estimate = my_distance_function ( fp1 , fp2 )
output_data . append ([ id1 , id2 , distance_estimate ])
with open ( "MySubmission.csv" , "w" , newline = '' ) as f :
writer = csv . writer ( f )
writer . writerows ( output_data )最初のタスクの手順は、次のように要約できます。
これらの手順は、下の画像に示されています。

Python 3.6.5を使用してアプリケーションファイルを作成しました。コンテストの開始時に与えられたサンプルファイルに含まれていない追加のモジュールを含めました。これらのモジュールは、次のようにリストできます。
| モルル | タスク |
|---|---|
| Tensorflow | 深い学習 |
| パンダ | データ分析 |
| scipy | 距離計算 |
これらのモジュールを最初のステップとしてインストールすることから始めました。
## 1.1 Installing modules
!p ip install tensorflow == 2.6 . 2
!p ip install scipy
!p ip install pandas このステップでは、繰り返し可能な結果を得るために使用される関連ランダムシードを修正しました。このようにして、すべての実行で同じ結果を得る決定論的なパスを提供しました。ただし、観察によると、異なるコンピューターで得られた結果はわずかに異なる場合があります(±1%)
## 1.2 Setting Random Seeds
seed_value = 0
import os
os . environ [ 'PYTHONHASHSEED' ] = str ( seed_value )
import random
random . seed ( seed_value )
import numpy as np
np . random . seed ( seed_value )
import tensorflow as tf
tf . random . set_seed ( seed_value )
import tensorflow as tf
session_conf = tf . compat . v1 . ConfigProto ( intra_op_parallelism_threads = 1 , inter_op_parallelism_threads = 1 )
sess = tf . compat . v1 . Session ( graph = tf . compat . v1 . get_default_graph (), config = session_conf )このセクションでは、使用するデータをロードします。指定されたサンプルファイル( Task1-IPS-Challenge-2021.ipynb )からコードと説明を取得しました。
task1_fingerprints.jsonは、問題のすべての指紋情報が含まれています。つまり、各エントリは、モールのエリアにあるWiFiエミッターの実際のスキャンを表しています。同じMACアドレスが多くの指紋に存在することがわかります。
task1_train.csvには、アルゴリズムの設計/トレーニングに役立つ有効なトレーニングペアが含まれています。各id1-id2ペアには、ラベルが付いたグラウンドトゥルース距離(メートル)があり、各IDはtask1_fingerprints.jsonの指紋に対応しています。
task1_test.csvは、 task1_train.csvと同じ形式ですが、変位は含まれていません。
## 1.3 Loading the data
import csv
import json
import os
from tqdm import tqdm
path_to_data = "for_contestants"
with open ( os . path . join ( path_to_data , "task1_fingerprints.json" )) as f :
fps = json . load ( f )
with open ( os . path . join ( path_to_data , "task1_train.csv" )) as f :
train_data = []
train_h = csv . DictReader ( f )
for pair in tqdm ( train_h ):
train_data . append ([ pair [ 'id1' ], pair [ 'id2' ], float ( pair [ 'displacement' ])])
with open ( os . path . join ( path_to_data , "task1_test.csv" )) as f :
test_h = csv . DictReader ( f )
test_ids = []
for pair in tqdm ( test_h ):
test_ids . append ([ pair [ 'id1' ], pair [ 'id2' ]]) 879824it [05:16, 2778.31it/s]
5160445it [01:00, 85269.27it/s]
このステップでは、2つの機能を使用して機能抽出を実行します。 feature_extraction_file関数jsonファイルから指紋の関連する値(ペア)を引くだけで、 feature_extraction関数に送信して計算を行います。
feature_extraction関数では、これらの2つの指紋がサイズとそれらを含むデバイスの点で互いに異なる場合、2つの指紋に含まれるすべてのデバイスがまとめられて、繰り返されることなく共通のシーケンスを形成します。各配列では、値0を非対応するデバイスに割り当てることにより、これらの2つの配列が同じ(それらを含むデバイスの観点から)同一にします。このプロセスは、次の画像の例で説明されています。
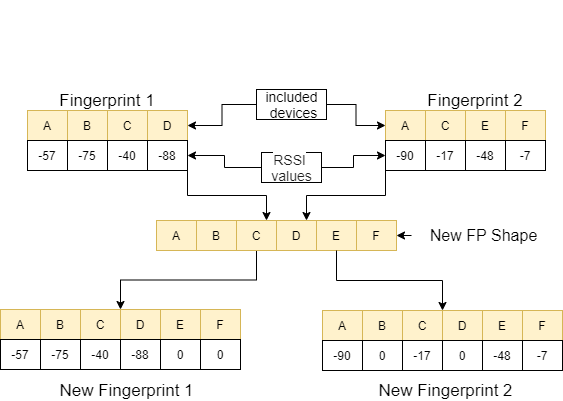
類似したこれら2つの指紋間の距離は、11の異なる方法を使用して計算されます[1]。これらの方法は次のとおりです。
次に、これらの値はfeature_extraction_file関数に向けられ、この関数内のCSVファイルとして保存されます。言い換えれば、さまざまなサイズの指紋は、このプロセスの結果として11フィーチュアCSVファイルに変わります。使用するモデルは、これらの新しく作成された機能でトレーニングおよびテストされます。
## 1.4 Feature Extraction
def feature_extraction_file ( data , name , flag ):
features = [[ "braycurtis" ,
"canberra" ,
"chebyshev" ,
"cityblock" ,
"correlation" ,
"cosine" ,
"euclidean" ,
"jensenshannon" ,
"minkowski" ,
"sqeuclidean" ,
"wminkowski" , "real" ]]
for i in tqdm (( data ), position = 0 , leave = True ):
fp1 = fps [ i [ 0 ]]
fp2 = fps [ i [ 1 ]]
feature = feature_extraction ( fp1 , fp2 )
if flag :
feature . append ( i [ 2 ])
else : feature . append ( 0 )
features . append ( feature )
with open ( name , "w" , newline = '' ) as f :
writer = csv . writer ( f )
writer . writerows ( features )
#print(features) ## 1.4 Feature Extraction
def feature_extraction ( fp1 , fp2 ):
mac = set ( list ( fp1 . keys ()) + list ( fp2 . keys ()))
mac = { i : 0 for i in mac }
f1 = mac . copy ()
f2 = mac . copy ()
for key in fp1 :
f1 [ key ] = fp1 [ key ]
for key in fp2 :
f2 [ key ] = fp2 [ key ]
f1 = list ( f1 . values ())
f2 = list ( f2 . values ())
braycurtis = scipy . spatial . distance . braycurtis ( f1 , f2 )
canberra = scipy . spatial . distance . canberra ( f1 , f2 )
chebyshev = scipy . spatial . distance . chebyshev ( f1 , f2 )
cityblock = scipy . spatial . distance . cityblock ( f1 , f2 )
correlation = scipy . spatial . distance . correlation ( f1 , f2 )
cosine = scipy . spatial . distance . cosine ( f1 , f2 )
euclidean = scipy . spatial . distance . euclidean ( f1 , f2 )
jensenshannon = scipy . spatial . distance . jensenshannon ( f1 , f2 )
minkowski = scipy . spatial . distance . minkowski ( f1 , f2 )
sqeuclidean = scipy . spatial . distance . sqeuclidean ( f1 , f2 )
wminkowski = scipy . spatial . distance . wminkowski ( f1 , f2 , 1 , np . ones ( len ( f1 )))
output_data = [ braycurtis ,
canberra ,
chebyshev ,
cityblock ,
correlation ,
cosine ,
euclidean ,
jensenshannon ,
minkowski ,
sqeuclidean ,
wminkowski ]
output_data = [ 0 if x != x else x for x in output_data ]
return output_data このタスクでは、モールのwifiエミッターの周囲からRRSI信号を持つ指紋スキャンがあります。 First Challangeは、回帰タスクである2つの指紋スキャン間の距離を推定することを望んでいます。生物学的ニューラルネットワークに触発されたANN(人工ニューラルネットワーク)を使用しました。アンは3つのレイヤーで構成されています。入力層、隠されたレイヤー(複数)、出力層。 Annは、トレーニングデータ(機能を備えた)を含む入力層から始まり、データを最初の隠れレイヤーの重みによって計算される最初の隠しレイヤーにデータを渡します。隠れ層では、入力に対する重みの計算の反復があり、アクティベーション関数を適用します[2]。私たちの問題は回帰であるため、最後の層は単一の出力ニューロンです。その出力は、指紋スキャンのペア間の距離を予測することです。最初の隠し層には64個、2番目のレイヤーには128個のニューロンがあります。このモデルのすべてのアーキテクチャは、次のように共有されます。 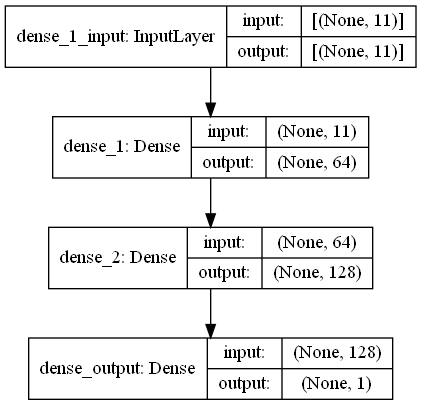
2つの機能を使用して深い学習を実行します。Create_Model関数はcreate_modelトレーニングデータを形成してモデルをトレーニングし、モデルの構造を決定します。 model_features関数は、指定された構造を持つモデルを生成します。作成されたモデルは、 create_model関数によってトレーニングされた後に使用されるように保存されます。
## 1.5 Model
import scipy . spatial
import pandas as pd
import numpy as np
import matplotlib . pyplot as plt
from tensorflow import keras
from tensorflow . keras . models import Sequential
from tensorflow . keras . layers import Dense
#from keras.utils.vis_utils import plot_model
% matplotlib inline
def model_features ( i , ii ):
model = Sequential ()
model . add ( Dense ( i , input_shape = ( 11 , ), activation = 'relu' , name = 'dense_1' ))
model . add ( Dense ( ii , activation = 'relu' , name = 'dense_2' ))
model . add ( Dense ( 1 , activation = 'linear' , name = 'dense_output' ))
model . compile ( optimizer = 'adam' , loss = 'mse' , metrics = [ 'mae' ])
model . summary ()
#plot_model(model, to_file='model_plot.png', show_shapes=True, show_layer_names=True)
#print(model.get_config())
return model
def create_model ( name ):
df = pd . read_csv ( name )
df . replace ([ np . inf , - np . inf ], np . nan , inplace = True )
df = df . fillna ( 0 )
X = df [ df . columns [ 0 : - 1 ]]
X_train = np . array ( X )
y_train = np . array ( df [ df . columns [ - 1 ]])
model = model_features ( 64 , 128 )
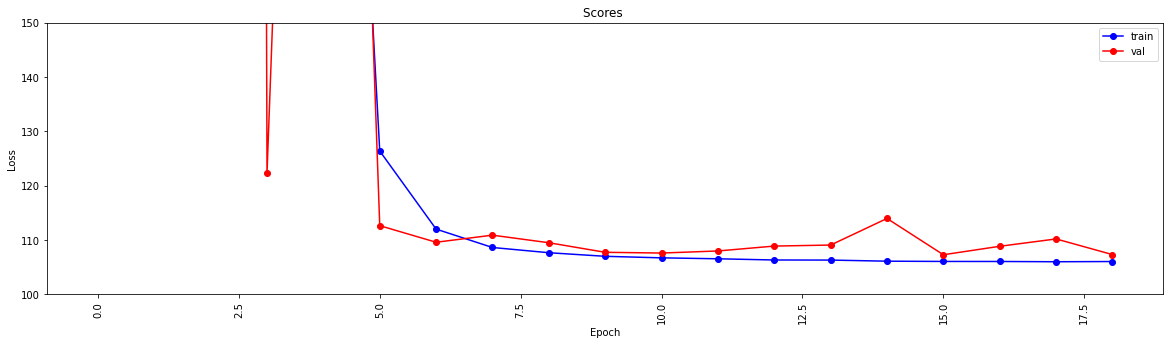
history = model . fit ( X_train , y_train , epochs = 19 , validation_split = 0.5 ) #,batch_size=1)
loss = history . history [ 'loss' ]
val_loss = history . history [ 'val_loss' ]
my_xticks = list ( range ( len ( loss )))
plt . figure ( figsize = ( 20 , 5 ))
plt . plot ( my_xticks , loss , linestyle = '-' , marker = 'o' , color = 'b' , label = "train" )
plt . plot ( my_xticks , val_loss , linestyle = '-' , marker = 'o' , color = 'r' , label = "val" )
plt . title ( "Scores " )
plt . legend ( numpoints = 1 )
plt . ylabel ( "Loss" )
plt . xlabel ( "Epoch" )
plt . xticks ( rotation = 90 )
plt . ylim ([ 100 , 150 ])
plt . show ()
madelname = "./THEMODEL"
model . save ( madelname )
print ( "Model Created!" )
この関数は、トレーニングデータとテストデータが機能抽出を経ているかどうかをチェックします。そうでない場合は、対応する関数を呼び出すことにより、これらのファイルとモデルを作成します。モデルとすべての機能抽出を処理した後、テストデータをフォーマットして最終結果を生成します。
## 1.6 Checking the inputs
from numpy import inf
from numpy import nan
def create_new_files ( train , test ):
model_path = "./THEMODEL/"
my_train_file = 'new_train_features.csv'
my_test_file = 'new_test_features.csv'
if os . path . isfile ( my_train_file ) :
pass
else :
print ( "Please wait! Training data feature extraction is in progress... n it will take about 10 minutes" )
feature_extraction_file ( train , my_train_file , 1 )
print ( "TThe training feature extraction completed!!!" )
if os . path . isfile ( my_test_file ) :
pass
else :
print ( "Please wait! Testing data feature extraction is in progress... n it will take about 100-120 minutes" )
feature_extraction_file ( test , my_test_file , 0 )
print ( "The testing feature extraction completed!!!" )
if os . path . isdir ( model_path ):
pass
else :
print ( "Please wait! Creating the deep learning model... n it will take about 10 minutes" )
create_model ( my_train_file )
print ( "The model file created!!! n n n " )
model = keras . models . load_model ( model_path )
df = pd . read_csv ( my_test_file )
df . replace ([ np . inf , - np . inf ], np . nan , inplace = True )
df = df . fillna ( 0 )
X_train = df [ df . columns [ 0 : - 1 ]]
X_train = np . array ( X_train )
y_train = np . array ( df [ df . columns [ - 1 ]])
predicted = model . predict ( X_train )
print ( "Please wait! Creating resuşts... " )
return predicted このステップは、抽出とモデルの作成プロセスを特徴とし、すべてのプロセスを開始できるようにします。したがって、 test1_test.csvファイルのIDを使用して、この指紋ペアの推定距離で3番目の(変位)列に入力し、名前TASK1-MySubmission.csvという名前でこのファイルをディレクトリに保存します。
## 1.7 Submission
distance_estimate = create_new_files ( train_data , test_ids )
count = 0
output_data = [[ "id1" , "id2" , "displacement" ]]
for id1 , id2 in tqdm ( test_ids ):
output_data . append ([ id1 , id2 , distance_estimate [ count ][ 0 ]])
count += 1
print ( "Process finished. Preparing result file ..." )
with open ( "TASK1-MySubmission.csv" , "w" , newline = '' ) as f :
writer = csv . writer ( f )
writer . writerows ( output_data )
print ( "The results are ready. n See MySubmission.csv" ) Please wait! Creating the deep learning model...
it will take about 10 minutes
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 64) 768
_________________________________________________________________
dense_2 (Dense) (None, 128) 8320
_________________________________________________________________
dense_output (Dense) (None, 1) 129
=================================================================
Total params: 9,217
Trainable params: 9,217
Non-trainable params: 0
_________________________________________________________________
Epoch 1/19
13748/13748 [==============================] - 30s 2ms/step - loss: 2007233.6250 - mae: 161.3013 - val_loss: 218.8822 - val_mae: 11.5630
Epoch 2/19
13748/13748 [==============================] - 27s 2ms/step - loss: 24832.6309 - mae: 53.9385 - val_loss: 123437.0859 - val_mae: 307.2885
Epoch 3/19
13748/13748 [==============================] - 26s 2ms/step - loss: 4028.0859 - mae: 29.9960 - val_loss: 3329.2024 - val_mae: 49.9126
Epoch 4/19
13748/13748 [==============================] - 27s 2ms/step - loss: 904.7919 - mae: 17.6284 - val_loss: 122.3358 - val_mae: 6.8169
Epoch 5/19
13748/13748 [==============================] - 25s 2ms/step - loss: 315.7050 - mae: 11.9098 - val_loss: 404.0973 - val_mae: 15.2033
Epoch 6/19
13748/13748 [==============================] - 26s 2ms/step - loss: 126.3843 - mae: 7.8173 - val_loss: 112.6499 - val_mae: 7.6804
Epoch 7/19
13748/13748 [==============================] - 27s 2ms/step - loss: 112.0149 - mae: 7.4220 - val_loss: 109.5987 - val_mae: 7.1964
Epoch 8/19
13748/13748 [==============================] - 26s 2ms/step - loss: 108.6342 - mae: 7.3271 - val_loss: 110.9016 - val_mae: 7.6862
Epoch 9/19
13748/13748 [==============================] - 26s 2ms/step - loss: 107.6721 - mae: 7.2827 - val_loss: 109.5083 - val_mae: 7.5235
Epoch 10/19
13748/13748 [==============================] - 27s 2ms/step - loss: 107.0110 - mae: 7.2290 - val_loss: 107.7498 - val_mae: 7.1105
Epoch 11/19
13748/13748 [==============================] - 29s 2ms/step - loss: 106.7296 - mae: 7.2158 - val_loss: 107.6115 - val_mae: 7.1178
Epoch 12/19
13748/13748 [==============================] - 26s 2ms/step - loss: 106.5561 - mae: 7.2039 - val_loss: 107.9937 - val_mae: 6.9932
Epoch 13/19
13748/13748 [==============================] - 26s 2ms/step - loss: 106.3344 - mae: 7.1905 - val_loss: 108.8941 - val_mae: 7.4530
Epoch 14/19
13748/13748 [==============================] - 27s 2ms/step - loss: 106.3188 - mae: 7.1927 - val_loss: 109.0832 - val_mae: 7.5309
Epoch 15/19
13748/13748 [==============================] - 27s 2ms/step - loss: 106.1150 - mae: 7.1829 - val_loss: 113.9741 - val_mae: 7.9496
Epoch 16/19
13748/13748 [==============================] - 26s 2ms/step - loss: 106.0676 - mae: 7.1788 - val_loss: 107.2984 - val_mae: 7.2192
Epoch 17/19
13748/13748 [==============================] - 27s 2ms/step - loss: 106.0614 - mae: 7.1733 - val_loss: 108.8553 - val_mae: 7.4640
Epoch 18/19
13748/13748 [==============================] - 28s 2ms/step - loss: 106.0113 - mae: 7.1790 - val_loss: 110.2068 - val_mae: 7.6562
Epoch 19/19
13748/13748 [==============================] - 27s 2ms/step - loss: 106.0519 - mae: 7.1791 - val_loss: 107.3276 - val_mae: 7.0981
INFO:tensorflow:Assets written to: ./THEMODELassets
Model Created!
The model file created!!!
Please wait! Creating resuşts...
100%|████████████████████████████████████████████████████████████████████| 5160445/5160445 [00:08<00:00, 610910.29it/s]
Process finished. Preparing result file ...
The results are ready.
See MySubmission.csv
WiFi距離を評価するためのメトリックがあることを考えると、次のタスクは、モール(最初のチャレンジで使用されているモールとは異なるモール)から、属する別の方法で軌道を分離することです。 、しかし、グラフクラスタリングアプローチを強くお勧めします。
データ内の各WiFi指紋をグラフのノードとして考え、2つの指紋を評価することにより、グラフ内の他の指紋とエッジを形成できることを考えます。指紋と、類似していないものの間には、指紋と低い(またはエッジなし)の間に高い類似性があるエッジに高い重量を割り当てることができます。理論的には、完全に正確な類似性メトリックは、約4メートルを超えるすべてのエッジを除外できるため、床を簡単に分離します(建物の約1階の高さ)。実際には、床の間に誤った縁を作る可能性が高く、これらのエッジを何らかの形で壊す必要があります。
簡単な例から始めましょう。ノードの色が指紋の真の床分類を示している以下のグラフを考えてください。エッジは、これらのノードが同じ床に存在すると考えていることを反映しています。この演習では、グラフ内の任意の2つのノードの間で最短のパスをとることでこのエッジが数回行われる数をカウントするメトリックである、そのエッジが「間のスコア」で事前にラベルを付けました。通常、これにより、接続性が高いことを示すエッジが明らかになり、除去の候補になります。
この例では、Edge-Betwetweennessスコアを使用してグラフコミュニティを検出します。各サブリストにコミュニティのノードIDが含まれているリストのリストを返します。これは、問題の理解を支援するためだけのものであり、実際のソリューションにはカウントされません。
def detect_communities ( Graph ):
## This function should return a list of lists containing
## the node ids of the communities that you have detected.
eb_score = nx . edge_betweenness_centrality ( G )
raise NotImplementedError import networkx as nx
from metrics import check_result
G = nx . read_adjlist ( "graph.adjlist" )
communities = detect_communities ( G )
if check_result ( communities ):
print ( "Correct!" )
else :
print ( "Try again" )この問題のサンプルトレーニングデータは、106981指紋( task2_train_fingerprints.json )とそれらの間のいくつかのエッジのセットです。 3つの異なるエッジタイプを示すファイルを提供しました。これらはすべて異なる方法で処理する必要があります。
task2_train_steps.csv軌跡内で後続のステップを接続するエッジを示します。これらのエッジは、同じ床から2つの指紋が記録されたことを確実に示しているため、非常に信頼される必要があります。
task2_train_elevations.csv手順の反対を示します。これらの標高は、指紋がほぼ間違いなく別の床からのものであることを示しています。したがって、指紋の場合、それを外挿することができます
task2_train_estimated_wifi_distances.csv 、独自の距離メトリックを使用して計算した事前に計算された距離です。このメトリックは不完全であるため、これらのエッジの多くが間違っていることがわかっています(つまり、2フロアをつなぎます)。最初にこのファイルのエッジを使用して、初期グラフを構築し、ソリューションを計算することをお勧めします。ただし、Task1で高いスコアを取得した場合は、グラフを構築するために独自のWiFi距離を計算することを検討する場合があります。
グラフは、軌跡レベルまたは指紋レベルの2つのレベルの詳細のいずれかにある場合があります。使用する表現を選択できますが、最終的には軌道クラスターを知りたいです。軌道レベルには、すべてのノードが軌道として軌道としてあり、ノード間のエッジは、軌跡の指紋が高い類似性を持っている場合に発生します。指紋レベルには、各指紋がノードとして含まれます。 task2_train_lookup.jsonを使用して指紋の軌跡IDを検索して、表現間を変換できます。
ソリューションのデバッグとトレーニングを支援するために、 task2_train_GT.jsonのいくつかの軌跡の基本的な真理を提供しました。このファイルでは、キーは軌道ID( task2_train_lookup.jsonと同じ)であり、値は建物の実際のフロアIDです。
テストセットは、トレーニングセットとまったく同じ形式です(別々の建物の場合、それほど簡単にするつもりはありませんでした;)が、同等のグラウンドトゥルースファイルは含まれていません。これは、あなたのソリューションを獲得できるように源泉徴収されます。
考慮すべき点
このセクションでは、ファイルを開き、両方のタイプのグラフを構築するためのいくつかのサンプルコードを提供します。
import os
import json
import csv
import networkx as nx
from tqdm import tqdm
path_to_data = "task2_for_participants/train"
with open ( os . path . join ( path_to_data , "task2_train_estimated_wifi_distances.csv" )) as f :
wifi = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
wifi . append ([ line [ 'id1' ], line [ 'id2' ], float ( line [ 'estimated_distance' ])])
with open ( os . path . join ( path_to_data , "task2_train_elevations.csv" )) as f :
elevs = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
elevs . append ([ line [ 'id1' ], line [ 'id2' ]])
with open ( os . path . join ( path_to_data , "task2_train_steps.csv" )) as f :
steps = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
steps . append ([ line [ 'id1' ], line [ 'id2' ], float ( line [ 'displacement' ])])
fp_lookup_path = os . path . join ( path_to_data , "task2_train_lookup.json" )
gt_path = os . path . join ( path_to_data , "task2_train_GT.json" )
with open ( fp_lookup_path ) as f :
fp_lookup = json . load ( f )
with open ( gt_path ) as f :
gt = json . load ( f )
これは、グラフ内の各ノードが指紋である指紋レベルのグラフを作成する1つの方法です。 WiFiおよびPDRエッジからそれぞれ推定/真の距離に対応するエッジウェイトを追加しました。また、この関係を示すために標高エッジを追加しました。ソリューションを開発する際に、これらのエッジ(または軌道間の有効な標高エッジ)がないことを明示的に実施することをお勧めします。
G = nx . Graph ()
for id1 , id2 , dist in tqdm ( steps ):
G . add_edge ( id1 , id2 , ty = "s" , weight = dist )
for id1 , id2 , dist in tqdm ( wifi ):
G . add_edge ( id1 , id2 , ty = "w" , weight = dist )
for id1 , id2 in tqdm ( elevs ):
G . add_edge ( id1 , id2 , ty = "e" )軌道グラフは、軌跡間の多くのWiFi接続を表す方法を考える必要があるほど単純ではありません。以下のサンプルグラフでは、平均距離を重量として取得しますが、これは本当に最高の表現ですか?
B = nx . Graph ()
# Get all the trajectory ids from the lookup
valid_nodes = set ( fp_lookup . values ())
for node in valid_nodes :
B . add_node ( node )
# Either add an edge or append the distance to the edge data
for id1 , id2 , dist in tqdm ( wifi ):
if not B . has_edge ( fp_lookup [ str ( id1 )], fp_lookup [ str ( id2 )]):
B . add_edge ( fp_lookup [ str ( id1 )],
fp_lookup [ str ( id2 )],
ty = "w" , weight = [ dist ])
else :
B [ fp_lookup [ str ( id1 )]][ fp_lookup [ str ( id2 )]][ 'weight' ]. append ( dist )
# Compute the mean edge weight
for edge in B . edges ( data = True ):
B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ] = sum ( B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ]) / len ( B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ])
# If you have made a wifi connection between trajectories with an elev, delete the edge
for id1 , id2 in tqdm ( elevs ):
if B . has_edge ( fp_lookup [ str ( id1 )], fp_lookup [ str ( id2 )]):
B . remove_edge ( fp_lookup [ str ( id1 )],
fp_lookup [ str ( id2 )])あなたの提出物は、同じフロアにあると思われる軌跡が、同じ行のインデックスがコンマによって分離されたCSVファイルである必要があります。新しいクラスターはそれぞれ新しい行に入力されます。
たとえば、以下のランダムエントリを参照してください。
import random
random_data = []
n_clusters = random . randint ( 50 , 100 )
for i in range ( 0 , n_clusters ):
random_data . append ([])
for traj in set ( fp_lookup . values ()):
cluster = random . randint ( 0 , n_clusters - 1 )
random_data [ cluster ]. append ( traj )
with open ( "MyRandomSubmission.csv" , "w" , newline = '' ) as f :
csv_writer = csv . writer ( f )
csv_writer . writerows ( random_data )タスク2の手順は、次のように要約できます。
Node2vecを使用してベクトル化されます。TASK2-Mysubmission.csv )は、IDの軌跡に従って準備されています。これらの手順は、下の画像に示されています。

Python 3.6.5を使用してアプリケーションファイルを作成しました。コンテストの開始時に与えられたサンプルファイルに含まれていない追加のモジュールを含めました。これらのモジュールは、次のようにリストできます。
| モルル | タスク |
|---|---|
| Scikit-Learn | 機械学習とデータの準備 |
| node2vec | ネットワークのスケーラブルな機能学習 |
| numpy | 数学操作 |
これらのモジュールを最初のステップとしてインストールすることから始めました。
## 2.1 Installing modules
!p ip install node2vec
!p ip install scikit - learn
!p ip install numpy このステップでは、繰り返し可能な結果を得るために使用される関連ランダムシードを修正しました。このようにして、すべての実行で同じ結果を得る決定論的なパスを提供しました。ただし、観察によると、異なるコンピューターで得られた結果はわずかに異なる場合があります(±1%)
## 2.2 Setting Random Seeds
seed_value = 0
import os
os . environ [ 'PYTHONHASHSEED' ] = str ( seed_value )
import random
random . seed ( seed_value )
import numpy as np
np . random . seed ( seed_value )このセクションでは、テストデータに与えられたファイルがロードされます。
wifi変数はtask2_test_estimated_wifi_distances.csvからIDと重みを取得します。steps変数は、ファイルtask2_test_steps.csvからIDと重みを取得します。elevs変数は、ファイルtask2_test_elevations.csvからIDを取得します。fp_lookup変数task2_test_lookup.jsonファイルからIDと軌道を取得します。このプロセスから得た結果が大きな違いをもたらさなかったため、Task1で得たモデルでWiFiで与えられた推定距離を再計算する方法を好まなかった。そのため、究極の作業でtask2_test_fingerprints.jsonファイルを使用しませんでした。
## 2.3 Loading the data
import os
import json
import csv
import networkx as nx
from tqdm import tqdm
path_to_data = "task2_for_participants/test"
with open ( os . path . join ( path_to_data , "task2_test_estimated_wifi_distances.csv" )) as f :
wifi = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
wifi . append ([ line [ 'id1' ], line [ 'id2' ], float ( line [ 'estimated_distance' ])])
with open ( os . path . join ( path_to_data , "task2_test_elevations.csv" )) as f :
elevs = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
elevs . append ([ line [ 'id1' ], line [ 'id2' ]])
with open ( os . path . join ( path_to_data , "task2_test_steps.csv" )) as f :
steps = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
steps . append ([ line [ 'id1' ], line [ 'id2' ], float ( line [ 'displacement' ])])
fp_lookup_path = os . path . join ( path_to_data , "task2_test_lookup.json" )
with open ( fp_lookup_path ) as f :
fp_lookup = json . load ( f ) 3773297it [00:19, 191689.25it/s]
2767it [00:00, 52461.27it/s]
139537it [00:00, 180082.01it/s]
軌跡グラフを作成するとき、平均距離を重量として取得します。このプロセスには、タスク2( Task2-IPS-Challenge-2021.ipynb )に与えられた例を使用しました。結果のグラフ( B )をディレクトリの隣接リストとして保存しました( my.adjlistとして)。
## 2.3 Generating the Trajectory graph.
B = nx . Graph ()
# Get all the trajectory ids from the lookup
valid_nodes = set ( fp_lookup . values ())
for node in valid_nodes :
B . add_node ( node )
# Either add an edge or append the distance to the edge data
for id1 , id2 , dist in tqdm ( wifi ):
if not B . has_edge ( fp_lookup [ str ( id1 )], fp_lookup [ str ( id2 )]):
B . add_edge ( fp_lookup [ str ( id1 )],
fp_lookup [ str ( id2 )],
ty = "w" , weight = [ dist ])
else :
B [ fp_lookup [ str ( id1 )]][ fp_lookup [ str ( id2 )]][ 'weight' ]. append ( dist )
# Compute the mean edge weight
for edge in B . edges ( data = True ):
B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ] = sum ( B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ]) / len ( B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ])
# If you have made a wifi connection between trajectories with an elev, delete the edge
for id1 , id2 in tqdm ( elevs ):
if B . has_edge ( fp_lookup [ str ( id1 )], fp_lookup [ str ( id2 )]):
B . remove_edge ( fp_lookup [ str ( id1 )],
fp_lookup [ str ( id2 )])
nx . write_adjlist ( B , "my.adjlist" ) 100%|████████████████████████████████████████████████████████████████████| 3773297/3773297 [00:27<00:00, 135453.95it/s]
100%|██████████████████████████████████████████████████████████████████████████████████████| 2767/2767 [00:00<?, ?it/s]
隣接リストを機械学習アルゴリズムへの入力として提供する前に、ノードをベクトルに変換します。私たちの研究では、2016年にGrover&Leskovecによって提案されたグラフ埋め込みアルゴリズム方法論としてnode2vecを使用しました[3]。 node2vecは、ネットワーク内のノードの機能学習のための半監視アルゴリズムです。 node2vecは、分布構造の概念に動機付けられたNLPアプローチであるスキップグラム技術に基づいて作成されます。アイデアに基づいて、同様のコンテキストで使用される異なる単語が同様の意味を持ち、それらの間に明らかな関係があります。 Skip-Gramテクニックは、中心ワード(入力)を使用して、特定のウィンドウサイズ(中央の後の前のアイテムの連続的なシーケンス)、つまりn-gramsに基づいて周囲の確率を計算しながら、近隣(出力)を予測します。 NLPアプローチとは異なり、node2vecシステムには、線形構造を持つ単語ではなく、分布のグラフィック構造を持つノードとエッジが供給されます。この多次元構造により、埋め込みは複雑になり、計算高価になりますが、node2vecは、確率的勾配降下(SGD)を最適化するために最適化する否定的なサンプリングを使用して、それに対処します。これに加えて、ランダムウォークアプローチを使用して、非線形構造でソースノードの隣接するサンプルノードを検出します。
私たちの研究では、2つのノード(重み)の距離からnode2vecをモデル化することにより、低次元空間でのノード関係のベクトル表現を最初に実行しました。次に、ノードのベクトルを備えたnode2vec(グラフ埋め込み)の出力を使用して、従来のk-meansクラスタリングアルゴリズムを供給しました。
nod2vecで使用するパラメーターは、次のようにリストできます。
| ハイパーパラメーター | 価値 |
|---|---|
| 寸法 | 32 |
| walk_length | 15 |
| num_walks | 100 |
| 労働者 | 1 |
| シード | 0 |
| ウィンドウ | 10 |
| min_count | 1 |
| batch_words | 4 |
node2vecモデルは、隣接リストを入力として取得し、32サイズのベクトルを出力します。この部分では、node.pyファイルが作成され、 Jupyter Notebookで実行されます。 Jupyter Notebookセルよりも外部で実行することが望ましい理由は2つあります。
Node2vecは非常に計算的に高価な方法です。JupyterNotebook内で実行すると、RAMオーバーフローエラーは非常に可能です。 Node2vecモデルの作成と実行外では、このエラーは回避されます。以下のセルは、node.pyという名前のファイルを作成します。このファイルは、node2vecモデルを作成します。このモデルは、隣接リスト( my.adjlist )を入力として取得し、32次元ベクトルファイルを出力( vectors.emb )として作成します。
重要!以下のコードは、Linuxディストリビューション(Google ColabおよびUbuntuでテストされている)で実行する必要があります。
# 2.4 Converting nodes to vectors
# A folder named tmp is created. This folder is essential for the node2vec model to use less RAM.
try :
if not os . path . exists ( "tmp" ):
os . makedirs ( "tmp" )
except OSError :
print ( "The folder could not be created! n Please manually create the " tmp " folder in the directory" )
node = """
# importing related modules
from node2vec import Node2Vec
import networkx as nx
#importing adjacency list file as B
B = nx.read_adjlist("my.adjlist")
seed_value=0
# Specifying the input and hyperparameters of the node2vec model
node2vec = Node2Vec(B, dimensions=32, walk_length=15, num_walks=100, workers=1,seed=seed_value,temp_folder = './tmp')
#Assigning/specifying random seeds
import os
os.environ['PYTHONHASHSEED']=str(seed_value)
import random
random.seed(seed_value)
import numpy as np
np.random.seed(seed_value)
# creation of the model
model = node2vec.fit(window=10, min_count=1, batch_words=4,seed=seed_value)
# saving the output vector
model.wv.save_word2vec_format("vectors.emb")
# save the model
model.save("vectorMODEL")
"""
f = open ( "node.py" , "w" )
f . write ( node )
f . close ()
! PYTHONHASHSEED = 0 python3 node . py ベクトルファイルが作成された後、このファイル( vectors.emb )を読み取ります。このファイルは33列で構成されています。最初の列はノード番号(IDS)であり、残りはベクトル値です。ファイル全体を最初の列でソートすることにより、ノードを元の注文に返します。次に、このID列を削除しますが、使用しなくなります。そのため、データの最終的な形状を提供します。私たちのデータは、機械学習アプリケーションで使用する準備ができています。
# 2.4 Reshaping data
vec = np . loadtxt ( "vectors.emb" , skiprows = 1 )
print ( "shape of vector file: " , vec . shape )
print ( vec )
vec = vec [ vec [:, 0 ]. argsort ()];
vec = vec [ 0 : vec . shape [ 0 ], 1 : vec . shape [ 1 ]] shape of vector file: (11162, 33)
[[ 9.1200000e+03 3.9031842e-01 -4.7147268e-01 ... -5.7490986e-02
1.3059708e-01 -5.4280665e-02]
[ 6.5320000e+03 -3.5591956e-02 -9.8558587e-01 ... -2.7217887e-02
5.6435770e-01 -5.7787680e-01]
[ 5.6580000e+03 3.5879680e-01 -4.7564098e-01 ... -9.7607370e-02
1.5506668e-01 1.1333219e-01]
...
[ 2.7950000e+03 1.1724627e-02 1.0272172e-02 ... -4.5596390e-04
-1.1507459e-02 -7.6738600e-04]
[ 4.3380000e+03 1.2865483e-02 1.2103912e-02 ... 1.6619096e-03
1.3672550e-02 1.4605848e-02]
[ 1.1770000e+03 -1.3707868e-03 1.5238028e-02 ... -5.9994194e-04
-1.2986251e-02 1.3706315e-03]]
タスク2はクラスタリングの問題です。この問題を解決するときに決定する必要があるという前提は、分割するクラスターの数です。このために、さまざまなクラスター番号を試して、得たスコアを比較しました。以下のグラフは、クラスターの数と得られたスコアの比較を示しています。このグラフからわかるように、クラスターの数は5から21の間で継続的に増加し、いくつかの例外変動を除いて21後に安定しました。このため、私たちは研究で21から23のクラスターの数に焦点を合わせました。
# 2.5 Determine the number of clusters
import numpy as np
import matplotlib . pyplot as plt
import seaborn as sns
import matplotlib
% matplotlib inline
sns . set_style ( "whitegrid" )
agglom = [ 24.69 , 28.14 , 28.14 , 28.14 , 30 , 33.33 , 40.88 , 38.70 , 40 , 40 , 40 , 29.12 , 45.85 , 45.85 , 48.00 , 50.17 , 57.83 , 57.83 , 57.83 ]
plt . figure ( figsize = ( 10 , 5 ))
plt . plot ( range ( 5 , 24 ), agglom )
matplotlib . pyplot . xticks ( range ( 5 , 24 ))
plt . title ( 'Number of clusters and performance relationship' )
plt . xlabel ( 'Number of clusters' )
plt . ylabel ( 'Score' )
plt . show ()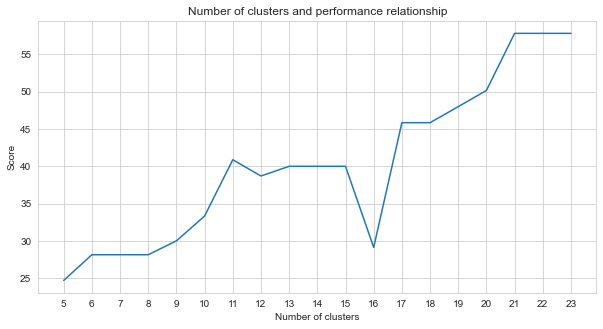
私たちが試した監視されていない機械学習方法(K-means、凝集クラスタリング、アフィニティ伝播、平均シフト、スペクトルクラスタリング、DBSCAN、光学系、ミニバッチKマーンズなど)の中で、K-Meansを使用して最良の結果を達成しました23のクラスター付き。
K-Meansはクラスタリングアルゴリズムであり、非標識データを使用して均一または自然な要素グループ(クラスター)を見つけるために仮定を立てる基本的および従来の非監視されていない機械学習技術の1つです。クラスターは、特定の類似点を共有する一連のポイント(データのノード)をグループ化します。 K-meansには、データを分割するグループの数を指す目標数の重心数が必要です。アルゴリズムは、ランダムに割り当てられた重心のグループから始まり、それらの最良の位置を見つけるために繰り返しを継続します。アルゴリズムは、ポイントのメンバーの正方形の合計をクラスター内で使用して、ポイント/ノードを指定された重心に割り当てます。これは、継続的な更新と再配置です[4]。この例では、重心の数は床の数を反映しています。これは、床の順序に関する情報を提供しないことに注意する必要があります。
以下では、K-Meansアプリケーションが23のクラスターに対して行われました。
# 2.5 Best result
from sklearn import cluster
import time
ML_results = []
k_clusters = 23
algorithms = {}
algorithms [ 'KMeans' ] = cluster . KMeans ( n_clusters = k_clusters , random_state = 10 )
second = time . time ()
for model in algorithms . values ():
model . fit ( vec )
ML_results = list ( model . labels_ )
print ( model , time . time () - second ) KMeans(n_clusters=23, random_state=10) 1.082334280014038
機械学習アルゴリズムの出力は、指紋がどのクラスターに属するかを決定します。しかし、私たちに必要なのは、軌跡を束ねることです。したがって、これらの指紋は、 fp_lookup変数を使用して軌道の対応物に変換されます。この出力はTASK2-Mysubmission.csvファイルに処理されます。
## 2.6 Submission
result = {}
for ii , i in enumerate ( set ( fp_lookup . values ())):
result [ i ] = ML_results [ ii ]
ters = {}
for i in result :
if result [ i ] not in ters :
ters [ result [ i ]] = []
ters [ result [ i ]]. append ( i )
else :
ters [ result [ i ]]. append ( i )
final_results = []
for i in ters :
final_results . append ( ters [ i ])
name = "TASK2-Mysubmission.csv"
with open ( name , "w" , newline = '' ) as f :
csv_writer = csv . writer ( f )
csv_writer . writerows ( final_results )
print ( name , "file is ready!" ) TASK2-Mysubmission.csv file is ready!
[1] P. VirtanenおよびScipy 1.0の寄稿者。 Scipy 1.0:Pythonの科学コンピューティングの基本的なアルゴリズム。自然方法、17:261--272、2020。
[2] A. Geron、Scikit-Learn、Keras、およびTensorflowを使用した実践的な機械学習:インテリジェントシステムを構築するための概念、ツール、およびテクニック。 O'Reilly Media、2019年
[3] A.グローバー、J。Leskovec。 ACM SIGKDD知識発見とデータマイニングに関する国際会議(KDD)、2016年。
[4] Jin X.、Han J.(2011)K-Means Clustering。 In:Sammut C.、Webb Gi(eds)Encyclopedia of Machine Learning。マサチューセッツ州ボストンのスプリンガー。 https://doi.org/10.1007/978-0-387-30164-8_425


