Noise Reduction
1.0.0

プロジェクトについて
技術スタック
ファイル構造
はじめる
結果とデモ
将来の仕事
貢献者
謝辞とリソース
ライセンス
信号を除去すると除去される非環境ノイズのように自然に誘導されるノイズを除去する必要がありました。このドキュメントを参照してくださいAIノイズリダクションに関するこのブログ
オーディオマンピレーションのためのLibrosaライブラリが使用されます。
オーディオ信号には、Scipyを使用しました
MATPLOTLIBは、データを操作して信号を視覚化するために使用されます。
残りは数学的操作のためにnumpyであり、ウェーブファイルで動作するための波です。
Noise Reduction ├───docs ## Documents and Images │ └───Input Audio file ├─── Project Details │ | │ ├─── │ │ ├───Research papers │ │ ├───Linear Algebra │ │ ├───Neural networks & Deep Learning │ │ ├───Project Documentation │ │ ├───AI Noise Reduction Blog │ │ ├───AI Noise Reduction Report │ │ └───Code Implementation │ │ ├───AI Noise Reduction.py │ │ ├───audio.wav │ │ ├───Resources
Windowsでテストされています
git clone https://github.com/dhriti03/noise-reduction.gitcdノイズ還元
ノートに特定のライブラリをインストールします
ピップインストール波 PIPインストールLIBROSA PIPインストールScipy.io PIPインストールmatplotlib.pyplot
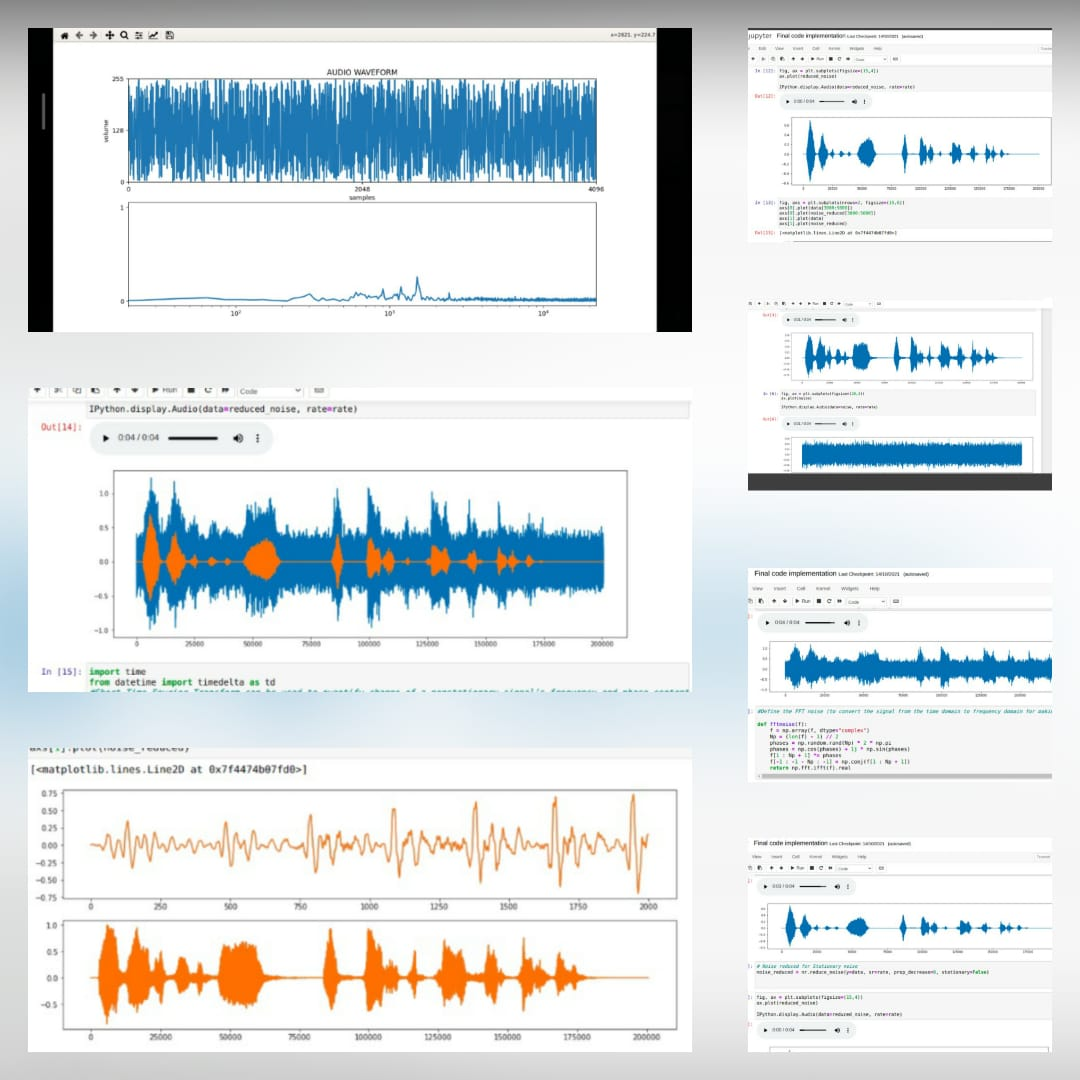
*これは元のオーディオファイルです * 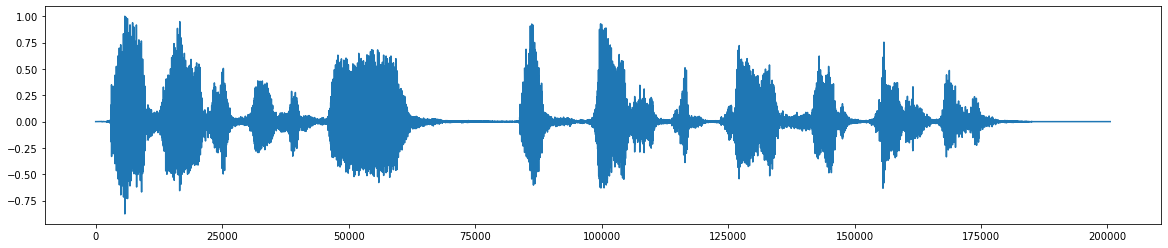 *ノイズの追加後 *
*ノイズの追加後 * 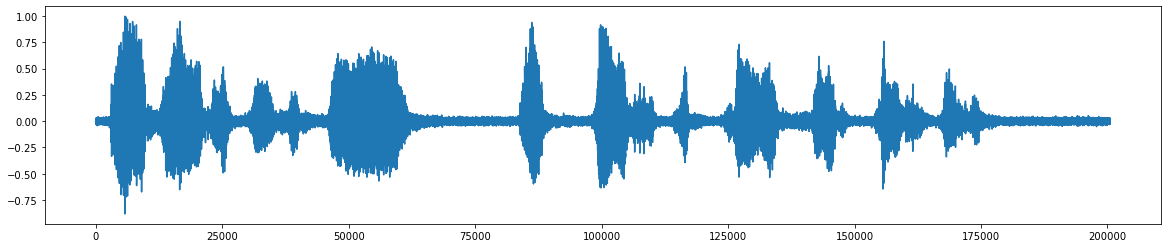 *ノイズを削除した後の最終的なオーディオ信号 *
*ノイズを削除した後の最終的なオーディオ信号 * 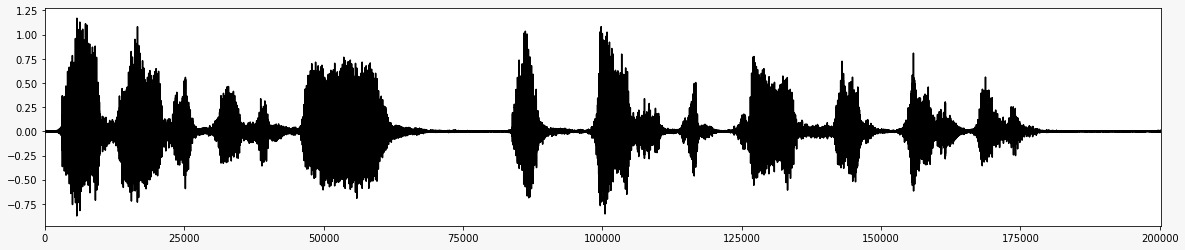 *プロジェクトのフローチャート *
*プロジェクトのフローチャート * 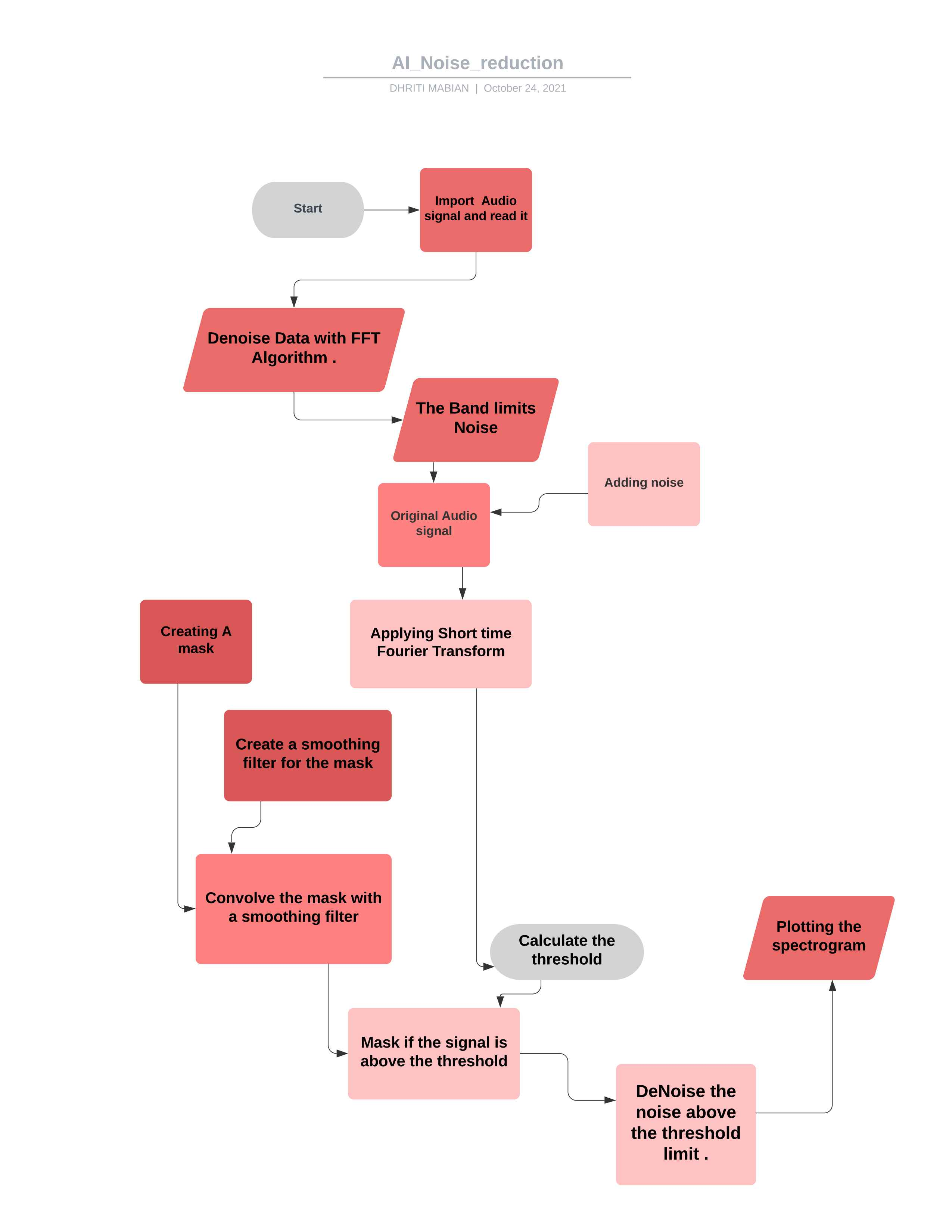
要件に応じてコードを操作すると、オーディオサインラのほとんどを制御するために使用できます。 ##理論
FFTは、ノイズオーディオクリップ上で計算されます
統計は、ノイズのFFT(頻度)で計算されます
しきい値は、ノイズの統計(およびアルゴリズムの望ましい感度)に基づいて計算されます。
マスクは、信号FFTをしきい値と比較することにより決定されます
マスクは、周波数と時間を超えてフィルターで滑らかになっています
マスクは信号のFFTに装着され、反転します
scipy.ioからipythonをインポートwavfileimport scipy.signalimport numpy as npimpoptlotlib.pyplotとしてpltimport librosaimport wave%matplotlib inline
ここでは、インタラクティブおよび探索的コンピューティングのための包括的な環境を作成するために使用されるIPython Libのようなライブラリをインポートしています。
Scipy.ioから、幅広いPythonコマンドを使用してデータのデータと視覚化を操作するために使用されます。
Numpyには、多次元配列とマトリックスのデータ構造が含まれています。したがって、三角、統計、および代数ルーチンなどのアレイで多くの数学的操作を実行するために使用できます。したがって、非常に有用なライブラリです。
matplotlib.pyplotライブラリは、さまざまな視覚化を通じて膨大な量のデータを理解するのに役立ちます。
Librosaは、音楽生成(LSTMを使用)、自動音声認識のようなオーディオデータを使用するときに使用します。音楽情報検索システムを作成するために必要なビルディングブロックを提供します。
%MATPLOTLIBインラインインラインプロットを有効にします。ここでは、プロット/グラフがプロットコマンドが書かれているセルのすぐ下に表示されます。 Jupyter Notebookのようなフロントエンドのバックエンドとのインタラクティブ性を提供します。
wav_loc = r '/home/nose_reduction/downloads/wave/file.wav'rate、data = wavfile.read(wav_loc、mmap = false)
ここでは、WAWファイルパスの場所を取り、 Scipy.ioライブラリからのWawfileモジュールを使用してそのWAWファイルを読み取ります。パラメーター(ファイル名 - 入力WAVファイルである文字列または開くファイルハンドル)を使用します。
def fftnoise(f):f = np.array(f、dtype = "complex")np =(len(f)-1)// 2phase = np.random.rand(np) * 2 * np.piphase = np .cos(phases) + 1j * np.sin(phases)f [1:np + 1] * = phasef [-1:-1 -np:-1] = np.conj(f [1:np + 1] )np.fft.ifft(f).realを返します
ここでは、最初にFFTノイズ関数を簡単に定義します。高速フーリエ変換(FFT)は、シーケンスの離散フーリエ変換(DFT)またはその逆(IDFT)を計算するアルゴリズムです。フーリエ分析は、元のドメイン(多くの場合、時間または空間)から信号を周波数領域の表現に変換し、その逆も同様です。 DFTは、さまざまな周波数のコンポーネントに一連の値を分解することにより取得されます。
高速フーリエ変換を使用し、データ型複合体の関数を定義し、最後に関数の実際の部分を計算します。これでは、最小周波数と最大周波数の範囲の範囲が1に設定され、不要な休息が無視されます。
ファイルの場所を与えます
WAVファイルを読む
-32767〜 +32767は適切なオーディオ(対称)であり、32768はその時点でオーディオがクリップされたことを意味します
WAVファイルは16ビット整数であり、範囲は[-32768、32767]であるため、32768(2^15)で除算されます。
def band_limited_noise(min_freq、max_freq、samplys = 1024、samplerate = 1):freqs = np.abs(np.fft.fftfreq(サンプル、1 /サンプル))f = np.zeros(サンプル)f [np.logical_and(freqs > = min_freq、freqs <= max_freq)] = 1return fftnoise(f)
フーリエ変換が有限範囲の周波数または波長に制限される関数または時系列。
MINと最大制限で標準FREQでFREQを定義します。
noise_len = 2#secondsnoise = band_limited_noise(min_freq = 4000、max_freq = 12000、samples = len(data)、samplerate = rate)*10noise_clip =ノイズ
バンド制限されたホワイトノイズブロックは、ユニットがHzである両面スペクトルを指定します。
12000の最大値と4000の最小FREQが、ノイズと提供されたデータと比較されます。
ここでは、速度の積とノイズ信号のレンを持つことにより、ノイズ信号を切り取っています。
したがって、ノイズと指定されたデータを追加します
実際には、ノイズを追加すると、トレーニングデータセットのサイズが拡大します。
ランダムなノイズが入力変数に追加され、モデルにさらされるたびに異なるようになります。
入力サンプルにノイズを追加することは、データ増強の単純な形式です。
ノイズを追加するということは、ネットワークが常に変化しているため、トレーニングサンプルを暗記することができないことを意味します。
その結果、ネットワークの重みが小さくなり、一般化エラーが低いより堅牢なネットワークが得られます。
Timefrom Import Import TimedeltaをTDとしてインポートします
インポート時間このモジュールは、さまざまな時間関連機能を提供します。関連する機能については、DateTimeおよびCalendarモジュールも参照してください。クラスDateTime.timedelta
2つの日付、時間、またはデータタイムインスタンスの違いをマイクロ秒分解能に表現する期間。
def _stft(y、n_fft、hop_length、win_length):return librosa.stft(y = y、n_fft = n_fft、hop_length = hop_length、win_length = win_length)
短時間のフーリエ変換を使用して、非定常信号の周波数と位相含有量の変化を時間の経過とともに定量化できます。
ホップの長さは、連続したフレーム間のサンプルの数を指す必要があります。信号分析の場合、ホップの長さはフレームサイズよりも低く、フレームが重複するようにする必要があります。
パラメーターynp.ndarray [shape =(n、)]、実際の入力信号
n_fftint> 0 [スカラー]
ゼロでパディングした後のウィンドウ付き信号の長さ。 STFTマトリックスDの行数は(1 + n_fft/2)です。デフォルト値、N_FFT = 2048サンプルは、22050 Hzのサンプルレートで93ミリ秒の物理期間、つまりLIBROSAのデフォルトサンプルレートに対応します。この値は、音楽信号に適しています。ただし、音声処理では、推奨される値は512で、22050 Hzのサンプルレートで23ミリ秒に相当します。いずれにせよ、高速フーリエ変換(FFT)アルゴリズムの速度を最適化するために、N_FFTを2の電力に設定することをお勧めします。
hop_lengthint> 0 [scalar]
隣接するSTFT列間のオーディオサンプルの数。
値が小さく、STFTの周波数解像度に影響を与えることなく、Dの列の数を増やします。
不特定の場合、デフォルトはwin_length // 4になります(以下を参照)。
win_lengthint <= n_fft [scalar]
オーディオの各フレームは、長さのwin_lengthのウィンドウでウィンドウにされ、Zerosでパディングしてn_fftに一致します。
値が小さく、周波数解像度を犠牲にしてSTFTの時間分解能(つまり、時間内に密接に間隔を空けている衝動を区別する能力)を改善します(つまり、周波数が密接に間隔を空けている純粋なトーンを区別する能力)。この効果は、時間周波数のローカリゼーショントレードオフとして知られており、入力信号yのプロパティに従って調整する必要があります。
不特定の場合、デフォルトはwin_length = n_fftになります。
return librosa.istft(y、hop_length、win_length)
逆短時間のフーリエ変換(ISTFT)。複雑な値のスペクトログラムSTFT_MATRIXをタイムシリーズYに変換し、STFT_MATRIXとYのSTFTの間の平均二乗誤差を最小化することにより、
一般に、ウィンドウ関数、ホップの長さ、その他のパラメーターはSTFTと同じでなければなりません。これは、主に変更されていないSTFT_MATRIXからの信号の完全な再構築につながります。
def _amp_to_db(x):return librosa.core.amplitute_to_db(x、ref = 1.0、amin = 1e-20、top_db = 80.0)
1.振幅スペクトログラムをdb-scaledスペクトログラムに変換します。これはpower_to_db(s ** 2)に相当しますが、便利なために提供されています。
return librosa.core.db_to_amplitude(x、ref = 1.0)
DBスケールのスペクトログラムを振幅スペクトログラムに変換します。
これは効果的にamplitude_to_dbを反転させます:
db_to_amplitude(s_db)〜= 10.0 (0.5*(s_db + log10(ref)/10))**
def plot_spectRogram(信号、タイトル):fig、ax = plt.subplots(figsize =(20、4))cax = ax.matshow(signal、ogin = "dower"、aspect = "auto"、cmap = plt.cm。地震、vmin = -1 * np.max(np.abs(信号))、vmax = np.max(np.abs(信号))、
))入力として信号を使用して分光図をプロットします。
軸クラスには、軸、ティック、ライン2D、テキスト、ポリゴンなどのほとんどの図要素が含まれており、座標系を設定します。
この関数を介してアクセス可能なMatplotlibの複数のカラーマップを提供します。oデータセットの3Dカラースペースで適切な表現を見つけます。
fig.colorbar(cax)ax.set_title(title)
何が起こっているのかを見る最良の方法は、散布図を作成した後、ColorBar(plt.colorbar())を追加することです。 0〜10000の間のout値はすべて、物事が非常に薄い緑色であるバーの最下部の部分を下回っていることに注意してください。
一般に、VMIN以下の値は最も低い色で着色され、VMAXの上の値は最高色になります。
VMAXをVMINよりも小さく設定すると、内部的に交換されます。ただし、MATPLOTLIBの正確なバージョンと呼ばれる正確な関数に応じて、MATPLOTLIBはエラー警告を与える可能性があります。したがって、VMINを常にVMAXよりも低く設定するのが最善です。
def plot_statistics_and_filter(mean_freq_noise、std_freq_noise、noise_thresh、smoothing_filter):ax、ax = plt.subplots(ncols = 2、figsize =(20、4))plt_std、= ax [0] .plot(std_freq_noise、 "std。ノイズの ")
plt_std、= ax [0] .plot(noise_thresh、label = "ノイズしきい値(頻度)")ax [0] .set_title( "マスクのしきい値"))
ax [0] .legend()cax = ax [1] .matshow(smoothing_filter、origin = "lower")fig.colorbar(cax)ax [1] .set_title( "スムージングマスクのフィルター"))ノイズリダクションの基本統計をプロットします。
信号対雑音比(SNRまたはS/N)は、科学と工学で使用される尺度であり、目的の信号のレベルをバックグラウンドノイズのレベルと比較します。
SNRは、デシベルでしばしば表現されるノイズパワーに対する信号電力の比率として定義されます。
1:1(0 dBを超える)を超える比率は、ノイズよりも多くの信号を示します。
ノイズマスキングの閾値周波数を設定します。
マスキングしきい値とは、別のサウンドが存在するため、1つの音が聞こえなくレンダリングされるプロセスを指します。
したがって、マスキングのしきい値は、「マスカー」と呼ばれる別のノイズの存在下で音を聞くために必要な音の音の圧力レベルです。
したがって、しきい値を追加しました。
さまざまなローパスフィルターを備えたぼやけノイズ信号
カスタムメイドのフィルターを画像に適用します(2D畳み込み)
def removenoise(#トライアングル波の正斜面部分(上昇)の信号(電圧)を平均して、できるだけ多くのノイズを除去しようとする。 Operations noise_clip、n_grad_freq = 2、#mask.n_grad_time = 4で滑らかにする周波数チャネルの数、mask.n_fft = 2048、#stft columns.win_length = frames of frames 2048、#各フレームは「ウィンドウ()」でウィンドウになります。 n_std_thresh = 1.5、#signalprop_decrease = 1.0と見なされるノイズの平均db(各周波数レベル)よりも大きい標準偏差の数、#ノイズを減らすべき範囲(1 = all、0 = none)verbose = false 、#フラグを使用すると、表示可能なvisual = falseに見える正規表現を作成できます。
def removenoise(三角波の正斜面部分(上昇)の信号(電圧)を平均して、できるだけ多くのノイズを除去しようとします。
audio_clip、
これらのクリップは、それぞれの操作を行うパラメーターです
noise_clip、 n_grad_freq = 2マスクで滑らかにする周波数チャネルの数。
n_grad_time = 4、マスクで滑らかにする時間チャネルの数。
n_fft = 2048
STFT列間のフレームの番号オーディオ。
win_length = 2048、オーディオの各フレームはwindow()によってウィンドウが付けられています。ウィンドウは長さのwin_lengthになり、Zerosでパディングしてn_fftに一致します。
hop_length = 512、 stft列間のフレームの数のオーディオ。
N_STD_THRESH = 1.5ノイズの平均dB(各周波数レベル)よりも大きい標準偏差の数
prop_decrease = 1.0、どの程度ノイズを減らすべきか(1 = all、0 = none)
verbose = false、
フラグを使用すると、表示可能なvisual = falseに見える正規表現を作成できます。#アルゴリズムの手順をプロットするかどうか):
noise_stft = _stft(noise_clip、n_fft、hop_length、win_length)noise_stft_db = _amp_to_db(np.abs(noise_stft))
STFT Over Noise
DBに変換します
mean_freq_noise = np.mean(noise_stft_db、axis = 1)std_freq_noise = np.std(noise_stft_db、axis = 1)noise_thresh = mean_freq_noise + std_freq_noise * n_std_thresh
ノイズ上の統計を計算します
ここでは、しきいノイズについては、平均と標準ノイズ、およびN_STDノイズを追加します。
sig_stft = _stft(audio_clip、n_fft、hop_length、win_length)sig_stft_db = _amp_to_db(np.abs(sig_stft))
STFT上の信号
mask_gain_db = np.min(_amp_to_db(np.abs(sig_stft)))
dbをマスクする値を計算します
smoothing_filter = np.outer(np.concatenate(
[np.linspace(0、1、n_grad_freq + 1、endpoint = false)、np.linspace(1、0、n_grad_freq + 2)、
]
)[1:-1]、np.concatenate(
[np.linspace(0、1、n_grad_time + 1、endpoint = false)、np.linspace(1、0、n_grad_time + 2)、
]
)[1:-1]、
)smoothing_filter = smoothing_filter / np.sum(smoothing_filter)時間と頻度でマスクのスムージングフィルターを作成する
db_thresh = np.repeat(np.reshape(noise_thresh、[1、len(mean_freq_noise)])、np.shape(sig_stft_db)[1]、axis = 0、
).T各周波数/タイムビンのしきい値を計算します
sig_mask = sig_stft_db <db_thresh
信号用のマスク
sig_mask = scipy.signal.fftconvolve(sig_mask、smoothing_filter、mode = "same")sig_mask = sig_mask * prop_decrease
スムージーフィルターを備えたマスク畳み込み
#signalig_stft_db_masked =(sig_stft_db *(1 -sig_mask)+ np.shape(mask_gain_db)) * mask_mask) _to_amp (sig_stft_db_masked) * np.sign(sig_stft)) +(1j * sig_imag_masked)
信号をマスクします
#信号Recovered_signal = _istft(sig_stft_amp、hop_length、win_length)recovered_spec = _amp_to_db(np.abs(_stft(recovered_signal、n_fft、hop_length、win_length))
))信号を回復します
したがって、信号がしきい値を超えている場合はマスクを適用します
スムージングフィルターでマスクを連結します
既にダウンロードしたWAVファイルにノイズリダースアルゴリズムを適用します。
オーディオ信号のライブ記録にFFTを適用します。
ノイズキャンセルのためのAIのさらに深い実装。
さまざまな形式のオーディオファイルにノイズリダースアルゴリズムを適用します。
マイクとESP32を使用したライブオーディオ信号を使用するため、さらに計算および信号処理のためにWAVファイルを取得します。
Dhriti Mabian
Priyal Awankar
*SRA VJTI_EKLAVYA 2021
シュレヤアトレ
厳しいシャー
大胆さ
ノイズキャンセル方法
マーティンハインツからボイラープレートを取りました
ティム・セインバーグ
ライセンス


