mario ai
1.0.0
このプロジェクトには、入力として生のピクセルのみを使用してスーパーマリオワールドの最初のレベルを自動的に再生するモデルをトレーニングするコードが含まれています(手工学的機能なし)。使用済みの手法は、Atari Paper(要約)に記載されているように、空間変圧器と組み合わせた深いQラーニングです。
トレーニング方法は、リプレイメモリを使用した深いQラーニングです。つまり、モデルはスクリーンのシーケンスを観察し、メモリに保存し、後にトレーニングを行います。「トレーニング」は、予想されるアクション報酬値を正確に予測することを学習することを意味します(」アクションは、収集された記憶に基づいて、「ボタンXを押す」を意味します。リプレイメモリには、デフォルトでは250Kエントリのサイズがあります。それがいっぱいになり始めると、新しいエントリは古いエントリを置き換えます。トレーニングバッチの場合、例はランダムに選択され(均一な分布)、メモリの報酬は、これまでネットワークが学んだことに基づいて再推定されます。
各例の入力には、次の構造があります。
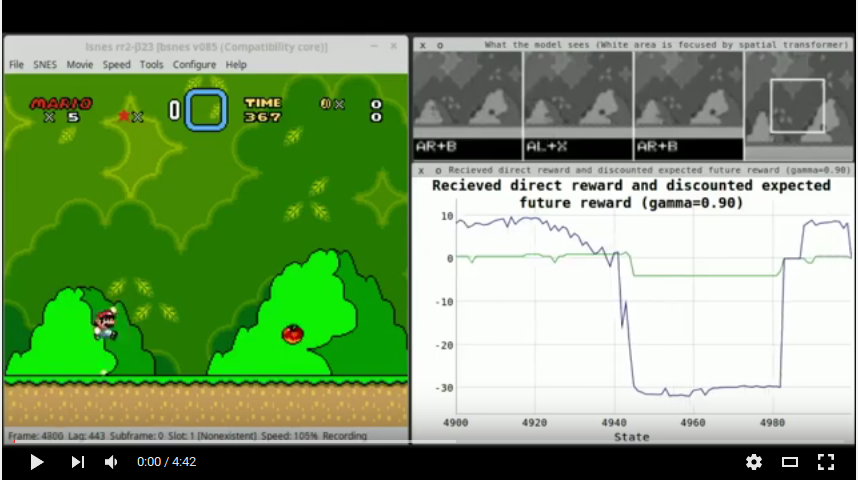
Tは現在4に設定されています(これには、シーケンスの最後の状態が含まれていることに注意してください)。画面は5番目のフレームごとにキャプチャされます。各例の出力は、選択したアクションのアクション報酬値です(直接報酬 +次の状態の割引Q値を受け取ります)。モデルは、状態ごとに2つのアクションを選択できます。1つの矢印ボタン(上、下、右、左)と他のコントロールボタン(A、B、X、Y)の1つです。これは、エージェントが一度に1つのボタンしか選択できなかったAtari-Modelとは異なります。 (この変更がなければ、エージェントは理論的には多くのジャンプを行うことができません。これにより、Aボタンを押して右に移動するように強制します。)報酬関数は、ほぼ0、正確に2つの2つであるように構築されているため各例の出力値はゼロではないと予想されます。
エージェントは次の報酬を受け取ります。
+0.5エージェントが右に移動した場合、右に速く移動した場合は+1.0 (最後のゲーム状態と比較して8ピクセル以上)、左に移動した場合は-1.0 、場合は-1.5左に速く移動しました(-8ピクセル以上)。+2.0レベルフィニッシュアニメーションが再生されている間。-3.0死のアニメーションが再生されている間。 gamma (予想/間接報酬の割引)は0.9に設定されています。
スコアのみでモデルをトレーニングするのは(Atari Paperのように)増加する可能性が高いため、敵は画面の外側を動かすと敵が再び覆われているため、エージェントはスコアを増やすたびに何度も殺すことができます。
選択的MSEは、エージェントのトレーニングに使用されます。つまり、各例について、勾配はMSEのように計算されます。ただし、すべてのアクション値の勾配は、ターゲット報酬が0の場合は0に設定されます。これは、選択したボタンの1組(矢印ボタン、その他のボタン)に対する受信された報酬のみが含まれているためです。他のアクションのペアは可能だったでしょうが、エージェントはそれらを選択しなかったため、それらに対する報酬は不明です。彼らの報酬値(例ごと)は0に設定されていますが、それらが本当に0だったからではなく、代わりにエージェントが選択した場合にどのような報酬が受け取ったかわからないためです。したがって、それらのバックプロパゲート勾配(つまり、エージェントが0に不等に値を予測する場合)は合理的ではありません。
この実装は、選択されたボタンの受信された報酬が(ここで)正確に0であるため(ここでは)、0に不平等であることに基づいて、選択されたボタンと選択されていないボタン(ターゲットベクトル内)を区別する余裕があります(ここでは)報酬関数)。他の実装は、このステップをより注意深くする必要があるかもしれません。
このポリシーは、Epsilon = 0.8で始まり、400K番目の選択したアクションで0.1にアニールするEpsilon-Greedyのものです。ポリシーに従ってランダムアクションを選択する必要がある場合は、エージェントがコイン(つまり50:50のチャンス)を投げ、2つの(矢印、その他のボタン)アクションのいずれかをランダム化するか、両方をランダム化します。
モデルは3つのブランチで構成されています。
ブランチの端では、出力ニューロンに到達する前に、すべてが隠れた層を通って供給され、1つのベクトルにマージされます。これらの出力ニューロンは、押されたボタンごとに予想される報酬を予測します。
ネットワークの概要:

空間変圧器には、以下に示すローカリゼーションネットワークが必要です。

両方のネットワークには、全体で約660万パラメーターがあります。
エージェントは、最初のレベルでのみトレーニングされます(最初のオーバーワールドの最初の右)。他のレベルは、エージェントがほとんど対処できないさまざまな困難から大きく苦しんでいます。これらのいくつかは次のとおりです。
最初のレベルはこれらの困難のどれもほとんどないため、DQNに役立ちます。そのため、ここで使用されています。あらゆるレベルでトレーニングしてから別のレベルでテストすることもかなり困難です。各レベルは、新しい敵やまったく異なる敵や新しいメカニック(登山、新しいアイテム、死に絞るオブジェクトなど)などの新しいものを導入しているようです。
luarocks install packageName ): nn 、 cudnn 、 paths 、 image 、 display 。ディスプレイは通常、トーチの一部ではありません。git clone https://github.com/qassemoquab/stnbhwd.gitcd stnbhwdluarocks make stnbhwd-scm-1.rockspecsudo apt-get install sqlite3 libsqlite3-devluarocks install lsqlite3source/src/libray/lua.cppとnamespace { : #ifndef LUA_OK
#define LUA_OK 0
#endif
#ifdef LUA_ERRGCMM
REGISTER_LONG_CONSTANT("LUA_ERRGCMM", LUA_ERRGCMM, CONST_PERSISTENT | CONST_CS);
#endif
source/include/core/controller.hppおよび関数を変更するdo_button_actionプライベートからパブリックに変更します。 Line void do_button_action(const std::string& name, short newstate, int mode); private:ブロックしてpublic:ブロック。source/src/lua/input.cppおよびlua::functions LUA_input_fns(... (ファイルの最後で)挿入: int do_button_action(lua::state& L, lua::parameters& P)
{
auto& core = CORE();
std::string name;
short newstate;
int mode;
P(name, newstate, mode);
core.buttons->do_button_action(name, newstate, mode);
return 1;
}
core.lua2->input_controllerdata設定されないため、エミュレータのデフォルトのすべての機能は機能しません。source/src/lua/input.cppで、block lua::functions LUA_input_fns(... 、 do_button_actionを追加します。それを行うには、ラインを変更します。 {"controller_info", controller_info}, {"controller_info", controller_info}, {"do_button_action", do_button_action},source/に戻ります。makeでエミュレータをコンパイルします。options.buildでそれを無効にします。libwxgtk3.0-devをインストールしてください。source/ exute sudo cp lsnes /usr/bin/ && sudo chown root:root /usr/bin/lsnesから。その後、コンソールウィンドウでlsnes入力するだけでLSNESを開始できます。sudo mkdir /media/ramdisksudo chmod 777 /media/ramdisksudo mount -t tmpfs -o size=128M none /media/ramdisk && mkdir /media/ramdisk/mario-ai-screenshotsconfig.luaでSCREENSHOT_FILEPATH変更する必要があります。git clone https://github.com/aleju/mario-ai.gitを介してこのリポジトリをクローンします。cd 。lsnesを使用して、LSNES(リポジトリディレクトリから)を開始します。Configure -> Settings -> Advancedに移動し、LUAメモリ制限を1024MBに設定します。 (一度だけ行う必要があります。)Configure -> Settings -> Controller )。 Overworldがポップアップするまでプレイします。そこで、右に移動して、そのレベルを開始します。そのレベルを少し再生し、エミュレータのFile -> Save -> Stateサブディレクトリstates/trainに州を介して、ほんの一握りの状態を保存します。名前は問題ではありませんが、 .lsmvで終了する必要があります。 (州をレベル全体に広めるようにしてください。)th -ldisplay.startを使用してディスプレイサーバーを起動します。それがうまくいかない場合は、ディスプレイをまだインストールしていない場合は、 luarocks install displayを使用してください。http://localhost:8000/を開くことにより、ディスプレイサーバーの出力を開きます。Tools -> Run Lua script... 、 train.luaを選択します。Tools -> Reset Lua VM 。learned/でファイルを削除する必要があります。リプレイメモリ( memory.sqlite )を保持し、新しいネットワークを訓練できることに注意してください。 test.lua使用してモデルをテストできます。驚くほどうまくプレイすることを期待しないでください。エージェントは、パラメーターの悪いセットに関するトレーニングを終了した場合、さらに多くのことを死にます。


