シャドウハンドコントローラー
ディープラーニングとディープ強化学習を使用して、ムホコ環境でシャドウハンドモデルのコントローラーを構築しました。コントローラーを使用すると、ハンドがサイン言語ジェスチャーを実行できます。この手のサポートされているジェスチャーは次のとおりです。
- 休む
- 落とす
- 中指
- はい
- いいえ
- ロック
- 丸
シャドウハンドデモ:https://youtu.be/vt_booel3fu
シャドウハンドの説明

Shadowhandは、 Mujoco_menagerieリポジトリが学術および研究のために提供する3Dロボットハンドです。 https://github.com/deepmind/mujoco_menagerie/tree/main/shadow_handにあります
それがどのように機能するか
Shadowhandは、20の位置モーターをアクチュエーターとして使用して、指と手首の動きを可能にします。アクチュエーターは、メーカーによって定義された制御範囲が限られています。各アクチュエータの位置は、Mujocoシミュレーターをダウンロードし、 Drag&Dropを介してShadowhand XMLファイル( OBJECS/Shadow_Hand/Scene_Left.xml )をシミュレータにインポートすることで見つけることができます。各アクチュエーターの位置と方向を表示するには、レンダリング/モデルエレメントパネルにあるシミュレーションウィンドウ内でジョイントオプションを有効にする必要があります。あふれて、それらはXMLファイル内で分析的に説明されています。
手の各アクチュエーターの位置と制御範囲を以下に示します。
| id | ctrl_limit_left | ctrl_limit_right |
|---|
| 0 | -0.523599 | 0.174533 |
| 1 | -0.698132 | 0.488692 |
| 2 | -1.0472 | 1.0472 |
| 3 | 0 | 1.22173 |
| 4 | -0.20944 | 0.20944 |
| 5 | -0.698132 | 0.698132 |
| 6 | -0.261799 | 1.5708 |
| 7 | -0.349066 | 0.349066 |
| 8 | -0.261799 | 1.5708 |
| 9 | 0 | 3.1415 |
| 10 | -0.349066 | 0.349066 |
| 11 | -0.261799 | 1.5708 |
| 12 | 0 | 3.1415 |
| 13 | -0.349066 | 0.349066 |
| 14 | -0.261799 | 1.5708 |
| 15 | 0 | 3.1415 |
| 16 | 0 | 0.785398 |
| 17 | -0.349066 | 0.349066 |
| 18 | -0.261799 | 1.5708 |
| 19 | 0 | 3.1415 |

行動クローニング
Behavioral Cloning(BC)は、人間の専門家を観察および模倣することにより、タスクを実行するためのコントローラーを教える方法です。ロボット工学の特に一般的な手法であり、モデルは人間を模倣することでタスクを実行することを学びます。この方法には以下が含まれます。
- データ収集:人間の専門家は、ペアで構成されるデータセットを構築する必要があります:(観察、アクション) 。
- 学習アルゴリズム:次に、観測アルゴリズム(ニューラルネットワークなど)が設計され、観測値(入力)を予想アクション(出力)にマッピングします。
- 展開:コントローラーは、物理モデルに評価および展開されます。
深い強化学習
Deep Renection Learning(DRL)は、ティーチングマシンが最適な方法でタスクを実行するためのもう1つの一般的な手法ですが、行動のクローニングとは異なります。行動のクローニングは、望ましい行動の例(デモンストレーション)から直接学習しますが、DRLは環境との相互作用と報酬または罰則の形でフィードバックを受け取ることを通じて学習します。 DRL環境では、エージェントがその状態を受け取ります $ s_ {t} $環境から、アクションを選択します $ a_ {t} $そのポリシーを使用します $ pi _ { theta} $ 、その後、次の状態に移動します $ s_ {t+1} $そして最後に報酬を受け取ります $ r_ {t+1} $アクションがどれほど良かったかに基づいています。エージェントの目標は、累積リターンを最大化することです$ r = r_ {t + 1} + r_ {t + 2} + r_ {t + 3} + ... $。
DRLの問題で使用されるアルゴリズムの2つのファミリーがあります。
- 値ベースの方法:これらの方法は、特定の状態(または状態アクションペア)からエージェントが得ることができる予想される累積報酬の尺度である値関数を見つけることを目的としています。最も一般的な値関数はQ機能Q(S、A)です。 $ a_ {t} $状態 $ s_ {t} $ 。期待収益を測定する別の方法は、 $ v(s)$ 、状態がどれほど良いかを測定します $ s_ {t} $ 。エージェントのトレーニングプロセスと学習パフォーマンスを高速化するために、これら2つの機能が組み合わされる場合があります。値関数を正しく推定することにより、エージェントは連続した状態間で最適な遷移を行い、したがって最適な動作を学習できます。以下に示すように、Neural Networkを使用してQ機能関数と値関数の両方を推定できます。
- ポリシー勾配の方法:推定されたリターンを計算する代わりに、ポリシー勾配の方法は、仲介者としての値関数を必要とせずにポリシー機能を直接最適化します。通常、ポリシーは一連の重み(ニューラルネットワークなど)によってパラメーター化され、学習にはこれらの重みを調整して、予想される報酬を最大化することが含まれます。アイデアは、ニューラルネットワークの重みを変更し、選択したアクションを変更することにより、エージェントが環境で受信する報酬も変更するということです。エージェントの目標は、以下に示すように、報酬を最大化するディレクティンのポリシー(その重み)を変更することです。価値ベースの方法よりもポリシー勾配の方法の主な利点の1つは、個別のアクション(例えば1,2,3)ではなく、連続アクション(フロート値など)を使用できることです。これは、各アクチュエータの制御(フロート値)を予測することが目標である私たちのようなムホコ環境で特に役立ちます。
観察(入力)
行動のクローニングとDRLの両方の手法は、データを取得するためにデータセットまたはシミュレーション環境を必要とします。両方のエージェントをトレーニングするために、ペアで構成されるデータセットを構築しました $(符号、注文) - > (コントロール)$ 。
- 記号:記号は一連のシーケンシャルコントロールであり、サインジェスチャーを実行するために、ハンドコントローラーが実行する必要があります。たとえば、「はい」のジェスチャーを実行するには、最初に拳を作成し、次に手を下に移動してから、再び(3)を移動する必要があります。
- 順序:順序は、シーケンス内の目的のコントロールのインデックスです。これは、指定された順序ですべてのコントロールを順番に実行する必要があるため、これは必要です。たとえば、「はい」の例では、コントロール(1)、(2)、(3)は連続して実行する必要があります。
- コントロール:コントロールは20値のベクトル(配列)で、各アクチュエーターに1つです。各値は、アクチュエータの位置を制御するフロート番号であり、上記の表に記載されている制御制限を超えません。
署名/注文表現
ニューラルネットワークは入力ベクトルを受信し、制御ベクトルを出力します。入力ベクトルはフロート値のベクトルになると予想されますが、データセットには、文字列(単語)と整数の順序であるサインが含まれています。データセットは非常に小さいため、以下に示すように、各単語と順序を一意のベクトルに変換しました。
| サイン | ベクター |
|---|
| 休む | [0,0,0,0,0,0,1] |
| 落とす | [0,0,0,0,0,1,0] |
| 中指 | [0,0,0,0,1,0,0] |
| はい | [0,0,0,1,0,0,0] |
| いいえ | [0,0,1,0,0,0,0] |
| ロック | [0,1,0,0,0,0,0] |
| 丸 | [1,0,0,0,0,0,0] |
| 注文 | ベクター |
|---|
| 1 | [0,0,1] |
| 2 | [0,1,0] |
| 3 | [1,0,0] |
これで、これらの機能を連結して、ニューラルネットワーク/DRLエージェントコントローラーに挿入できます。
ニューラルネットワーク(BC)
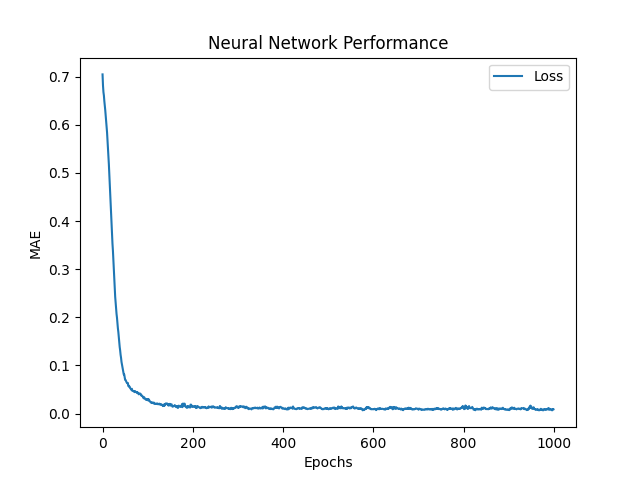
ニューラルネットワークの目標は、20のアクチュエーターの制御値を予測することです。 $ hat {y_ {0}}、 hat {y_ {1}}、 hat {y_ {2}}、 hat {y_ {3}}、...、 hat {y_ {19}} $ 、サインを使用して、ペアを入力として注文します。そのために、ネットワークは制御予測を出力し、その予測誤差を評価するために平均絶対誤差(MAE)関数を使用します。次に、ネットワークはAdam Optimizerを使用します。これは、重みを更新してMAEを削減するために、勾配降下アルゴリズムの改善です。もし $ y $そして $ hat {y} $それぞれターゲット(実際)と予測されたコントロールは、次のように定義されます。
$ frac {1} {n} * sum_ {i = 1}^{n} | y_i - hat {y_i} | $
近位政策最適化Peformance(DRL)
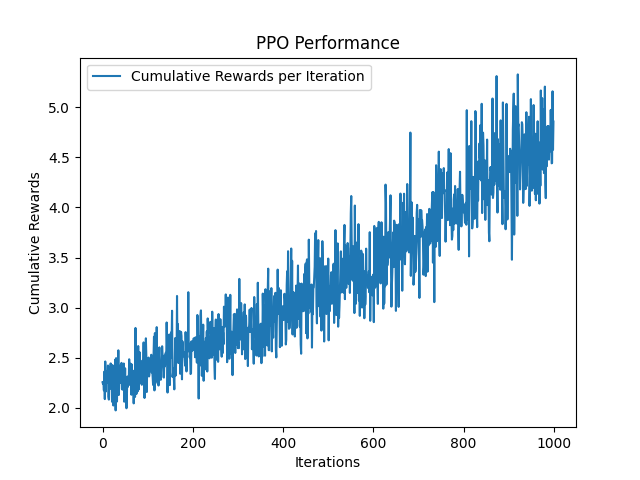
近位政策最適化(PPO)は、Trust Region Policy Optimization(TRPO)が直面するトレーニングの安定性と効率性におけるいくつかの課題に対処する一般的なポリシーグラデーションアルゴイトムです。 PPOは、ポリシーが単一のステップであまりにも劇的に更新されないようにするためのクリッピングメカニズムを導入し(重量が大規模な更新を受信し、劇的に変更するのを防ぎます)、新しいポリシーが古いポリシーからあまり逸脱しないようにします。 PPOは、予想される報酬を直接最大化する代わりに、ポリシーを育てるとき、目的関数のクリップバージョンを最大化することを目指しています。この切り取られた目的は、新しいポリシーと古いポリシーの確率の比率を制限します。具体的には、新しいポリシーが古いポリシーと比較してアクションの確率を大幅に増加させる場合、この変更は指定された範囲内にクリップされます(例:0.8〜1.2)。これにより、過度に積極的な更新が防止され、最適なポリシーに迅速に収束する可能性があります。この範囲は、クリッピングパラメーターによって定義されます $ e $ 、通常、間に設定されます $ [0.1、0.3] $ 。
BCニューラルネットワークと同様に、PPOは入力として(符号、順序)のペアを受け取り、手のターゲット制御を出力します。次に、損失(エラー)関数を使用してエラーを評価する代わりに、報酬関数を使用して報酬を受け取ります。報酬は、各反復で最大化しようとします。報酬関数 $ r $として定義されています $ r_ {t} = frac {1} {euclidean(y_ {t} - hat {y_ {t}})} $ 、ユークリッドは予測されたコントロールとターゲットコントロールの間のユークリッド距離です。
Pythonバージョンとライブラリ
- python == 3.9 https://www.python.org/downloads/release/python-390/
- Mujoco = 2.3.7 https://github.com/deepmind/mujoco
- Tensorflow == 2.9.1 https://www.tensorflow.org/install
- Ray [rllib] == 2.3.1 https://docs.ray.io/en/latest/rllib/index.html
- Gymnasium == 0.26.1 https://gymnasium.farama.org/
- matplotlib == 3.7.2 https://matplotlib.org/
実行方法
- python generate_expert_dataset.pyデータセットを作成します。手はキーボタン(1-7)を使用してジェスチャーを切り替えることができます。マウスはシミュレーションの世界をナビゲートするために使用できます
- python train_nn.pyニューラルネットワークを訓練および評価します
- PYTON TRAIN_PPO.PY PPOエージェントをトレーニングおよび評価します
- python simulate_neural_network_controller.pyニューラルネットワークベースのコントローラーを展開および評価します
- python simulate_neural_network_controller.pyは、 PPOベースのコントローラーを展開および評価します
パラメーターの説明
- trajectory_Steps :2つの連続したコントロール間で実行するための介入制御の数(例:
start_ctrl = [1,1,1], end_ctrl = [2,2,2] and trajectory_steps=5の場合、手は2 + 3コントロールを実行します[ 1,1,1]および[2,2,2]。 - CAM_Verbose :ターミナルのカメラの位置を印刷します(これにより、最初にカメラの位置と向きを調整するのに役立ちます)。
- Sim_verbose :各タイムステップで各アクチュエータのコントロールを印刷します。
- One_hot_signs :1ホットのサインと注文をするかどうか。 falseの場合、署名と命令はそれぞれ文字列と整数として返されます。ただし、ニューラルネットワークとDRLエージェントの両方を、文字列を入力として使用できるように変更する必要があります。それを行う1つの方法は、埋め込み層(https://www.tensorflow.org/text/guide/word_embeddings)を追加することです。これは、ジェスチャーの数と標識のシーケンスサイズが非常に大きい場合に役立つ可能性があるため、1ホットのエンコーディング方法を使用できません。
- Learning_rate :ニューラルネットワークのリーアニング率。これにより、ネットワークの更新が削減され、ネットワークがゆっくりと局所的な最小値に収束するようにします。 0.001は良い典型的な価値です
- エポック:ネットワークをトレーニングするためのエポックの数(データセットがネットワークに供給される回数)。デフォルトは1000です。
- loss_fn :ニューラルネットワークの損失関数。デフォルトは「MAE」になります。
- Train_iterations :エージェントがトレーニングされます。デフォルトは1000です。
- 種子:乱数を生成するために使用されるランダムシード。これにより、実験を再現できます。デフォルトは0です。
カスタムコントローラー
Control Handのアクチュエータを順に順番にGLFWSimulatorクラスでカスタムモデルコントローラーを提供できます( SIMULATE_NEURAL_NETWORK_CONTROLLER.pyをチェックし、 simulate_neural_network_controller.pyの例)。次の行を変更できます
hand_controller = Controller(
model=agent,
ctrl_limits=ctrl_limits
)
エージェントがカスタムエージェントに置き換えるように。エージェント(またはモデル)は、コントローラー/controller.pyファイルにあるController classを継承し、次の方法を定義する必要があります。
-
def _set_sign(self, sign: str) :コントローラーの動作を指定されたサインに設定します def _get_next_control(self, sign: str, order: int) :指定された符号の次のコントロールを取得します(例:記号が10のシーケンシャルコントロールとして定義されている場合、 get_next_controlそのシーケンスの次の予測コントロールを返す必要があります(check model.pyファイル)。
シミュレーション環境
シミュレーション環境は、Mujocoが提供するGLFWライブラリを使用してwritenです。 Simulaton/pyopengl.pyファイルのwhileループを変更することで簡単に変更できます。
カスタムニューラルネットワーク
ニューラルネットワークは、TensorFlowライブラリを使用してモデル/TF/NN.PYで構築されています。カスタムニューラルネットワークはNeuralNetwork classのビルド方法を拡張することで構築できます。現在のアーキテクチャでは、各入力ベクトルに2層の128ユニット(符号ベクトルでは128、順序ベクトルでは128)と各層のRelu Activation関数を使用します。次に、2層が256ユニットのベクトルに連結され、その後、128個のニューロン、最終的に20個の出力単位の別の層が続きます。最後の20ユニットは、アクチュエータコントロールを設定するために使用されます。
カスタムエージェント
このリポジトリは、RLLIBのPPOエージェントを使用しています。ただし、いくつかのことを追加できます。
- 微調整(PPOのより良いパラメーターを検索)。現在、アルゴリスは、 John Schulman et。 alの元の論文https://arxiv.org/abs/1707.06347
- より強力な学習アルゴリズムを追加する:例:ソフトアクタークリティック、別名SACはムホコ環境で非常に強力なパフォーマンスを持っていることが知られています:https://arxiv.org/pdf/1801.01290.pdf
- トレーニングの繰り返しを増やす:このライブラリで提供される事前に訓練されたモデルでは、ニューラルネットワークとPPOエージェントの両方が1000の反復でトレーニングされました。ニューラルネットワークは小さなエラーに収束しましたが、PPOは収束するためにより多くのトレーニングの反復が必要です。これが、PPOのコントローラーが奇妙な動作をしているように見える理由です。
- カスタムニューラルネットワークをActor-Criticモデルとして追加します。これは非常に難しい作業ですが、その目的のためにリポジトリを作成しました:https://github.com/kochlisgit/deep-rl-frameworks


