awesome RLHF
1.0.0
これは、人間のフィードバック(RLHF)による補強学習のための研究論文のコレクションです。リポジトリは、RLHFのフロンティアを追跡するために継続的に更新されます。
フォローアンドスターへようこそ!
素晴らしいRLHF(人間のフィードバック付きRL)
2024
2023
2022
2021
2020年以前
詳細な説明
目次
RLHFの概要
論文
コードベース
データセット
ブログ
その他の言語サポート
貢献
ライセンス
RLHFのアイデアは、補強学習の方法を使用して、人間のフィードバックを使用して言語モデルを直接最適化することです。 RLHFにより、言語モデルは、テキストデータの一般的なコーパスでトレーニングされたモデルの整列を複雑な人間の価値のモデルに整列させ始めました。
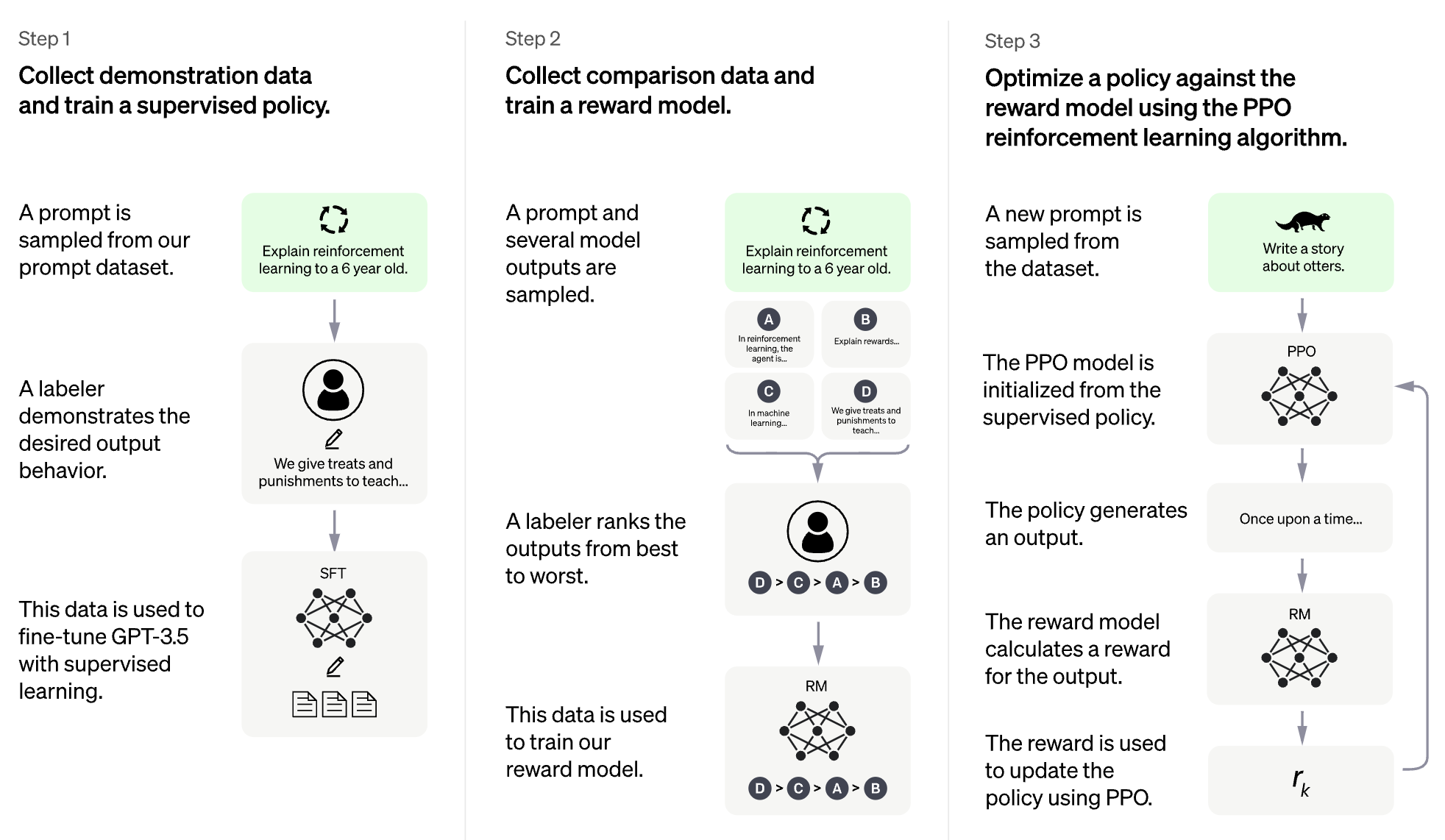
大規模な言語モデル(LLM)のRLHF
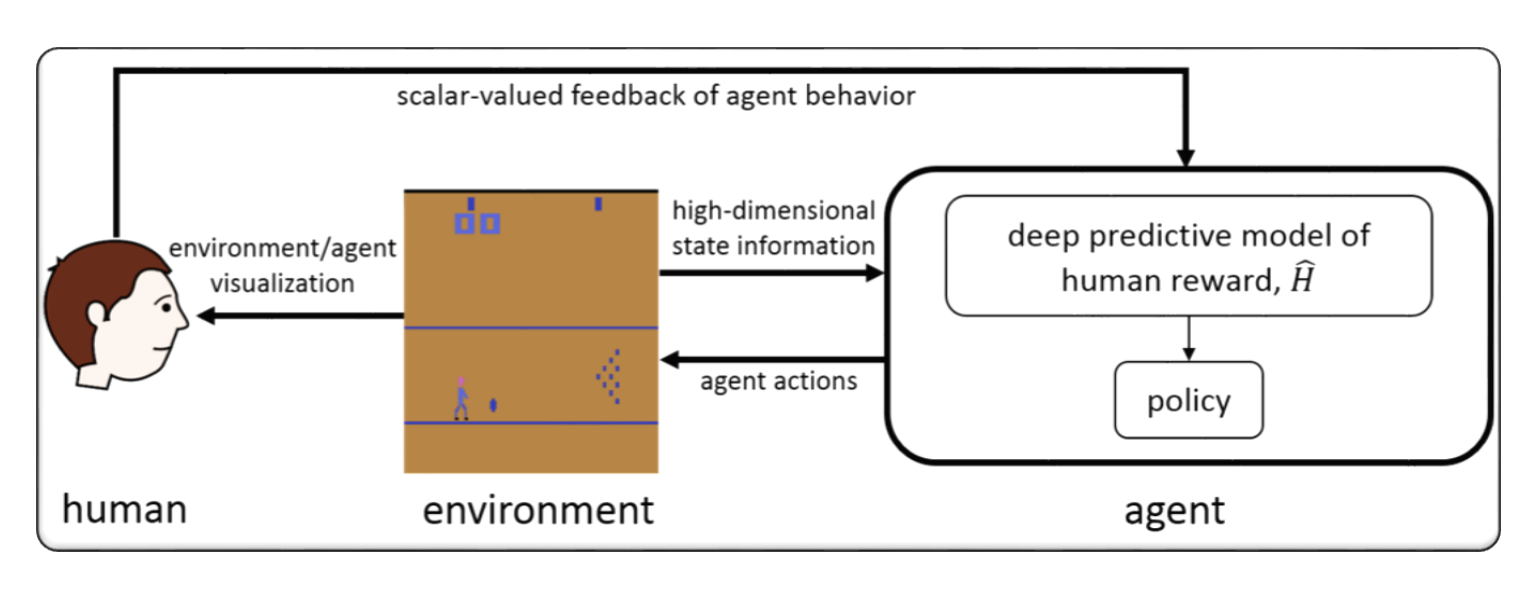
ビデオゲームのrlhf(例:atari)
(次のセクションは、chatgptによって自動的に生成されました)
RLHFは通常、「人間のフィードバックを使用した学習を強化」を指します。 Rehnection Learning(RL)は、環境からのフィードバックに基づいて意思決定を行うためにエージェントをトレーニングすることを伴う機械学習の一種です。 RLHFでは、エージェントは、その行動の評価または評価の形で人間からフィードバックを受け取ります。これは、より迅速かつ正確に学習するのに役立ちます。
RLHFは、人工知能の積極的な研究分野であり、ロボット工学、ゲーム、パーソナライズされた推奨システムなどの分野にアプリケーションがあります。エージェントが環境からのフィードバックへのアクセスを制限し、パフォーマンスを改善するために人間の入力を必要とするシナリオでRLの課題に対処しようとしています。
人間のフィードバック(RLHF)による強化学習は、人工知能の急速に発展している研究分野であり、RLHFシステムのパフォーマンスを改善するために開発されたいくつかの高度な技術があります。ここにいくつかの例があります:
Inverse Reinforcement Learning (IRL) :IRLは、事前に定義された報酬機能に依存するのではなく、エージェントが人間のフィードバックから報酬機能を学習できるようにする手法です。これにより、エージェントは、望ましい動作のデモンストレーションなど、より複雑なフィードバック信号から学習できます。
Apprenticeship Learning :見習い学習は、IRLと監視された学習を組み合わせて、エージェントが人間のフィードバックと専門家のデモの両方から学習できるようにするテクニックです。これは、肯定的および否定的なフィードバックの両方から学習できるため、エージェントがより迅速かつ効果的に学習するのに役立ちます。
Interactive Machine Learning (IML) :IMLは、エージェントと人間の専門家との積極的な相互作用を含む手法であり、専門家がエージェントの行動に関するフィードバックをリアルタイムで提供できるようにします。これは、学習プロセスの各ステップでアクションに関するフィードバックを受信できるため、エージェントがより迅速かつ効率的に学習するのに役立ちます。
Human-in-the-Loop Reinforcement Learning (HITLRL) :HITLRLは、報酬の形成、アクション選択、ポリシーの最適化など、複数のレベルで人間のフィードバックをRLプロセスに統合することを含む手法です。これは、人間と機械の両方の強度を活用することにより、RLHFシステムの効率と有効性を改善するのに役立ちます。
ここに、人間のフィードバック(RLHF)による補強学習の例がいくつかあります。
Game Playing :ゲームプレイでは、人間のフィードバックは、エージェントがさまざまなゲームシナリオで効果的な戦略と戦術を学ぶのに役立ちます。たとえば、人気のあるゲームでは、人間の専門家はその動きについてエージェントにフィードバックを提供し、ゲームプレイと意思決定を改善するのに役立ちます。
Personalized Recommendation Systems :推奨システムでは、人間のフィードバックは、エージェントが個々のユーザーの好みを学習し、パーソナライズされた推奨事項を提供できるようにすることができます。たとえば、エージェントは、推奨製品のユーザーからのフィードバックを使用して、どの機能が最も重要であるかを学習できます。
Robotics :ロボット工学では、人間のフィードバックは、エージェントが安全で効率的な方法で物理的環境と対話する方法を学ぶのに役立ちます。たとえば、ロボットは、採用するのに最適なパスまたは避けるべきオブジェクトについて、人間のオペレーターからのフィードバックを使用して、新しい環境をより迅速にナビゲートすることを学ぶことができます。
Education :教育では、人間のフィードバックは、エージェントが生徒により効果的に教える方法を学ぶのに役立ちます。たとえば、AIベースのチューターは、教師からのフィードバックを使用して、さまざまな学生と教育戦略が最適に機能し、学習体験をパーソナライズするのに役立ちます。
format: - [title](paper link) [links] - author1, author2, and author3... - publisher - keyword - code - experiment environments and datasets
ハイブリッドフロー:柔軟で効率的なRLHFフレームワーク
Guangming Sheng、Chi Zhang、Zilingfeng Ye、Xibin Wu、Wang Zhang、Ru Zhang、Yanghua Peng、Haibin Lin、Chuan Wu
キーワード:柔軟で効率的なRLHFフレームワーク
コード:公式
アラーム:階層的な報酬モデリングを介して言語モデルを調整します
Yuhang Lai、Siyuan Wang、Shujun Liu、Xuanjing Huang、Zhongyu Wei
キーワード:階層的な報酬、オープンテキスト生成タスク
コード:公式
TLCR:人間のフィードバックからのきめ細かな強化学習に対するトークンレベルの継続的な報酬
Eunseop Yoon、Hee Suk Yoon、Soohwan Eom、Gunsoo Han、Daniel Wontae Nam、Daejin Jo、Kyoung-Woon on、Mark A. Hasegawa-Johnson、Sungwoong Kim、Chang D. Yoo
キーワード:トークンレベルの連続報酬、RLHF
コード:公式
大規模なマルチモーダルモデルを事実上拡張RLHFと整列させます
Zhiqing Sun、Sheng Shen、Shengcao Cao、Haotian Liu、Chunyuan Li、Yikang Shen、Chuang Gan、Liang-Yan Gui、Yu-Xiong Wang、Yiming Yang、Kurt Keutzer、Trevor Darrell
キーワード:事実上拡張RLHF、ビジョンと言語、人間の好みデータセット
コード:公式
自己報酬のコントラスト迅速な蒸留による直接的な言語モデルのアライメント
Aiwei Liu、Haoping Bai、Zhiyun Lu、Xiang Kong、Simon Wang、Jiulong Shan、Meng Cao、Lijie Wen
キーワード:人間の好みデータなし、自己報酬、DPO
コード:公式
多様なユーザー設定のためのLLMSの算術制御:多目的報酬との方向方向の整合
Haoxiang Wang、Yong Lin、Wei Xiong、Rui Yang、Shizhe Diao、Shuang Qiu、Han Zhao、Tong Zhang
キーワード:ユーザーの好み、多目的報酬モデル、拒否サンプリングフィニング
コード:公式
基本に戻る:LLMSでの人間のフィードバックから学ぶためのスタイルの最適化を強化する
Arash Ahmadian、Chris Cremer、MatthiasGallé、Marzieh Fadaee、Julia Kreutzer、Olivier Pietquin、Ahmetün、Sara Hooker
キーワード:オンラインRL最適化、低い計算コスト
コード:公式
編集制約を最小限に抑えて、細粒の補強学習を介して大規模な言語モデルを改善する
Zhipeng Chen、Kun Zhou、Wayne Xin Zhao、Junchen Wan、Fuzheng Zhang、Di Zhang、Ji-Rong Wen
キーワード:トークンレベルの報酬、LLM
コード:公式
RLAIF対RLHF:AIフィードバックを使用した人間のフィードバックからの補強補強学習
ハリソン・リー、サムラット・ファタール、ハッサン・マンソール、トーマス・メスナード、ヨハン・フェレット、ケリー・レン・ルー、コルトン・ビショップ、イーサン・ホール、ビクター・カーブン、アブヒナフ・ラストギ、寿司プラカシュ
キーワード:AIフィードバックからのRL
コード:公式
バイレベル補強学習およびRLHFの原則的なペナルティベースの方法
ハン・シェン、Zhuoran Yang、Tianyi Chen
キーワード:バイレベルの最適化
コード:公式
人間のフィードバックからの補強学習で無料で密集した報酬
アレックス・ジェームズ・チャン、ハオ・サン、サミュエル・ホルト、ミヘラ・ファン・デル・シャール
キーワード:報酬形状、RLHF
コード:公式
人間のフィードバックから学習を強化するためのミニマリストアプローチ
Gokul Swamy、Christoph Dann、Rahul Kidambi、Steven Wu、Alekh Agarwal
キーワード:Minimaxの勝者、自己プレイの好みの最適化
コード:公式
RLHF-V:細粒補正のヒトフィードバックからの動作アライメントを介した信頼できるMLLMSに向けて
Tianyu Yu、Yuan Yao、Haoye Zhang、Taiwen He、Yifeng Han、Ganque Cui、Jinyi Hu、Zhiyuan Liu、Hai-Tao Zheng、Maosong Sun、Tat-Seng Chuaa
キーワード:マルチモーダルの大手言語モデル、幻覚の問題、人間のフィードバックからの強化学習
コード:公式
RLHFワークフロー:報酬モデリングからオンラインRLHFまで
Hanze Dong、Wei Xiong、Bo Pang、Haoxiang Wang、Han Zhao、Yingbo Zhou、Nan Jiang、Doyen Sahoo、Caiming Xiong、Tong Zhang
キーワード:オンライン反復RLHF、優先モデリング、大規模な言語モデル
コード:公式
Maxmin-RLHF:多様な人間の好みを持つ大規模な言語モデルの公平なアライメントに向けて
Souradip Chakraborty、Jiahao Qiu、Hui Yuan、Alec Koppel、Furong Huang、Dinesh Manocha、Amrit Singh Bedi、Mengdi Wang
キーワード:優先分布の混合、Maxminアライメント目標
コード:公式
RLHFのデータセットリセットポリシーの最適化
ジョナサン・D・チャン、ウェンハオ・ザン、オーウェン・オルテル、キアンテ・ブラントリー、ディペンドラ・ミスラ、ジェイソン・D・リー、ウェン・サン
キーワード:データセットリセットポリシーの最適化
コード:公式
テキストからイメージへの拡散を好みに合わせて密な報酬ビュー
Shentao Yang、Tianqi Chen、Mingyuan Zhou
キーワード:テキストから画像の生成、DPOの密な報酬改善、効率的なアライメントのためのRLHF
コード:公式
セルフプレイの微調整は、弱い言語モデルを強力な言語モデルに変換する
Zixiang Chen、Yihe Deng、Huizhuo Yuan、Kaixuan Ji、Quanquan Gu
キーワード:セルフプレイの微調整
コード:公式
RLHF解読:LLMの人間のフィードバックからの強化学習の重要な分析
シュレイヤス・チャウドハリ、プランジャル・アガルワル、ヴィシュヴァク・ムラハリ、タンメイ・ラジプロヒット、アシュウィン・カリャン、カルティク・ナラシンハン、アミート・デシュパンデ、ブルーノ・カストロ・ダ・シルバ
キーワード:RLHF、口腔報酬、報酬モデル分析、調査
拡散モデルに対する最適化過剰化に直面する:誘導性と優位の偏りの視点
Ziyi Zhang、Sen Zhang、Yibing Zhan、Yong Luo、Yonggang Wen、Dacheng Tao
キーワード:拡散モデル、アライメント、強化学習、RLHF、報酬過剰最適化、プライマシーバイアス
コード:公式
大規模な言語モデルアライメントの多様な好みについて
Dun Zeng、Yong Dai、Pengyu Cheng、Tianhao Hu、Wanshun Chen、Nan Du、Zenglin Xu
キーワード:共有設定の調整、報酬モデリングメトリック、LLM
コード:公式
分配設定報酬モデリングを介してクラウドフィードバックを調整します
Dexun Li、Cong Zhang、Kuicai Dong、Derrick Goh Xin Deik、Ruiming Tang、Yong Liu
キーワード:RLHF、優先分布、Aling、LLM
1つのプレーファレンスフィットフィットアライメントを超えて:多目的直接選好最適化
Zhanhui Zhou、Jie Liu、Chao Yang、Jing Shao、Yu Liu、Xiangyu Yue、Wanli Ouyang、Yu Qiao
キーワード:報酬モデリングのない多目的RLHF、DPO
コード:公式
エミュレートされた分解:大規模な言語モデルの安全整合性が裏目に出る場合があります!
Zhanhui Zhou、Jie Liu、Zhichen Dong、Jiaheng Liu、Chao Yang、Wanli Oyang、Yu Qiao
キーワード:LLM推論時間攻撃、DPO、トレーニングなしで有害なLLMSを生成する
コード:公式
一般的なKL正規化された選好の下で人間のフィードバックから学習するナッシュの理論分析
Chenlu Ye、Wei Xiong、Yuheng Zhang、Nan Jiang、Tong Zhang
キーワード:ゲームベースのRLHF、NASH Learning、Reward-ModelフリーのOracleの下でのアラインメント
RLHFのアライメント税の緩和
ヨン・リン、ハングユ・リン、ウェイ・シオン、シズヘ・ディアオ、ジアンメン・リュー、ジペン・チャン、ルイ・パン、ハオキシアン・ワン、ウェンビン・フー、ハニング・チャン、ハンゼ・ドン、レンジー・パイ、ハン・チャオ、ナン・ジアン、ヘン・ジ
キーワード:RLHF、アライメント税、壊滅的な忘却
強化学習を備えた拡散モデルのトレーニング
ケビン・ブラック、マイケル・ジャナー、イルン・デュ、イリヤ・コストリコフ、セルゲイ・レヴァイン
キーワード:強化学習、RLHF、拡散モデル
コード:公式
Aligndiff:行動顧客拡散モデルを介して、多様な人間の好みを調整します
Zibin Dong、Yifu Yuan、Jianye Hao、Fei Ni、Yao MU、Yan Zheng、Yujing Hu、Tangjie LV、Changjie Fan、Zhipeng Hu
キーワード:強化学習。拡散モデル; rlhf;優先順位
コード:公式
人間のフィードバックからの補強学習で無料で密集した報酬
アレックス・J・チャン、ハオ・サン、サミュエル・ホルト、ミヘラ・ファン・デル・シャール
キーワード:RLHF
コード:公式
大規模な言語モデルを調整するための報酬の変換と組み合わせ
Zihao Wang、Chirag Nagpal、Jonathan Berant、Jacob Eisenstein、Alex D'Amour、Sanmi Koyejo、Victor Veitch
キーワード:rlhf、aling、llm
パラメーター効率的な強化人間のフィードバックからの学習
ハキム・シダード、サムラト・ファタール、アレックス・ハッチソン、Zhuonan Lin、Zhang Chen、Zac Yu、Jarvis Jin、Simral Chaudhary、Roman Komarytsia、Christiane Ahlheim、Yonghao Zhu、Bowen Li、Saravanan ganes 、Abhinav Rastogi、Lucas Dixon
キーワード:RLHF、パラメーター効率的な方法、低い計算コスト、LLM、VLM
効率的な報酬モデルアンサンブルで人間のフィードバックからの強化学習の改善
Shun Zhang、Zhenfang Chen、Sunli Chen、Yikang Shen、Zhiqing Sun、Chuang Gan
キーワード:RLHF、報酬アンサンブル、効率的なアンサンブルメソッド
人間の好みから学習を理解するための一般的な理論的パラダイム
Mohammad Gheshlaghi Azar、Mark Rowland、Bilal Piot、Daniel Guo、Daniele Calandriello、Michal Valko、RémiMunos
キーワード:RLHF、ペアワイズ設定
細い人間のフィードバックは、言語モデルのトレーニングに対してより良い報酬を与えます
Zeqiu Wu、Yushi Hu、Weijia Shi、Nouha Dziri、Alane Suhr、Prithviraj Ammanabrolu、Noah A. Smith、Mari Ostendorf、Hannaneh Hajishirzi
キーワード:RLHF、文レベルの報酬、LLM
コード:公式
言語モデルの微調整のための優先順位のトークンレベルのガイダンス
Shentao Yang、Shujian Zhang、Congying Xia、Yihao Feng、Caiming Xiong、Mingyuan Zhou
キーワード:RLHF、トークンレベルのトレーニングガイダンス、代替/オンライントレーニングフレームワーク、ミニマリストトレーニング目標
コード:公式
素晴らしい報酬とそれらを飼いならす方法:タスク指向の対話システムの報酬学習に関するケーススタディ
Yihao Feng*、Shentao Yang*、Shujian Zhang、Jianguo Zhang、Caiming Xiong、Mingyuan Zhou、Huan Wang
キーワード:RLHF、ジェネラル化された報酬機能学習、報酬機能の利用、タスク指向のダイアログシステム、ランク学習
コード:公式
逆選好学習:報酬機能のない好みベースのRL
ジョーイ・ヘイナ、ドーサ・サディッグ
キーワード:報酬モデルなしの逆選好学習
コード:公式
Alpacafarm:人間のフィードバックから学習する方法のシミュレーションフレームワーク
Yann Dubois、Chen Xuechen Li、Rohan Taori、Tianyi Zhang、Ishaan Gulrajani、Jimmy BA、Carlos Guestrin、Percy S. Liang、Tatsunori B. Hashimoto
キーワード:RLHF、シミュレーションフレームワーク
コード:公式
人間のアライメントの優先ランキング最適化
Feifan Song、Bowen Yu、Minghao Li、Haiyang Yu、Fei Huang、Yongbin Li、Houfeng Wang
キーワード:優先ランキング最適化
コード:公式
敵対的な好みの最適化
Pengyu Cheng、Yifan Yang、Jian Li、Yong Dai、Nan du
キーワード:RLHF、ガン、敵対ゲーム
コード:公式
人間のフィードバックから学習する反復的好み:KL-Constraintの下でのRLHFの理論と実践をブリッジ化
Wei Xiong、Hanze Dong、Chenlu Ye、Ziqi Wang、Han Zhong、Heng Ji、Nan Jiang、Tong Zhang
キーワード:RLHF、反復DPO、数学的基礎
積極的な探査による人間のフィードバックからの効率的な強化学習
Viraj Mehta、Vikramjeet Das、Ojash Neopane、Yijia Dai、Ilija Bogunovic、Jeff Schneider、Willie Neiswanger
キーワード:RLHF、サンプル効率、探索
統計フィードバックからの強化学習:ABテストからアリテストへの旅
Feiyang Han、Yimin Wei、Zhaofeng Liu、Yanxing Qi
キーワード:RLHF、ABテスト、RLSF
分布シフトで基礎モデルを正確に分析する報酬モデルの能力のベースライン分析
ベン・ピクス、ウィル・レヴァイン、トニー・チェン、ショーン・ヘンドリックス
キーワード:RLHF、OOD、分布シフト
自然言語による人間のフィードバックとの大規模な言語モデルのデータ効率の高いアラインメント
ディ・ジン、シキブ・メリ、デヴァマニュー・ハザリカ、アイシュワリヤ・パドマクマル、スンジン・リー、ヤン・リュー、マフディ・ナマジファー
キーワード:RLHF、データ効率、アライメント
段階的に強化しましょう
サラ・パン、ヴラディスラヴ・リアリン、シェリン・ムッカティラ、アンナ・ラムシスキー
キーワード:RLHF、推論
報酬モデリングなしの直接的な優先ベースのポリシーの最適化
Gaon An、Junhyeok Lee、Xingdong Zuo、Nario Kosaka、Kyung-Min Kim、Hyun Oh Song
キーワード:報酬モデリング、コントラスト学習、オフラインの精製学習のないRLHF
Aligndiff:行動顧客拡散モデルを介して、多様な人間の好みを調整します
Zibin Dong、Yifu Yuan、Jianye Hao、Fei Ni、Yao MU、Yan Zheng、Yujing Hu、Tangjie LV、Changjie Fan、Zhipeng Hu
キーワード:RLHF、アライメント、拡散モデル
Eureka:大規模な言語モデルをコーディングすることによる人間レベルの報酬設計
Yecheng Jason MA、William Liang、Guanzhi Wang、De-An Huang、Osbert Bastani、Dinesh Jayaraman、Yuke Zhu、Linxi Fan、Anima Anandkumar
キーワード:LLMベースの報酬機能デザイン
SAFE RLHF:人間のフィードバックからの安全な補強学習
Josef Dai、Xuehai Pan、Ruiyang Sun、Jiaming Ji、Xinbo Xu、Mickel Liu、Yizhou Wang、Yaodong Yang
キーワード:販売RL、LLMファインチュア
人間のフィードバックによる品質の多様性
Li Ding、Jenny Zhang、Jeff Clune、Lee Spector、Joel Lehman
キーワード:品質の多様性、拡散モデル
Remax:大規模な言語モデルを調整するためのシンプルで効果的で効率的な強化学習方法
Ziniu Li、Tian Xu、Yushun Zhang、Yang Yu、Ruoyu Sun、Zhi-Quan Luo
キーワード:計算効率、分散削減手法
タスクの報酬を使用してコンピュータービジョンモデルを調整します
アンドレ・スサノ・ピント、アレクサンダー・コレスニコフ、Yuge Shi、Lucas Beyer、Xiaohua Zhai
キーワード:コンピュータービジョンの報酬調整
後知恵の知恵は、言語モデルをより良い指導フォロワーにします
Tianjun Zhang、Fangchen Liu、Justin Wong、Pieter Abbeel、Joseph E. Gonzalez
キーワード:後知恵の命令のリレーブリング、RLHFシステム、値ネットワークは必要ありません
コード:公式
言語は、人間と調整のための強化学習を指示しました
Hengyuan Hu、Dorsa Sadigh
キーワード:人間と調整、人間の好みの調整、命令条件付きRL
人間のフィードバックからのオフライン強化学習を備えた言語モデルを調整する
Jian Hu、Li Tao、June Yang、Chandler Zhou
キーワード:意思決定トランスベースのアライメント、オフライン強化学習、RLHFシステム
人間のアライメントの優先ランキング最適化
Feifan Song、Bowen Yu、Minghao Li、Haiyang Yu、Fei Huang、Yongbin Li、Houfeng Wang
キーワード:監視された人間の好みのアライメント、好みのランキング拡張機能
コード:公式
ギャップの橋渡し:自然言語生成のための(人間)フィードバックの統合に関する調査
パトリック・フェルナンデス、アマン・マダン、エミー・リュー、アントニオ・ファリーニャス、ペドロ・ヘンリケ・マーティンズ、アマンダ・バーツチ、ホセ・GC・デ・スーザ、シュヤン・Zhou、トングシュアン・ウー、グラハム・ノイビグ、アンドレ・フィート・マルティンズ
キーワード:自然言語生成、人間のフィードバック統合、フィードバックの形式化と分類、AIフィードバック、原則に基づく判断
GPT-4テクニカルレポート
Openai
キーワード:大規模でマルチモーダルモデル、変圧器ベースモデル、微調整された使用済みRLHF
コード:公式
データセット:Drop、Winogrande、Hellaswag、Arc、Humanval、GSM8K、MMLU、Truthfulqa
RAFT:生成基盤モデルのアライメントに対して、微調整された報酬
Hanze Dong、Wei Xiong、Deepanshu Goyal、Rui Pan、Shizhe Diao、Jipeng Zhang、Kashun Shum、Tong Zhang
キーワード:PPO、拡散モデルに代わる射影の微調整
コード:公式
RRHF:涙のない人間のフィードバックと言語モデルを調整するためのランク応答
Zheng Yuan、Hongyi Yuan、Chuanqi Tan、Wei Wang、Songfang Huang、Fei Huang
キーワード:RLHFの新しいパラダイム
コード:公式
ループの人間のRLの少数のショット選好学習
ジョーイ・ヘイナ、ドーサ・サディッグ
キーワード:優先学習、インタラクティブ学習、マルチタスク学習、ループ内の人間を表示することで利用可能なデータのプールを拡大する
コード:公式
人間の好みを持つテキストからイメージモデルをより適切に調整します
Xiaoshi Wu、Keqiang Sun、Feng Zhu、Rui Zhao、Hongsheng Li
キーワード:拡散モデル、テキストからイメージ、美学
コード:公式
Imagereward:テキストから画像の生成に対する人間の好みを学び、評価します
Jiazheng Xu、Xiao Liu、Yuchen Wu、Yuxuan Tong、Qinkai Li、Ming Ding、Jie Tang、Yuxiao Dong
キーワード:汎用テキストからイメージまでの人間の好みRM、テキストから画像への生成モデルの評価
コード:公式
データセット:coco、diffusiondb
人間のフィードバックを使用してテキストから画像へのモデルを調整します
キミン・リー、ハオ・リュウ、ムーンキョン・リュウ、オリビア・ワトキンス、ユキング・デュ、クレイグ・ブーティリエ、ピーター・アベル、モハマド・ガヴァムザデ、シクシアン・シェーン・グ
キーワード:テキストからイメージ、安定した拡散モデル、人間のフィードバックを予測する報酬機能
VisualChatGpt:Visual Foundationモデルとの会話、描画、編集
Chenfei Wu、Shengming Yin、Weizhen Qi、Xiaodong Wang、Zecheng Tang、Nan Duan
キーワード:Visual Foundationモデル、Visual ChatGpt
コード:公式
人間の好みを備えた事前削除言語モデル(PHF)
Tomasz Korbak、Kejian Shi、Angelica Chen、Rasika Bhalerao、Christopher L. Buckley、Jason Phang、Samuel R. Bowman、Ethan Perez
キーワード:事前トレーニング、オフラインRL、意思決定トランス
コード:公式
F-Divergence最小化(F-DPG)を通じて好みを持つ言語モデルを調整する
Dongyoung Go、Tomasz Korbak、GermánKruszewski、Jos Rozen、Nahyeon Ryu、Marc Dymetman
キーワード:f-divergence、rl with klペナルティ
ペアワイズまたはK-ワイズの比較からの人間のフィードバックによる原則的な強化学習
Banghua Zhu、Jiantao Jiao、Michael I. Jordan
キーワード:悲観的なMLE、Max-Entropy IRL
大規模な言語モデルにおける道徳的自己修正の能力
人類
キーワード:RLHFトレーニングを増やすことにより、道徳的な自己修正機能を改善します
データセット;バーベキュー
自然言語処理のための補強学習(存在しません):自然言語政策最適化のためのベンチマーク、ベースライン、およびビルディングブロック(NLPO)
Rajkumar Ramamurthy、Prithviraj Ammanabrolu、Kianté、Brantley、Jack Hessel、Rafet Sifa、Christian Bauckhage、Hannaneh Hajishirzi、Yejin Choi
キーワード:RL、ベンチマーク、パフォーマンスRLアルゴリズムを使用した言語ジェネレーターの最適化
コード:公式
データセット:IMDB、Commongen、CNN Daily Mail、Totto、WMT-16(EN-DE)、NaryativeQa、DailyDialog
報酬モデルの過剰最適化のためのスケーリング法
レオガオ、ジョン・シュルマン、ジェイコブ・ヒルトン
キーワード:ゴールド報酬モデルトレインプロキシ報酬モデル、データセットサイズ、ポリシーパラメーターサイズ、ボン、PPO
ターゲットを絞った人間の判断を介した対話エージェントの調整の改善(スパロウ)
Amelia Glaese、Nat McAleese、MajaTręBacz、他
キーワード:情報を求めるダイアログエージェント、良い対話を自然言語ルール、DPCに分解し、特定のルールの違反を引き出すためにモデルと対話します(敵対的な調査)
データセット:自然な質問、ELI5、品質、Triviaqa、Winobias、BBQ
害を減らすための赤いチームの言語モデル:方法、スケーリング行動、学んだ教訓
ディープ・ガンガリ、リアン・ロヴィット、ジャクソン・カーニオン、他
キーワード:レッドチーム言語モデル、スケーリングの動作を調査し、チーム化データセットを読む
コード:公式
強化学習を使用した自由回答形式の対話における動的計画
デボラ・コーエン、ムーンキョン・リュウ、インラム・チョウ、オルガド・ケラー、アイド・グリーンバーグ、アビナタン・ハシディム、マイケル・フィンク、ヨッシ・マティアス、イダン・シュペットール、クレイグ・ボウティリア、ギャル・エリダン
キーワード:リアルタイム、オープンエンドのダイアログシステムは、言語モデル、CAQL、CQL、BERTによる会話状態の簡潔な埋め込みとペア
Quark:補強された補強されたテキスト生成を補強していない
Ximing Lu、Sean Welleck、Jack Hessel、Liwei Jiang、Lianhui Qin、Peter West、Prithviraj Ammanabrolu、Yejin Choi
キーワード:PPOを使用したDecision Transformer、LLMチューニングのシグナルで言語モデルを微調整する
コード:公式
データセット:writingprompts、SST-2、wikitext-103
人間のフィードバックからの補強学習で役立つ無害なアシスタントをトレーニングする
Yuntao Bai、Andy Jones、Kamal Ndusse、et al。
キーワード:無害なアシスタント、オンラインモード、RLHFトレーニングの堅牢性、OOD検出。
コード:公式
データセット:Triviaqa、Hellaswag、Arc、Openbookqa、Lambada、Humanval、MMLU、Truthfulqa
確認された引用符で回答をサポートするための言語モデル(Gophercite)
ジェイコブ・メニック、マジャ・トレバチ、ウラジミール・ミクリク、ジョン・アスラニデス、フランシス・ソング、マーティン・チャドウィック、ミア・グレーゼ、スザンナ・ヤング、ルーシー・キャンベル・ギリンガム、ジェフリー・アーヴィング、ナット・マカリーズ
キーワード:特定の証拠を引用する回答を生成し、不確かなときに答えることを控えます
データセット:自然な質問、ELI5、品質、Truthfulqa
人間のフィードバックを使用して指示に従うための言語モデルをトレーニングする(instructgpt)
Long Ouyang、Jeff Wu、Xu Jiang、他
キーワード:大規模な言語モデル、言語モデルを人間の意図と整列させる
コード:公式
データセット:Truthfulqa、RealToxicityPrompts
憲法AI:AIフィードバックからの無害
Yuntao Bai、Saurav Kadavath、Sandipan Kundu、Amanda Adkell、Jackson Kernionなど
キーワード:AIフィードバック(RLAIF)からのRL、自己改善、考え方のスタイルを通じて無害なAIアシスタントをトレーニングし、より正確に制御するAIの動作
コード:公式
モデル作成された評価で言語モデルの動作を発見します
イーサン・ペレス、サム・リンガー、カミル・ルコシュトė、カリーナ・ヌグエン、エドウィン・チェン、他
キーワード:LMSで評価を自動的に生成し、RLHFを増やすとLMSがさらに悪化します。LM書かれた評価は高品質です
コード:公式
データセット:BBQ、Winogender Schemas
解釈可能な複数のインスタンス学習を介した軌跡ラベルからの非マルコビアン報酬モデリング
ジョセフ・アーリー、トム・ビューリー、クリスティン・エバーズ、サルバパリ・ラムチャル
キーワード:報酬モデリング(RLHF)、非マルコビア語、複数のインスタンス学習、解釈可能性
コード:公式
WebGPT:人間のフィードバックを使用してブラウザアシストの質問を応答する(WebGPT)
reiichiro nakano、ジェイコブ・ヒルトン、シアル・バラジ、他
キーワード:モデルWebを検索して参照、模倣学習、BC、長いフォームの質問を提供します
データセット:ELI5、Triviaqa、Truthfulqa
人間のフィードバックで本を再帰的に要約します
ジェフ・ウー、ロング・ウーヤン、ダニエル・M・ジーグラー、ニサン・スティエノン、ライアン・ロウ、ヤン・レイキ、ポール・クリスチャン
キーワード:人間がより広範なタスクを評価するために小さなタスクでトレーニングされたモデル、BC
データセット:booksum、nativativeqa
神経機械の翻訳のための補強学習の弱点を再検討する
サミュエル・キーゲランド、ジュリア・クロイザー
キーワード:ポリシーグラデーションの成功は、出力分布の形状、機械翻訳、NMT、ドメイン適応の形状ではなく報酬によるものです
コード:公式
データセット:WMT15、IWSLT14
人間のフィードバックから要約することを学ぶ
Nisan Stiennon、Long Ouyang、Jeff Wu、Daniel M. Ziegler、Ryan Lowe、Chelsea Voss、Alec Radford、Dario Amodei、Paul Christiono
キーワード:概要の品質、トレーニングの損失はモデルの動作に影響し、報酬モデルが新しいデータセットに一般化することに注意してください
コード:公式
データセット:TL; DR、CNN/DM
人間の好みからの微調整言語モデル
ダニエル・M・ジーグラー、ニサン・スティエノン、ジェフリー・ウー、トム・B・ブラウン、アレック・ラドフォード、ダリオ・アモデイ、ポール・クリスチャン、ジェフリー・アーヴィング
キーワード:言語の報酬学習、肯定的な感情を伴う継続テキスト、要約タスク、物理的記述
コード:公式
データセット:TL; DR、CNN/DM
報酬モデリングを介したスケーラブルエージェントアライメント:研究の方向
Jan Leike、David Krueger、Tom Everitt、Miljan Martic、Vishal Maini、Shane Legg
キーワード:エージェントアライメントの問題、インタラクションから報酬を学ぶ、RLで報酬を最適化する、再帰報酬モデリング
コード:公式
env:アタリ
Atariでの人間の好みとデモンストレーションからの学習に報いる
Borja Ibarz、Jan Leike、Tobias Pohlen、Geoffrey Irving、Shane Legg、Dario Amodei
キーワード:専門家のデモンストレーション軌跡の好みは、ハッキングの問題、人間のラベルのノイズに報いる
コード:公式
env:アタリ
ディープテイマー:高次元状態空間でのインタラクティブなエージェント形成
ギャレット・ワーネル、ニコラス・ウェイトウィッチ、バーノン・ローハーン、ピーター・ストーン
キーワード:高次元状態、人間のトレーナーの入力を活用する
コード:サードパーティ
env:アタリ
人間の好みからの深い強化学習
ポール・クリスチャン、ヤン・レイキ、トム・B・ブラウン、ミルジャン・マーティック、シェーン・レッグ、ダリオ・アモデイ
キーワード:軌跡セグメンテーションのペア間の人間の好みで定義された目標を探る、人間のフィードバックよりも複雑なことを学ぶ
コード:公式
env:アタリ、ムホコ
政策依存の人間のフィードバックからのインタラクティブな学習
ジェームズ・マクグラシャン、マーク・K・ホー、ロバート・ロフティン、ベイ・ペン、グアン・ワン、デビッド・ロバーツ、マシュー・E・テイラー、マイケル・L・リットマン
キーワード:決定は、人間のフィードバックではなく現在のポリシーの影響を受けます。
format: - [title](codebase link) [links] - author1, author2, and author3... - keyword - experiment environments, datasets or tasks
Verl:LLMの火山エンジン補強学習
bytedance seed mlsys team&hku:guangming sheng、chi zhang、zilingfeng ye、xibin wu、wang zhang、ru zhang、yanghua peng、haibin lin、chuan wu
キーワード:柔軟で効率的なRLHFフレームワーク
タスク:RLHF、数学やコードを含む推論タスク。
openrlhf
openrlhf
キーワード:70b、rlhf、deepspeed、ray、vllm
タスク:使いやすく、スケーラブルで高性能RLHFフレームワーク(70B+フルチューニング&LORA&MIXTRAL&KTOをサポート)。
palm + rlhf -pytorch
フィル・ワン、ヤシン・ザヒディ、イッコ・エルトシア・アシミン、エリック・アルカイド
キーワード:トランス、パームアーキテクチャ
データセット:ENWIK8
lm-human-preferences
ダニエル・M・ジーグラー、ニサン・スティエノン、ジェフリー・ウー、トム・B・ブラウン、アレック・ラドフォード、ダリオ・アモデイ、ポール・クリスチャン、ジェフリー・アーヴィング
キーワード:言語の報酬学習、肯定的な感情を伴う継続テキスト、要約タスク、物理的記述
データセット:TL; DR、CNN/DM
次のインストラクション - ヒューマンフィードバック
Long Ouyang、Jeff Wu、Xu Jiang、他
キーワード:大規模な言語モデル、言語モデルを人間の意図と整列させる
データセット:Truthfulqa RealToxicityPrompts
トランス補強学習(TRL)
Leandro Von Werra、Younes Belkada、Lewis Tunstall、他
キーワード:RL、PPO、トランスを備えたLLMをトレーニングします
タスク:IMDBセンチメント
トランス強化学習X(TRLX)
ジョナサン・トウ、レアンドロ・フォン・ウェラ、他
キーワード:分散トレーニングフレームワーク、T5ベースの言語モデル、RL、PPO、ILQLを備えたLLMをトレーニング
タスク:提供された報酬機能または報酬標識データセットを使用してRLを使用してLLMを微調整します
RL4LMS(人間の好みに合わせて言語モデルを微調整するためのモジュラーRLライブラリ)
Rajkumar Ramamurthy、Prithviraj Ammanabrolu、Kianté、Brantley、Jack Hessel、Rafet Sifa、Christian Bauckhage、Hannaneh Hajishirzi、Yejin Choi
キーワード:RL、ベンチマーク、パフォーマンスRLアルゴリズムを使用した言語ジェネレーターの最適化
データセット:IMDB、Commongen、CNN Daily Mail、Totto、WMT-16(EN-DE)、NaryativeQa、DailyDialog
Lamda-rlhf-pytorch
フィル・ワン
キーワード:ラムダ、注意メカニズム
タスク:PytorchのGoogleのLamda Research Paperのオープンソースの事前トレーニングの実装
textrl
エリック・ラム
キーワード:Huggingfaceのトランス
タスク:テキスト生成
env:PFRL、ジム
minrlhf
トムフォスター
キーワード:PPO、最小ライブラリ
タスク:教育目的
deepspeed-chat
マイクロソフト
キーワード:手頃なRLHFトレーニング
ドロメダリー
IBM
キーワード:最小限の人間の監督、自己調整
タスク:最小限の人間の監督で訓練された自己整合言語モデル
fg-rlhf
Zeqiu Wu、Yushi Hu、Weijia Shi、他
キーワード:細かいrlhf、すべてのセグメントの後に報酬を提供し、異なるフィードバックタイプに関連付けられた複数のRMを組み込む
タスク:密度と複数のRMS -Safe-RLHFで細かく密集している報酬関数からトレーニングと学習を可能にするフレームワーク
Xuehai Pan、Ruiyang Sun、Jiaming Ji、他
キーワード:人気のある事前訓練モデル、大規模な人間標識データセット、安全制約の検証のためのマルチスケールメトリック、カスタマイズされたパラメーターをサポートする
タスク:SAFE RLHFを介して、付加価値LLMを制約します
format: - [title](dataset link) [links] - author1, author2, and author3... - keyword - experiment environments or tasks
HH-RLHF
ベン・マン、ディープ・ガンガリ
キーワード:人間の好みのデータセット、赤いチーム化データ、機械書
タスク:有用性と無害性に関する人間の好みのデータのためのオープンソースデータセット
スタンフォードヒューマン選好データセット(SHP)
エタヤラジ、カウィンとチャン、ハイジと王、イジュホンとジュラフスキー、ダン
キーワード:自然に発生し、人間が書いたデータセット、18の異なるサブジェクトエリア
タスク:RLHF報酬モデルのトレーニングに使用することを目的としています
プロンプトソース
Stephen H. Bach、Victor Sanh、Zheng-Xin Yong et al。
キーワード:英語のデータセットを促し、データの例を自然言語にマッピングする
タスク:自然言語のプロンプトを作成、共有、使用するためのツールキット
構造化された知識接地(SKG)リソースコレクション
Tianbao Xie、Chen Henry Wu、Peng Shi et al。
キーワード:構造化された知識の基礎
タスク:データセットの収集は、構造化された知識の基礎に関連しています
フランコレクション
Longpre Shayne、Houle、Vu Tu et al。
タスク:コレクションはFlan 2021、P3、超自然的な指示からのデータセットをコンパイルします
RLHF-REWARD-DATASETS
Xie
キーワード:マシン作成されたデータセット
webgpt_comparisons
Openai
キーワード:人間が作成したデータセット、長いフォームの質問応答
タスク:人間の好みに合わせて長いフォームの質問回答モデルをトレーニングする
summarize_from_feedback
Openai
キーワード:人間が書いたデータセット、要約
タスク:要約モデルをトレーニングして、人間の好みに合わせて
Dahoas/Synthetic-Instruct-Gptj-PairWise
dahoas
キーワード:人間が書いたデータセット、合成データセット
安定したアライメント - ソーシャルゲームでのアライメント学習
Ruibo Liu、Ruixin(Ray)Yang、Qiang Peng
キーワード:アライメントトレーニングに使用されるインタラクションデータ、サンドボックスで実行
タスク:シミュレートされたソーシャルゲームで記録された相互作用データのトレーニング
リマ
メタAI
キーワード:RLHFがなければ、慎重にキュレーションされたプロンプトと応答はほとんどありません
タスク:LIMAモデルのトレーニングに使用されるデータセット
[Openai] ChatGpt:ダイアログの言語モデルを最適化します
[顔を抱き締める]人間のフィードバックからの補強学習(RLHF)
[zhihu]通向agi之路:大型语言模型(LLM)技术精要
[Zhihu]大语言模型的涌现能力:现象与解释
[Zhihu]中文Hh-rlhf数据集上的ppos
[W&B完全に接続されている]人間のフィードバックからの補強学習(RLHF)
[deepmind]人間のフィードバックを通して学習
[概念]深入理解语言模型的突现能力
[概念] gpt-3.5各项能力的起源
[GIST]言語モデルの強化学習
[YouTube] John Schulman-人間のフィードバックからの補強学習:進歩と課題
[Openai / arize]人間のフィードバックを用いた補強学習に関するOpenai
[エンコード]コンピュータービジョンのための人間のフィードバック(RLHF)からの強化学習のガイド
[Weixun Wang] RL(HF)+LLMの概要
トルコ語
私たちの目的は、このレポをさらに良くすることです。貢献に興味がある場合は、貢献の指示についてはこちらをご覧ください。
Awesome RLHFは、Apache 2.0ライセンスの下でリリースされます。


