VitalSource Grabber
1.0.0
VitalSourceは、教科書用のオンラインストアです。残念ながら、購入したコンテンツへのアクセスは非常に限られています。 Vitalsourceのアプリを使用して本(PDFなし)を読む必要があり、印刷は一度に2ページに制限されています。これらの2ページは、電子メールアドレスが透かして透かしられ、画像として提供されるため、検索不可能になります。素晴らしい。 Vitalsourceの本のダウンロードを約束する他のいくつかのリポジトリがありますが、それらのどれも私のために働いていないので、私は自分のものを書きました。
pip3 install requests )brew install imagemagick )前述のように、VitalSourceを使用すると、一度に最大2ページを印刷できます。これは重要な詳細です。各本は別の形式(A5/A4/カスタム)で設定される可能性があるため、印刷されたレイアウトは常にA4サイズです。したがって、2つのA5サイズのテキストでは、2つのA4印刷ページが完全には記入されません。
VitalSourceに1つずつページを印刷するように依頼すると、すべてのページのコンテンツが均等に分散されます。 2ページで印刷することを選択し、元の本がA4形式よりも小さく設定されていた場合、均一なページは通常ほとんど空になります。この違いをよりよく説明するには、次の画像を参照してください。 
ページをダウンロードするには、希望するバリアントに応じて、 download_single.pyまたはdownload_double.pyスクリプトのいずれかを使用する必要があります。両方のバリアントで最初の10ページをダウンロードし、結果に基づいて決定することをお勧めします(各本で異なります)。
スクリプトを実行する前に、行9-11、 IBAN 、 VitalSourceAPIKey 、およびVitalSourceAccessTokenの行のパラメーターを変更する必要があります。 IBANはかなり自明ですが、他の2つのパラメーターはあなたの側で何らかの作業を必要とします。推奨されるデバッグプロキシのいずれかを使用して、BookShelfアプリのネットワークトラフィックをキャプチャし、そこから2つのヘッダープロパティを抽出する必要があります。プロキシを配置したら、本棚アプリで本を開いて、任意のページを印刷します。次に、 https://print.vitalsource.com/ domainへのトラフィックのプロキシログを確認し、リクエストヘッダーを確認します。 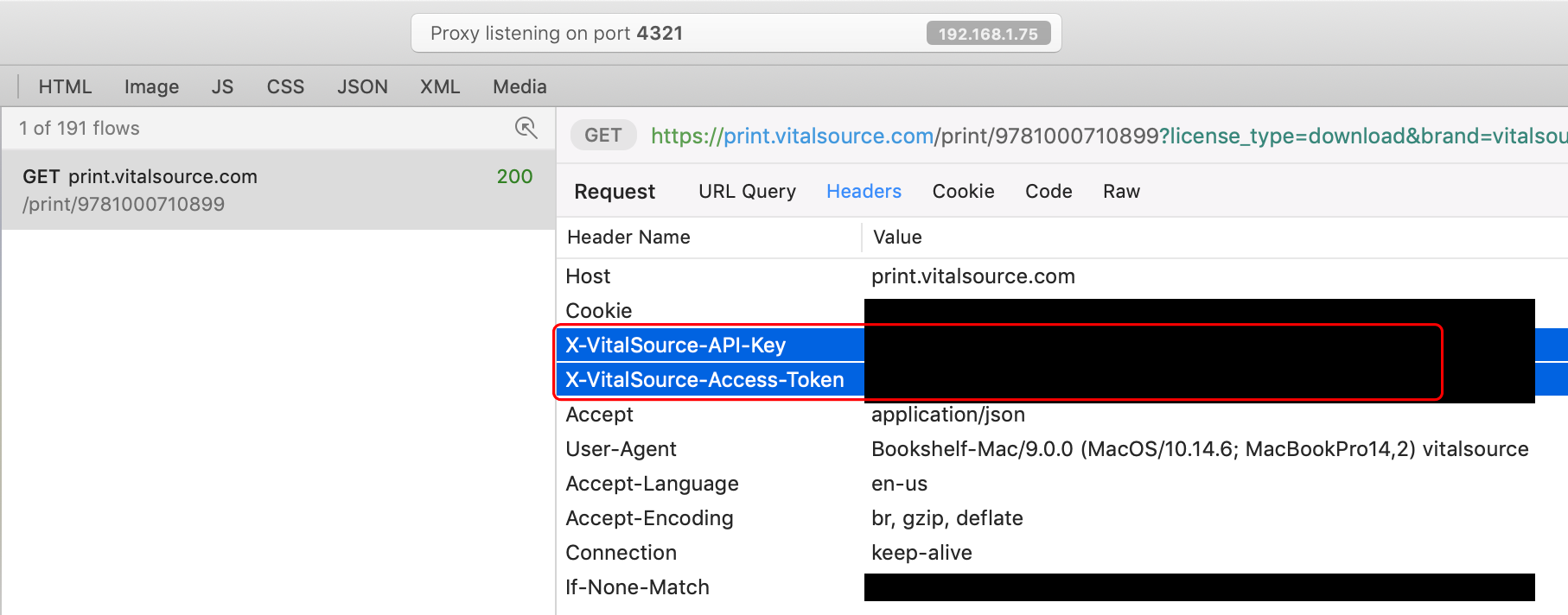
3つのパラメーターを更新したら、スクリプトを実行します。ゆっくりと(アラートのトリガーを避けるためにダウンロードがスロットルされます)、要求されたページをダウンロードの新しいフォルダーにダウンロードします。
Script process.shダウンロードされたページのクリーンアップを処理します。まず、透かしを削除し、各ページの下部にページ番号を追加します。 
ダウンロードされた本のIBANでスクリプトを唯一のパラメーターとして実行するだけで、あなたは良いはずです。このように./process.sh 9781000710899
これは簡単です - すべての画像を選択するだけで、右クリックしてクイックアクションを選択> PDFの作成を選択します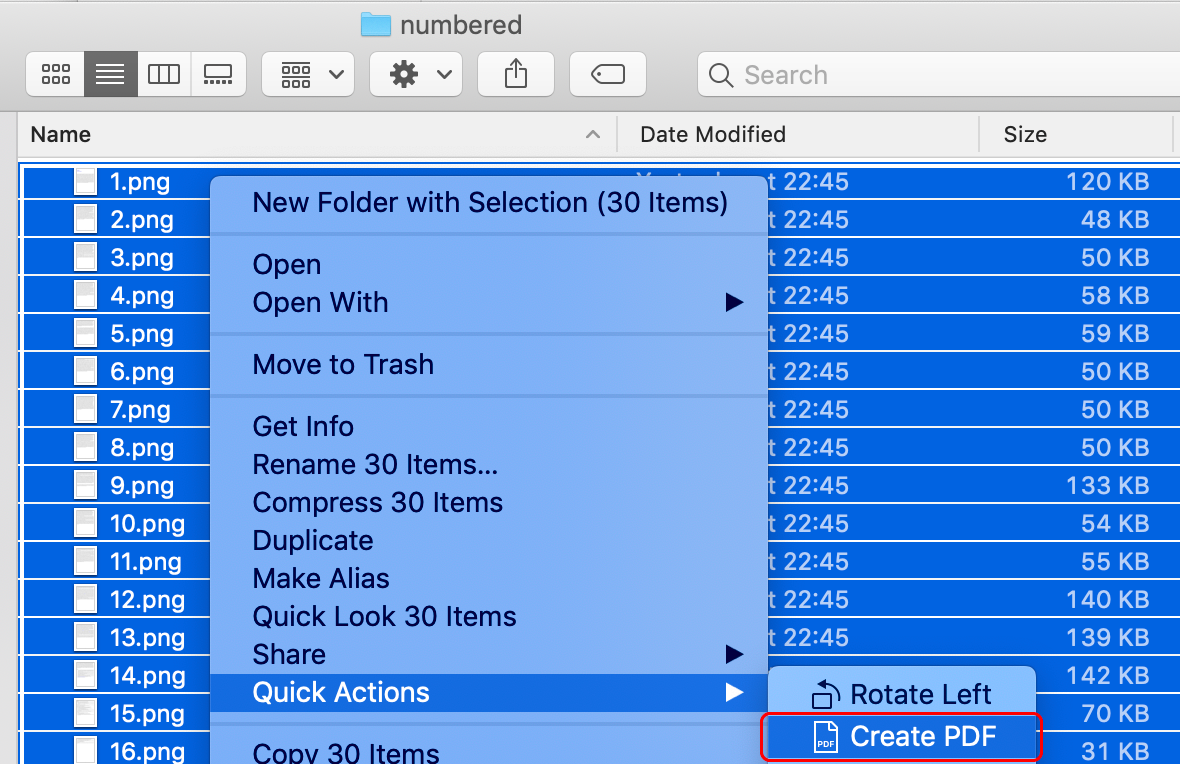
最終的なPDFを検索可能にするには、光学文字認識(OCR)を実行する必要があります。これを行うことができる多くの商用ツールがあります。たとえば、Adobe Acrobatなどです。


