IP Adapter
1.0.0
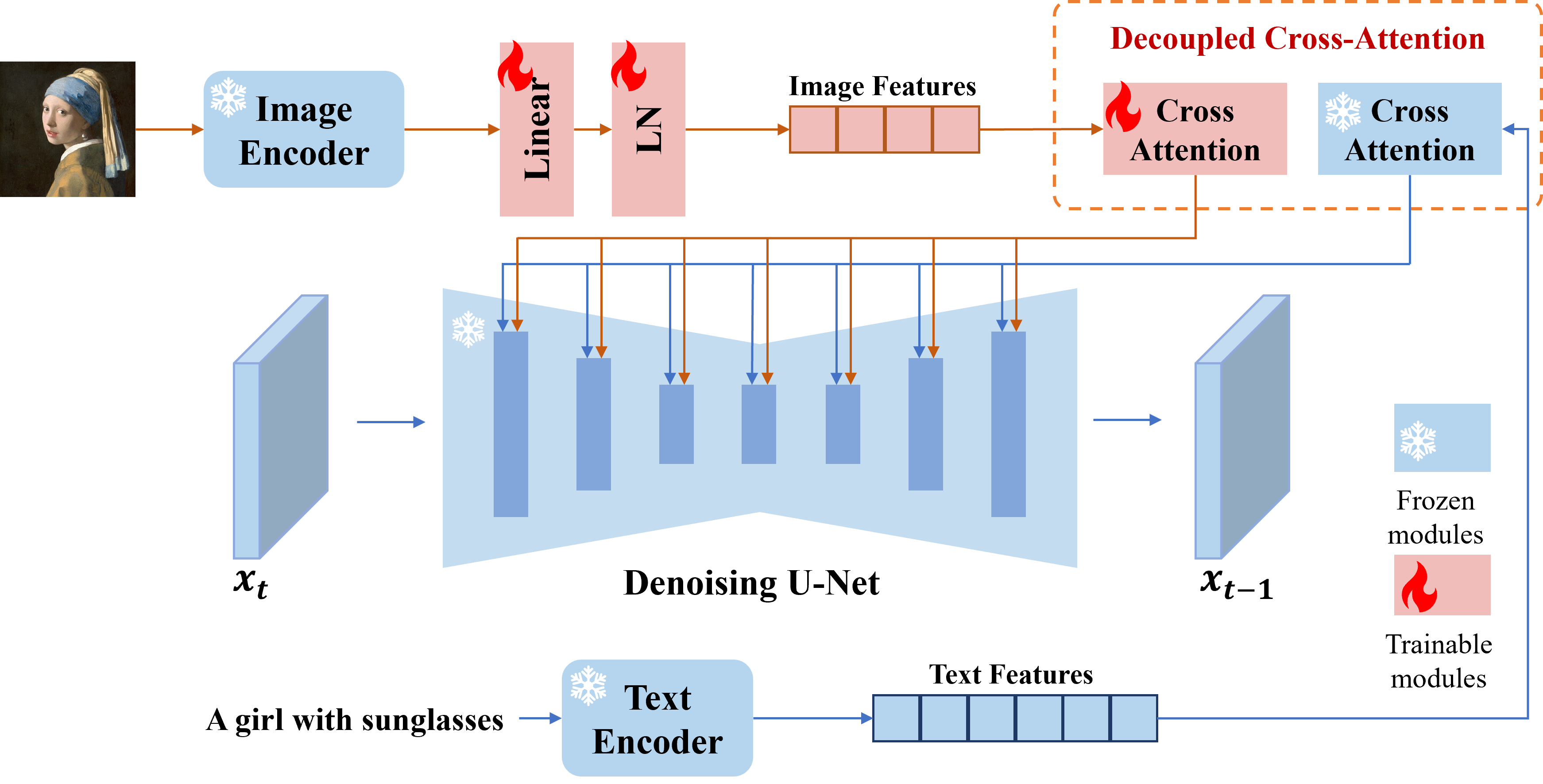
事前に訓練されたテキストから画像への拡散モデルの画像プロンプト機能を実現するための効果的で軽量のアダプターであるIP-Adapterを提示します。 22mパラメーターのみを備えたIPアダプターは、微調整された画像プロンプトモデルに匹敵するパフォーマンスまたはさらに優れたパフォーマンスを実現できます。 IP-Adapterは、同じベースモデルから微調整された他のカスタムモデルだけでなく、既存の制御可能なツールを使用した制御可能な生成にも一般化できます。さらに、画像プロンプトは、マルチモーダル画像生成を達成するために、テキストプロンプトともうまく連携することもできます。
# install latest diffusers
pip install diffusers==0.22.1
# install ip-adapter
pip install git+https://github.com/tencent-ailab/IP-Adapter.git
# download the models
cd IP-Adapter
git lfs install
git clone https://huggingface.co/h94/IP-Adapter
mv IP-Adapter/models models
mv IP-Adapter/sdxl_models sdxl_models
# then you can use the notebook
ここからモデルをダウンロードできます。デモを実行するには、次のモデルもダウンロードする必要があります。









ベストプラクティス
scale=1.0およびtext_prompt="" (または「最高品質」などの一般的なテキストプロンプトを設定できます。ネガティブテキストプロンプトを使用することもできます)。 scaleを下げると、より多様な画像を生成できますが、画像プロンプトとそれほど一致しない場合があります。scaleを調整して最良の結果を得ることができます。ほとんどの場合、 scale=0.5の設定は良い結果を得ることができます。 SD 1.5のバージョンについては、コミュニティモデルを使用して良い画像を生成することをお勧めします。非二乗画像用のIPアダプター
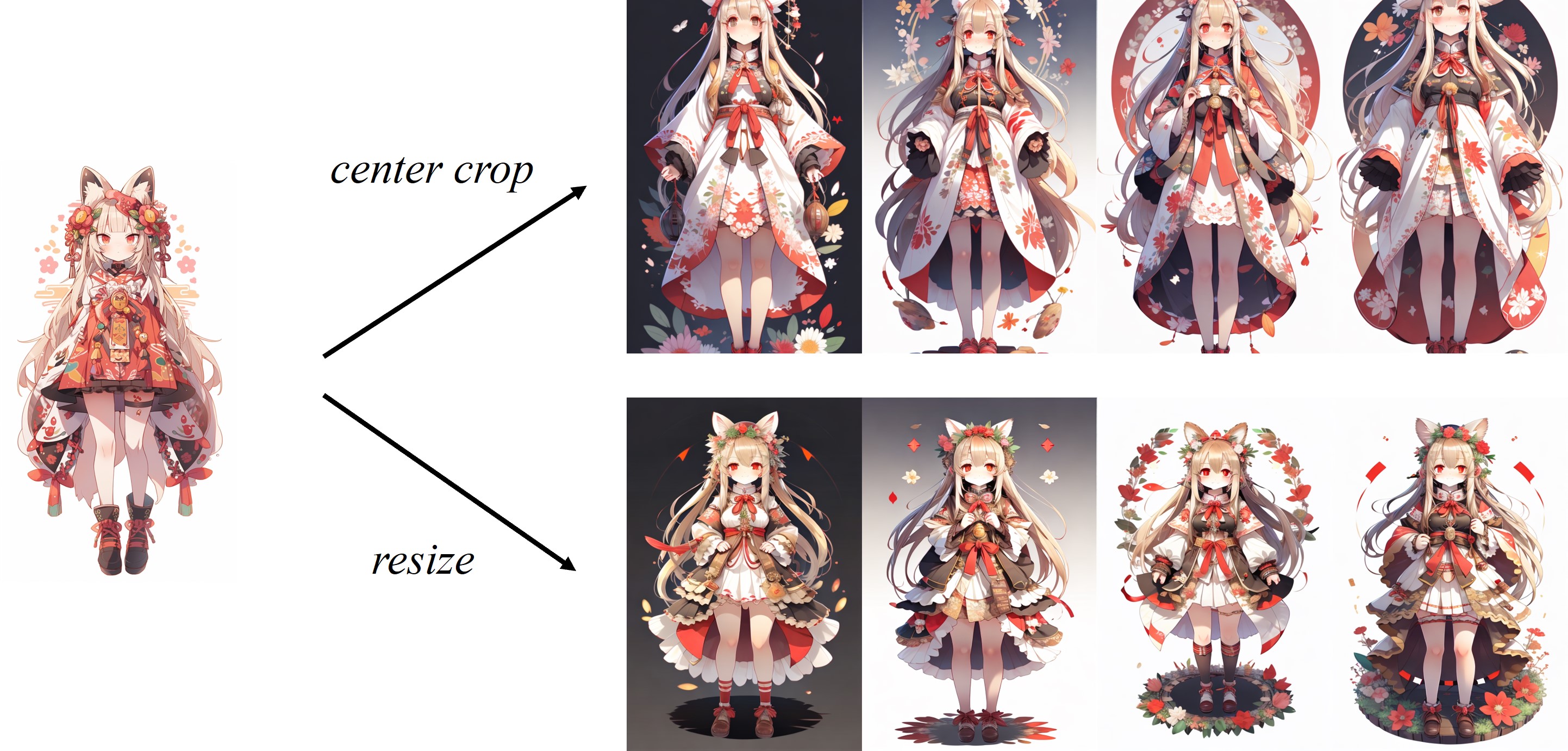
画像はClipのデフォルト画像プロセッサで中央にトリミングされているため、IP-Adapterは正方形の画像に最適です。非正方形の画像については、センターの外側の情報を見逃します。ただし、非二乗画像の場合は224x224にサイズを変更できます。比較は次のとおりです。
IP-Adapter_xlとReimagine XLの比較は、次のように示されています。

新しいバージョンの改善(2023.9.8) :
トレーニングについては、Accelerateをインストールし、JSONファイルに独自のデータセットを作成する必要があります。
accelerate launch --num_processes 8 --multi_gpu --mixed_precision "fp16"
tutorial_train.py
--pretrained_model_name_or_path="runwayml/stable-diffusion-v1-5/"
--image_encoder_path="{image_encoder_path}"
--data_json_file="{data.json}"
--data_root_path="{image_path}"
--mixed_precision="fp16"
--resolution=512
--train_batch_size=8
--dataloader_num_workers=4
--learning_rate=1e-04
--weight_decay=0.01
--output_dir="{output_dir}"
--save_steps=10000
トレーニングが完了したら、次のコードでウェイトを変換できます。
import torch
ckpt = "checkpoint-50000/pytorch_model.bin"
sd = torch . load ( ckpt , map_location = "cpu" )
image_proj_sd = {}
ip_sd = {}
for k in sd :
if k . startswith ( "unet" ):
pass
elif k . startswith ( "image_proj_model" ):
image_proj_sd [ k . replace ( "image_proj_model." , "" )] = sd [ k ]
elif k . startswith ( "adapter_modules" ):
ip_sd [ k . replace ( "adapter_modules." , "" )] = sd [ k ]
torch . save ({ "image_proj" : image_proj_sd , "ip_adapter" : ip_sd }, "ip_adapter.bin" )このプロジェクトは、AI駆動型の画像生成のドメインにプラスの影響を与えるよう努めています。ユーザーには、このツールを使用して画像を作成する自由が認められますが、地元の法律に準拠し、責任ある方法でそれを活用することが期待されています。開発者は、ユーザーによる潜在的な誤用について一切責任を負いません。
IP-Adapterが研究やアプリケーションに役立つと思われる場合は、このbibtexを使用して引用してください。
@article { ye2023ip-adapter ,
title = { IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models } ,
author = { Ye, Hu and Zhang, Jun and Liu, Sibo and Han, Xiao and Yang, Wei } ,
booktitle = { arXiv preprint arxiv:2308.06721 } ,
year = { 2023 }
}

