multi model server
v1.1.11 - Extra error logging and new timeout config
| ubuntu/python-2.7 | ubuntu/python-3.6 |
|---|---|
Multi Model Server(MMS)は、ML/DLフレームワークを使用してトレーニングされたディープラーニングモデルを提供するための柔軟で使いやすいツールです。
MMSサーバーCLIまたは事前に構成されたDocker画像を使用して、モデル推論要求を処理するHTTPエンドポイントを設定するサービスを開始します。
サービングとパッケージの両方の簡単な概要と例を以下に示します。詳細なドキュメントと例は、Docsフォルダーに記載されています。
参加してください Slackチャンネル開発チームと連絡を取り、質問し、料理が何であるかなどを見つけてください!
Slackチャンネル開発チームと連絡を取り、質問し、料理が何であるかなどを見つけてください!
このドキュメントをさらに進める前に、次の前提条件があることを確認してください。
ubuntu、centos、またはmacos。 Windowsサポートは実験的です。次の指示では、Linuxとmacosのみに焦点を当てます。
Python -Multi Model Serverでは、ワーカーを実行するためにPythonが必要です。
PIP -PIPはPythonパッケージ管理システムです。
Java 8-マルチモデルサーバーでは、Java 8を開始する必要があります。 Java 8をインストールするための次のオプションがあります。
ubuntuの場合:
sudo apt-get install openjdk-8-jre-headlessCentosの場合:
sudo yum install java-1.8.0-openjdkmacosの場合:
brew tap homebrew/cask-versions
brew update
brew cask install adoptopenjdk8ステップ1:仮想環境をセットアップします
仮想環境にマルチモデルサーバーをインストールして実行することをお勧めします。仮想環境ですべてのPython依存関係を実行およびインストールすることをお勧めします。これにより、依存関係の分離と依存関係の管理が容易になります。
1つのオプションは、virtualenvを使用することです。これは、仮想Python環境を作成するために使用されます。次のように、Python 2.7用のVirtualenvをインストールしてアクティブにすることができます。
pip install virtualenv次に、仮想環境を作成します。
# Assuming we want to run python2.7 in /usr/local/bin/python2.7
virtualenv -p /usr/local/bin/python2.7 /tmp/pyenv2
# Enter this virtual environment as follows
source /tmp/pyenv2/bin/activate詳細については、Virtualenvドキュメントを参照してください。
ステップ2: MXNET MMSのインストールは、デフォルトでMXNETエンジンをインストールしません。仮想環境にまだインストールされていない場合は、MXNET PIPパッケージの1つをインストールする必要があります。
CPU推論には、 mxnet-mklが推奨されます。次のようにインストールしてください:
# Recommended for running Multi Model Server on CPU hosts
pip install mxnet-mkl GPU推論には、 mxnet-cu92mklが推奨されます。次のようにインストールしてください:
# Recommended for running Multi Model Server on GPU hosts
pip install mxnet-cu92mklステップ3:次のようにMMSをインストールまたはアップグレードします。
# Install latest released version of multi-model-server
pip install multi-model-server以前のバージョンのmulti-model-serverからアップグレードするには、Migration Reference Documentを参照してください。
注:
model-archiverの最小バージョンがインストールされます。より多くのオプションと詳細については、モデルアーチバーを参照してください。インストールしたら、MMSモデルサーバーを非常に迅速に実行して実行できます。試してみてください--help 、利用可能なすべてのCLIオプションを確認してください。
multi-model-server --helpこのクイックスタートのために、ほとんどの機能をスキップしますが、準備ができたらサーバーの完全なドキュメントを確認してください。
オブジェクト分類モデルを提供するための簡単な例を次に示します。
multi-model-server --start --models squeezenet=https://s3.amazonaws.com/model-server/model_archive_1.0/squeezenet_v1.1.mar上記のコマンドを実行すると、ホストでMMSを実行し、推論リクエストを聞きます。 MMSの開始時にモデルを指定する場合、利用可能なVCPU(CPUインスタンスで実行する場合)または利用可能なGPUの数(GPUインスタンスで実行される場合)に等しい数にバックエンドワーカーを自動的にスケーリングすることに注意してください。 )。多くのコンピューテリソース(VCPUまたはGPU)を備えた強力なホストの場合、この起動と自動化プロセスにはかなりの時間がかかる場合があります。 MMSの起動時間を最小限に抑えたい場合は、起動時間中にモデルの登録とスケールアップを避けて、対応する管理API呼び出しを使用して後のポイントに移動することを試みることができます(これにより、より細かいリソースが割り当てられる量になります。特定のモデル)。
それをテストするために、MMSを実行しているものの横に新しいターミナルウィンドウを開くことができます。その後-o curl使用して、子猫のこれらのkitten.jpg写真の1つをダウンロードできます。次に、子猫のイメージを使用して、MMSへのPOST MMSに予測するエンドポイントcurl 。

以下の例では、これらの手順のショートカットを示します。
curl -O https://s3.amazonaws.com/model-server/inputs/kitten.jpg
curl -X POST http://127.0.0.1:8080/predictions/squeezenet -T kitten.jpg予測エンドポイントは、JSONで予測応答を返します。それは次の結果のように見えます:
[
{
"probability" : 0.8582232594490051 ,
"class" : " n02124075 Egyptian cat "
},
{
"probability" : 0.09159987419843674 ,
"class" : " n02123045 tabby, tabby cat "
},
{
"probability" : 0.0374876894056797 ,
"class" : " n02123159 tiger cat "
},
{
"probability" : 0.006165083032101393 ,
"class" : " n02128385 leopard, Panthera pardus "
},
{
"probability" : 0.0031716004014015198 ,
"class" : " n02127052 lynx, catamount "
}
]この結果は、予測エンドポイントへのcurlコールへの応答と、MMSを実行する端子ウィンドウのサーバーログに表示されます。また、メトリックでローカルに記録されています。
他のモデルはモデル動物園からダウンロードできますので、それらのいくつかも試してください。
今、あなたはMMSで深い学習モデルを提供することがどれほど簡単であるかを見てきました!もっと知りたいですか?
現在の実行中のモデルサーバーインスタンスを停止するには、次のコマンドを実行します。
$ multi-model-server --stopマルチモデルサーバーが停止したことを指定する出力が表示されます。
MMSを使用すると、すべてのモデルアーティファクトを単一のモデルアーカイブにパッケージ化できます。これにより、モデルを簡単に共有して展開できます。モデルをパッケージ化するには、モデルアーキバーのドキュメントをご覧ください
ドキュメントの完全なインデックスについては、Docs ReadMeを参照してください。これには、より多くの例、APIサービスのカスタマイズ方法、APIエンドポイントの詳細などが含まれます。
MMSを搭載したディープラーニングアプリケーションのデモの例を次に示します。
製品レビュー分類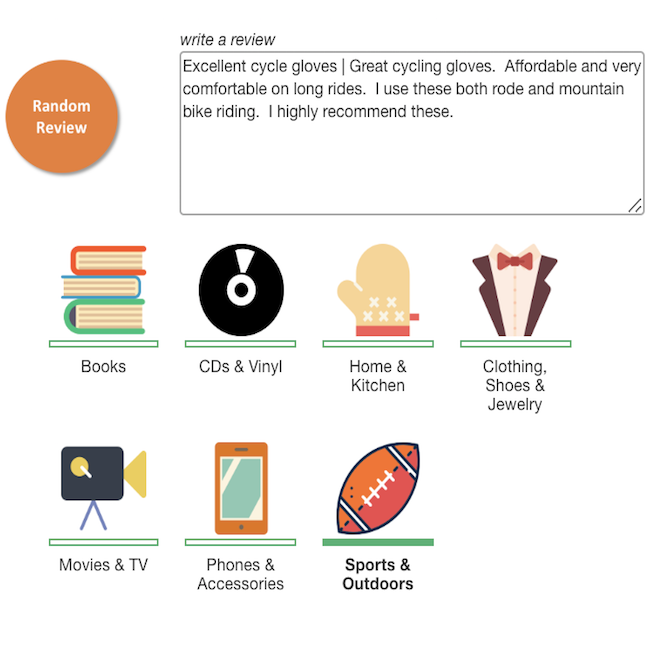 | 視覚検索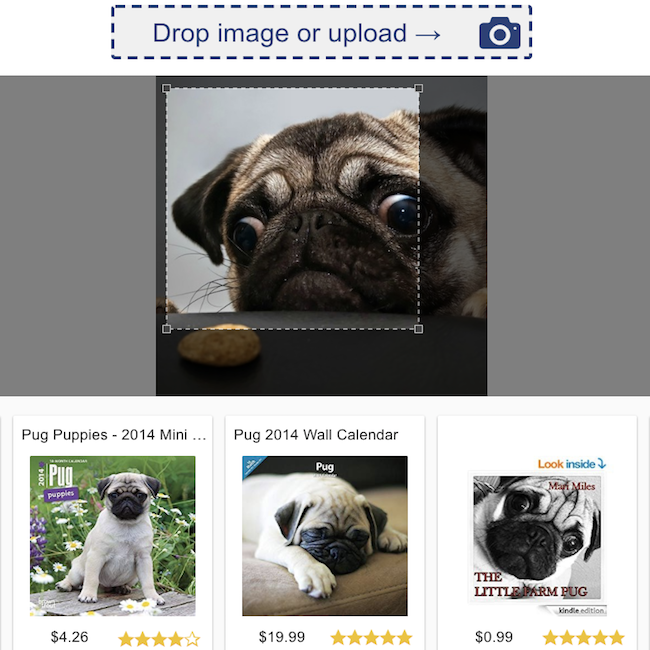 |
顔の感情認識 | ニューラルスタイルの転送 |
すべての貢献を歓迎します!
バグを提出したり、機能をリクエストしたりするには、githubの問題を提出してください。プルリクエストは大歓迎です。


