rl 6 nimmt
1.0.0
6 nimmt! 1994年から2人から10人のプレイヤー向けの受賞歴のあるカードゲームです。ウィキペディアを引用してください。
ゲームには104枚のカードがあり、それぞれにペナルティポイントを表す数字と1〜7個のブルのヘッドシンボルがあります。すべてのプレイヤーが選択した1枚のカードをテーブルに配置する10ターンのラウンドが再生されます。配置されたカードは、固定規則に従って4行に配置されます。すでに5枚のカードを持っている列に配置すると、プレイヤーは5枚のカードを受け取ります。これらのカードは、ラウンドの終わりに合計されているペナルティポイントとしてカウントされます。
6 nimmt!不完全な情報と大量の確率の競争力のあるゲームです。うまくプレーするには、かなりの計画が必要です。同時にゲームプレイはゲームとブラフをマインドすることに役立ちますが、困難なエンドゲームのポジションで終わるのを避けるためには、いくつかの長期的な戦略が必要です。
6 nimmtのわずかに簡素化されたバージョンを実装しました! Openaiジム環境として。元のゲームとは異なり、すべてのスタックの最後のカードよりも低いカードをプレイするとき、プレイヤーはどのスタックを交換するかを自由に選択することはできませんが、代わりにペナルティポイントの最小数で常にスタックを取得します。
これまでのところ、次のエージェントを実装しています。
最初のテストとして、シンプルなセルフプレイトーナメントを実行しました。訓練を受けていない5人のエージェントから始めて、合計で4000ゲームをプレイしました。各ゲームについて、2つ、3つ、または4つのエージェントをランダムに選択してプレイしました(および学習)しました。 400ゲームごとに、最高のパフォーマンスを発揮するエージェントをクローニングし、パフォーマンスの貧しいエージェントのいくつかを追い出しました。最終的に、各エージェントタイプの最高のインスタンスを維持しました。
すべてのゲームにわたる結果:
| エージェント | ゲームが再生されました | 平均スコア | わずかに勝ちます | エロ |
|---|---|---|---|---|
| alpha0.5 | 2246 | -7.79 | 0.42 | 1806 |
| MCS | 2314 | -8.06 | 0.40 | 1745 |
| エイサー | 1408 | -12.28 | 0.18 | 1629 |
| d3qn | 1151 | -13.32 | 0.17 | 1577 |
| ランダム | 1382 | -13.49 | 0.19 | 1556 |
これは、トーナメントの過程で開発されたモデルのパフォーマンス(ELOで測定)です。
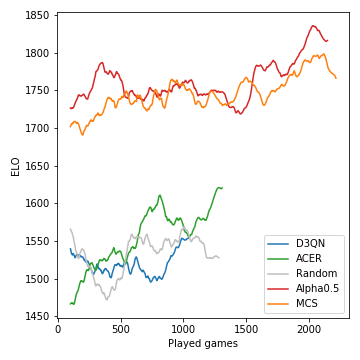
モンテカルロのツリー検索は非常に重要であり、強力なプレイヤーにつながります。一方、モデルのないRLエージェントは、ランダムベースラインを明確に上回ることさえ苦労しています。ゲームの確率的性質のため、勝利の確率とELOの違いは、たとえばチェスにとって可能なほど劇的ではありません。多くのハイパーパラメーターのいずれも調整していないことに注意してください。
この自己プレイフェーズの後、Alpha0.5エージェントは最高の6 Nimmtの1つであるMerleに直面しました!私たちの友人グループのプレイヤーは、5ゲームで。これらはスコアです:
| ゲーム | 1 | 2 | 3 | 4 | 5 | 和 |
|---|---|---|---|---|---|---|
| メルル | -10 | -16 | -11 | -3 | -4 | -44 |
| alpha0.5 | -1 | -3 | -14 | -8 | -6 | -32 |
アナコンダがインストールされていると仮定すると、リポジトリをクローンします
git clone [email protected]:johannbrehmer/rl-6nimmt.git
で仮想環境を作成します
conda env create -f environment.yml
conda activate rl
人間のプレーヤーと訓練されたエージェント間のエージェントの自己プレイとゲームの両方が、simple_tournament.ipynbで実証されています。
ヨハン・ブレマーとマルセル・グッツェによってまとめられます。


