text embeddings inference
v1.5.1
テキスト埋め込みモデルの燃える高速推論ソリューション。
512トークンのシーケンス長を持つNVIDIA A10のBaai/BGE-Base-en-V1.5のベンチマーク:
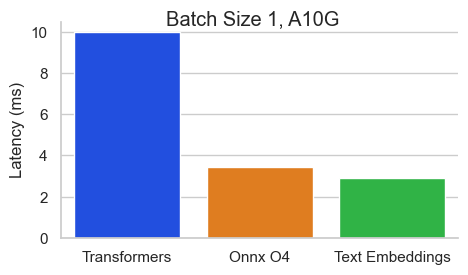
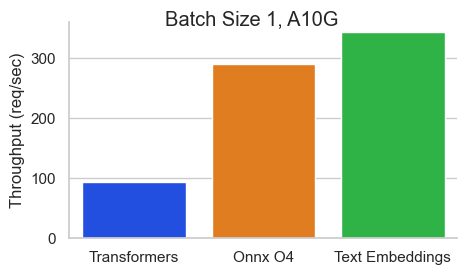
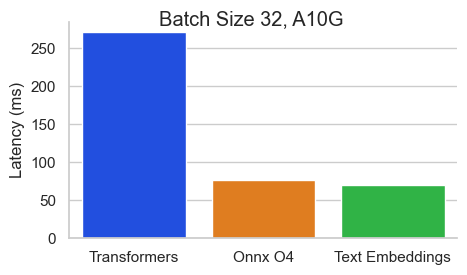
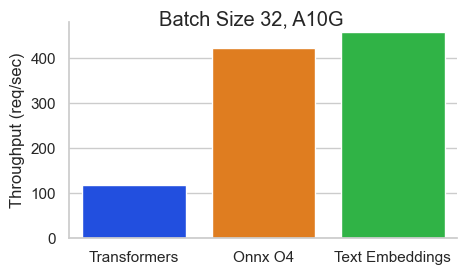
テキスト埋め込み推論(TEI)は、オープンソースのテキスト埋め込みとシーケンス分類モデルを展開および提供するためのツールキットです。 TEIは、Flagembedding、Ember、GTE、E5など、最も人気のあるモデルの高性能抽出を可能にします。 TEIは次のような多くの機能を実装しています。
テキストの埋め込み推論は現在、NOMIC、BERT、CAMEMBERT、XLM-ROBERTAモデルを絶対位置にサポートしています。アリバイ位置とミストラルを備えたジナバートモデル、ロープの位置を持つQWEN2モデルをサポートしています。
以下は、現在サポートされているモデルの例です。
| MTEBランク | モデルサイズ | モデルタイプ | モデルID |
|---|---|---|---|
| 1 | 7b(非常に高価) | ミストラル | Salesforce/SFR-embedding-2_R |
| 2 | 7b(非常に高価) | QWEN2 | Alibaba-nlp/gte-qwen2-7b-instruct |
| 9 | 1.5b(高価) | QWEN2 | Alibaba-nlp/gte-qwen2-1.5b-instruct |
| 15 | 0.4b | Alibaba Gte | Alibaba-nlp/gte-large-en-v1.5 |
| 20 | 0.3b | バート | Whereisai/uae-large-v1 |
| 24 | 0.5b | xlm-roberta | intfloat/multhingual-e5-rarge-intruct |
| n/a | 0.1b | NomicBert | NOMIC-AI/NOMIC-MENBED-TEXT-V1 |
| n/a | 0.1b | NomicBert | nomic-ai/nomic-medbed-text-v1.5 |
| n/a | 0.1b | ジナバート | Jinaai/Jina-embeddings-v2-base-en |
| n/a | 0.1b | ジナバート | Jinaai/Jina-embeddings-v2-base-code |
最高のパフォーマンスのテキスト埋め込みモデルのリストを調べるには、大規模なテキスト埋め込みベンチマーク(MTEB)リーダーボードにアクセスしてください。
テキストの埋め込み推論は現在、Camembertと、絶対位置を持つXLM-Robertaシーケンス分類モデルをサポートしています。
以下は、現在サポートされているモデルの例です。
| タスク | モデルタイプ | モデルID |
|---|---|---|
| 再ランク | xlm-roberta | baai/bge-reranker-large |
| 再ランク | xlm-roberta | baai/bge-reranker-base |
| 再ランク | GTE | Alibaba-NLP/GTE-Multilingual-Reranker-Base |
| 感情分析 | ロベルタ | Samlowe/Roberta-Base-go_emotions |
model=BAAI/bge-large-en-v1.5
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $modelそして、次のようなリクエストを行うことができます
curl 127.0.0.1:8080/embed
-X POST
-d ' {"inputs":"What is Deep Learning?"} '
-H ' Content-Type: application/json '注: GPUを使用するには、NVIDIAコンテナツールキットをインストールする必要があります。マシン上のnvidiaドライバーは、CUDAバージョン12.2以上と互換性がある必要があります。
モデルを提供するすべてのオプションを表示するには:
text-embeddings-router --help Usage: text-embeddings-router [OPTIONS]
Options:
--model-id <MODEL_ID>
The name of the model to load. Can be a MODEL_ID as listed on <https://hf.co/models> like `thenlper/gte-base`.
Or it can be a local directory containing the necessary files as saved by `save_pretrained(...)` methods of
transformers
[env: MODEL_ID=]
[default: thenlper/gte-base]
--revision <REVISION>
The actual revision of the model if you're referring to a model on the hub. You can use a specific commit id
or a branch like `refs/pr/2`
[env: REVISION=]
--tokenization-workers <TOKENIZATION_WORKERS>
Optionally control the number of tokenizer workers used for payload tokenization, validation and truncation.
Default to the number of CPU cores on the machine
[env: TOKENIZATION_WORKERS=]
--dtype <DTYPE>
The dtype to be forced upon the model
[env: DTYPE=]
[possible values: float16, float32]
--pooling <POOLING>
Optionally control the pooling method for embedding models.
If `pooling` is not set, the pooling configuration will be parsed from the model `1_Pooling/config.json` configuration.
If `pooling` is set, it will override the model pooling configuration
[env: POOLING=]
Possible values:
- cls: Select the CLS token as embedding
- mean: Apply Mean pooling to the model embeddings
- splade: Apply SPLADE (Sparse Lexical and Expansion) to the model embeddings. This option is only
available if the loaded model is a `ForMaskedLM` Transformer model
- last-token: Select the last token as embedding
--max-concurrent-requests <MAX_CONCURRENT_REQUESTS>
The maximum amount of concurrent requests for this particular deployment.
Having a low limit will refuse clients requests instead of having them wait for too long and is usually good
to handle backpressure correctly
[env: MAX_CONCURRENT_REQUESTS=]
[default: 512]
--max-batch-tokens <MAX_BATCH_TOKENS>
**IMPORTANT** This is one critical control to allow maximum usage of the available hardware.
This represents the total amount of potential tokens within a batch.
For `max_batch_tokens=1000`, you could fit `10` queries of `total_tokens=100` or a single query of `1000` tokens.
Overall this number should be the largest possible until the model is compute bound. Since the actual memory
overhead depends on the model implementation, text-embeddings-inference cannot infer this number automatically.
[env: MAX_BATCH_TOKENS=]
[default: 16384]
--max-batch-requests <MAX_BATCH_REQUESTS>
Optionally control the maximum number of individual requests in a batch
[env: MAX_BATCH_REQUESTS=]
--max-client-batch-size <MAX_CLIENT_BATCH_SIZE>
Control the maximum number of inputs that a client can send in a single request
[env: MAX_CLIENT_BATCH_SIZE=]
[default: 32]
--auto-truncate
Automatically truncate inputs that are longer than the maximum supported size
Unused for gRPC servers
[env: AUTO_TRUNCATE=]
--default-prompt-name <DEFAULT_PROMPT_NAME>
The name of the prompt that should be used by default for encoding. If not set, no prompt will be applied.
Must be a key in the `sentence-transformers` configuration `prompts` dictionary.
For example if ``default_prompt_name`` is "query" and the ``prompts`` is {"query": "query: ", ...}, then the
sentence "What is the capital of France?" will be encoded as "query: What is the capital of France?" because
the prompt text will be prepended before any text to encode.
The argument '--default-prompt-name <DEFAULT_PROMPT_NAME>' cannot be used with '--default-prompt <DEFAULT_PROMPT>`
[env: DEFAULT_PROMPT_NAME=]
--default-prompt <DEFAULT_PROMPT>
The prompt that should be used by default for encoding. If not set, no prompt will be applied.
For example if ``default_prompt`` is "query: " then the sentence "What is the capital of France?" will be
encoded as "query: What is the capital of France?" because the prompt text will be prepended before any text
to encode.
The argument '--default-prompt <DEFAULT_PROMPT>' cannot be used with '--default-prompt-name <DEFAULT_PROMPT_NAME>`
[env: DEFAULT_PROMPT=]
--hf-api-token <HF_API_TOKEN>
Your HuggingFace hub token
[env: HF_API_TOKEN=]
--hostname <HOSTNAME>
The IP address to listen on
[env: HOSTNAME=]
[default: 0.0.0.0]
-p, --port <PORT>
The port to listen on
[env: PORT=]
[default: 3000]
--uds-path <UDS_PATH>
The name of the unix socket some text-embeddings-inference backends will use as they communicate internally
with gRPC
[env: UDS_PATH=]
[default: /tmp/text-embeddings-inference-server]
--huggingface-hub-cache <HUGGINGFACE_HUB_CACHE>
The location of the huggingface hub cache. Used to override the location if you want to provide a mounted disk
for instance
[env: HUGGINGFACE_HUB_CACHE=]
--payload-limit <PAYLOAD_LIMIT>
Payload size limit in bytes
Default is 2MB
[env: PAYLOAD_LIMIT=]
[default: 2000000]
--api-key <API_KEY>
Set an api key for request authorization.
By default the server responds to every request. With an api key set, the requests must have the Authorization
header set with the api key as Bearer token.
[env: API_KEY=]
--json-output
Outputs the logs in JSON format (useful for telemetry)
[env: JSON_OUTPUT=]
--otlp-endpoint <OTLP_ENDPOINT>
The grpc endpoint for opentelemetry. Telemetry is sent to this endpoint as OTLP over gRPC. e.g. `http://localhost:4317`
[env: OTLP_ENDPOINT=]
--otlp-service-name <OTLP_SERVICE_NAME>
The service name for opentelemetry. e.g. `text-embeddings-inference.server`
[env: OTLP_SERVICE_NAME=]
[default: text-embeddings-inference.server]
--cors-allow-origin <CORS_ALLOW_ORIGIN>
Unused for gRPC servers
[env: CORS_ALLOW_ORIGIN=]
テキスト埋め込み推論特定のバックエンドをターゲットにするために使用できる複数のDocker画像を搭載した船舶は次のとおりです。
| 建築 | 画像 |
|---|---|
| CPU | ghcr.io/huggingface/text-embeddings-inference:cpu-1.5 |
| Volta | サポートされていません |
| チューリング(T4、RTX 2000シリーズ、...) | ghcr.io/huggingface/text-embeddings-inference:turing-1.5(実験) |
| アンペア80(A100、A30) | ghcr.io/huggingface/text-embeddings-inference:1.5 |
| アンペア86(A10、A40、...) | ghcr.io/huggingface/text-embeddings-inference:86-1.5 |
| Ada Lovelace(RTX 4000シリーズ、...) | ghcr.io/huggingface/text-embeddings-inference:89-1.5 |
| ホッパー(H100) | ghcr.io/huggingface/text-embeddings-inference:hopper-1.5(実験的) |
警告:正確な問題に苦しむため、チューリング画像のデフォルトでフラッシュの注意がオフになります。 USE_FLASH_ATTENTION=True環境変数を使用して、Flashの注意V1をオンにすることができます。
/docsルートを使用して、 text-embeddings-inference REST APIのOpenAPIドキュメントを参照できます。 Swagger UIは、https://huggingface.github.io/text-embeddings-inferenceでも入手できます。
text-embeddings-inferenceによって使用されるトークンを構成するために、 HF_API_TOKEN環境変数を利用するオプションがあります。これにより、保護されたリソースにアクセスできます。
例えば:
HF_API_TOKEN=<your cli READ token>またはDockerで:
model= < your private model >
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
token= < your cli READ token >
docker run --gpus all -e HF_API_TOKEN= $token -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model空気ギャップされた環境でテキスト埋め込み推論を展開するには、最初にウェイトをダウンロードしてから、ボリュームを使用してコンテナ内に取り付けます。
例えば:
# (Optional) create a `models` directory
mkdir models
cd models
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
git clone https://huggingface.co/Alibaba-NLP/gte-base-en-v1.5
# Set the models directory as the volume path
volume= $PWD
# Mount the models directory inside the container with a volume and set the model ID
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id /data/gte-base-en-v1.5text-embeddings-inference v0.4.0 Camembert、Roberta、XLM-Roberta、およびGTEシーケンス分類モデルのサポートが追加されました。再ランカーモデルは、クエリとテキストの類似性をスコアリングする単一のクラスを備えたシーケンス分類クロスエンコーダーモデルです。
LlamainDexチームによるこのブログ投稿を参照して、ラグパイプラインで再ランカーモデルを使用してダウンストリームパフォーマンスを改善する方法を理解してください。
model=BAAI/bge-reranker-large
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $modelそして、クエリとテキストのリストの類似性を次のようにランク付けできます。
curl 127.0.0.1:8080/rerank
-X POST
-d ' {"query": "What is Deep Learning?", "texts": ["Deep Learning is not...", "Deep learning is..."]} '
-H ' Content-Type: application/json 'SamLowe/roberta-base-go_emotionsなどのクラシックシーケンス分類モデルを使用することもできます。
model=SamLowe/roberta-base-go_emotions
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $modelモデルを展開したら、 predictエンドポイントを使用して、入力に最も関連する感情を取得できます。
curl 127.0.0.1:8080/predict
-X POST
-d ' {"inputs":"I like you."} '
-H ' Content-Type: application/json 'BertおよびDistilbert MaskedlmアーキテクチャのSplade Poolingをアクティブにすることを選択できます。
model=naver/efficient-splade-VI-BT-large-query
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model --pooling spladeモデルを展開したら、 /embed_sparseエンドポイントを使用して、スパース埋め込みを取得できます。
curl 127.0.0.1:8080/embed_sparse
-X POST
-d ' {"inputs":"I like you."} '
-H ' Content-Type: application/json 'text-embeddings-inferenceは、Opentelemetryを使用した分散トレースで計装されています。この機能は--otlp-endpoint引数を使用してアドレスをOTLPコレクターに設定することで使用できます。
text-embeddings-inference高性能展開用のデフォルトのHTTP APIに代わるものとしてGRPC APIを提供します。 API Protobuf定義はここにあります。
-grpcタグをTEI Docker画像に追加して、GRPC APIを使用できます。例えば:
model=BAAI/bge-large-en-v1.5
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5-grpc --model-id $model grpcurl -d ' {"inputs": "What is Deep Learning"} ' -plaintext 0.0.0.0:8080 tei.v1.Embed/Embedまた、 text-embeddings-inferenceをローカルにインストールすることもできます。
最初に錆をインストールします:
curl --proto ' =https ' --tlsv1.2 -sSf https://sh.rustup.rs | shその後、実行:
# On x86
cargo install --path router -F mkl
# On M1 or M2
cargo install --path router -F metalこれで、次のようなCPUでテキストエンミング推論を起動できます。
model=BAAI/bge-large-en-v1.5
text-embeddings-router --model-id $model --port 8080注:一部のマシンでは、OpenSSLライブラリとGCCも必要になる場合があります。 Linuxマシンで、実行してください:
sudo apt-get install libssl-dev gcc -yCUDA計算機能<7.5を備えたGPUはサポートされていません(V100、Titan V、GTX 1000シリーズ、...)。
CUDAとNvidiaドライバーがインストールされていることを確認してください。デバイス上のnvidiaドライバーは、CUDAバージョン12.2以上と互換性がある必要があります。また、Nvidiaバイナリをパスに追加する必要があります。
export PATH= $PATH :/usr/local/cuda/binその後、実行:
# This can take a while as we need to compile a lot of cuda kernels
# On Turing GPUs (T4, RTX 2000 series ... )
cargo install --path router -F candle-cuda-turing -F http --no-default-features
# On Ampere and Hopper
cargo install --path router -F candle-cuda -F http --no-default-featuresこれで、次のようなGPUでテキストエンミング推論を起動できます。
model=BAAI/bge-large-en-v1.5
text-embeddings-router --model-id $model --port 8080次のようにCPUコンテナを構築できます。
docker build .CUDA容器を構築するには、実行時に使用するGPUの計算キャップを知る必要があります。
次に、次のようにコンテナを構築できます。
# Example for Turing (T4, RTX 2000 series, ...)
runtime_compute_cap=75
# Example for A100
runtime_compute_cap=80
# Example for A10
runtime_compute_cap=86
# Example for Ada Lovelace (RTX 4000 series, ...)
runtime_compute_cap=89
# Example for H100
runtime_compute_cap=90
docker build . -f Dockerfile-cuda --build-arg CUDA_COMPUTE_CAP= $runtime_compute_capここで説明されているように、MPS対応のARM64 Docker画像、Metal / MPSはDockerを介してサポートされていません。このように推論はCPUバウンドであり、M1/M2 ARM CPUでこのDockerイメージを使用する場合、おそらくかなり遅くなります。
docker build . -f Dockerfile --platform=linux/arm64


