kubeai
helm-chart-models-0.9.0
Kubernetesで実行されている推論を取得:LLMS、埋め込み、スピーチツーテキスト。
API互換性を備えたOpenAIのドロップイン交換
sealゼロからのスケール、負荷に基づくオートスケール
?テキスト生成モデル(LLM、VLMなど)を提供する
テキストAPIへのスピーチ
?埋め込み/ベクトルAPI
マルチプラットフォーム:CPUのみ、GPU、TPU
?共有ファイルシステムを使用したモデルキャッシュ(EFS、Filestoreなど)
ゼロ依存関係(ISTIO、ナイティブなどに依存しません)
チャットUIが含まれています(OpenWebui)
? OSSモデルサーバー(VLLM、Ollama、FasterWhisper、Infinity)を操作します
✉メッセージング統合を介したストリーム/バッチ推論(Kafka、pubsubなど)
コミュニティからの引用:
LLMSを実行するための再利用可能な、よく抽象化されたソリューション-MikeEnsor
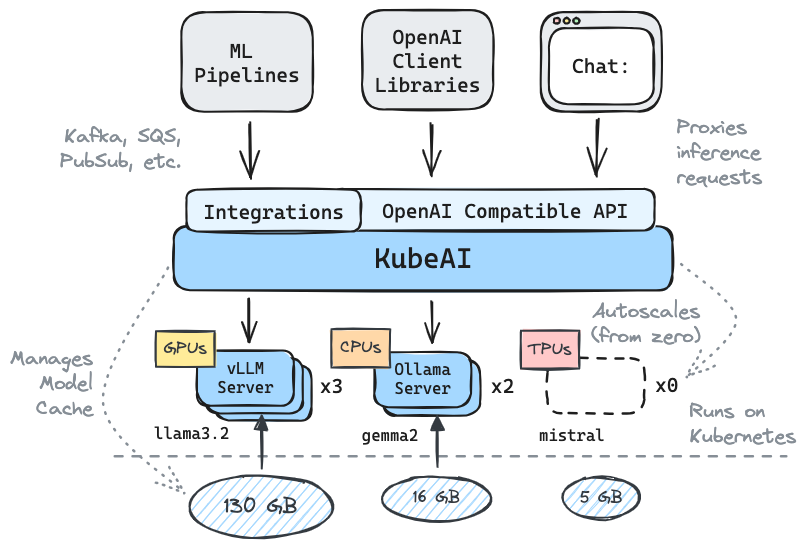
Kubeaiは、OpenAI互換性のあるHTTP APIを提供しています。管理者はkind: Model Kubernetesカスタムリソースを介してMLモデルを構成できます。 Kubeaiは、VLLMおよびOllamaサーバーを管理するモデル演算子(オペレーターパターンを参照)と考えることができます。
KindまたはMinikubeを使用してローカルクラスターを作成します。
# You might need to stop and remove the existing machine:
podman machine stop
podman machine rm
# Init and start a new machine:
podman machine init --memory 6144 --disk-size 120
podman machine startkind create cluster # OR: minikube startKubeai Helmリポジトリを追加します。
helm repo add kubeai https://www.kubeai.org
helm repo updateKubeaiをインストールし、すべてのコンポーネントが準備が整うのを待ちます(1分かかる場合があります)。
helm install kubeai kubeai/kubeai --wait --timeout 10mいくつかの事前定義されたモデルをインストールします。
cat << EOF > kubeai-models.yaml
catalog:
gemma2-2b-cpu:
enabled: true
minReplicas: 1
qwen2-500m-cpu:
enabled: true
nomic-embed-text-cpu:
enabled: true
EOF
helm install kubeai-models kubeai/models
-f ./kubeai-models.yaml次のステップに進む前に、スタンドアロンターミナルのポッドの時計を開始して、Kubeaiがモデルを展開する方法を確認します。
kubectl get pods --watchminReplicas: 1 Gemmaモデルには、モデルポッドが既に登場する必要があります。
バンドルチャットUIにローカルポートを開始します。
kubectl port-forward svc/openwebui 8000:80ブラウザをLocalHost:8000に開き、Gemmaモデルを選択してチャットを開始します。
ブラウザに戻ってQWEN2とのチャットを開始すると、最初に応答するのに時間がかかることに気付くでしょう。これは、 minReplicas: 0このモデルの場合は、Kubeaiが新しいポッドをスピンアップする必要があります( kubectl get models -oyaml qwen2-500m-cpuで確認できます)。
kubeai.orgのドキュメントをチェックアウトして、次の情報を見つけます。
既知の採用者のリスト:
| 名前 | 説明 | リンク |
|---|---|---|
| 望遠鏡 | Telescopeは、多地域の大規模バッチLLM推論にKubeaiを使用します。 | trytelescope.ai |
| Googleクラウド分散エッジ | Kubeaiは、エッジで推論するための参照アーキテクチャとして含まれています。 | LinkedIn、gitlab |
| ラムダ | Lambda AI開発者クラウドでKubeaiをお試しください。 Lambdaのチュートリアルとビデオをご覧ください。 | ラムダ |
Kubeaiを使用していて、採用者としてリストされたい場合は、PRを作成してください。
# Implemented #
/v1/chat/completions
/v1/completions
/v1/embeddings
/v1/models
/v1/audio/transcriptions
# Planned #
# /v1/assistants/*
# /v1/batches/*
# /v1/fine_tuning/*
# /v1/images/*
# /v1/vector_stores/* 注: Kubeaiは、基本的な自動化を備えた単純なKubernetes LLMプロキシであるLingoというプロジェクトから生まれました。プロジェクトをKubeai(2024年8月下旬)として再開し、ロードマップを今日のように拡大しました。
? Githubにスターを落とし、リポジトリに従って最新の状態を保つことを忘れないでください!
質問や質問で見ることや手を差し伸べることに興味がある機能についてお知らせください。 Discordチャンネルにアクセスして、ディスカッションに参加してください!
または、接続したい場合は、LinkedInにアクセスしてください。


