Reading_groups
1.0.0
コンピューティングの力:多くの証拠は、機械学習の進歩は研究ではなくコンピューティングによって主に促進されていることを示しています。「苦いレッスン」を参照してください。しばしば出現と均質化現象があります。 調査により、人工知能コンピューティングの使用は約3.4か月ごとに2倍になり、効率の改善は16か月ごとに2倍になることが示されています。その中でも、計算の量は主にコンピューティングパワーによって駆動されますが、効率は研究によって駆動されます。 これは、コンピューティングの成長が歴史的に機械学習とそのサブフィールドの進歩を支配してきたことを意味します。これは、GPT-4の出現によってさらに証明されています。それにもかかわらず、S4などの将来的には、より崩壊したアーキテクチャがあるかどうかにまだ注意を払う必要があります。 現在のNLP研究ホットスポットのほとんどは、より高度なLLM(〜100B、
LLMトピックの詳細については、こちらとこちらを参照してください。
論文(大まかなカテゴリ)
リソース
GPT-4でのテスト、制限】人工的な一般情報の火花:GPT-4を使用した初期実験
sft、PPOなどを含むinstructgptペーパー、最も重要な記事の1つで、人間のフィードバックで指示に従うための言語モデルをトレーニングする
scalableスケーラブルな監視:モデルが独自のタスクを超えた後、人間はどのようにモデルを改善し続けることができますか? ollight大規模な言語モデルのスケーラブル監視の進捗状況の測定
deepMindによって生成されるアライメントの定義】言語エージェントのアラインメント
調整のための研究室としての一般的な言語アシスタント
[レトロペーパー、CCA+を使用して検索されたモデル]数兆個のトークンから取得することにより、言語モデルの改善
人間の好みからの微調整言語モデル
人間のフィードバックからの補強学習で役立つ無害なアシスタントをトレーニングする
中国語と英語の大きなモデル、GPT-3を超えるGLM-130B:オープンバイリンガルの事前訓練モデル
training訓練前のターゲット最適化】UL2:統一言語学習パラダイム
Alignmentの新しいベンチマーク、モデルライブラリ、および新しい方法は、自然言語処理の補強学習(違います):自然言語政策最適化のためのベンチマーク、ベースライン、およびビルディングブロックは
[[マスク]のないテクノロジーを介した[マスク]タグのないMLM
【イメージトレーニングへのテキストは、語彙のニーズを軽減し、特定の攻撃に抵抗します】言語モデリング
Lexmae:大規模な検索のためのLexicon-BottleNecked Pretraining
Incoder:コードの充填と合成の生成モデル
[言語モデルのテキスト関連の画像を検索してくださいトレーニング前]視覚的に熟成した言語モデリング
非単調な自己終了言語モデル
proptデザインによる否定的なフィードバックの比較と微調整】後知恵のチェーンは、言語モデルをフィードバックと整列させます
【スパローモデル
[小さなモデルパラメーターを使用して、大規模なモデルのトレーニングプロセスを加速します(ゼロから始めるのではなく)]効率的な変圧器トレーニングのために前処理されたモデルを成長させる学習
[複数の知識ソースのMOEセミパラメトリックナレッジフュージョンモデル]知識内の知識:知識のある半パラメトリック言語モデルに向けて
[異なるデータセットで複数の訓練されたモデルを統合するためのマージ方法]言語モデルの重みを統合することによるデータレス知識融合
[検索メカニズムが変圧器のFFNの一般的なアーキテクチャに取って代わること(×2.54時間)がモデルパラメーターに保存されている知識を切り離すことに非常に刺激的です]プラグインで言語モデル
gpt-3トレーニング用の命令チューニングデータを自動的に生成する】自己導入:言語モデルを自己生成命令と整列させる
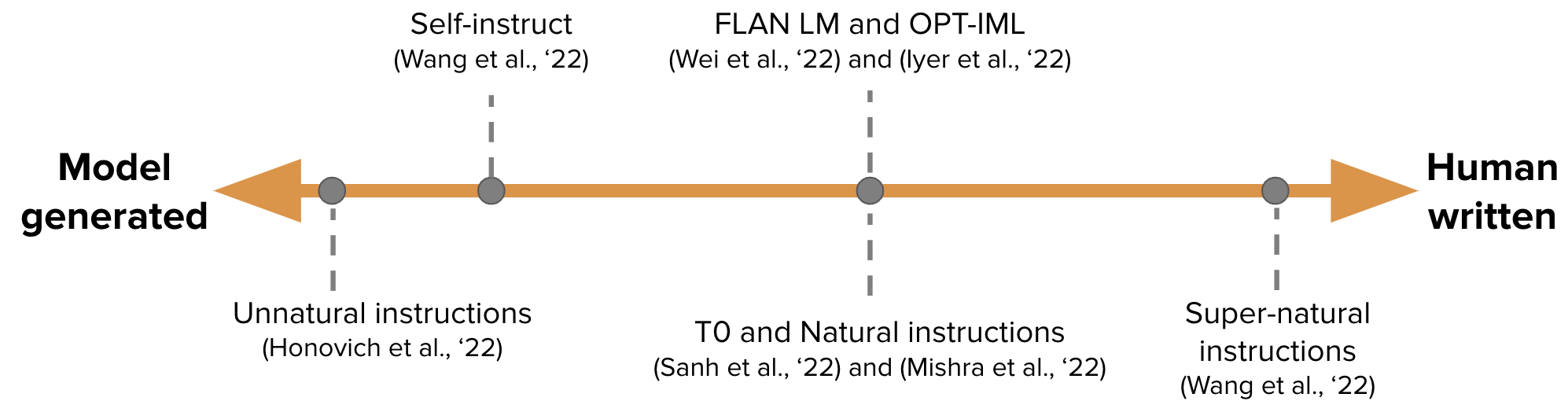
- 
条件付きに依存するマスクされた言語モデルに向けて
deansean Welleckのフォローアップ記事】自己修正を学習することにより、Sean Welleckのフォローアップ記事を繰り返し発生します。
[継続的な学習:新しいタスクにプロップを追加すると、前のタスクのProptと大きなモデルは変わらないままです]プログレッシブプロンプト:忘れずに言語モデルの継続的な学習
[EMNLP 2022、モデルの継続的な更新] Memprompt:ユーザーフィードバックによるメモリアシストプロンプト編集
【新しいニューラルアーキテクチャ(Folnet)、これには一次論理誘導バイアスが含まれています】論理誘導バイアスを備えた言語表現の学習
GANLM:補助装備を使用したエンコーダーデコーダー事前トレーニング
【状態空間モデルに基づいた事前トレーニング言語モデル、注意なしでbertを超える】
[トレーニング前に人間のフィードバックを検討してください]人間の好みを持つ前の言語モデル
[MetaのオープンソースLlamaモデル、7B-65Bは、通常よりも小さなモデルとラベル付けされたより多くのラベルを訓練し、さまざまな推論予算の下で最適なパフォーマンスを達成します] llama:オープンで効率的な基礎言語モデル
[少数の例を使用して、大規模な言語モデルを自己非難し、生成されたコードを説明するために指導しますが、現在はこのように使用されています]大規模な言語モデルを自己debugに教える
ラクダは、オープンリソースの指示の状態をどのくらい探索できますか?
リマ:アライメントの方が多い
【前思想的、ますますalphagoのように、大規模な言語モデルでの意図的な問題解決
ICLを適用するためのマルチステップ推論方法は非常に刺激的です】反応:言語モデルでの相乗的推論と行動
COTはプログラムコードを直接生成し、Pythonインタープリターを実行することを可能にします。
[ビッグモデルは証拠のコンテキストを直接生成する]取得ではなく生成する:大きな言語モデルは強力なコンテキストジェネレーターです
come 4つの特定の操作を備えたライティングモデル】ピア:共同言語モデル
python、SQLエグゼクタ、ビッグモデルの結合
[ドキュメント生成コードを取得]ドキュメント:ドキュメントを取得してコードを生成する
[次のシリーズでは、接地+LLMに多くの記事があります] LLM-Planner:大規模な言語モデルを持つ具体化されたエージェントの少数の根拠のある計画
【自己認証(Pythonを使用して検証)トレーニングデータ
関連記事:多段階の推論に向けて小言語モデルを専門とする
STAR:Neurip 22(モデル微調整のためのCOTデータを生成する)からの推論によるブートストラップの推論、小さなモデルを教える一連のCOT記事を引き起こします。
同様のアイデア[知識の蒸留]小さな言語モデルを指導して、コンテキストを蒸留することによって理性と学習を教える
同様のアイデアKaistとXiang Ren Groups([Cotの理論的微調整(教授)]ピント:迅速な生成された理論的根拠などを使用した忠実な言語の推論)と大規模な言語モデルは、教師を推論しています
ETHの[COTデータトレーニング問題の分解と問題解決モデルを個別に訓練]セマンティック分解を介して、大規模な言語モデルのマルチステップ推論機能を小さなモデルに蒸留する
【コットの能力を学習させる小さなモデル】コンテキスト内学習蒸留:訓練を受けた言語モデルの少数の学習能力の転送
【大きなモデルは小さなモデルのコットをティーチします】大手言語モデルは教師を推論しています
[ビッグモデルは証拠を生成し(朗読)、小さなサンプルの閉店の質問と回答を実行します]朗読済み言語モデル
[帰納的推論の自然言語方法]誘導性の推論としての言語モデル
[GPT-3はデータアノテーションに使用されます(感情分類など)] GPT-3は優れたデータアノテーターですか?
destデータ増強のモデルマルチタスクトレーニングを減らすためのマルチタスクトレーニング増加】knowda:低リソースNLPでのデータ増強のためのオールインワンナレッジ混合モデル
【時代に興味がない手続き上の計画作業
[目的:大きなWebコーパスに接地することにより、クエリの事実上修正記事を生成する
contextコンテキストでの外部物理学シミュレーターの結果を組み合わせる】マインドの目:シミュレーションによる根拠のある言語モデルの推論
[知識を集中するためにコットを強化するタスクを取得する]知識集約的なマルチステップの質問のための考え方の推論を伴うインターリーブ検索
corpervisedされていない認識言語モデルにおける潜在的な(バイナリ)知識を対照的に監督なしで言語モデルの潜在的な知識を発見する
[Percy Liang Group、信頼できる検索エンジン、生成された文の51.5%のみが引用によって完全にサポートされています]生成検索エンジンの検証可能性を評価する
プログレッシブヒントプロンプトは、大規模な言語モデルの推論を改善します
人間の監督を最小限に抑えて、ゼロから言語モデルの原則主導型の自己整理
MTベンチとチャットボットアリーナでLLM-As-A-Judgeを判断します
[私の意見では、それは最も重要な記事の1つです。トレーニング、および幅と深さなどのアーキテクチャの詳細
[他の最も重要な記事の1つであるChinchillaは、限られたコンピューティングの下で、最適なモデルは最大のモデルではなく、より多くのデータでトレーニングされたより小さなモデル(60-70B))
[どのアーキテクチャと最適化の目標がゼロサンプルの一般化に役立ちます]ゼロショット一般化に最適な言語モデルのアーキテクチャと客観的な客観的な客観的な方法は何ですか?
【グローキング「エピファニー」学習プロセスの暗記 - >サーキットフォーメーション - >清掃
[検索ベースのモデルの特性を調査し、両方が限られた推論であることを発見します] Retriver-Augmented Languageモデルの理由
[Human-AI-AI-AI-Interaction Evateruation Framework] Human言語モデルの相互作用の評価
学習アルゴリズムは、インテキストモデルを使用して調査しますか?
モデル編集、これはホットトピックです】変圧器の大量編集メモリ
[無関係なコンテキストに対するモデルの感受性、プロンプトの例に無関係な情報を追加し、無関係なコンテキストを無視する指示を追加することは部分的に解決することは無関係な文脈によって簡単に気を散らすことができます
shoreゼロショットコットは、デリケートな問題の下でバイアスと毒性を示します
Big ModelのCotには言語間の機能があります】言語モデルは多言語の考え方の理由です
[異なるプロンプトシーケンスの混乱が低いほど、パフォーマンスが優れています]困惑の推定による言語モデルのプロンプトの分解プロンプト
[大規模なモデルのバイナリインプリティ解像度タスク、この提案は難しく、スケーリング現象はありません]大きな言語モデルはゼロショットコミュニケーターではありません(https://github.com/google/big-bench/tree/main/bigbench/ benchmark_tasks/ inflicity)
multimutionマルチステップの推論のための複雑さベースのプロンプト
生成言語モデルの構造化された剪定における何が重要ですか?
[Ambibench Dataset、Task Amviguity:スケーリングRLHFモデルは、曖昧性の除去に最適なパフォーマンスを発揮します。微調整は少数のショットプロンプトよりも役立ちます】人間と言語モデルのタスクのあいまいさ
memory、キャリブレーション、バイアスなどを含むGPT-3テスト。
[OSU研究COTのどの部分がパフォーマンスに効果的であるか]考え方の促しを理解するため:重要なことの経験的研究
[離散プロンプトの横断モデルに関する研究]離散情報抽出プロンプトは、言語モデル全体で一般化できますか?
memoryメモリレートは、トレーニングにおけるモデルサイズ、プレフィックスの長さ、および繰り返し速度との対数線形関係です】神経言語モデル全体の暗記の定量化
それは非常に刺激的で、問題をGPTイテレーションを通じてサブ質問に分解し、それに答えます。
[公務員の知性の質問と同様のGPT-3の類似テスト]大規模な言語モデルの緊急の類似の推論
【テキストの短いトレーニング、長いテキストテスト、モデル変数の長さの適応性の評価
[言語モデルを信頼しない場合:パラメトリックおよびノンパラメトリックの記憶の有効性と制限の調査
ICLは別の形式のグラデーションアップデートです。なぜGPTはコンテキスト内で勾配降下を実行できるのですか?
GPT-3は心理的な観点から大きな言語モデルを評価していますか?
[OPTモデルをさまざまなサイズでトレーニングするプロセスに関する研究で、混乱はICLの指標であることがわかりました]スケール全体の言語モデルの軌跡のトレーニング
[EMNLP 2022、事前に訓練された純粋な英語のコーパスには他の言語が含まれており、モデルの横断的機能はデータ漏れから生じる可能性があります]言語汚染は、英語の事前に守られたモデルの横断的能力を説明するのに役立ちます
[セマンティックプライアーをオーバーライドし、PROPTで情報を使用することはサージ能力です]大規模な言語モデルでは、文書内学習が異なります。
【EMNLP 2022調査結果spu 100万GPU時間がある場合、どの言語モデルをトレーニングするのですか?
[推論中にCFGテクノロジーを導入すると、小規模モデルの命令コンプライアンス能力が大幅に向上します]分類器のないガイダンスでトピックを維持する
openaiのGPT-4で独自のllamaモデルをトレーニングしてください。
反射:動的な記憶と自己反省を備えた自律剤
personalsedパーソナライズされたスタイルのプロンプト学習、OPT】言語モデルの拡張可能なプロンプトを選択します
[大規模なモデルデコードの加速、小さなモデルと大型モデルの間の直接コンセンサスを使用して、一度に複数回使用することを使用します。
[ソフトプロンプトを使用して、微調整、第1段階の微調整、第2段階の微調整によって引き起こされるICL機能の低下を減らします)
∎セマンティック解析タスク、ICL、コーデックス、T5-Largeのサンプル選択方法
textテキスト生成のための新しい最適化方法
[複数のサンプリング出力と組み合わせてセマンティッククラスタリングを使用してクラスターのエントロピーを推定する条件付き生成の不確実性推定]
ゴーチューニング:小言語モデルのゼロショット学習能力の向上
【無料のテキスト制約の下で非常に刺激的なテキスト生成方法
[予測を生成するときは、softmaxトークンの代わりに類似性を使用してフレーズを選択します]ノンパラメトリックマスク言語モデリング
[長いテキストのICLメソッド]並列コンテキストウィンドウは、大規模な言語モデルのコンテキスト学習を改善します
destly instructgptモデルのサンプル自体でICLを生成する】オープンドメインQAの自己促進大規模な言語モデル
cransferおよび注意メカニズムにより、ICLがより多くの注釈サンプルを入力できるようになります】構造化されたプロンプト:コンテキスト内学習を1,000の例に拡大する
テキスト生成の運動量キャリブレーション
coptおよびGPTJに基づく実験2つのICLサンプル選択方法
mauveの評価指標の分析(pillutla et al。)
PROMPTAGATOR:8つの例から少数の密な検索
[3人のコブラー、Zhuge Liang]自己整合性は、言語モデルの推論の連鎖を改善する
[入力、ラベルは、条件の指示を生成します]命令を推測します!
【LLMの逆派生自己検証】大規模な言語モデルは自己検証の理由です
【検索方法 - 証拠を生成するプロセスの下での安全シナリオ】フォベート、属性、および合理化:安全で信頼できるAIに向けて
[ビーム検索に基づいてテキスト生成情報によって抽出されたフラグメントの信頼推定]ビーム検索は、生成シーケンスラベル付けのスパンレベルの信頼推定をどのように改善しますか?
SPT:MultiTaskの迅速な学習の半パラメトリックプロンプトチューニング
extract抽出された要約に関する議論ゴールドラベル】オラクルの期待とのテキストの要約
【火星の距離に基づくOOD検出方法
[注意モジュールは、プロンプトを予測するプロンプトを統合するサンプルレベルを予測する]プロンプトフュージョンの代わりにモデルアンサンブル:少数のショットプロンプトチューニングのためのサンプル固有の知識転送方法
complus分解と1つのプロンプトへの蒸留による複数のタスクのプロンプ
[ステップバイステップの推論生成テキストの評価指標は、次回共有するトピックとして使用できます] Roscoe:Stap-by-Stepの推論を得るためのメトリックスイート
[シーケンスのキャリブレーションの可能性により、条件付き言語生成が改善されます]
gradium勾配最適化に基づくテキスト攻撃方法
[GMMモデリングICL決定分類境界を調整する境界]言語モデルの少数のショット学習のためのプロトタイプのキャリブレーション
【書き換えの問題、およびグラフベースのICL集約方法】言語モデルを促すための簡単な戦略
[発表されていないサンプルプールからのICLとして優れた候補者を選択するためのデータベース]選択的注釈は、言語モデルをより良い少数のショット学習者にします
プロンプトブースト:10回のフォワードパスによるブラックボックステキスト分類
トランスに対する注意誘導のバックドア攻撃
【プロンプトマスク位置自動ラベルの選択
[FID入力ベクトルの長さを圧縮し、出力ドキュメントランキングに出力するときにそれを並べ替えます。
【大規模モデルの生成に関する説明】ピント:迅速な生成された理論的根拠を使用した忠実な言語推論
prepraining前の影響のサブセットを見つける】ORCA:事前トレーニングデータの海での証拠をサポートする場所を介して促された言語モデルの解釈
[指導を目的としたプロジェクトのプロジェクトは、第一段階と2段階のソートフィルタリングを生成します]大規模な言語モデルは人間レベルの迅速なエンジニアです
言語モデルのプライバシーリスクを緩和するための知識の学習
タスク算術を使用したモデルの編集
[毎回手順やサンプルを入力しないで、パラメーター効率の高いモジュールに変換しないでください。]ヒント:効率的なゼロショット一般化のためにハイパーネットワーク命令チューニング
[手動サンプルの選択なしのICLディスプレイ生成方法] Z-ICL:擬似デモンストレーションを使用したゼロショットコンテキスト内学習
[タスク命令とテキストが一緒に埋め込みを生成します] 1つの埋め込み、任意のタスク:命令finetunedテキスト埋め込み
bigモデルを教える小さなモデルコット】ナイフ:自由テキストの理論的根拠を備えた知識の蒸留
[ソースとターゲットの間の矛盾の問題情報抽出生成モデルのセグメンテーション]抽出NLPタスク上の生成モデルのトークン化一貫性
Parsel:アルゴリズム推論のための統一された自然言語の枠組み
[ICLサンプルの選択、第一位の選択、および第2位のソート]自己適応性内文化学習
[集中的な読書、読み取り可能なプロンプト監視なしの選択方法、GPT-2]人間の読み取り可能なプロンプトチューニングに向けて:Kubrick's The Shiningは良い映画であり、良いプロンプトでもあります
prontoqaデータセットテストCOT推論能力をテストし、計画能力がまだ限られていることを発見します】言語モデルは(ある種の)理由:考え方の体系的な正式な分析
【推論データセット】wikiwhy:因果関係の質問に答えて説明します
【推論データセット】通り:マルチタスク構造化された推論と説明ベンチマーク
cotコット微調整モデルを含むオプトプレトレーニングと微調整の比較データセットの推論】アラート:言語モデルを推論タスクに適合させる
[Zhijiang UniversityのZhang Ningyuチームによる最近の推論の要約]言語モデルのプロンプトとの推論:調査
[FudanのXiao Yanghuaのチームによるテキスト生成技術と方向の概要]人間のような自然言語生成の知識と推論を活用する:簡単なレビュー
[最近の推論記事の要約、UIUCのJie Huang]大規模な言語モデルの推論に向けて:調査
【数学的推論とDLのタスク、データセット、方法のレビュー】数学的推論のための深い学習の調査
プログラミングのための自然言語処理に関する調査
報酬モデリングデータセット:
Red-teaming数据集,harmless vs. helpful, RLHF +scale更难被攻击(另一个有效的技术是CoT fine-tuning):
【知识】+【推理】+【生成】
如果对您有帮助,请star支持一下,欢迎Pull Request~
主观整理,时间上主要从ICLR 2023 Rebuttal期间开始的,包括ICLR,ACL,ICML等预印版论文。
不妥之处或者建议请指正! Dongfang Li, [email protected]


