langroid
0.24.0
Langroid 、CMUおよびUW-Madisonの研究者からLLMを搭載したアプリケーションを簡単に構築するための直感的で軽量で拡張可能なPythonフレームワークです。エージェントをセットアップし、オプションのコンポーネント(LLM、ベクトルストア、ツール/関数)を装備し、タスクを割り当て、メッセージを交換して問題を共同で解決させます。このマルチエージェントパラダイムは、俳優のフレームワークに触発されています(ただし、これについて何も知る必要はありません!)。
Langroidは、LLMアプリ開発の新たなテイクであり、開発者エクスペリエンスを簡素化することにかなりの考えがあります。 Langchain 、またはその他のLLMフレームワークは使用しません。
Langroidアーキテクチャの(WIP)概要をお読みください
?企業は、生産にLangroidを使用/適応させています。これが引用です:
Nullifyは、安全なソフトウェア開発にAIエージェントを使用します。脆弱性を見つけ、優先順位付け、修正します。 Crewai、Autogen、Langchain、Langflowなどを評価した後、生産におけるLangroidのマルチエージェントオーケストレーションフレームワークを内部的に適合させました。Langroidは、セットアップと柔軟性の容易さの点でそれらのフレームワークよりもはるかに優れていることがわかりました。 Langroidのエージェントとタスクの抽象化は直感的でよく考えられており、優れた開発者エクスペリエンスを提供します。私たちは、生産で何かを得るための最も迅速な方法を望んでいました。他のフレームワークでは数週間かかりましたが、Langroidでは数分で良い結果を得ました。強くお勧めします!
-NullifyのAIの責任者であるJacky Wong。
LancedBチームからのLangroidブログ投稿のこのイントロを参照してください
ML for Healthcare(2024)に掲載されたばかり:薬物学生用のLangroidベースのマルチエージェントRAGシステム、ブログ投稿を参照してください
貢献を歓迎します。何を貢献するかについてのアイデアについては、貢献ドキュメントを参照してください。
LLMアプリケーションを構築していますか、それとも会社のLangroidのヘルプが必要ですか、それとも会社のユースケースにLangroid機能を優先したいですか? Prasad Chalasaniは、コンサルティング(アドバイザリー/開発):Gmail Dot comのPchalasaniです。
スポンサーシップは、Githubスポンサーを介して受け入れられます
質問、フィードバック、アイデア? Discordに参加してください!
これは単なるティーザーです。関数呼び出し/ツール、マルチエージェントコラボレーション、構造化された情報抽出、Docchatagent(RAG)、SQLChatagent、非Openai Local/Remote LLMSなど、さらに多くのことがあります。スクロールダウンまたはドキュメントを参照してください。 OpenAI ChatCompletion APIを使用して、2エージェントの情報抽出例を構築するLangroidクイックスタートコラブを参照してください。代わりにOpenaiアシスタントAPIを使用するこのバージョンも参照してください。
リリースされたばかり!ラングロイドマルチエージェントとツールを使用して、ローカルLLMのみを使用してドキュメントから構造化された情報を抽出する方法を示す例の例。
import langroid as lr
import langroid . language_models as lm
# set up LLM
llm_cfg = lm . OpenAIGPTConfig ( # or OpenAIAssistant to use Assistant API
# any model served via an OpenAI-compatible API
chat_model = lm . OpenAIChatModel . GPT4o , # or, e.g., "ollama/mistral"
)
# use LLM directly
mdl = lm . OpenAIGPT ( llm_cfg )
response = mdl . chat ( "What is the capital of Ontario?" , max_tokens = 10 )
# use LLM in an Agent
agent_cfg = lr . ChatAgentConfig ( llm = llm_cfg )
agent = lr . ChatAgent ( agent_cfg )
agent . llm_response ( "What is the capital of China?" )
response = agent . llm_response ( "And India?" ) # maintains conversation state
# wrap Agent in a Task to run interactive loop with user (or other agents)
task = lr . Task ( agent , name = "Bot" , system_message = "You are a helpful assistant" )
task . run ( "Hello" ) # kick off with user saying "Hello"
# 2-Agent chat loop: Teacher Agent asks questions to Student Agent
teacher_agent = lr . ChatAgent ( agent_cfg )
teacher_task = lr . Task (
teacher_agent , name = "Teacher" ,
system_message = """
Ask your student concise numbers questions, and give feedback.
Start with a question.
"""
)
student_agent = lr . ChatAgent ( agent_cfg )
student_task = lr . Task (
student_agent , name = "Student" ,
system_message = "Concisely answer the teacher's questions." ,
single_round = True ,
)
teacher_task . add_sub_task ( student_task )
teacher_task . run ()2024年11月:
Agent Sのサポートを有効にします。Qwen2.5-Coder-32b-Instruct )2024年10月:
2024年9月:
o1-miniおよびo1-previewモデルのサポート。DocChatAgent 、相互ランク融合(RRF)を使用して、さまざまな方法で取得したランクのチャンクをランク付けします。run_batch_task新しいオプションstop_on_first_resultタスクが結果を返すとすぐにバッチの終了を許可します。2024年8月:
Task.run(), Task.run_async 。2024年7月:
2024年6月:
RewindTool (そして、すべての依存メッセージが系統の追跡のおかげでクリアされます)。ここでメモを読んでください。2024年5月:
doc-chat 、 db (データベース関連の依存関係)。以下およびドキュメント内の更新されたインストール手順を参照してください。examplesという名前のクラスメソッドを含めることができました。このリストのランダムな例を使用して、LLMの1ショット例を生成します。これが改善されたため、各例がツールインスタンスまたは(説明、ツールインスタンス)のタプルである例のリストを提供できるようになりました。説明は、LLMにツールを使用する「思考」です(ドキュメントの例を参照)。いくつかのシナリオでは、LLMツールの生成の精度を向上させることができます。また、ランダムな例の代わりに、すべての例を使用して、少数のショット例を生成します。TaskConfigで構成可能。エンティティが本質的に類似している(ただしまったく同じではない)ことを繰り返し言っている近似ループではなく、正確なループのみを検出します。RecipientToolメカニズムに代わるより簡単な代替です(これが重要なシナリオで)。DocChatAgentを使用する場合、大いに改善された引用生成と表示。gpt-4oは、全体を通してデフォルトのLLMになりました。このLLMで動作するテストと例を更新します。 LLMに対応するトークン剤を使用します。gemini 1.5 pro litellm経由のProサポートQdrantDB:学習したスパース埋め込みをサポートするための更新。2024年4月:
chat_model="groq/llama3-8b-8192"を指定します。チュートリアルを参照してください。Task.run(), Task.run_async(), run_batch_tasksはmax_costおよびmax_tokensパラメーションがあり、トークンまたはコストが制限を超えると終了します。結果ChatDocument.metadataには、タスク完了理由コードを示すコードであるstatusフィールドが含まれるようになりました。また、 task.run()などは、Redisキャッシュのさまざまな設定を検索するためのキーとして使用される明示的なsession_idフィールドで呼び出すことができます。現在、「キルステータス」を検索するためにのみ使用されます。これにより、 task.kill()またはclassmethod Task.kill_session(session_id)のいずれかで実行されるタスクを殺すことができます。たとえば、Test_task_killのtest_task_kill /main/test_task.pyを参照してください2024年3月:
DocChatAgentの同時実行を可能にするための改善、 test_doc_chat_agent.pyを参照してください。特にtest_doc_chat_batch() ;新しいタスク実行ユーティリティ: run_batch_task_genタスクジェネレーターを指定できる場所で、入力ごとに1つのタスクを生成します。DocChatAgent Image-PDFSで動作することを意味します)。DocChatAgent Context-Window修正URLLoader :URLが.pdf 、 .docxなどの認識可能なサフィックスで終了しない場合、ヘッダーからファイル時間を検出します。sentence_transformerモジュールが利用可能かどうかに基づいて、自動選択埋め込み構成。sentence-transformers依存関係、いくつmkdocs haystack重いunstructured chromadbオプションhuggingface-hubします。import langroid as lrからのより簡単なトップレベルのインポート2024年2月:
chat_model="ollama/mistral"を指定します。リリースノートを参照してください。2024年1月:
SQLChatAgent仕組みに類似)。このエージェントを使用したスクリプトの例を参照して、Python PKG依存関係に関する質問に答えてください。.docファイルの解析のサポート( .docxに加えて)OpenAIGPTConfigでオプションのformatter Paramを指定して、ローカルLLMの正確なチャットフォーマットを確保します。DocChatAgentConfig 、 contentフィールドに挿入する追加のドキュメントフィールドを指定して、検索を改善するための新しいparam: add_fields_to_contentがあります。2023年12月:
DocChatAgent :Pandasデータフレームとフィルタリングを摂取します。LanceDocChatAgent 、効率的なベクター検索とフルテキスト検索とフィルタリングのためにLanceDB Vector-DBを活用します。LanceRAGTaskCreator 、ラグエージェントに送信するフィルターと言い換えのクエリを決定するLanceFilterAgentで構成される2エージェントシステムを作成します。ChatAgentを使用したよりシンプルなTask初期化。2023年11月:
0.1.126: OpenAisistant Agent:キャッシュサポート。
0.1.117: OpenAIアシスタントAPIツールのサポート:関数-Calling、Code-Intepreter、およびRetriver(RAG)、ファイルアップロード。これらは、Langroidのタスクと再構成とシームレスに機能します。ドキュメントが準備が整うまで、これらの使用例を確認するのが最善です。
テスト:
例:スクリプト:
0.1.112: OpenAIAssistant 、新しいOpenaiアシスタントAPIを活用するChatAgentのサブクラスです。 ChatAgentのドロップイン交換として使用でき、アシスタントAPIに依存して会話状態を維持することができ、必要に応じて永続的なスレッドとアシスタントをレバレッジして再接続します。例: test_openai_assistant.py 、 test_openai_assistant_async.py
0.1.111:最新のOpenAIモデルをサポート: GPT4_TURBO (例えば使用法などを参照)
0.1.110: Openai v0.xからv1.1.1へのアップグレード(アシスタントAPIなどの準備中)。 (Openaiバージョンの競合により、 litellm一時的に無効になっています)。
2023年10月:
DocChatAgent再ランカー: rank_with_diversity 、 rank_to_periphery (lost in middle)。DocChatAgentConfig.n_neighbor_chunks > 0使用すると、コンテキストチャンクを試合中に返すことができます。DocChatAgent 、 RelevanceExtractorAgentを使用してLLM抽出物に文のンジャリングを使用してチャンクの関連部分を抽出し、 LangChainでラングLLMChainExtractorを使用する素朴な「文化パロージング」アプローチ(関連する全体的な文章を書き出す)と比較して、巨大なスピードアップとコスト削減をもたらします。import langroid as lrことでアクセスできます。使用法のドキュメントを参照してください。2023年9月:
docxファイルのロードのサポート(予備)。SQLChatAgent改善。2023年8月:
GoogleSearchTool 、エージェント(LLM)が機能コール/ツールを介してGoogle検索を行うことを可能にします。このツールをエージェントに追加するのがどれほど簡単かについては、このチャットの例を参照してください。SQLChatAgentを追加 - 最新の貢献者Rithwik Babuのおかげです!2023年7月:
TableChatAgentを追加して表現するようにTabular Datasets(データフレーム、ファイル、URLS)とチャット:LLMはPandasコードを生成し、Langroidのツール/機能コールメカニズムを使用してコードが実行されます。DocChatAgent PDFファイルまたはURLを受け入れるようになりました。商業リース文書の主要な条件に関する構造化された情報を抽出したいとします。 Langroid-Examplesリポジトリで表示されるように、2エージェントシステムを使用してLangroidで簡単にこれを行うことができます。 (ローカルMistral-7Bモデルを使用して同じ機能を持つバージョンについては、このスクリプトを参照してください。)デモは、次のようなLangroidの多くの機能のいくつかを紹介します。
LeaseExtractorはタスクを担当し、そのLLM(GPT4)は、 DocAgentが回答する質問を生成します。DocAgent LLM(GPT4)は、ベクターストアから検索を使用してLeaseExtractorの質問に答え、答えをサポートする特定の抜粋を引用します。LeaseExtractor LLMは、関数コールを使用して構造化された形式で情報を提示します。これが動作中のものです(一時停止可能なMP4ビデオはこちらです)。
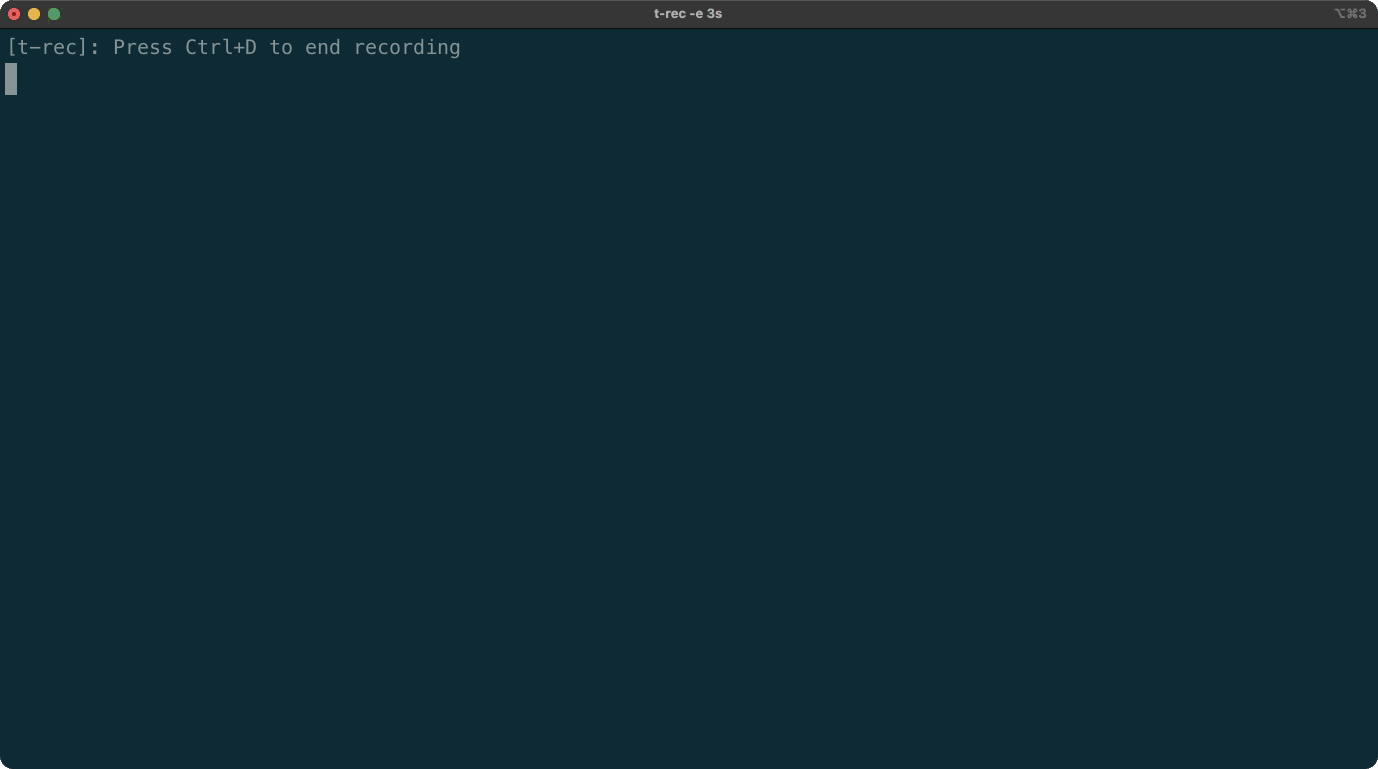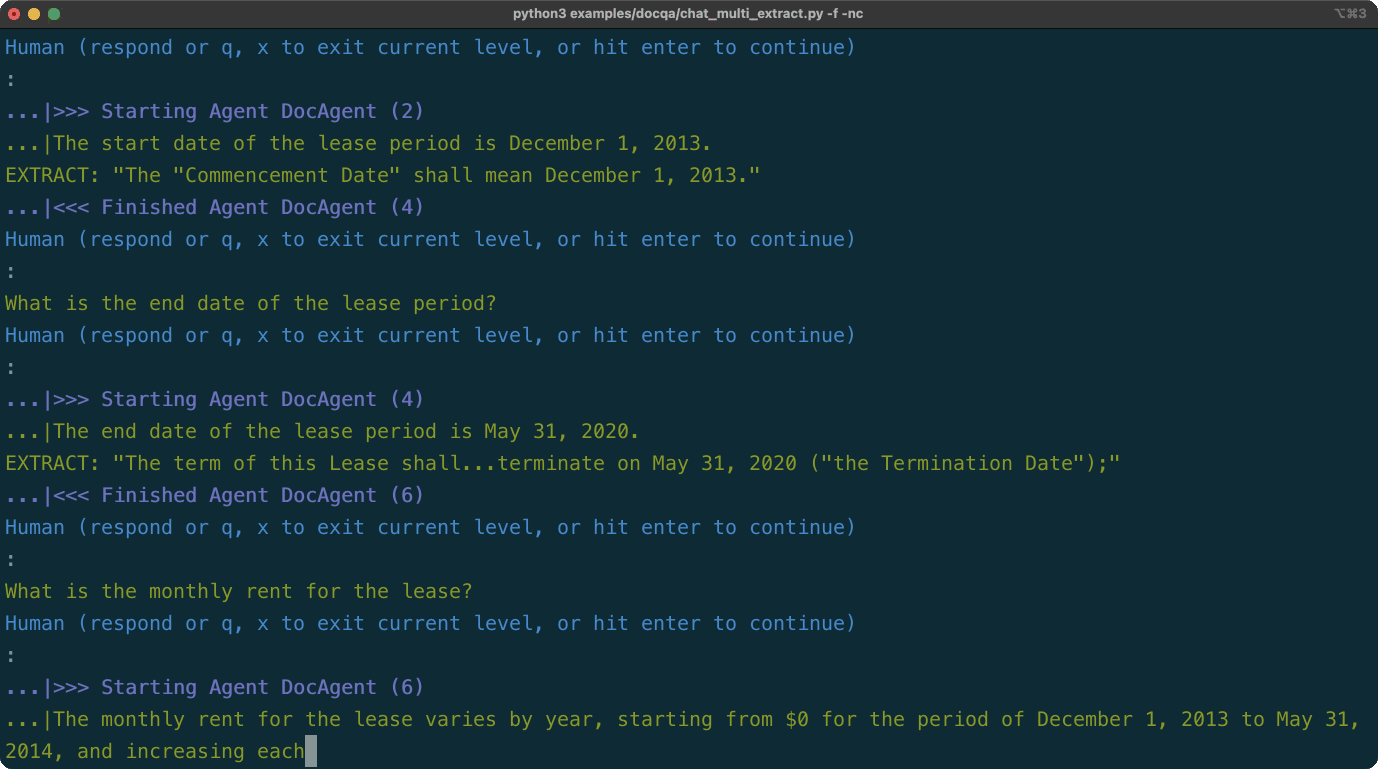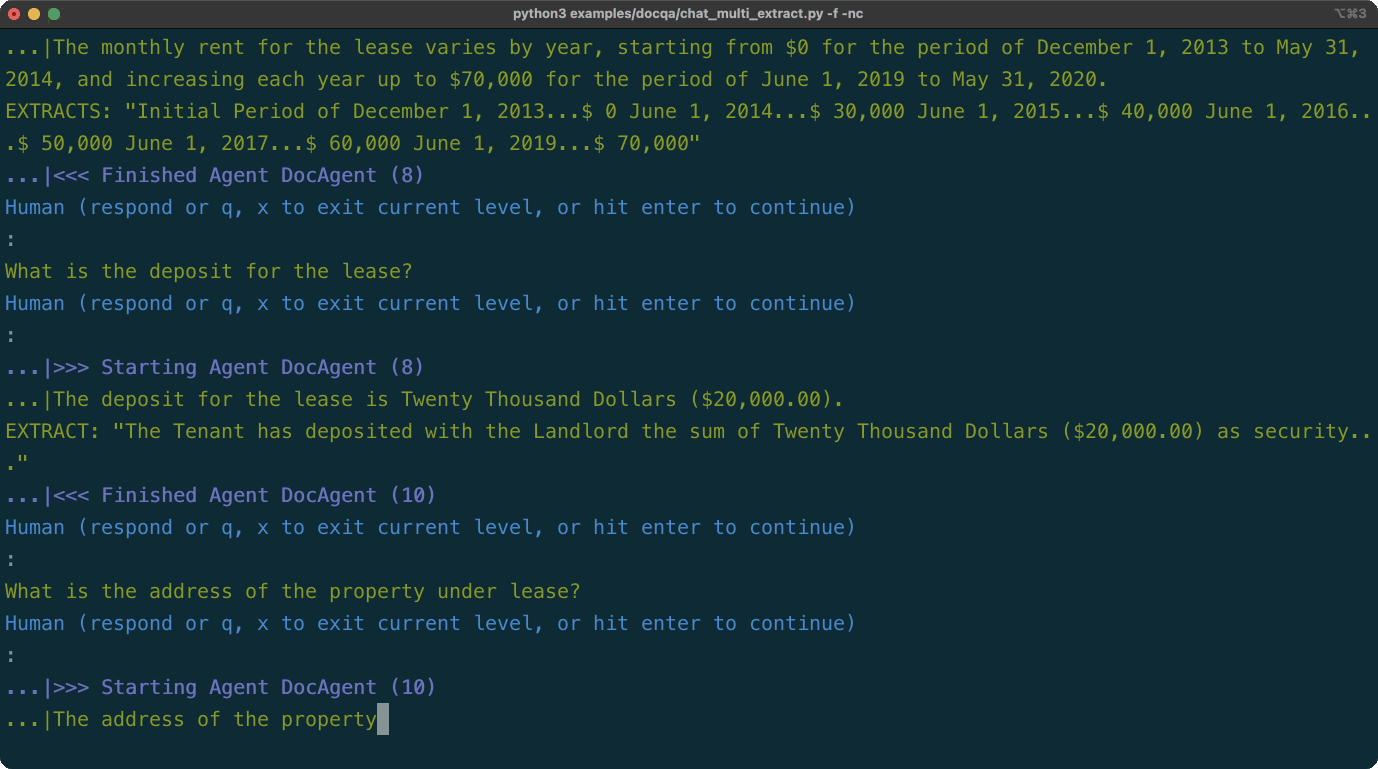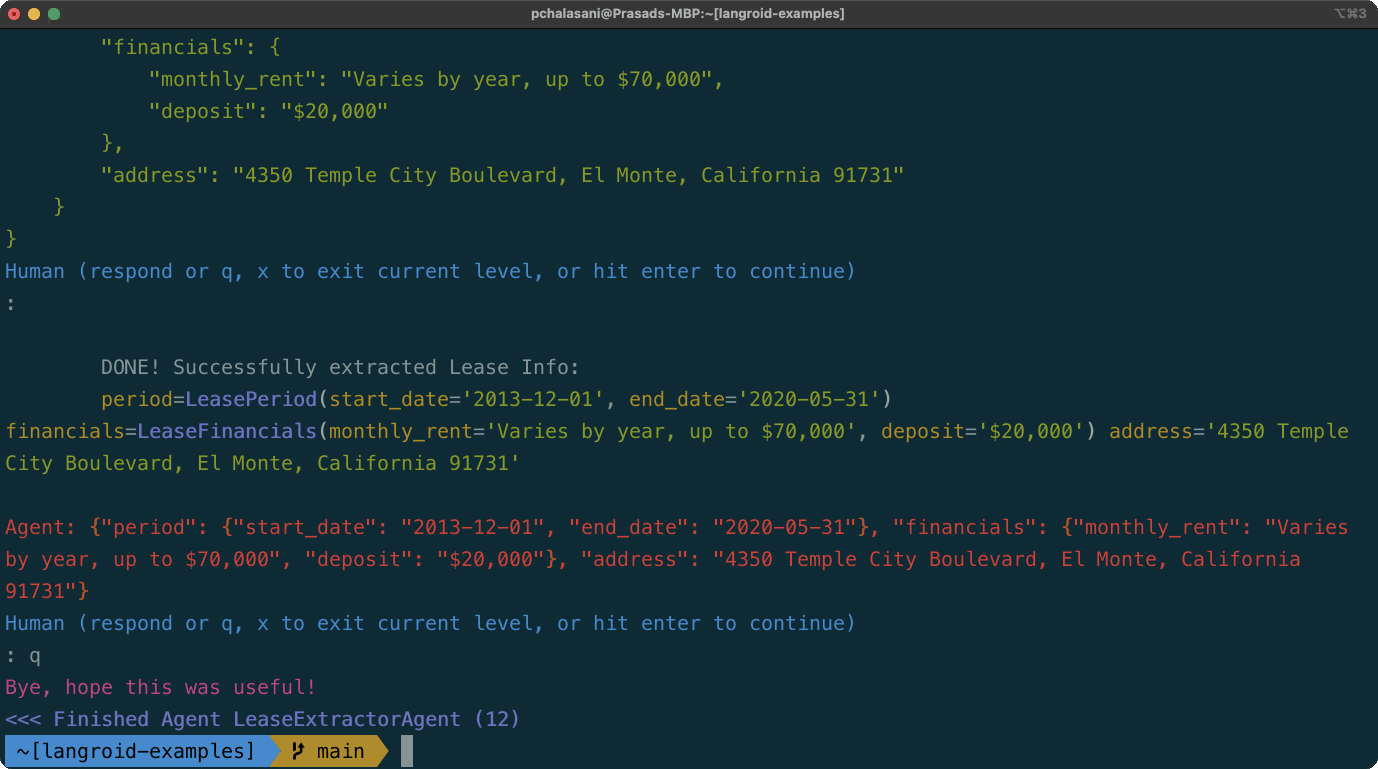
(最新のリストについては、上記の更新/リリースセクションを参照してください)
Task.run()メソッドはエージェントのレスポンダーのメソッドと同じタイプシグネチャーを持っています。これは、エージェントのタスクが他のサブタスクに委任する方法の鍵です。タスクの観点から、サブタスクは単に追加のレスポンダーであり、エージェント自身のレスポンダーの後にラウンドロビンファッションで使用されます。AgentとTask抽象化により、ユーザーは特定のスキルを備えたエージェントを設計し、タスクにラップし、タスクを柔軟な方法で組み合わせることができます。ToolMessageメカニズムをサポートします。関数呼び出しとツールには、Pydanticを使用して実装された同じ開発者向けインターフェイスがあり、ツール/機能を簡単に定義し、エージェントがそれらを使用できるようになります。 Pydanticを使用することの利点は、関数呼び出しのために複雑なJSON仕様を書く必要がないことであり、LLMが奇形のJSONを幻覚すると、PydanticエラーメッセージがLLMに送信され、修正できます。langroidをインストールしますLangroidにはPython 3.11+が必要です。仮想環境を使用することをお勧めします。 pipを使用して、 langroid (Pypiから)のベアボーンスリムバージョンを仮想環境にインストールします。
pip install langroid Core Langroidパッケージを使用すると、APIを介してOpenai Embeddingsモデルを使用できます。代わりに、Huggingfaceからモデルを埋め込むsentence-transformersを使用する場合は、次のようにLangroidをインストールします。
pip install " langroid[hf-embeddings] "多くの実用的なシナリオでは、追加のオプションの依存関係が必要になる場合があります。
doc-chat extraでlangroidをインストールします。 pip install " langroid[doc-chat] "db Extraを使用してください。 pip install " langroid[db] "
` `pip install " langroid[doc-chat,db] "all追加を使用します(ただし、これにより、ロード/起動時間が長くなり、インストールサイズが大きくなることに注意してください): pip install " langroid[all] "SQLChatAgent (たとえば、スクリプトのexamples/data-qa/sql-chat/sql_chat.py )を使用している場合、postgres dbを使用して、次のことが必要です。
sudo apt-get install libpq-dev on ubuntu、brew install postgresqlpip install langroid[postgres] poetry add langroid[postgres]またはpoetry install -E postgresを追加します。これによりエラーが発生した場合は、virtualenvにpip install psycopg2-binaryみてください。 mysqlclient含む奇妙なエラーが発生した場合は、 pip uninstall mysqlclientを実行してからpip install mysqlclient試してみてください。
開始するには、必要なのはOpenai APIキーだけです。持っていない場合は、このOpenAIページをご覧ください。 (これは開始する最も簡単な方法ですが、LangroidはOpenaiのものだけでなく、実質的にあらゆるLLMを使用します。Open/Local LLMS、およびその他の非Openai Proprietary LLMを使用するガイドをご覧ください。)
リポジトリのルートで、 .env-templateファイルを新しいファイルにコピーします.env
cp .env-template .env次に、OpenAI APIキーを挿入します。 .envファイルは次のように見えるはずです(組織はオプションですが、一部のシナリオでは必要になる場合があります)。
OPENAI_API_KEY=your-key-here-without-quotes
OPENAI_ORGANIZATION=optionally-your-organization-idまたは、これをシェル内の環境変数として設定することもできます(新しいシェルを開くたびにこれを行う必要があります):
export OPENAI_API_KEY=your-key-here-without-quotes次のすべての環境変数設定はオプションであり、一部は特定の機能を使用するためにのみ必要です(以下のように)。
MOMENTO_AUTH_TOKENの値として、 .envファイルにMomentoトークンを入力します(以下の例を参照)、.envファイルでCACHE_TYPE=momento ( CACHE_TYPE=redisの代わりにデフォルト)。GoogleSearchToolを使用できるようにするためにのみ必要です。 Google SearchをLLMツール/プラグイン/機能コールとして使用するには、Google APIキーを設定し、Googleカスタム検索エンジン(CSE)をセットアップしてCSE IDを取得する必要があります。 (これらのドキュメントは困難な場合があります。GPT4にステップバイステップガイドを求めることをお勧めします。)これらの資格情報を取得した後、 .envファイルにGOOGLE_API_KEYおよびGOOGLE_CSE_IDの値として保存します。これを使用することに関する完全なドキュメント(およびそのような「ステートレス」ツール)はまもなく登場しますが、その間にこのチャットの例を覗いてみてください。これは、エージェントにGoogleSearchtoolを簡単に装備する方法を示しています。これらのオプション変数をすべて追加すると、 .envファイルは次のようになります。
OPENAI_API_KEY=your-key-here-without-quotes
GITHUB_ACCESS_TOKEN=your-personal-access-token-no-quotes
CACHE_TYPE=redis # or momento
REDIS_PASSWORD=your-redis-password-no-quotes
REDIS_HOST=your-redis-hostname-no-quotes
REDIS_PORT=your-redis-port-no-quotes
MOMENTO_AUTH_TOKEN=your-momento-token-no-quotes # instead of REDIS* variables
QDRANT_API_KEY=your-key
QDRANT_API_URL=https://your.url.here:6333 # note port number must be included
GOOGLE_API_KEY=your-key
GOOGLE_CSE_ID=your-cse-id Azure Openaiを使用する場合、 .envファイルに追加の環境変数が必要です。このページMicrosoft Azure Openaiはより多くの情報を提供し、次のように各環境変数を設定できます。
AZURE_OPENAI_API_KEY 、 API_KEYの値からAZURE_OPENAI_API_BASE ENDPOINTの値から、通常はhttps://your.domain.azure.comのように見えます。AZURE_OPENAI_API_VERSIONの場合、デフォルト値を.env-templateで使用でき、最新バージョンはこちらにあります。AZURE_OPENAI_DEPLOYMENT_NAMEは展開モデルの名前であり、モデルのセットアップ中にユーザーによって定義されますAZURE_OPENAI_MODEL_NAME azure openaiは、展開のモデルを選択する際に特定のモデル名を許可します。選択された正確なモデル名を正確に配置する必要があります。たとえば、GPT-4( gpt-4-32kまたはgpt-4である必要があります)。AZURE_OPENAI_MODEL_VERSIONが必要ですAZURE_OPENAI_MODEL_NAME = gpt=4では、ラングロイドがモデルのコストを決定するのを支援しますこのDocker画像を介してlangroid-examplesリポジトリのコンテナ化バージョンを提供します。必要なのは、 .envファイルに環境変数をセットアップすることです。コンテナをセットアップするには、次の手順に従ってください。
# get the .env file template from `langroid` repo
wget -O .env https://raw.githubusercontent.com/langroid/langroid/main/.env-template
# Edit the .env file with your favorite editor (here nano), and remove any un-used settings. E.g. there are "dummy" values like "your-redis-port" etc -- if you are not using them, you MUST remove them.
nano .env
# launch the container
docker run -it --rm -v ./.env:/langroid/.env langroid/langroid
# Use this command to run any of the scripts in the `examples` directory
python examples/ < Path/To/Example.py > これらは、Langroidで何ができるか、コードがどのように見えるかを垣間見るための迅速なティーザーです。
langroid-examplesリポジトリを参照することをお勧めします。
LangroidのさまざまなLLMプロンプトと指示は、GPT-4(およびある程度GPT-4O)でうまく機能するようにテストされています。他のLLMS(ローカル/オープンおよび専有)への切り替えは簡単で(上記のガイドを参照)、一部のアプリケーションでは十分かもしれませんが、一般的には、プロンプトやマルチエージェントのセットアップを調整しない限り劣った結果が表示される場合があります。
詳細なチュートリアルについてはGetting Started Guideも参照してください。
クリックして、以下のコード例を展開します。これらはすべて、コラブノートブックで実行できます。
import langroid . language_models as lm
mdl = lm . OpenAIGPT ()
messages = [
lm . LLMMessage ( content = "You are a helpful assistant" , role = lm . Role . SYSTEM ),
lm . LLMMessage ( content = "What is the capital of Ontario?" , role = lm . Role . USER ),
]
response = mdl . chat ( messages , max_tokens = 200 )
print ( response . message ) cfg = lm . OpenAIGPTConfig (
chat_model = "local/localhost:8000" ,
chat_context_length = 4096
)
mdl = lm . OpenAIGPT ( cfg )
# now interact with it as above, or create an Agent + Task as shown below.モデルがliteLLMによってサポートされている場合、プロキシサーバーを起動する必要はありません。上記のchat_model paramをlitellm/anthropic/claude-instant-1 litellm/[provider]/[model]に設定するだけです。 litellm使用するには、 litellm Extra: poetry install -E litellmまたはpip install langroid[litellm]をインストールする必要があることに注意してください。リモートモデルの場合、通常、APIキーなどを環境変数として設定する必要があります。 Litellmドキュメントに基づいてそれらを設定できます。必要な環境変数が欠落している場合、Langroidは、どの環境が必要かを示す役立つエラーメッセージを提供します。 litellmを使用してlangroidを使用するには、 litellm Extra、つまり仮想envにpip install langroid[litellm]か、 langroid Repo内で開発している場合は、 poetry install -E litellm必要があります。
pip install langroid[litellm] import langroid as lr
agent = lr . ChatAgent ()
# get response from agent's LLM, and put this in an interactive loop...
# answer = agent.llm_response("What is the capital of Ontario?")
# ... OR instead, set up a task (which has a built-in loop) and run it
task = lr . Task ( agent , name = "Bot" )
task . run () # ... a loop seeking response from LLM or User at each turnNumber Number nを与えられた場合、おもちゃ番号ゲーム:
repeater_taskのLLMは単にnを返します、even_taskのLLMはn/2均等に返しますnodd_taskのLLMは、 nが奇妙な場合は3*n+1を返します。これらのTaskはそれぞれ、デフォルトのChatAgentを自動的に構成します。
import langroid as lr
from langroid . utils . constants import NO_ANSWER
repeater_task = lr . Task (
name = "Repeater" ,
system_message = """
Your job is to repeat whatever number you receive.
""" ,
llm_delegate = True , # LLM takes charge of task
single_round = False ,
)
even_task = lr . Task (
name = "EvenHandler" ,
system_message = f"""
You will be given a number.
If it is even, divide by 2 and say the result, nothing else.
If it is odd, say { NO_ANSWER }
""" ,
single_round = True , # task done after 1 step() with valid response
)
odd_task = lr . Task (
name = "OddHandler" ,
system_message = f"""
You will be given a number n.
If it is odd, return (n*3+1), say nothing else.
If it is even, say { NO_ANSWER }
""" ,
single_round = True , # task done after 1 step() with valid response
)次に、 repeater_taskのサブタスクとしてeven_taskとodd_taskを追加し、 repeater_taskを実行し、入力として数字で蹴ります。
repeater_task . add_sub_task ([ even_task , odd_task ])
repeater_task . run ( "3" )LangroidはPydanticを活用して、Openaiの機能を呼び出すAPIと独自のネイティブツールをサポートします。利点は、スキーマを指定するためにJSONを記述する必要がないこと、およびLLMが奇形のツール構文を幻覚する場合、LangroidはPydantic Validationエラー(適切に消毒された)をLLMに送信して修正できます!
簡単な例:エージェントに数字の秘密リストがあり、LLMにリスト内の最小の数字を見つけてほしいとします。 LLMに、単一の数値n引数として取得するprobeツール/関数を提供したいと考えています。エージェントのツールハンドラーメソッドは、リスト内の数値の数がせいぜいnであるかどうかを返します。
LangroidのToolMessageクラスを使用して、最初にツールを定義します。
import langroid as lr
class ProbeTool ( lr . agent . ToolMessage ):
request : str = "probe" # specifies which agent method handles this tool
purpose : str = """
To find how many numbers in my list are less than or equal to
the <number> you specify.
""" # description used to instruct the LLM on when/how to use the tool
number : int # required argument to the tool次に、このツールを処理するメソッドprobeを使用して、 SpyGameAgent ChatAgentのサブクラスとして定義します。
class SpyGameAgent ( lr . ChatAgent ):
def __init__ ( self , config : lr . ChatAgentConfig ):
super (). __init__ ( config )
self . numbers = [ 3 , 4 , 8 , 11 , 15 , 25 , 40 , 80 , 90 ]
def probe ( self , msg : ProbeTool ) -> str :
# return how many numbers in self.numbers are less or equal to msg.number
return str ( len ([ n for n in self . numbers if n <= msg . number ]))次に、エージェントをインスタンス化し、ツールを使用して応答できるようにします。
spy_game_agent = SpyGameAgent (
lr . ChatAgentConfig (
name = "Spy" ,
vecdb = None ,
use_tools = False , # don't use Langroid native tool
use_functions_api = True , # use OpenAI function-call API
)
)
spy_game_agent . enable_message ( ProbeTool )完全な例についてはlangroid-examples RepoのChat-Agent-tool.pyスクリプトを参照してください。
エージェントがネストされたJSON構造として、リース文書からリースの主要な条件を抽出したいとします。最初に、Pydanticモデルを介して目的の構造を定義します。
from pydantic import BaseModel
class LeasePeriod ( BaseModel ):
start_date : str
end_date : str
class LeaseFinancials ( BaseModel ):
monthly_rent : str
deposit : str
class Lease ( BaseModel ):
period : LeasePeriod
financials : LeaseFinancials
address : str次に、LangroidのToolMessageのサブクラスとしてLeaseMessageツールを定義します。注ツールには、タイプLeaseの必要な引数termsがあります。
import langroid as lr
class LeaseMessage ( lr . agent . ToolMessage ):
request : str = "lease_info"
purpose : str = """
Collect information about a Commercial Lease.
"""
terms : Lease次に、このツールを処理するメソッドlease_infoを使用してLeaseExtractorAgent定義し、エージェントをインスタンス化し、このツールを使用および応答できるようにします。
class LeaseExtractorAgent ( lr . ChatAgent ):
def lease_info ( self , message : LeaseMessage ) -> str :
print (
f"""
DONE! Successfully extracted Lease Info:
{ message . terms }
"""
)
return json . dumps ( message . terms . dict ())
lease_extractor_agent = LeaseExtractorAgent ()
lease_extractor_agent . enable_message ( LeaseMessage ) langroid-examplesリポジトリのchat_multi_extract.pyスクリプトを参照してください。
Langroidは、この目的のために専門的なエージェントクラスのDocChatAgentを提供します。ドキュメントシャード、埋め込み、ベクトル-DBでのストレージ、および検索されたクエリ回答生成が組み込まれています。このクラスを使用してドキュメントのコレクションとチャットするのは簡単です。最初に、チャットするドキュメントを指定するdoc_pathsフィールドを使用して、 DocChatAgentConfigインスタンスを作成します。
import langroid as lr
from langroid . agent . special import DocChatAgentConfig , DocChatAgent
config = DocChatAgentConfig (
doc_paths = [
"https://en.wikipedia.org/wiki/Language_model" ,
"https://en.wikipedia.org/wiki/N-gram_language_model" ,
"/path/to/my/notes-on-language-models.txt" ,
],
vecdb = lr . vector_store . QdrantDBConfig (),
)次に、 DocChatAgentをインスタンス化します(これにより、ドキュメントをベクターストアに摂取します):
agent = DocChatAgent ( config )その後、エージェントに1回限りの質問をすることができます。
agent . llm_response ( "What is a language model?" )または、 Taskにラップして、ユーザーとインタラクティブループを実行します。
task = lr . Task ( agent )
task . run () langroid-examples Repoのdocqaフォルダーの完全な作業スクリプトを参照してください。
Langroidを使用して、データセット(ファイルパス、URL、またはデータフレーム)を備えたTableChatAgentセットアップして照会できます。エージェントのLLMは、関数コール(またはツール/プラグイン)を介してクエリに回答するためにPandasコードを生成し、エージェントの関数処理メソッドがコードを実行して答えを返します。
これがあなたがこれを行う方法です:
import langroid as lr
from langroid . agent . special import TableChatAgent , TableChatAgentConfigデータファイル、URL、またはデータフレーム用のTableChatAgent設定します(データテーブルにヘッダー行があることを確認します。
dataset = "https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv"
# or dataset = "/path/to/my/data.csv"
# or dataset = pd.read_csv("/path/to/my/data.csv")
agent = TableChatAgent (
config = TableChatAgentConfig (
data = dataset ,
)
)タスクを設定し、次のような一回限りの質問をします。
task = lr . Task (
agent ,
name = "DataAssistant" ,
default_human_response = "" , # to avoid waiting for user input
)
result = task . run (
"What is the average alcohol content of wines with a quality rating above 7?" ,
turns = 2 # return after user question, LLM fun-call/tool response, Agent code-exec result
)
print ( result . content )または、タスクをセットアップして、ユーザーとのインタラクティブループで実行します。
task = lr . Task ( agent , name = "DataAssistant" )
task . run ()完全な例についてはlangroid-examples Repoのtable_chat.pyスクリプトを参照してください。
このプロジェクトが気に入ったら、星を渡してください。ネットワークまたはソーシャルメディアに単語を広めます:
あなたのサポートは、Langroidの勢いとコミュニティの構築に役立ちます。


