dalle flow
1.0.0


ループの人間?テキストからHD画像を作成するためのワークフロー
Dall・E Flowは、テキストプロンプトから高解像度画像を生成するためのインタラクティブなワークフローです。まず、Dall・e-mega、Glid-3 XL、および安定した拡散を活用して画像候補を生成し、クリップとしてサービスを呼び出して候補者にプロンプトをランク付けします。好ましい候補は、拡散のためにGlid-3 XLに供給され、テクスチャと背景を豊かにすることがよくあります。最後に、候補者はスウィニールを介して1024x1024に上昇します。
DALL・E Flowは、クライアントサーバーアーキテクチャのJinaで構築されており、高いスケーラビリティ、非ブロッキングストリーミング、最新のPythonicインターフェイスを提供します。クライアントは、TLSを使用してGRPC/WebSocket/HTTPを介してサーバーと対話できます。
なぜ人間のループ?生成アートは創造的なプロセスです。 Dall・eの最近の進歩は人々の創造性を解き放ちますが、シングルプロンプトシングル出力UX/UIを持つことで、想像力が単一の可能性にロックされますが、この単一の結果がどれほど素晴らしいかに関係なく悪いです。 Dall・E Flowは、生成アートを反復手順として形式化することにより、1ライナーの代替です。
Dall・E Flowは、クライアントサーバーアーキテクチャにあります。
grpcs://api.clip.jina.ai:2096 ( jina >= v3.11.0が必要)で利用可能なクリップとしてのクリップとして使用するには、最初にアクセストークンを入手する必要があります。詳細については、サービスとしてのクリップとしての使用を参照してください。flow_parser.pyでフラグを有効にする必要があります。grpcs://dalle-flow.dev.jina.aiに変化しています。すべての接続はTLS暗号化を使用しています。GoogleColabのノートブックを再開してください。p2.x8largeインスタンスで再現可能であることが証明されました。ViT-L/14@336pxを使用してサービスとして使用します。 steps 100->200 。















































クライアントの使用は非常に簡単です。次の手順は、JupyterノートブックまたはGoogle Colabで最もよく実行されます。
最初にDocarrayとJinaをインストールする必要があります:
pip install " docarray[common]>=0.13.5 " jinaプレイできるデモサーバーを提供しました。
ショ和 大規模なリクエストにより、サーバーはそれに応じて遅れている可能性があります。しかし、私たちは稼働時間を高く保つことに非常に自信があります。ここで命令に従って独自のサーバーを展開することもできます。
server_url = 'grpcs://dalle-flow.dev.jina.ai'次に、プロンプトを定義しましょう。
prompt = 'an oil painting of a humanoid robot playing chess in the style of Matisse'サーバーに送信して、結果を視覚化しましょう。
from docarray import Document
doc = Document ( text = prompt ). post ( server_url , parameters = { 'num_images' : 8 })
da = doc . matches
da . plot_image_sprites ( fig_size = ( 10 , 10 ), show_index = True )ここでは、Dalle-Megaから8人、Glid3 XLから8人、安定した拡散から8人の候補者を生成します。これは、約2分かかるnum_imagesで定義されています。長すぎる場合は、より小さな値を使用できます。

24人の候補者は、Clip-as-Serviceでソートされ、Index 0はClipで判断された最高の候補者として並べ替えられます。もちろん、あなたは違った考え方をするかもしれません。左上隅の番号に注目してください。あなたが一番好きなものを選択し、より良いビューを得る:
fav_id = 3
fav = da [ fav_id ]
fav . embedding = doc . embedding
fav . display ()
次に、選択した候補者を拡散のためにサーバーに提出しましょう。
diffused = fav . post ( f' { server_url } ' , parameters = { 'skip_rate' : 0.5 , 'num_images' : 36 }, target_executor = 'diffusion' ). matches
diffused . plot_image_sprites ( fig_size = ( 10 , 10 ), show_index = True )これにより、選択した画像に基づいて36の画像が表示されます。 skip_rateゼロ近くの値、または指定された画像に近さを強制するために、よりゼロの値、または近い値を与えることにより、モデルがより即興でできるようにすることができます。手順全体に約2分かかります。

あなたが一番好きな画像を選択し、それをよく見てください:
dfav_id = 34
fav = diffused [ dfav_id ]
fav . display ()
最後に、最後のステップでサーバーに送信します:1024 x 1024pxへのアップスケーリング。
fav = fav . post ( f' { server_url } /upscale' )
fav . display ()それでおしまい!それは1つです。満足していない場合は、手順を繰り返してください。

ところで、Docarrayは、構造化されていないデータの強力で使いやすいデータ構造です。クロス/マルチモーダルドメインで働くデータサイエンティストにとって非常に生産的です。 Docarrayの詳細については、ドキュメントをご覧ください。
以下の命令に従って、独自のサーバーをホストできます。
DALL・E Flowには、ピーク時に21GB VRAMを備えた1つのGPUが必要です。すべてのサービスはこの1つのGPUに絞り込まれます。これには(おおよそ)が含まれます
config.yml 、512x512)次の合理的なトリックを使用して、VRAMをさらに減らすために使用できます。
ハードドライブには、主に優先モデルをダウンロードするために、少なくとも50GBの空きスペースが必要です。
高速インターネットが必要です。遅い/不安定なインターネットは、モデルをダウンロードするときにイライラするタイムアウトを投げる可能性があります。
CPUのみの環境はテストされておらず、おそらく機能しない可能性があります。 Google ColabはOOMを投げている可能性が高いため、機能しません。

Jinaをインストールした場合、上記のフローチャートを経由して生成できます。
# pip install jina
jina export flowchart flow.yml flow.svg安定した拡散を使用する場合は、まずWebサイトのHuggingFaceにアカウントを登録し、モデルの利用規約に同意する必要があります。ログインした後、ここに行くことで必要なモデルのバージョンを見つけることができます。
compvis / sd-v1-5-inpainting.ckpt
ダウンロードThe Weightsセクションでは、 sd-v1-x.ckptのリンクをクリックします。執筆時点の最新の重みはsd-v1-5.ckptです。
Dockerユーザー:このファイルをldm/stable-diffusion-v1という名前のフォルダーに入れ、IT model.ckpt名前を変更します。デフォルトではSDが有効になっていないため、以下の指示に注意してください。
ネイティブユーザー:このファイルをdalle/stable-diffusion/models/ldm/stable-diffusion-v1/model.ckptに、「Natively」の下で残りのステップを終了した後。デフォルトではSDが有効になっていないため、以下の指示に注意してください。
直接引くことができる事前に構築されたDocker画像を提供しました。
docker pull jinaai/dalle-flow:latest箱から出してサーバーを実行できるDockerFileを提供しました。
私たちのDockerFileは、CUDA 11.6をベース画像として使用しています。システムに従って調整することができます。
git clone https://github.com/jina-ai/dalle-flow.git
cd dalle-flow
docker build --build-arg GROUP_ID= $( id -g ${USER} ) --build-arg USER_ID= $( id -u ${USER} ) -t jinaai/dalle-flow .建物の平均インターネット速度で10分かかり、18GBのDocker画像が発生します。
それを実行するには、単に実行します:
docker run -p 51005:51005
-it
-v $HOME /.cache:/home/dalle/.cache
--gpus all
jinaai/dalle-flowまたは、いくつかのワークフローを有効または無効にして実行して、メモリ外のクラッシュを防ぐこともできます。それを行うには、これらの環境変数の1つを渡します。
DISABLE_DALLE_MEGA
DISABLE_GLID3XL
DISABLE_SWINIR
ENABLE_STABLE_DIFFUSION
ENABLE_CLIPSEG
ENABLE_REALESRGAN
たとえば、Glid3XLワークフローを無効にしたい場合は、実行してください。
docker run -e DISABLE_GLID3XL= ' 1 '
-p 51005:51005
-it
-v $HOME /.cache:/home/dalle/.cache
--gpus all
jinaai/dalle-flow-v $HOME/.cache:/root/.cacheすべてのDocker実行で繰り返しモデルのダウンロードを避けます。-p 51005:51005の最初の部分は、ホストパブリックポートです。あなたが公開している場合は、人々がこのポートにアクセスできることを確認してください。その2番目の額は、flow.ymlで定義されているポートです。ENABLE_STABLE_DIFFUSIONで手動で有効にする必要があります。ENABLE_CLIPSEGで手動で有効にする必要があります。ENABLE_REALESRGANで手動で有効にする必要があります。 SDの環境フラグ( ENABLE_STABLE_DIFFUSION )を有効にしながら、重量をダウンロードして仮想ボリュームとして利用できるようにする場合にのみ、安定した拡散を有効にできます。
以前に、重みをldm/stable-diffusion-v1という名前のフォルダーに入れ、 model.ckptをラベル付けする必要がありました。以下のYOUR_MODEL_PATH/ldm独自のシステムのパスに置き換えて、ウェイトをDocker画像にパイプします。
docker run -e ENABLE_STABLE_DIFFUSION= " 1 "
-e DISABLE_DALLE_MEGA= " 1 "
-e DISABLE_GLID3XL= " 1 "
-p 51005:51005
-it
-v YOUR_MODEL_PATH/ldm:/dalle/stable-diffusion/models/ldm/
-v $HOME /.cache:/home/dalle/.cache
--gpus all
jinaai/dalle-flow実行すると、次のような画面が表示されるはずです。
ネイティブに実行するのとは異なり、Docker内で実行すると、鮮明なProgressBar、カラーログ、プリントが少なくなる可能性があります。これは、Dockerコンテナ内の端子の制限によるものです。実際の使用には影響しません。
ネイティブに実行するには、いくつかの手動の手順が必要ですが、多くの場合、デバッグが簡単です。
mkdir dalle && cd dalle
git clone https://github.com/jina-ai/dalle-flow.git
git clone https://github.com/jina-ai/SwinIR.git
git clone --branch v0.0.15 https://github.com/AmericanPresidentJimmyCarter/stable-diffusion.git
git clone https://github.com/CompVis/latent-diffusion.git
git clone https://github.com/jina-ai/glid-3-xl.git
git clone https://github.com/timojl/clipseg.git次のフォルダー構造が必要です。
dalle/
|
|-- Real-ESRGAN/
|-- SwinIR/
|-- clipseg/
|-- dalle-flow/
|-- glid-3-xl/
|-- latent-diffusion/
|-- stable-diffusion/
cd dalle-flow
python3 -m virtualenv env
source env/bin/activate && cd -
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116
pip install numpy tqdm pytorch_lightning einops numpy omegaconf
pip install https://github.com/crowsonkb/k-diffusion/archive/master.zip
pip install git+https://github.com/AmericanPresidentJimmyCarter/[email protected]
pip install basicsr facexlib gfpgan
pip install realesrgan
pip install https://github.com/AmericanPresidentJimmyCarter/xformers-builds/raw/master/cu116/xformers-0.0.14.dev0-cp310-cp310-linux_x86_64.whl &&
cd latent-diffusion && pip install -e . && cd -
cd stable-diffusion && pip install -e . && cd -
cd SwinIR && pip install -e . && cd -
cd glid-3-xl && pip install -e . && cd -
cd clipseg && pip install -e . && cd -Glid-3-XL用にダウンロードする必要があるカップルモデルがあります。
cd glid-3-xl
wget https://dall-3.com/models/glid-3-xl/bert.pt
wget https://dall-3.com/models/glid-3-xl/kl-f8.pt
wget https://dall-3.com/models/glid-3-xl/finetune.pt
cd - clipsegとRealESRGAN両方で、正しいキャッシュフォルダーパス、通常は$ home/のようなものを設定する必要があります。
cd dalle-flow
pip install -r requirements.txt
pip install jax~=0.3.24これでdalle-flow/下にあります。次のコマンドを実行します。
# Optionally disable some generative models with the following flags when
# using flow_parser.py:
# --disable-dalle-mega
# --disable-glid3xl
# --disable-swinir
# --enable-stable-diffusion
python flow_parser.py
jina flow --uses flow.tmp.ymlこの画面はすぐに表示されます。

最初のスタートでは、Dall・E Megaモデルやその他の必要なモデルをダウンロードするには約8分かかります。手続きの実行は、成功メッセージに到達するまでに約1分しかかからないはずです。
すべての準備ができたら、あなたは見るでしょう:
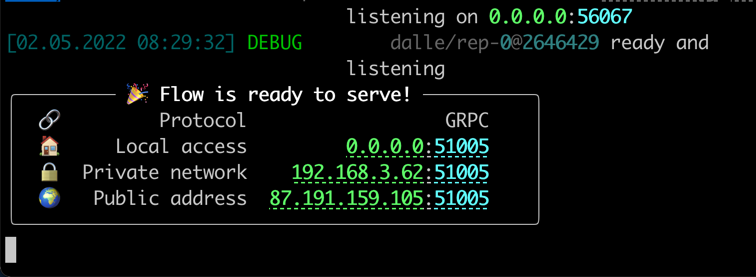
おめでとう!これで、クライアントを実行できるはずです。
モデルの変更、永続性の追加、またはInstagram/Openseaへの自動ポストなど、サーバーフローを好きなように変更および拡張できます。 JinaとDocarrayを使用すると、ドールを簡単にFlow Cloud-Nativeに作成し、生産の準備ができています。
VRAMの使用を減らすために、 grpcs://api.clip.jina.ai:2096で自由に利用できる外部エグゼキューターとしてCLIP-as-serviceとして使用できます。
まず、コンソールWebサイトからアクセストークンを作成したことを確認してください。
jina auth token create < name of PAT > -e < expiration days >次に、 flow.ymlからエグゼキュータ関連の構成( host 、 port 、 external 、 tls 、 grpc_metadata )を変更する必要があります。
...
- name : clip_encoder
uses : jinahub+docker://CLIPTorchEncoder/latest-gpu
host : ' api.clip.jina.ai '
port : 2096
tls : true
external : true
grpc_metadata :
authorization : " <your access token> "
needs : [gateway]
...
- name : rerank
uses : jinahub+docker://CLIPTorchEncoder/latest-gpu
host : ' api.clip.jina.ai '
port : 2096
uses_requests :
' / ' : rank
tls : true
external : true
grpc_metadata :
authorization : " <your access token> "
needs : [dalle, diffusion]また、 flow_parser.py使用して、外部エグゼキューターとしてCLIP-as-serviceの使用を使用して、フローを自動的に生成および実行することもできます。
python flow_parser.py --cas-token " <your access token>'
jina flow --uses flow.tmp.yml
ショ和 grpc_metadataは、Jinav3.11.0以降にのみ利用できます。古いバージョンを使用している場合は、最新バージョンにアップグレードしてください。
これで、フローで無料のCLIP-as-serviceを使用できます。
Dall・E FlowはJina AIに支えられ、Apache-2.0に基づいてライセンスされています。私たちは、AIエンジニアであるソリューションエンジニアを積極的に採用して、オープンソースで次のニューラル検索エコシステムを構築しています。


