rag experiment accelerator
1.0.0
RAG実験アクセラレータは、 Azure AI検索とRAGパターンを使用して実験と評価を実施するのに役立つ汎用性の高いツールです。このドキュメントは、目的、機能、インストール、使用法など、このツールについて知っておくべきすべてをカバーする包括的なガイドを提供します。
RAG実験アクセラレータの主な目標は、検索クエリの実験と評価とOpenaiからの応答の質の評価をより簡単かつ速くすることです。このツールは、研究者、データ科学者、および次のことを望む開発者に役立ちます。
2024年3月18日:コンテンツサンプリングが追加されました。この機能により、データセットを指定された割合でサンプリングできます。データはコンテンツによってクラスター化され、サンプルの割合が各クラスター全体で取得され、サンプリングされたデータの分布を試みます。
これは、データセット全体に到達するサンプルの代表的な結果を確実にするために行われます。
注:新しい依存関係のためにこのツールを以前に使用したことがある場合は、環境を再構築することをお勧めします。
RAG実験アクセラレータは構成駆動型であり、その目的をサポートする豊富な機能セットを提供します。
実験のセットアップ:さまざまな検索エンジンパラメーター、検索タイプ、クエリセット、および評価メトリックを指定することにより、実験を定義および構成できます。
統合:Azure AI検索、Azure Machine Learning、MLFlow、Azure Openaiとシームレスに統合します。
リッチ検索インデックス:構成ファイルで利用可能なHyperParameter構成に基づいて、複数の検索インデックスを作成します。
複数のドキュメントローダー:ツールは、Azure Document IntelligenceやBasic Langchain Loadersを介したロードなど、複数のドキュメントローダーをサポートしています。これにより、さまざまな抽出方法を実験し、それらの有効性を評価する柔軟性が得られます。
カスタムドキュメントインテリジェンスローダー:ドキュメントインテリジェンス用の「事前にビルトレイアウト」APIモデルを選択すると、このツールはカスタムドキュメントインテリジェンスローダーを使用してデータをロードします。このカスタムローダーは、列ヘッダーをキー価値ペアにするテーブルのフォーマットをサポートします(LLMの読みやすさを向上させるため)。LLMのファイルの無関係な部分(ページ番号やフッターなど)を除外し、Regexなどを使用してファイル内の繰り返しパターンを削除します。各テーブルの行はテキスト行に変換されるため、中央の列を壊さないようにするため、チャンクは段落と行によって再帰的に行われます。カスタムローダーは、「事前に構築されたレイアウト」が失敗したときにフォールバックとして、よりシンプルな「事前にビルトレイアウト」APIモデルに頼ります。他のAPIモデルは、Langchainの実装を利用して、ドキュメントインテリジェンスのAPIから生の応答を返します。
クエリ生成:このツールは、さまざまな多様でカスタマイズ可能なクエリセットを生成できます。これは、特定の実験ニーズに合わせて調整できます。
複数の検索タイプ:純粋なテキスト、純粋なベクトル、クロスベクトル、マルチベクトル、ハイブリッドなど、複数の検索タイプをサポートします。これにより、検索機能と結果に関する包括的な分析を実施することができます。
サブクエリ:パターンはユーザークエリを評価し、それが十分に複雑であると判断した場合、関連するコンテキストを生成するためにそれをより小さなサブQuerieに分解します。
再ランク:Azure AI検索からのクエリ応答は、LLMを使用して再評価され、クエリとコンテキストの関連性に応じてランク付けされます。
メトリックと評価:距離ベース、コサイン、セマンティックの類似性メトリックを含む、グラウンドトゥルースの回答(予想)と生成された回答(実際)を比較するエンドツーエンドメトリックをサポートします。また、コンテキストのリコールや回答の関連性など、LLMを使用してLLMを使用して検索と生成のパフォーマンスを評価するコンポーネントベースのメトリック、および検索結果を評価するための検索メトリック(MAP@K)も含まれます。
レポート生成: RAG実験アクセラレータは、レポート生成のプロセスを自動化し、実験結果を簡単に分析して共有できる視覚化を備えています。
多言語:このツールは、個々の言語での言語サポートと、検索インデックスのユーザー定義パターンの専門的な(言語に依存しない)アナライザーの言語分析装置をサポートしています。詳細については、アナライザーの種類を参照してください。
サンプリング:大規模なデータセットや実験をスピードアップしたい場合は、サンプリングプロセスを利用して、指定された割合のデータの小規模だが代表的なサンプルを作成します。データはコンテンツによってクラスター化され、各クラスターの割合がサンプルの一部として選択されます。得られた結果は、〜10%のマージン内の完全なデータセットをほぼ示す必要があります。アプローチが特定されたら、正確な結果を得るには、完全なデータセットで実行されます。
現時点では、RAG実験アクセラレータは、次のいずれかをローカルで活用できます。
開発コンテナを使用すると、必要なすべてのソフトウェアがインストールされていることを意味します。これにはWSLが必要です。開発コンテナの詳細については、containers.devをご覧ください
次のソフトウェアをホストマシンにインストールします。次の展開を実行します。
- Windows -Windows Store Ubuntu 22.04.3 LTS
- Dockerデスクトップ
- ビジュアルスタジオコード
- VSコード拡張機能:リモートコンテナー
WSLのセットアップに関するさらなるガイダンスは、こちらをご覧ください。今、あなたは前提条件を持っています、あなたは次のことができます:
git clone https://github.com/microsoft/rag-experiment-accelerator.git
code .プロジェクトがVSCODEで開いたら、「開発コンテナでこれを再開する」かどうかを尋ねる必要があります。はいと言います。
もちろん、必要に応じて、Windows/MacマシンでRAG実験アクセラレータを実行できます。正しいツールをインストールする責任があります。これらのインストール手順に従ってください。
git clone https://github.com/microsoft/rag-experiment-accelerator.gitconda create -n rag-experiment python=3.11
conda init bash端末を閉じて、新しいものを開いて実行します。
conda activate rag-experiment
pip install .az login
az account set --subscription= " <your_subscription_guid> "
az account show必要なすべてのAzureサービスをインストールする3つのオプションがあります。
このプロジェクトは、Azure開発者CLIをサポートしています。
azd provisionazd provisionに電話するように希望する場合は、 azd upを使用することもできます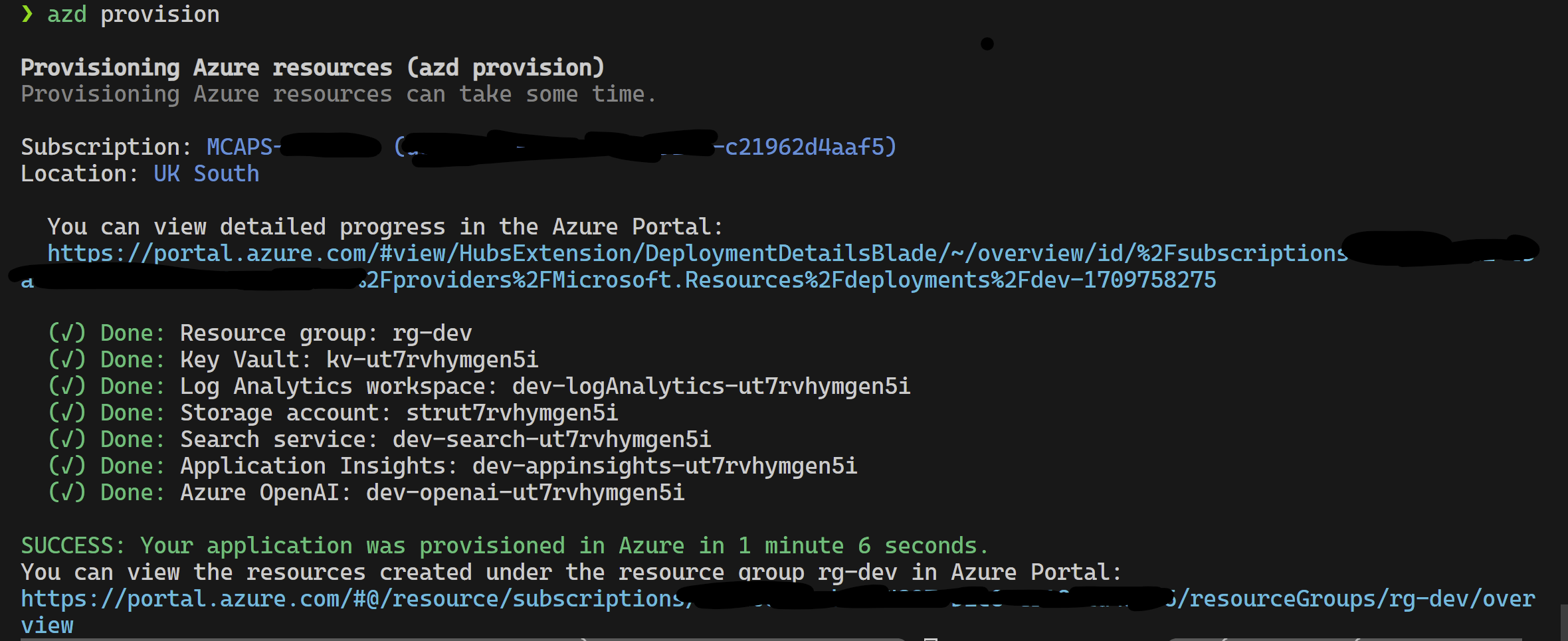
これが完了したら、起動構成を使用して実行するか、4つのステップをデバッグし、 azdによってプロビジョニングされた現在の環境に正しい値がロードされます。
テンプレートからインフラストラクチャを自分で展開したい場合は、ここをクリックしてください。
azdを使用したくない場合は、通常のaz CLIも使用できます。
次のコマンドを使用して展開します。
az login
az deployment sub create --subscription < subscription-id > --location < location > --template-file infra/main.bicepまたは
次のコマンドを使用して、孤立したネットワーク使用で展開します。パラメーター値を分離ネットワークの詳細に置き換えます。孤立したネットワークに展開する場合は、3つのパラメーターすべて(つまり、 vnetAddressSpace 、 proxySubnetAddressSpace 、およびsubnetAddressSpace )を提供する必要があります。
az login
az deployment sub create --location < location > --template-file infra/main.bicep
--parameters vnetAddressSpace= < vnet-address-space >
--parameters proxySubnetAddressSpace= < proxy-subnet-address-space >
--parameters subnetAddressSpace= < azure-subnet-address-space >パラメーター値の例は次のとおりです。
az deployment sub create --location uksouth --template-file infra/main.bicep
--parameters vnetAddressSpace= ' 10.0.0.0/16 '
--parameters proxySubnetAddressSpace= ' 10.0.1.0/24 '
--parameters subnetAddressSpace= ' 10.0.2.0/24 ' RAG実験アクセラレータをローカルに使用するには、次の手順に従ってください。
提供された.env.templateファイルを.envという名前のファイルにコピーし、必要な値をすべて更新します。 .envファイルに必要な値の多くは、以前に構成されていた、および/またはプロビジョニングインフラストラクチャセクションで提供されたリソースから収集できるリソースからのものです。また、デフォルトでは、 LOGGING_LEVEL DEBUG INFO CRITICAL設定されていますERROR INFO WARNのレベルのNOTSETかに変更できます。
cp .env.template .env
# change parameters manually提供されたconfig.sample.jsonファイルをconfig.jsonという名前のファイルにコピーし、ハイパーパラメーターを変更して実験に合わせます。
cp config.sample.json config.json
# change parameters manually任意のファイル(PDF、HTML、MarkDown、Text、JSON、またはDOCX形式)をdataフォルダーにコピーします。
01_index.py (python 01_index.py)を実行して、Azure AI検索インデックスとそれらにデータをロードします。
python 01_index.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-dd " The directory holding the data. Defaults to data "
-cf " JSON config filename. Defaults to config.json " 02_qa_generation.py (python 02_qa_generation.py)を実行して、Azure Openaiを使用して質問回答ペアを生成します。
python 02_qa_generation.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-dd " The directory holding the data. Defaults to data "
-cf " JSON config filename. Defaults to config.json " 03_querying.py (Python 03_Querying.py)を実行してAzure AI検索をクエリしてコンテキストを生成し、コンテキストでアイテムを再ランクし、新しいコンテキストを使用してAzure Openaiから応答を取得します。
python 03_querying.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-cf " JSON config filename. Defaults to config.json " 04_evaluation.py (Python 04_Evaluation.py)を実行して、さまざまな方法を使用してメトリックを計算し、MLFLOW統合を使用してAzure機械学習でチャートとレポートを生成します。
python 04_evaluation.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-cf " JSON config filename. Defaults to config.json "または、Azure MLパイプラインを使用して、上記の手順( 02_qa_generation.py以外)を実行できます。これを行うには、こちらのガイドに従ってください。
サンプリングはローカルで実行され、データの小さいが代表的なスライスが作成されます。これは迅速な実験に役立ち、コストを抑えます。得られた結果は、〜10%のマージン内の完全なデータセットをほぼ示す必要があります。アプローチが特定されたら、正確な結果を得るには、完全なデータセットで実行されます。
注:サンプリングはローカルでのみ実行できます。この段階では、分散型AMLコンピューティングクラスターではサポートされていません。したがって、プロセスは、局所的にサンプリングを実行し、生成されたサンプルデータセットを使用してAMLで実行することです。
非常に大きなデータセットがあり、データをサンプリングするために同様のアプローチを実行したい場合は、MicrosoftファブリックまたはAzure Synapse分析用のデータ発見ツールキットでPysparkインメモリ分散実装を使用できます。
"sampling" : {
"sample_data" : " Set to true to enable sampling " ,
"only_run_sampling" : " If set to true, this will only run the sampling step and will not create an index or any subsequent steps, use this if you want to build a small sampled dataset to run in AML " ,
"sample_percentage" : " Percentage of the document corpus to sample " ,
"optimum_k" : " Set to 'auto' to automatically determine the optimum cluster number or set to a specific value e.g. 15 " ,
"min_cluster" : " Used by the automated optimum cluster process, this is the minimum number of clusters e.g. 2 " ,
"max_cluster" : " Used by the automated optimum cluster process, this is the maximum number of clusters e.g. 30 " ,
},サンプリングプロセスは、サンプリングディレクトリに次のアーティファクトを生成します。
job_nameにちなんで名付けられたディレクトリは、AMLでプロセス全体を実行するときに--data_dir引数として指定できます。
"optimum_k": auto構成値が自動に設定されている場合、サンプリングプロセスはクラスターの最適数を自動的に設定しようとします。データに存在するコンテンツの広いバケツの数をほぼ知っている場合、これはオーバーライドできます。サンプリングフォルダーで肘グラフが生成されます。 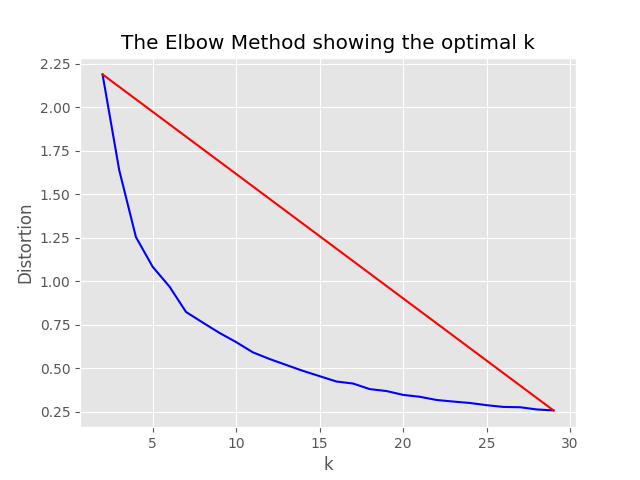
サンプリングの実行には2つのオプションが存在します。
インデックスプロセスをローカルに実行するように、次の値を設定します。
"sampling" : {
"sample_data" : true ,
"only_run_sampling" : false ,
"sample_percentage" : 10 ,
"optimum_k" : auto,
"min_cluster" : 2 ,
"max_cluster" : 30
},only_run_sampling構成値がtrueに設定されている場合、これはサンプリングステップのみを実行し、インデックスは作成されず、他の後続のステップは実行されません。 --data_dir引数をサンプリングプロセスによって作成されたディレクトリに設定します。
artifacts/sampling/config.[job_name] AMLパイプラインステップを実行します。
すべての値は要素のリストになります。ネストされた構成を含む。すべての配列は、メソッドflatten()特定のノードで呼び出されると、フラット構成の組み合わせを生成し、1つのランダムな組み合わせを選択します - メソッドsample()を呼び出します。
{
"experiment_name" : " If provided, this will be the experiment name in Azure ML and it will group all job run under the same experiment, otherwise (if left empty) index_name_prefix will be used and there may be more than one experiment " ,
"job_name" : " If provided, all jobs runs in Azure ML will be named with this property value plus timestamp, otherwise (if left empty) each job with be named only with timestamp " ,
"job_description" : " You may provide a description for the current job run which describes in words what you are about to experiment with " ,
"data_formats" : " Specifies the supported data formats for the application. You can choose from a variety of formats such as JSON, CSV, PDF, and more. [*] - means all formats included " ,
"main_instruction" : " Defines the main instruction prompt coming with queries to LLM " ,
"use_checkpoints" : " A boolean. If true, enables use of checkpoints to load data and skip processing that was already done in previous executions. " ,
"index" : {
"index_name_prefix" : " Search index name prefix " ,
"ef_construction" : " ef_construction value determines the value of Azure AI Search vector configuration. " ,
"ef_search" : " ef_search value determines the value of Azure AI Search vector configuration. " ,
"chunking" : {
"preprocess" : " A boolean. If true, preprocess documents, split into smaller chunks, embed and enrich them, and finally upload documents chunks for retrieval into Azure Search Index. " ,
"chunk_size" : " Size of each chunk e.g. [500, 1000, 2000] " ,
"overlap_size" : " Overlap Size for each chunk e.g. [100, 200, 300] " ,
"generate_title" : " A boolean. If true, a title is generated for the chunk of content and an embedding is created for it " ,
"generate_summary" : " A boolean. If true, a summary is generated for the chunk of content and an embedding is created for it " ,
"override_content_with_summary" : " A boolean. If true, The chunk content is replaced with its summary " ,
"chunking_strategy" : " determines the chunking strategy. Valid values are 'azure-document-intelligence' or 'basic' " ,
"azure_document_intelligence_model" : " represents the Azure Document Intelligence Model. Used when chunking strategy is 'azure-document-intelligence'. When set to 'prebuilt-layout', provides additional features (see above) "
},
"embedding_model" : " see 'Description of embedding models config' below " ,
"sampling" : {
"sample_data" : " Set to true to enable sampling " ,
"percentage" : " Percentage of the document corpus to sample " ,
"optimum_k" : " Set to 'auto' to automatically determine the optimum cluster number or set to a specific value e.g. 15 " ,
"min_cluster" : " Used by the automated optimum cluster process, this is the minimum number of clusters e.g. 2 " ,
"max_cluster" : " Used by the automated optimum cluster process, this is the maximum number of clusters e.g. 30 "
}
},
"language" : {
"analyzer" : {
"analyzer_name" : " name of the analyzer to use for the field. This option can be used only with searchable fields and it can't be set together with either searchAnalyzer or indexAnalyzer. " ,
"index_analyzer_name" : " name of the analyzer used at indexing time for the field. This option can be used only with searchable fields. It must be set together with searchAnalyzer and it cannot be set together with the analyzer option. " ,
"search_analyzer_name" : " name of the analyzer used at search time for the field. This option can be used only with searchable fields. It must be set together with indexAnalyzer and it cannot be set together with the analyzer option. This property cannot be set to the name of a language analyzer; use the analyzer property instead if you need a language analyzer. " ,
"char_filters" : " The character filters for the index " ,
"tokenizers" : " The tokenizers for the index " ,
"token_filters" : " The token filters for the index "
},
"query_language" : " The language of the query. Possible values: en-us, en-gb, fr-fr etc. "
},
"rerank" : {
"enabled" : " determines if search results should be re-ranked. Value values are TRUE or FALSE " ,
"type" : " determines the type of re-ranking. Value values are llm or cross_encoder " ,
"llm_rerank_threshold" : " determines the threshold when using llm re-ranking. Chunks with rank above this number are selected in range from 1 - 10. " ,
"cross_encoder_at_k" : " determines the threshold when using cross-encoding re-ranking. Chunks with given rank value are selected. " ,
"cross_encoder_model" : " determines the model used for cross-encoding re-ranking step. Valid value is cross-encoder/stsb-roberta-base "
},
"search" : {
"retrieve_num_of_documents" : " determines the number of chunks to retrieve from the search index " ,
"search_type" : " determines the search types used for experimentation. Valid value are search_for_match_semantic, search_for_match_Hybrid_multi, search_for_match_Hybrid_cross, search_for_match_text, search_for_match_pure_vector, search_for_match_pure_vector_multi, search_for_match_pure_vector_cross, search_for_manual_hybrid. e.g. ['search_for_manual_hybrid', 'search_for_match_Hybrid_multi','search_for_match_semantic'] " ,
"search_relevancy_threshold" : " the similarity threshold to determine if a doc is relevant. Valid ranges are from 0.0 to 1.0 "
},
"query_expansion" : {
"expand_to_multiple_questions" : " whether the system should expand a single question into multiple related questions. By enabling this feature, you can generate a set of alternative related questions that may improve the retrieval process and provide more accurate results " .,
"query_expansion" : " determines if query expansion feature is on. Value values are TRUE or FALSE " ,
"hyde" : " this feature allows you to experiment with various query expansion approaches which may improve the retrieval metrics. The possible values are 'disabled' (default), 'generated_hypothetical_answer', 'generated_hypothetical_document_to_answer' reference article - Precise Zero-Shot Dense Retrieval without Relevance Labels (HyDE - Hypothetical Document Embeddings) - https://arxiv.org/abs/2212.10496 " ,
"min_query_expansion_related_question_similarity_score" : " minimum similarity score in percentage between LLM generated related queries to the original query using cosine similarly score. default 90% "
},
"openai" : {
"azure_oai_chat_deployment_name" : " determines the Azure OpenAI deployment name " ,
"azure_oai_eval_deployment_name" : " determines the Azure OpenAI deployment name used for evaluation " ,
"temperature" : " determines the OpenAI temperature. Valid value ranges from 0 to 1. "
},
"eval" : {
"metric_types" : " determines the metrics used for evaluation (end-to-end or component-wise metrics using LLMs). Valid values for end-to-end metrics are lcsstr, lcsseq, cosine, jaro_winkler, hamming, jaccard, levenshtein, fuzzy_score, cosine_ochiai, bert_all_MiniLM_L6_v2, bert_base_nli_mean_tokens, bert_large_nli_mean_tokens, bert_large_nli_stsb_mean_tokens, bert_distilbert_base_nli_stsb_mean_tokens, bert_paraphrase_multilingual_MiniLM_L12_v2. Valid values for component-wise LLM-based metrics are llm_answer_relevance, llm_context_precision and llm_context_recall. e.g ['fuzzy_score','bert_all_MiniLM_L6_v2','cosine_ochiai','bert_distilbert_base_nli_stsb_mean_tokens', 'llm_answer_relevance'] " ,
}
}注:構成を変更するときは、変更することを忘れないでください。
config.sample.json (他の人によってコピーされる例の構成)embedding_modelは、使用する埋め込みモデルの構成を含む配列です。埋め込みモデルtype 、Azure Openaiモデルのazureと、Face Sente Transformerモデルをハグするためのsentence-transformerなければなりません。
{
"type" : " azure " ,
"model_name" : " the name of the Azure OpenAI model " ,
"dimension" : " the dimension of the embedding model. For example, 1536 which is the dimension of text-embedding-ada-002 "
} text-embedding-ada-002以外のモデルを使用している場合は、 dimensionフィールドのモデルの対応するディメンションを指定する必要があります。例えば:
{
"type" : " azure " ,
"model_name" : " text-embedding-3-large " ,
"dimension" : 3072
}さまざまなAzure Openai Embeddingsモデルの寸法は、Azure Openaiサービスモデルのドキュメントにあります。
新しい埋め込みモデル(V3)を使用する場合、埋め込みの短縮にサポートを活用することもできます。この場合、必要な寸法の数を指定し、 shorten_dimensionsフラグを追加して、埋め込みを短縮することを示します。例えば:
{
"type" : " azure " ,
"model_name" : " text-embedding-3-large " ,
"dimension" : 256 ,
"shorten_dimensions" : true
}{
"type" : " sentence-transformer " ,
"model_name" : " the name of the sentence transformer model " ,
"dimension" : " the dimension of the model. This field is not required if model name is one of ['all-MiniLM-L6-v2', 'all-mpnet-base-v2', 'bert-large-nli-mean-tokens] "
}クエリの質問に対する仮説的な答えの例を挙げてください。クエリに対する答えを保持する仮想的なパッセージ、または代替関連の質問をほとんど生成しない可能性があるため、検索を改善する可能性があり、したがって、LLMコンテキストに渡すためにドキュメントのより正確なチャンクを取得する可能性があります。参照記事に基づく - 関連ラベルのない正確なゼロショット密な検索(HYDE-仮説文書埋め込み)。
次の構成オプションは、この実験アプローチをオンにします。
{
"hyde" : " generated_hypothetical_answer "
}{
"hyde" : " generated_hypothetical_document_to_answer "
}この機能は、微細な関連する質問を生成し、 min_query_expansion_related_question_similarity_scoreパーセントを元のクエリから(Cosine類似性スコアを使用して)除外し、元のクエリとともにそれぞれの検索ドキュメントを検索し、結果を重複させて、レランカーとトップのKステップに戻します。
min_query_expansion_related_question_similarity_scoreのデフォルト値は90%に設定されていますconfig.jsonでこれを変更できます。
{
"query_expansion" : true ,
"min_query_expansion_related_question_similarity_score" : 90
}ソリューションはAzure Machine Learningと統合され、MLFLOWを使用して実験、ジョブ、およびアーティファクトを管理します。次のレポートを評価プロセスの一部として表示できます。
all_metrics_current_run.html 、選択した各メトリックの質問と検索タイプに平均スコアを表示します。
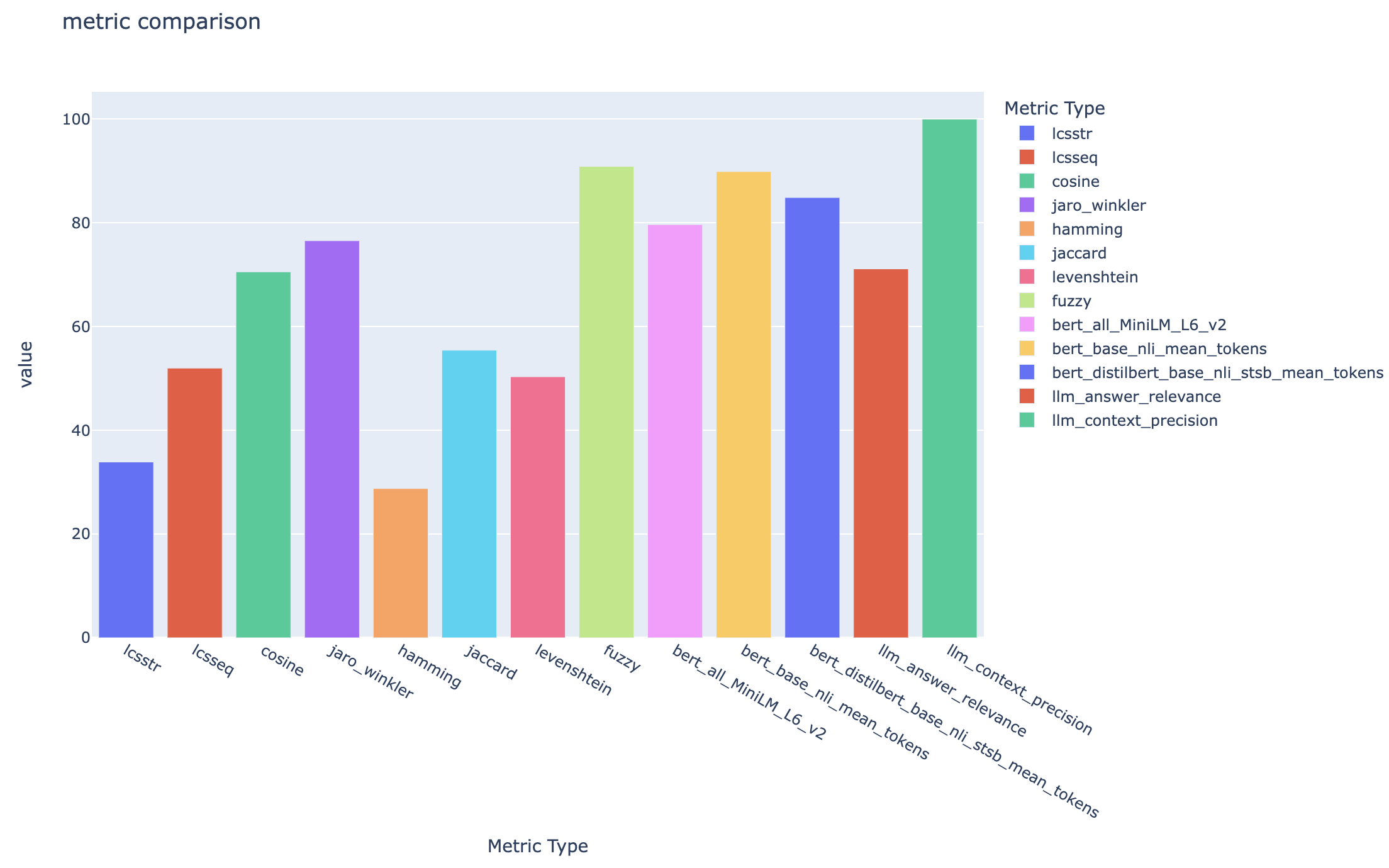
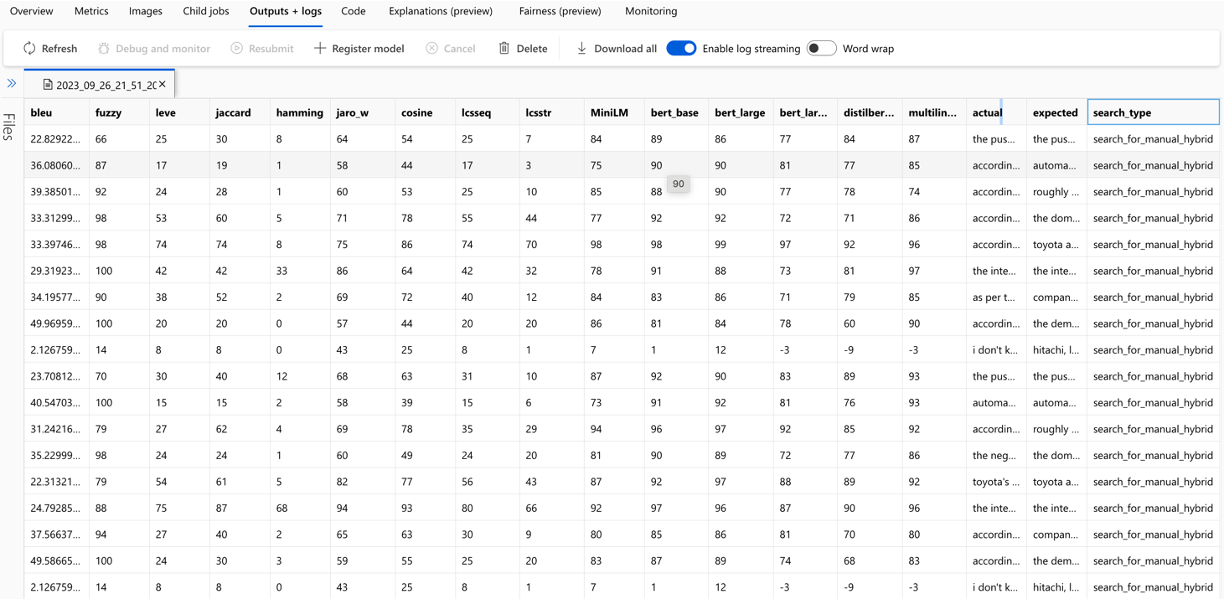
評価に使用される各メトリックとフィールドの計算は、出力CSVファイルの各質問と検索タイプについて追跡されます。
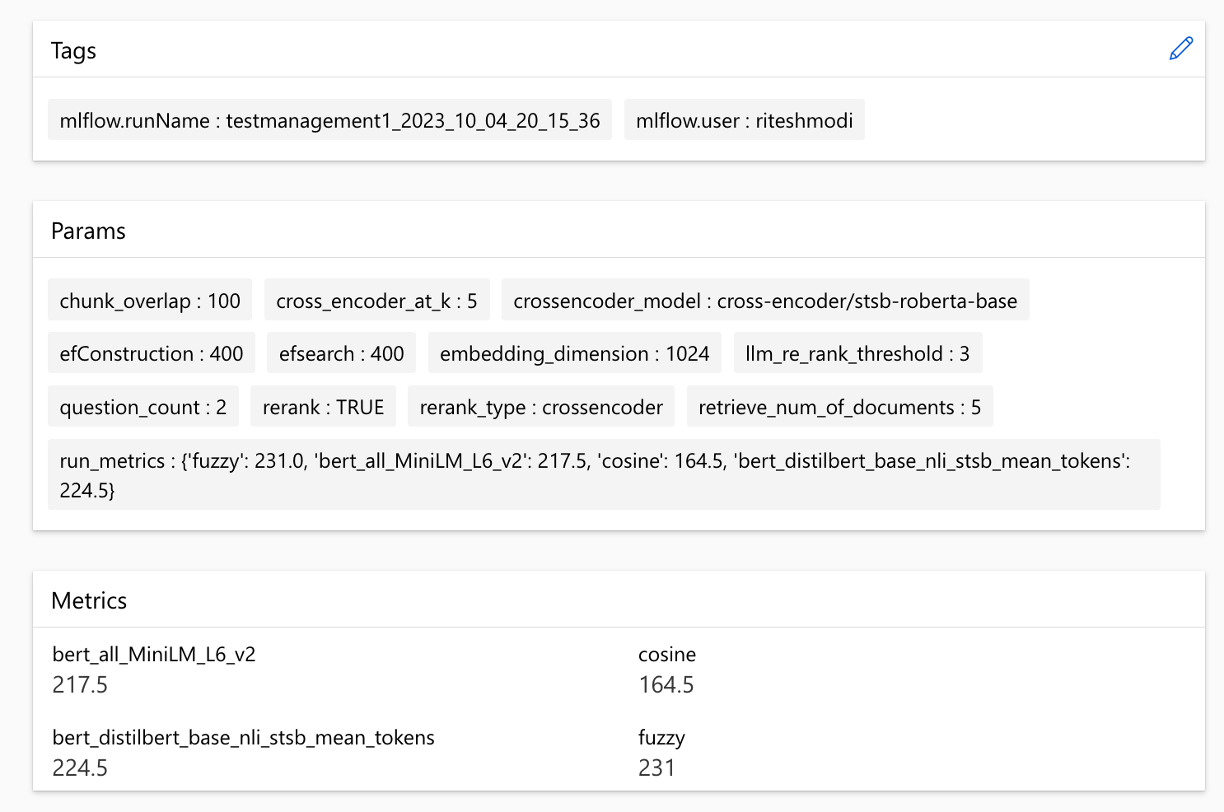
メトリックは実行間で比較できます。
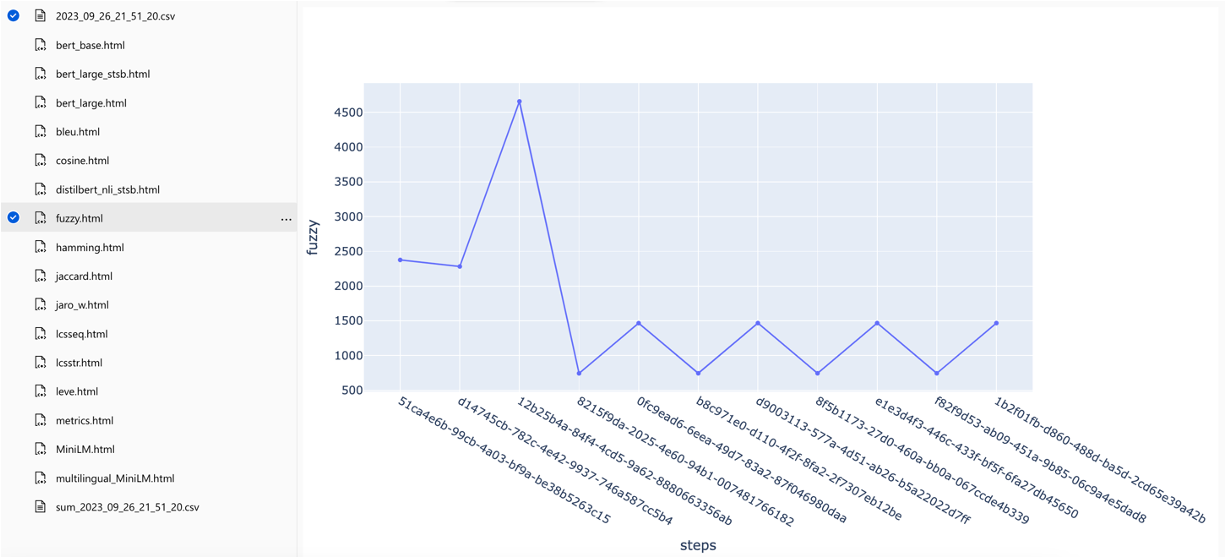
メトリックは、さまざまな検索戦略で比較できます。
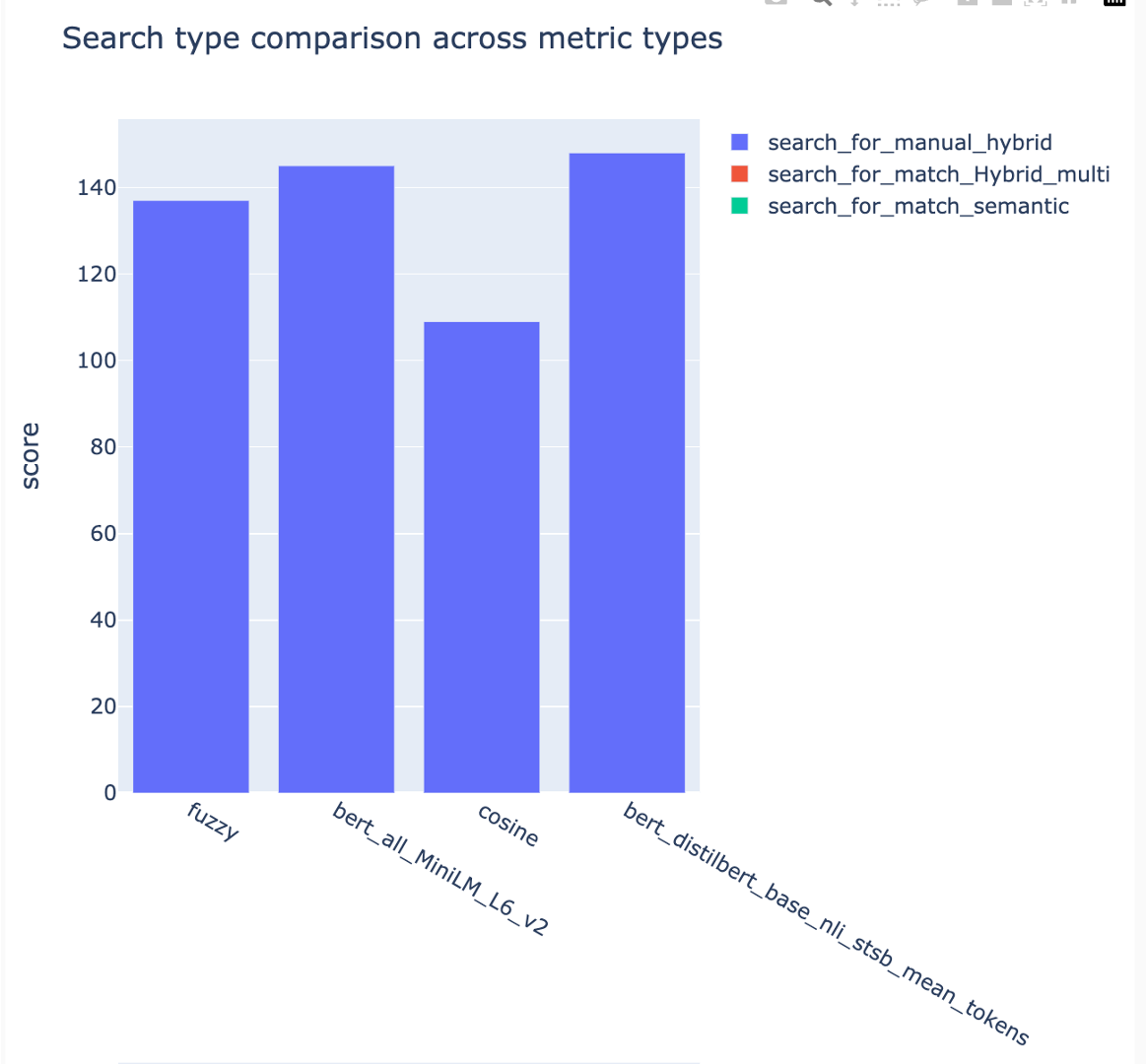
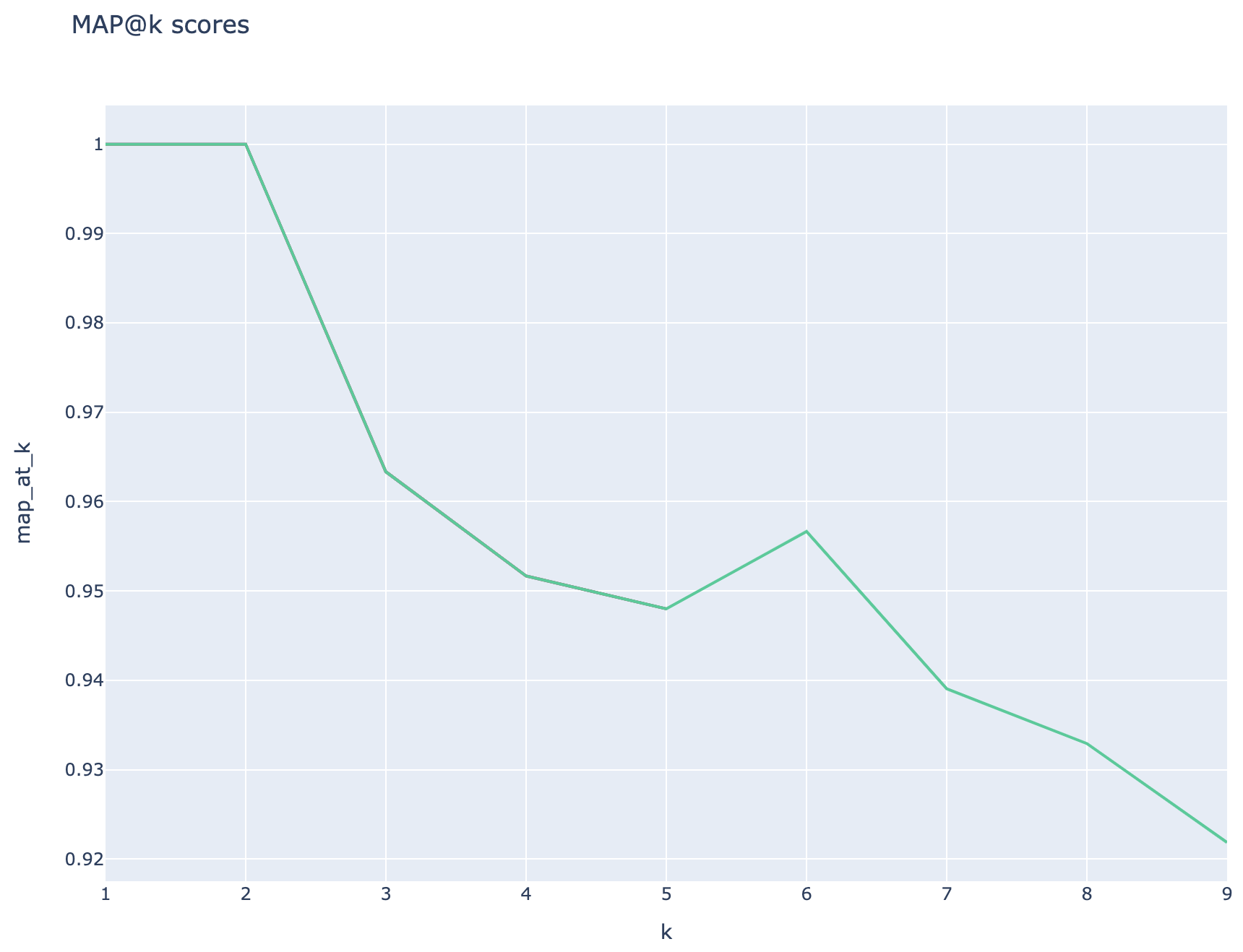
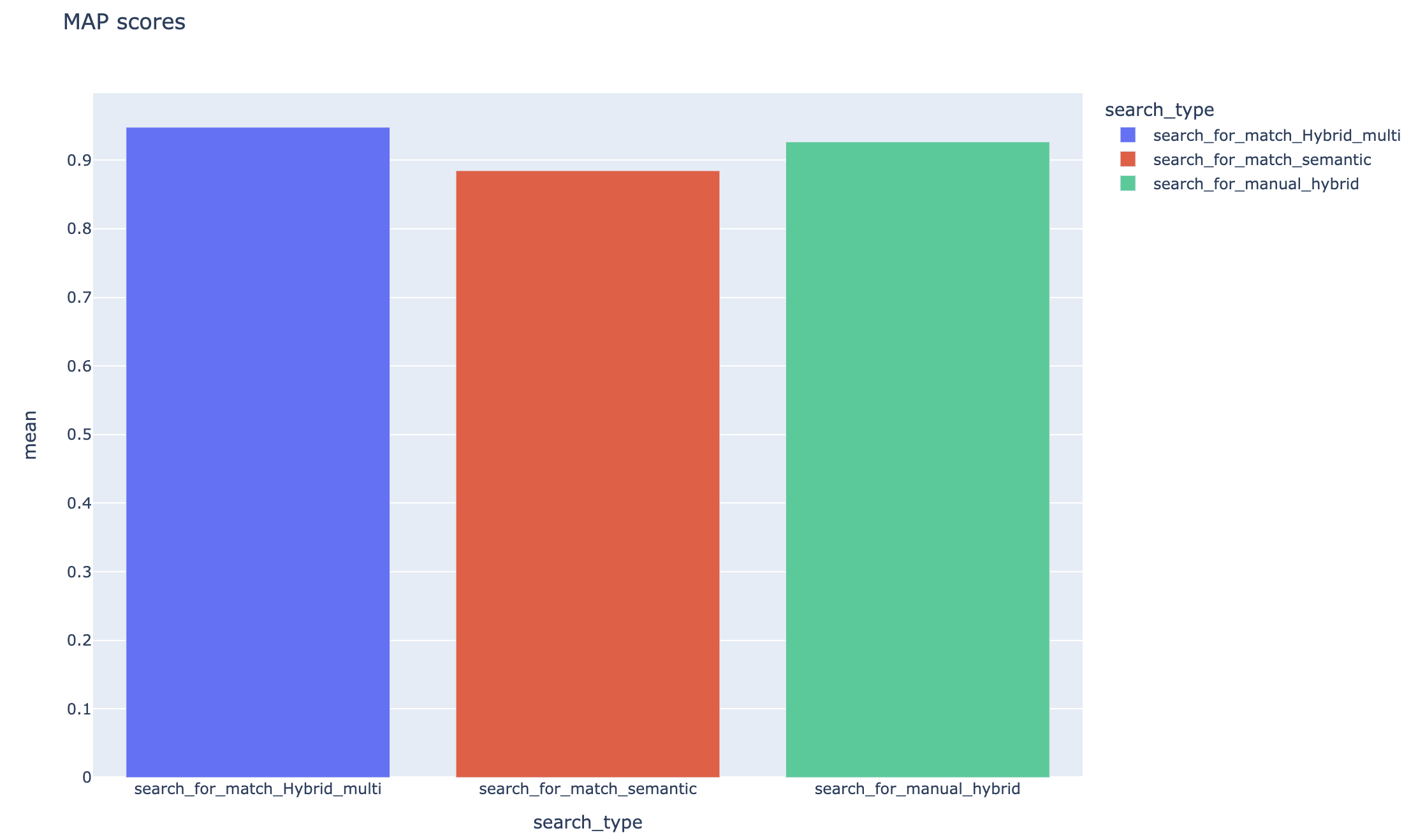
平均平均精度スコアが追跡され、検索タイプで平均マップスコアを比較できます。
このセクションでは、エンジニア/開発者/データ科学者がRAG実験アクセラレータを使用している間に遭遇する可能性のある一般的なゴッチャスまたは落とし穴の概要を説明します。
このソリューションを正常に利用するには、Azureアカウントにログインすることで、まず自分自身を認証する必要があります。この重要なステップにより、Azureリソースにアクセスして使用する必要なアクセス許可が確保されます。 QNAデータをAzure Machine Learning Data Assetsに保存し、Azureへの不適切な承認と認証の結果としてクエリと評価のステップを実行することに関連するエラーがあります。認証と承認については、このドキュメントのポイント4を参照してください。
有効な認証と承認にもかかわらず、ソリューションが依然としてエラーを生成する状況があるかもしれません。このような場合、新しいターミナルインスタンスを使用して新しいセッションを開始し、ステップ4で言及したステップを使用してAzureにログインし、ユーザーがソリューションに関連するAzureリソースへのアクセスを提供しているかどうかを確認します。
このソリューションは、機能とパフォーマンスに直接影響するconfig.jsonのいくつかの構成パラメーターを使用します。これらの設定に細心の注意を払ってください。
retaine_num_of_documents:この構成は、分析のために取得したドキュメントの初期数を制御します。値が過度に高いまたは低い値は、検索AIの結果のランク処理により、「範囲外」エラーにつながる可能性があります。
Cross_encoder_at_k:この構成は、ランキングプロセスに影響します。価値が高いと、最終結果には無関係な文書が含まれる可能性があります。
LLM_RERANK_THRESHOLD:この構成により、どのドキュメントが言語モデル(LLM)に渡されるかを決定して、さらに処理します。この値の設定が高すぎると、LLMが処理するための非常に大きなコンテキストが作成され、処理エラーや劣化した結果につながる可能性があります。これは、Azure Openaiエンドポイントからの例外をもたらす可能性があります。
このソリューションを実行する前に、config.jsonファイル内でAzure OpenAI展開名の両方を正しく設定し、環境変数(.ENVファイル)に関連する秘密を追加してください。この情報は、アプリケーションが設計どおりに適切なAzure Openaiリソースと機能に接続するために重要です。構成データがわからない場合は、.env.templateとconfig.jsonファイルを参照してください。このソリューションはGPT 3.5ターボモデルでテストされており、他のモデルのさらなるテストが必要です。
QNA生成ステップ中に、Azure Openaiから受け取ったJSON出力に関連するエラーが発生することがあります。これらのエラーは、いくつかの質問や回答の成功した生成を防ぐことができます。これがあなたが知っておくべきことです:
誤ったフォーマット: Azure OpenaiからのJSON出力は、予想される形式に準拠しておらず、QNA生成プロセスの問題を引き起こす可能性があります。コンテンツフィルタリング: Azure Openaiにはコンテンツフィルターがあります。入力テキストまたは生成された応答が不適切とみなされる場合、エラーにつながる可能性があります。 APIの制限: Azure Openaiサービスには、出力に影響するトークンとレートの制限があります。
エンドツーエンドの評価メトリック:生成された回答とグラウンドトゥルースの回答を比較するすべてのメトリックが、セマンティクスの違いを捉えることができるわけではありません。たとえば、 levenshteinやjaro_winklerなどのメトリックは、編集距離のみを測定します。 cosineメトリックは、セマンティクスの比較も許可していません。ターム周波数ベクトルに基づいたTextDistanceトークンベースの実装を使用します。生成された回答と予想される応答の間のセマンティックな類似性を計算するには、BERTスコア( bert_ )などの埋め込みベースのメトリックの使用を検討してください。
コンポーネントごとの評価メトリック: LLM-As-Judgesを使用した評価メトリックは決定論的ではありません。 Acceleratorに含まれるllm_メトリックは、 azure_oai_eval_deployment_name Configフィールドに示されているモデルを使用します。評価命令に使用されるプロンプトは調整でき、 prompts.pyファイル( llm_answer_relevance_instruction 、 llm_context_recall_instruction 、 llm_context_precision_instruction )に含まれます。
検索ベースのメトリック: MAPスコアは、取得した各チャンクを質問と比較し、QNAペアを生成するために使用されるチャンクを比較することにより計算されます。検索されたチャンクが関連するかどうかを評価するために、取得したチャンクとエンドユーザーの質問の連結とQNAステップ( 02_qa_generation.py )で使用されるチャンクの連結との類似性は、SpacyEvaluatorを使用して計算されます。 Spacyの類似性は、トークンベクトルの平均にデフォルトであり、計算が単語の順序に鈍感であることを意味します。デフォルトでは、類似のしきい値は80%に設定されています( spacy_evaluator.py )。
貢献と提案を歓迎します。貢献するには、お客様が貢献を使用する権利を認めていることを確認する貢献者ライセンス契約(CLA)に同意する必要があります。詳細については、[https://cla.opensource.microsoft.com]をご覧ください。
プルリクエストを送信すると、CLAボットはCLAを提供する必要があるかどうかを自動的に確認し、指示を提供します(たとえば、ステータスチェック、コメント)。ボットからの指示に従ってください。 CLAを使用するすべてのレポでこれを1回だけ行う必要があります。
貢献する前に、必ず実行してください
pip install -e .
pre-commit install
このプロジェクトは、Microsoftのオープンソース行動規範に従います。詳細については、質問やコメントについては、[email protected]に連絡してください。質問やコメントをご覧ください。
bug/11-short-descriptionfeature/22-short-descriptionexample_snake_caseのように、メトリック名と構成変数にはスネークケースを使用します。git config --global user.name "First Last"このプロジェクトには、プロジェクト、製品、またはサービスの商標またはロゴが含まれる場合があります。 Microsoftの商標およびロゴを正しく使用するには、Microsoftの商標&ブランドガイドラインに従う必要があります。混乱を引き起こしたり、Microsoftのスポンサーシップを暗示したりする方法で、このプロジェクトの変更されたバージョンでMicrosoftの商標またはロゴを使用しないでください。このプロジェクトに含まれるサードパーティの商標またはロゴのポリシーに従ってください。


