JARVIS ChatGPT
1.0.0
さまざまな合成声を装備した音声ベースのインタラクティブアシスタント(IronmanからのJarvisの声を含む)
 Midjourney AIによる画像
Midjourney AIによる画像
あなたの鎧を改善するためにハイパーインテリジェントなシステムのヒントを尋ねることを夢見たことはありませんか?今、あなたはできます!まあ、多分鎧の部分ではありません...このプロジェクトは、Openai Whisper、Openai ChatGpt、IBM Watsonを悪用します。
プロジェクトの動機:
多くの場合、アイデアは最悪の瞬間に来ており、あなたがそれらをよりよく探求する時間がある前に彼らは消え去ります。このプロジェクトの目的は、あなたが尋ねるものについては、準リアルタイムでヒントと意見を与えることができるシステムを開発することです。 Ultimate Assistantは、家や携帯電話内の任意の承認されたマイクからアクセスできるようになります。バックグラウンドで絶えず実行され、召喚されたときに意味のある回答(悪い音声で)を生成し、PCまたはサーバーとのインターフェースを生成し、後でアクセスできるファイルを保存/読み取り/書き込みファイルを作成できるはずです。研究を実行し、インターネットから資料を収集し(HTMLページからコンテンツを抽出し、YouTubeビデオを書き起こし、科学論文を見つけます...)、情報に基づいた決定を下すためにコンテキストとして使用できる要約を提供できるはずです。さらに、一部の外部ガジェット(IoT)とインターフェイスする可能性がありますが、それは追加です。
デモ:
研究モードの最初のドラフトをFinnalyを共有できます。このモダリティは、しばしば研究論文を扱う人々のために考えられていました。
PS:このモードは超安定しておらず、作業する必要があります
PPS:このプロジェクトは、2024年まで私の論文に取り組んでいるので、しばらくの間廃止されます。しかし、すでに改善できるものがたくさんあるので、戻ってきます!
免責事項:
このプロジェクトは、あなたのOpenaiクレジットを消費して、望ましくない請求になります。
私は不要な料金に対して責任を負いません。
OpenAIアカウントでクレジット消費の制限を設定することを検討してください。
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117 );あなたはあなたのためにほとんどのことをする新しい
setup.batに頼ることができます。
実行する必要があるメインスクリプト: openai_api_chatbot.pyデモフォルダー内で最新バージョンのopenai APIを使用する場合は、プロジェクトで使用されるパッケージのガイダンスが見つかります。最初にこれらのファイルをチェックして問題をターゲットにする可能性があります。主にアシスタントフォルダーに保存されています: get_audio.pyすべての機能を保存してマイクの相互作用を処理するために、 tools.py voice.pyします。 Agents.pyシステムのLangchain部分を処理します(ここでは、エージェントのツールキットからツールを追加または削除できます)
残りのスクリプトは音声生成に補足されており、編集しないでください。
Windows/Linuxで実行されている場合は、 setup.batを実行できます。スクリプトは、手動インストールのすべてのステップを順番に実行します。手順が失敗した場合に備えて、それらを参照してください。
自動インストールでは、Vicunaインストール(Vicunaインストールガイド)も実行されます
pip install -r venv_requirements.txt ;これには時間がかかるかもしれません。特定のパッケージで競合に遭遇した場合は、 ==<version>なしで手動でインストールします。whisper_editsフォルダー(。 venv lib site-packages whisper )にコピーして貼り付けますwhisperdemos/tts_demo.pyを実行できます)。 cd Vicuna
call vicuna.ps1
env.txtファイルにすべてのキーを貼り付け、 .envに名前を変更します(はい、txt拡張子を削除します)torch.cuda.is_available()およびtorch.cuda.get_device_name(0)実行することにより、pytorchと互換性があることを確認します。 。tests.pyを実行します。このファイルは、エラーを引き起こす可能性のある基本操作を実行しようとします。VirtualAssistant.__init__()内の言語を追加または変更します。 
whisper_model = whisper.load_model("large")の__main__()のより大きなものにアップグレードします。しかし、私はあなたのGPUメモリが同様に大きいことを願っています。 openai_api_chatbot.py ):実行中は、多くの情報が表示されていることがわかります。私は実行の読みやすさを改善するために常に努力しています。プロジェクト全体は大きなベータ版であり、以下の画面からのわずかなバリエーションを許しています。とにかく、これはあなたが「run」を押すときに一般的に起こることです:
Jarvis言う必要があります。この時点で、会話が開始され、必要な言語で話すことができます(ステップ2に従った場合)。会話は1)ストップワード2)1つの単語(「OK」など)3)を30秒以上停止するときに何かを言うときに終了します
chat_historyを展開し、APIでリクエストを送信し、chatgptから完全な回答を受け取るとすぐに履歴を更新します(これには最大5〜10秒かかる場合があります。急いでいる場合は短い回答を明示的に尋ねることを検討してください)。say()関数は、ジャービス/誰かの声と話すために声の複製を実行します。引数が英語でない場合、IBM Watsonは彼らの素敵なテキストからスピーチへのモデルの1つから応答を送信します。すべてが失敗した場合、関数はPyttsx3に依存します。これは高速でありながらクールな代替手段ではありません。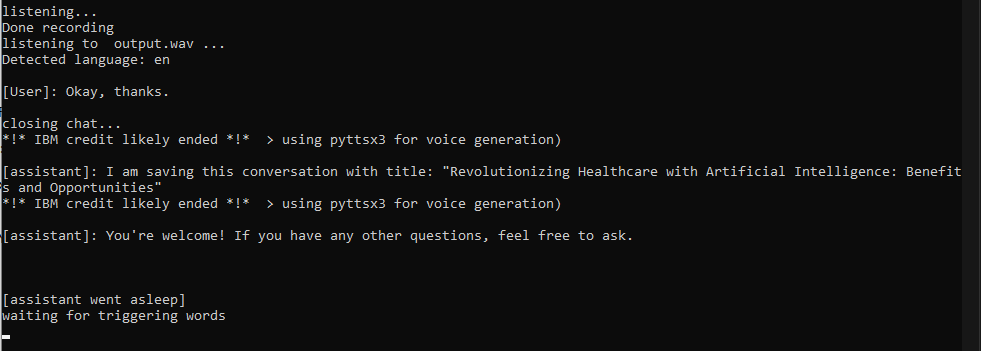
私はいくつかのプロンプトを作り、会話を閉じました
理想的ではありませんが、今のところ機能しています
VirtualAssistantクラスを作成する現在作業:
続く:
より多くの洞察については、プロジェクトのupdatehistory.mdを確認してください。
楽しむ!
カテゴリ:インストール、一般、ランタイム
問題はささやきに関するものです。 pip install whisper-openaiで手動で再インストールする必要があります
pip install --upgrade openai 。要件はコミットごとに更新されません。これによりエラーが生成される可能性がありますが、不足しているモジュールをすばやくインストールできます。同時に、新しいパッケージを試してみると、環境を競合から清潔に保つことができます(そして、私はそれらをたくさん試してみます)
これは、選択したモデルがCUDAデバイスメモリには大きすぎることを意味します。残念ながら、小さなモデルをロードする以外にできることはあまりありません。小規模なモデルがあなたを満足させない場合は、「より明確」な話をしたり、モデルに言っていることをより正確に予測できるようにするために、より長いプロンプトを作成したい場合があります。これは不便に聞こえますが、私の場合、私の英語を話すことを大幅に改善しました:)
これはまだ存在しているバグです。アシスタントとの長い会話があることを期待しないでください。修正は開発中であり、「スライド式のウィンドウ」アプローチを採用することで構成されている可能性があります。
今(2023年4月)私はこれについてほとんどノンストップで働いています。私は私の論文に取り組んでいるので、私はおそらく夏に休憩を取るでしょう。
質問がある場合は、問題を提起することで私に連絡することができ、できるだけ早く支援するために最善を尽くします。
Gianmarco Guarnier


