Deep RL Keras
1.0.0
Kerasの一般的なディープ補強学習アルゴリズムのモジュラー実装:
この実装には、Keras 2.1.6とOpenaiジムが必要です。
$ pip install gym keras==2.1.6アクターcriticアルゴリズムは、批評家が値関数近似として機能するモデルフリーでポリックオフポリティの方法であり、アクターはポリシー機能近似値として機能します。訓練するとき、批評家はTD-Errorを予測し、それ自体と俳優の両方の学習を導きます。実際には、Advantage関数を使用してTD-Errorに近似します。より安定性のために、両方のネットワークにわたって共有計算バックボーンと、割引報酬のN-STEP定式化を使用します。また、探索を促進するために、エントロピー正規化項(「ソフト」学習)を組み込みます。 A2Cはシンプルで効率的ですが、Atariゲームで実行することは、計算時間が長いためすぐに手に負えないものになります。
A2Cアルゴリズムと同様の方法で、A3Cの実装には非同期重量の更新が組み込まれているため、計算がはるかに高速になります。複数のエージェントを使用して、複数のスレッドで勾配上昇を非同期に実行します。 Atariブレイクアウト環境でA3Cをテストします。
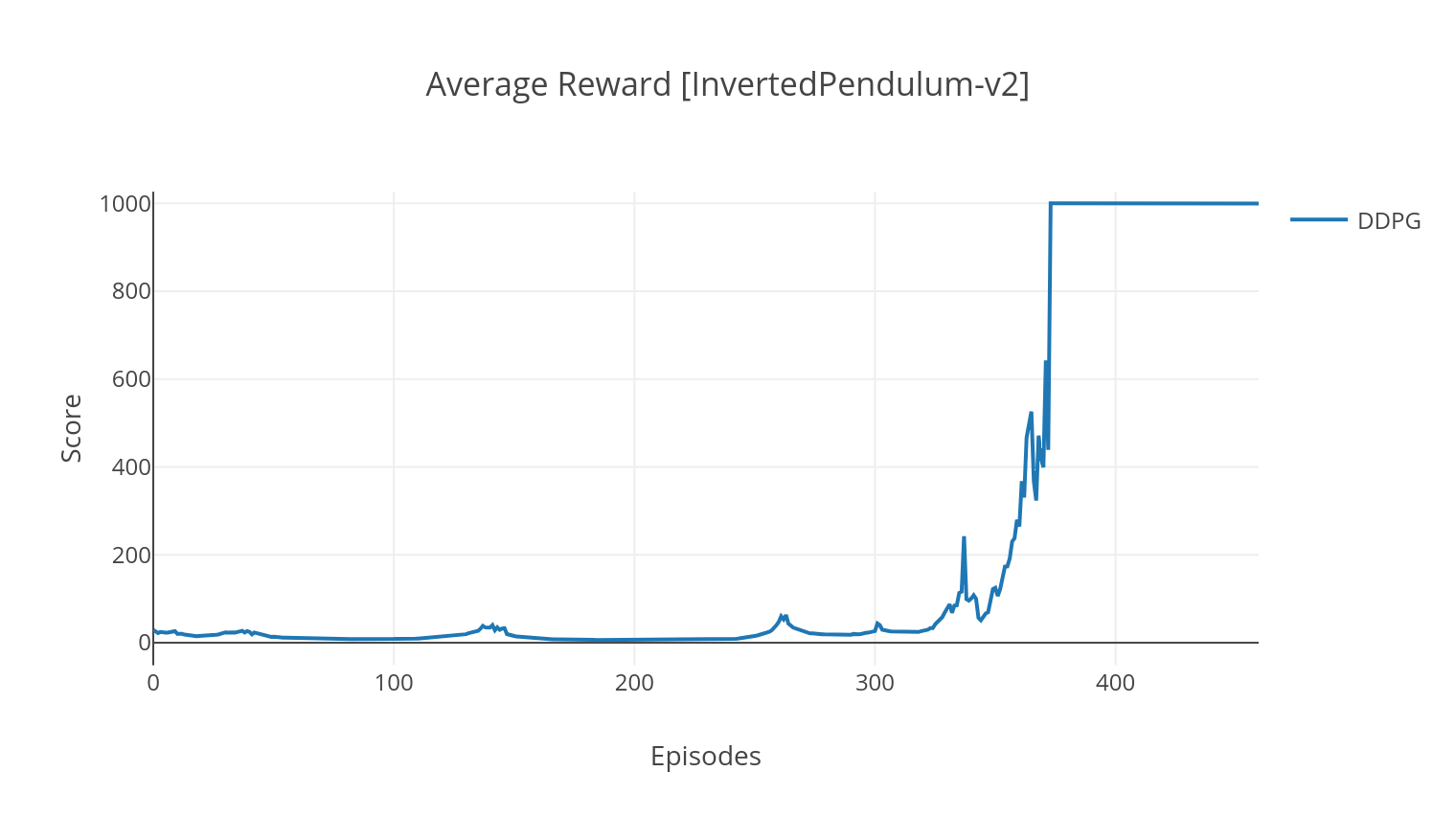
DDPGアルゴリズムは、連続的なアクションスペースのモデルフリーでオフポリシーアルゴリズムです。 A2Cと同様に、これはアクターと批判的なアルゴリズムであり、アクターが決定論的ターゲットポリシーについて訓練され、批評家はQ値を予測します。分散を減らして安定性を高めるために、エクスペリエンスリプレイと個別のターゲットネットワークを使用します。さらに、Openaiによって示唆されているように、パラメータースペースノイズを介した探索をお勧めします(従来のアクションスペースノイズとは対照的に)。月面環境でDDPGをテストします。
$ python3 main.py --type A2C --env CartPole-v1
$ python3 main.py --type A3C --env CartPole-v1 --nb_episodes 10000 --n_threads 16
$ python3 main.py --type A3C --env BreakoutNoFrameskip-v4 --is_atari --nb_episodes 10000 --n_threads 16
$ python3 main.py --type DDPG --env LunarLanderContinuous-v2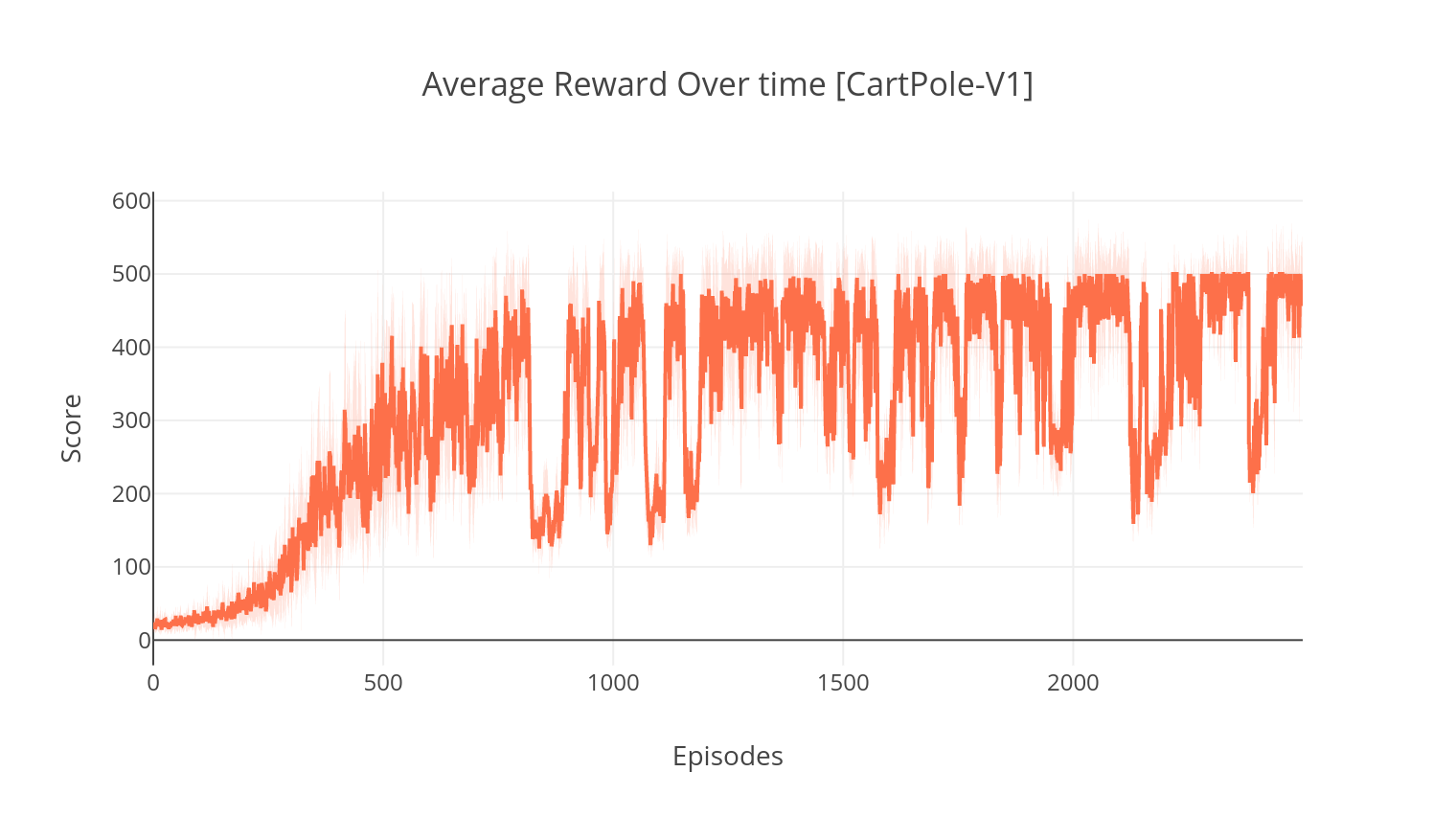
DQNアルゴリズムはQラーニングアルゴリズムであり、深いニューラルネットワークをQ値関数近似器として使用します。 Bellman方程式を活用することにより、ターゲットQ値を推定し、Epsilon-Greedyポリシーを通じて経験を収集します。より安定性のために、過去の経験をランダムにサンプリングします(リプレイを経験します)。 DQNアルゴリズムのバリアントは、Double-DQN(またはDDQN)です。 Q値をより正確に推定するために、2番目のネットワークを使用して、元のネットワークによるQ値の過大評価を緩和します。このターゲットネットワークは、すべてのトレーニングステップで、より遅いレートタウで更新されます。
優先順位付けされたエクスペリエンスリプレイ(PER)を追加することにより、DDQNアルゴリズムをさらに改善できます。このエクスペリエンスはTD-Errorによってランク付けされ、Sumtree構造に保存されているため、最高のエラーで(s、a、r、s ')遷移の効率的な検索が可能になります。
DQNの決闘バリアントでは、Qネットワークに中間層を組み込み、状態値と状態依存のアドバンテージ関数の両方を推定します。再編成後(参照を参照)、推定されたQ値を状態値として表現できることがわかります。状態に依存しない値と状態依存の値のこの要因化は、アクション全体で学習を解き放ち、より良い結果をもたらすのに役立ちます。
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64 --with_PER
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64 --dueling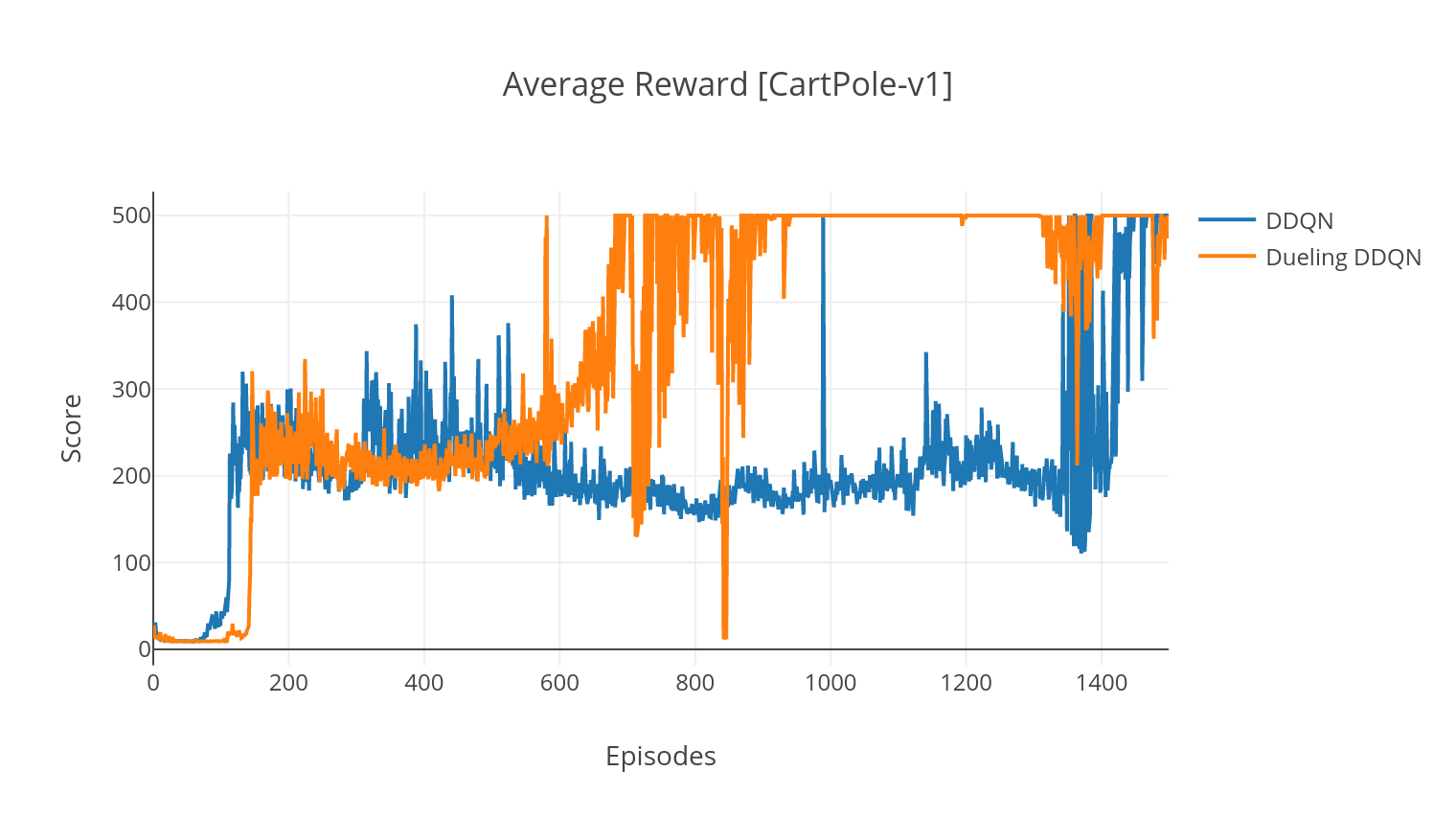
| 口論 | 説明 | 値 |
|---|---|---|
| - タイプ | 実行するRLアルゴリズムのタイプ | {a2c、a3c、ddqn、ddpg}から選択 |
| -ENV | 環境を指定します | breakoutnoframeskip-v4(デフォルト) |
| -NB_EPISODES | 実行するエピソードの数 | 5000(デフォルト) |
| -batch_size | バッチサイズ(DDQN、DDPG) | 32(デフォルト) |
| -Consecutive_frames | 積み重ねられた連続フレームの数 | 4(デフォルト) |
| -is_atari | 環境がピクセル入力を備えたAtariゲームであるかどうか | - |
| -with_per | 優先順位のあるエクスペリエンスリプレイを使用するかどうか(DDQNを使用) | - |
| - 婚約 | 決闘ネットワークを使用するかどうか(DDQNを使用) | - |
| -n_threads | スレッド数(A3c) | 16(デフォルト) |
| -gather_stats | 平均10ゲームを超えるスコアの統計を計算するかどうか(遅い、以下を参照) | - |
| - 与える | トレーニングであるため、環境をレンダリングするかどうか | - |
| -GPU | GPUインデックス | 0 |
すべてのモデルは、トレーニングが終了したときに<algorithm_folder>/models/の下に保存されます。 load_and_run.pyスクリプトを実行することにより、訓練された同じ環境で実行されている視覚化できます。 DQNモデルの場合、 --model_path引数で目的のモデルへのパスを指定する必要があります。 Actor-Criticモデルの場合、 --actor_pathおよび--critic_path引数で両方の重量ファイルを指定する必要があります。
Tensorboardを使用すると、トレーニング中にエージェントのスコアを監視できます。トレーニングするとき、選択した環境に一致する名前のログフォルダーが作成されます。たとえば、CartPole-V1のA2C進行に従うには、単に実行します。
$ tensorboard --logdir=A2C/tensorboard_CartPole-v1/引数--gather_statsでトレーニングするとき、すべてのエピソードで10ゲームを超えるスコアを含むログファイルが生成されます: logs.csv 。 Plotlyを使用すると、エピソードごとの平均報酬を視覚化できます。そのためには、最初にプロットをインストールして無料ライセンスを取得する必要があります。
pip3 install plotly資格情報を設定するには、実行してください。
import plotly
plotly . tools . set_credentials_file ( username = '<your_username>' , api_key = '<your_key>' )最後に、結果をプロットするには、実行してください。
python3 utils/plot_results.py < path_to_your_log_file >

