lang2sql
1.0.0
このレポは、OPNEAI APIを使用してSQLコードジェネレーターに自然言語をセットアップするための段階的なガイドとテンプレートを提供します。
チュートリアルはMediumでも利用できます。
最終更新:2024年1月7日
自然言語モデル、特に大規模な言語モデル(LLM)の急速な発展は、さまざまな分野に多くの可能性を提示しています。最も一般的なアプリケーションの1つは、コーディングにLLMSを使用することです。たとえば、OpenaiのChatGptとMetaのコードLlamaは、コードジェネレーターに最先端の自然言語を提供するLLMです。潜在的なユースケースの1つは、SQLコードジェネレーターの自然言語です。これは、非技術的な専門家が単純なデータ要求で支援し、データチームがより多くのデータ集約型タスクに集中できるようにすることを願っています。このチュートリアルは、OpenAI APIを使用してSQLコードジェネレーターの言語の設定に焦点を当てています。
可能なアプリケーションの1つは、関連するデータを使用してユーザークエリに応答できるチャットボットです(図1)。チャットボットは、次の手順を実行するPythonアプリケーションを使用して、Slackチャネルと統合できます。
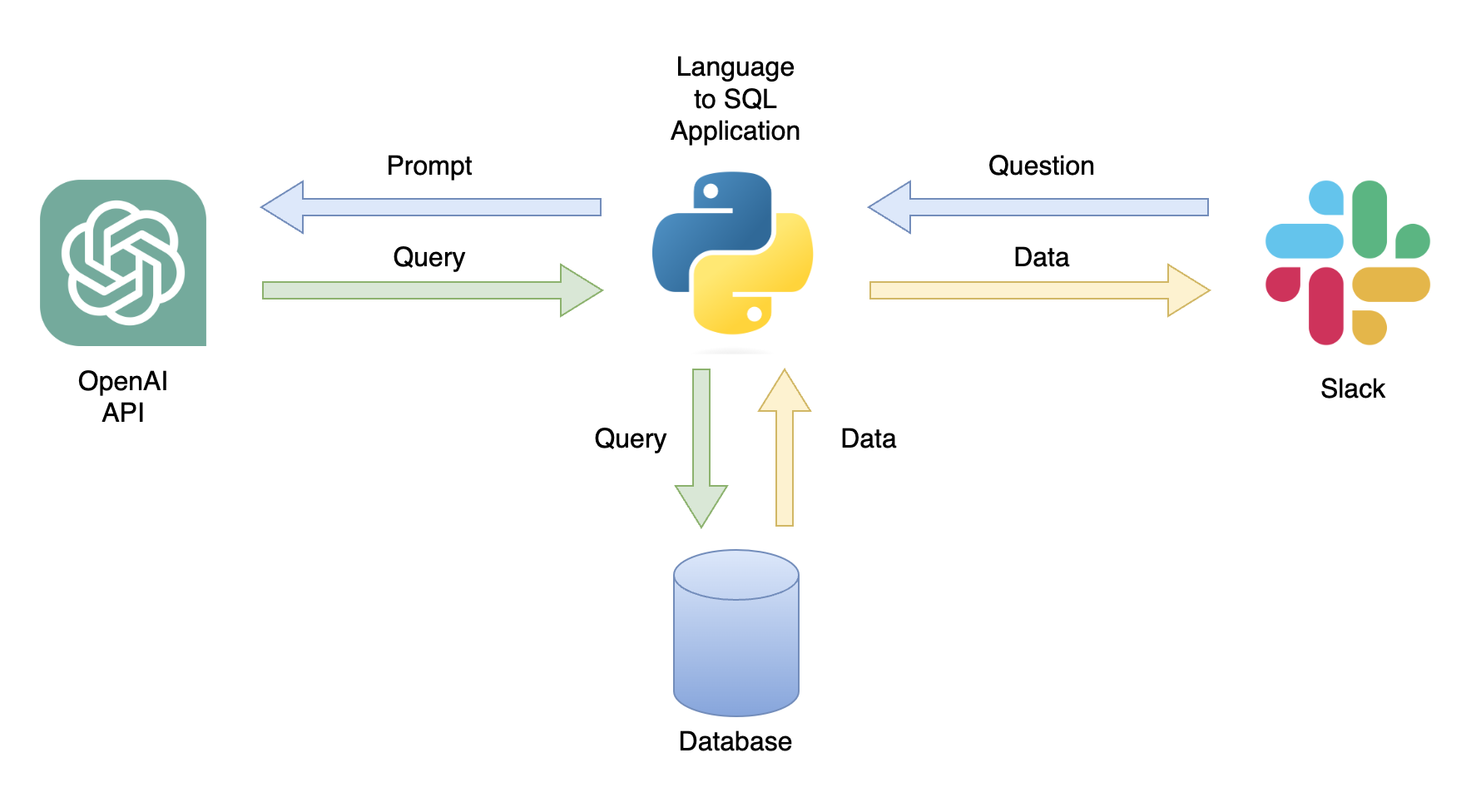
このチュートリアルでは、ユーザーの質問をSQLクエリに変換するステップバイステップPythonアプリケーションを構築します。
このチュートリアルでは、OpenAI APIを使用して一般的な質問をSQLクエリに変換するPythonアプリケーションを設定する方法に関する段階的なガイドを提供します。これには、次の機能が含まれます。
以下の図2は、SQLコードジェネレーターに対する単純な言語の一般的なアーキテクチャについて説明しています。
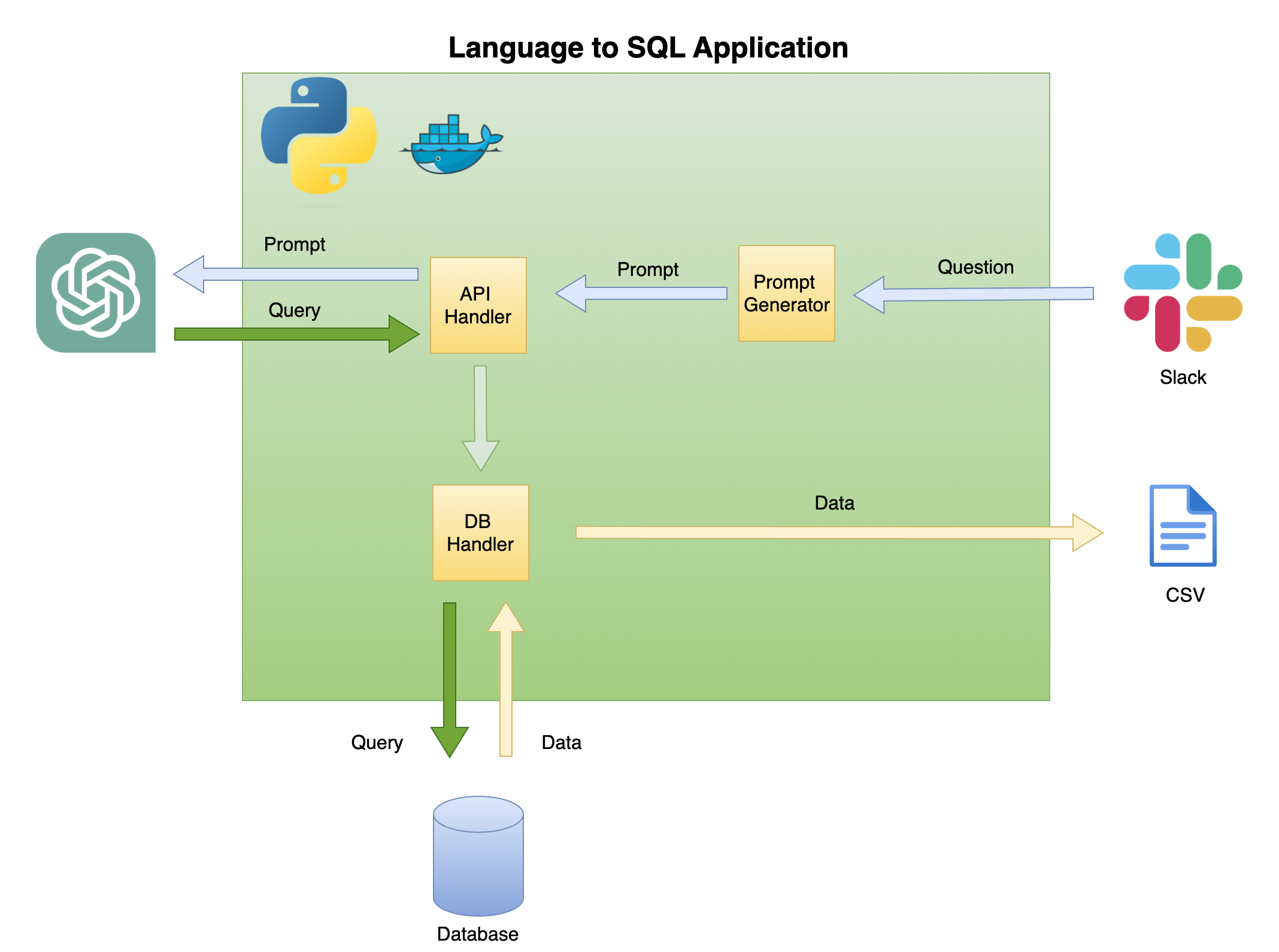
このチュートリアルの範囲と焦点は、グリーンボックスにあります - 次の機能を構築します。
迅速な質問- 質問をプロンプト形式に変換します。
APIハンドラー- Openai APIで動作する関数:
DBハンドラー- SQLクエリをデータベースに送信し、必要なデータを返す関数
このチュートリアルの主な前提条件は、Pythonの基本的な知識です。これには、次の機能が含まれます。
さらに、SQLの基本的な知識とOpenai APIへのアクセスが必要です。
必要ではありませんが、VSCodeの開発コンテナ拡張を使用してチュートリアルがDockerized環境で作成されたため、Dockerの基本的な知識を持つことが役立ちます。 Dockerや拡張機能の経験がない場合でも、仮想環境を作成して必要なライブラリをインストールすることでチュートリアルを実行できます(以下に説明します)。迅速なエンジニアリングとOpenai APIの知識も有益です。
VSCODEと開発者コンテナ拡張機能を使用して、Python Dockerized環境の設定に関する詳細なチュートリアルを作成しました。
https://github.com/ramikrispin/vscode-python
SQLコード生成に自然言語を設定するには、次のPythonライブラリを使用します。
pandasプロセス全体でデータを処理するduckdbデータベースで作業をシミュレートするopenai Openai APIを使用するtimeとos CSVファイルとフォーマットフィールドをロードするこのリポジトリには、VSCodeと開発コンテナ拡張のチュートリアル要件を備えたDockerized環境を起動するために必要な設定が含まれています。詳細については、次のセクションをご覧ください。
または、仮想環境を使用して以下の手順に従って、仮想環境セクションの指示を使用して、仮想環境を設定してチュートリアル要件をインストールすることもできます。
このチュートリアルは、VSCODEとDEVコンテナの拡張機能を備えたDocKerized環境内に構築されました。 VSCODEで実行するには、Dev Containers Extensionをインストールし、Dockerデスクトップ(または同等)を開く必要があります。環境の設定は、 .devcontainerフォルダーで使用できます。
.── .devcontainer
├── Dockerfile
├── Dockerfile.dev
├── devcontainer.json
├── install_dependencies_core.sh
├── install_dependencies_other.sh
├── install_quarto.sh
├── requirements_core.txt
├── requirements_openai.txt
└── requirements_transformers.txt
devcontainer.jsonは、このドキュカ化された環境のビルド命令とVSCODE設定があります。
{
"name" : " lang2sql " ,
"build" : {
"dockerfile" : " Dockerfile " ,
"args" : {
"ENV_NAME" : " lang2sql " ,
"PYTHON_VER" : " 3.10 " ,
"METHOD" : " openai " ,
"QUARTO_VER" : " 1.3.450 "
},
"context" : " . "
},
"customizations" : {
"settings" : {
"python.defaultInterpreterPath" : " /opt/conda/envs/lang2sql/bin/python " ,
"python.selectInterpreter" : " /opt/conda/envs/lang2sql/bin/python "
},
"vscode" : {
"extensions" : [
" quarto.quarto " ,
" ms-azuretools.vscode-docker " ,
" ms-python.python " ,
" ms-vscode-remote.remote-containers " ,
" yzhang.markdown-all-in-one " ,
" redhat.vscode-yaml " ,
" ms-toolsai.jupyter "
]
}
},
"remoteEnv" : {
"OPENAI_KEY" : " ${localEnv:OPENAI_KEY} "
}
}
ここで、 build引数がdocker buildメソッドを定義し、ビルドの引数を設定します。この場合、Pythonバージョンを3.10に、Conda Virtual Environmentをang2sqlに設定します。 METHOD引数は、環境のタイプを定義します - openaiは、OpenAI APIを使用してこのチュートリアルの要件ライブラリをインストールするか、 transformersを使用してHuggingFaces APIの環境を設定します(このチュートリアルの範囲外です)。
remoteEnv引数により、環境変数の設定が可能になります。それを使用して、Openai APIキーを設定します。この場合、変数をOPENAI_KEYとしてローカルに設定し、 localEnv引数を使用してロードしています。
VSCODEとDockerを使用してPython開発環境のセットアップについて詳しく知りたい場合は、このチュートリアルを確認してください。
チュートリアルドキュカ化環境を使用していない場合は、以下のスクリプトを使用してコマンドラインからローカル仮想環境を作成できます。
ENV_NAME=openai_api
PYTHON_VER=3.10
conda create -y --name $ENV_NAME python= $PYTHON_VER
conda activate $ENV_NAME
pip3 install -r ./.devcontainer/requirements_core.txt
pip3 install -r ./.devcontainer/requirements_openai.txt
注:私はcondaを使用しましたが、他のウイルタ環境法でも同様に機能するはずです。
ENV_NAMEおよびPYTHON_VER変数を使用して、それぞれ仮想環境とpythonバージョンを設定します。
環境が適切に設定されていることを確認するには、 conda listを使用して、必要なPythonライブラリがインストールされていることを確認します。以下の出力を期待する必要があります。
(openai_api) root@0ca5b8000cd5:/workspaces/lang2sql# conda list
# packages in environment at /opt/conda/envs/openai_api:
#
# Name Version Build Channel
_libgcc_mutex 0.1 main
_openmp_mutex 5.1 51_gnu
aiohttp 3.9.0 pypi_0 pypi
aiosignal 1.3.1 pypi_0 pypi
asttokens 2.4.1 pypi_0 pypi
async-timeout 4.0.3 pypi_0 pypi
attrs 23.1.0 pypi_0 pypi
bzip2 1.0.8 hfd63f10_2
ca-certificates 2023.08.22 hd43f75c_0
certifi 2023.11.17 pypi_0 pypi
charset-normalizer 3.3.2 pypi_0 pypi
comm 0.2.0 pypi_0 pypi
contourpy 1.2.0 pypi_0 pypi
cycler 0.12.1 pypi_0 pypi
debugpy 1.8.0 pypi_0 pypi
decorator 5.1.1 pypi_0 pypi
duckdb 0.9.2 pypi_0 pypi
exceptiongroup 1.2.0 pypi_0 pypi
executing 2.0.1 pypi_0 pypi
fonttools 4.45.1 pypi_0 pypi
frozenlist 1.4.0 pypi_0 pypi
gensim 4.3.2 pypi_0 pypi
idna 3.5 pypi_0 pypi
ipykernel 6.26.0 pypi_0 pypi
ipython 8.18.0 pypi_0 pypi
jedi 0.19.1 pypi_0 pypi
joblib 1.3.2 pypi_0 pypi
jupyter-client 8.6.0 pypi_0 pypi
jupyter-core 5.5.0 pypi_0 pypi
kiwisolver 1.4.5 pypi_0 pypi
ld_impl_linux-aarch64 2.38 h8131f2d_1
libffi 3.4.4 h419075a_0
libgcc-ng 11.2.0 h1234567_1
libgomp 11.2.0 h1234567_1
libstdcxx-ng 11.2.0 h1234567_1
libuuid 1.41.5 h998d150_0
matplotlib 3.8.2 pypi_0 pypi
matplotlib-inline 0.1.6 pypi_0 pypi
multidict 6.0.4 pypi_0 pypi
ncurses 6.4 h419075a_0
nest-asyncio 1.5.8 pypi_0 pypi
numpy 1.26.2 pypi_0 pypi
openai 0.28.1 pypi_0 pypi
openssl 3.0.12 h2f4d8fa_0
packaging 23.2 pypi_0 pypi
pandas 2.0.0 pypi_0 pypi
parso 0.8.3 pypi_0 pypi
pexpect 4.8.0 pypi_0 pypi
pillow 10.1.0 pypi_0 pypi
pip 23.3.1 py310hd43f75c_0
platformdirs 4.0.0 pypi_0 pypi
prompt-toolkit 3.0.41 pypi_0 pypi
psutil 5.9.6 pypi_0 pypi
ptyprocess 0.7.0 pypi_0 pypi
pure-eval 0.2.2 pypi_0 pypi
pygments 2.17.2 pypi_0 pypi
pyparsing 3.1.1 pypi_0 pypi
python 3.10.13 h4bb2201_0
python-dateutil 2.8.2 pypi_0 pypi
pytz 2023.3.post1 pypi_0 pypi
pyzmq 25.1.1 pypi_0 pypi
readline 8.2 h998d150_0
requests 2.31.0 pypi_0 pypi
scikit-learn 1.3.2 pypi_0 pypi
scipy 1.11.4 pypi_0 pypi
setuptools 68.0.0 py310hd43f75c_0
six 1.16.0 pypi_0 pypi
smart-open 6.4.0 pypi_0 pypi
sqlite 3.41.2 h998d150_0
stack-data 0.6.3 pypi_0 pypi
threadpoolctl 3.2.0 pypi_0 pypi
tk 8.6.12 h241ca14_0
tornado 6.3.3 pypi_0 pypi
tqdm 4.66.1 pypi_0 pypi
traitlets 5.13.0 pypi_0 pypi
tzdata 2023.3 pypi_0 pypi
urllib3 2.1.0 pypi_0 pypi
wcwidth 0.2.12 pypi_0 pypi
wheel 0.41.2 py310hd43f75c_0
xz 5.4.2 h998d150_0
yarl 1.9.3 pypi_0 pypi
zlib 1.2.13 h998d150_0
Openai APIを使用して、Text-Davinci-003エンジンを使用してChatGPTにアクセスします。これには、アクティブなOpenAIアカウントとAPIキーが必要でした。以下のリンクの指示に従ってアカウントとAPIキーを設定するのは簡単です。
https://openai.com/product
APIとキーへのアクセスを設定したら、環境変数としてキーを.zshrcファイル(またはシェルシステムに環境変数を保存するために使用している他の形式)に追加することをお勧めします。 APIキーをOPENAI_KEY Environment変数の下に保存しました。説得力のある理由から、同じ命名規則を使用することをお勧めします。
.zshrcファイル(または同等)に変数を設定するには、以下の行をファイルに追加します。
export OPENAI_KEY= " YOUR_API_KEY " vscodeを使用している場合、またはターミナルから実行している場合は、 .zshrcファイルに変数を追加した後、セッションを再起動する必要があります。
データベース機能をシミュレートするために、シカゴ犯罪データセットを利用します。このデータセットは、2001年以来シカゴ市で記録された犯罪に関する詳細な情報を提供します。800万近くの記録と22列を備えたデータセットには、犯罪分類、場所、時間、結果などの情報が含まれています。データはChicagoデータポータルからダウンロードできます。データをPandasデータフレームとしてローカルに保存し、DuckDBを使用してSQLクエリをシミュレートするため、過去3年間を使用してデータのサブセットをダウンロードします。
APIからデータをプルするか、CSVファイルをダウンロードできます。スクリプトを実行するたびにAPIを呼び出すことを避けるために、ファイルをダウンロードしてデータフォルダーの下に保存します。以下は、年ごとのデータセットへのリンクです。
データをダウンロードするには、右上のExportボタンを使用し、図4に示すように、 CSVオプションを選択し、[ Downloadボタンをクリックします。
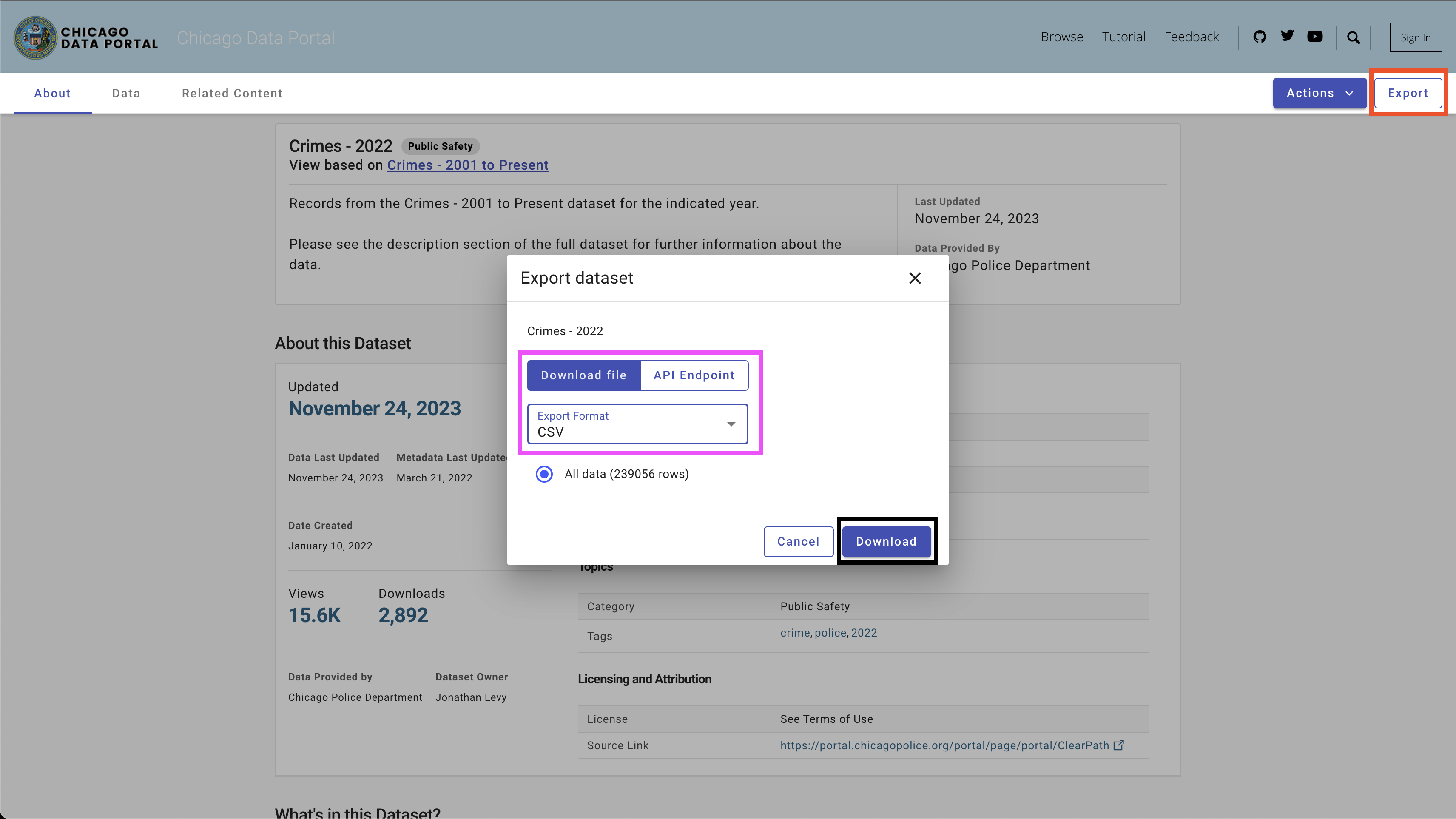
次のネーミング条約を使用しました-Chicago_crime_year.csvを使用して、 dataフォルダーにファイルを保存しました。各ファイルサイズは50 MBに近いです。したがって、それらをdataフォルダーの下のGIT Ingroreファイルに追加しましたが、このレポでは使用できません。ファイルをダウンロードして名前を設定した後、フォルダーに次のファイルを使用する必要があります。
| ── data
├── chicago_crime_2021.csv
├── chicago_crime_2022.csv
└── chicago_crime_2023.csv
注:このチュートリアルを作成する時点で、2023年のデータはまだ更新されています。したがって、次のセクションでクエリの一部を実行すると、わずかに異なる結果を受けることがあります。
SQLコードジェネレーターのセットアップであるエキサイティングな部分に進みましょう。このセクションでは、ユーザーの質問、関連するSQLテーブル、およびOpenAI APIキーを取り入れるPython関数を作成し、ユーザーの質問に答えるSQLクエリを出力します。
まず、Chicago Crime Datasetと必要なPythonライブラリを読み込むことから始めましょう。
まず最初に - 必要なPythonライブラリをロードしましょう。
import pandas as pd
import duckdb
import openai
import time
import osOSおよびTIMEライブラリを使用してCSVファイルをロードし、特定のフィールドを再フォーマットします。データはPandasライブラリを使用して処理され、 DuckDBライブラリでSQLコマンドをシミュレートします。最後に、 OpenAIライブラリを使用してOpenai APIへの接続を確立します。
次に、データフォルダーからCSVファイルをロードします。以下のコードは、データフォルダーで使用可能なすべてのCSVファイルを読み取ります。
path = "./data"
files = [ x for x in os . listdir ( path = path ) if ".csv" in x ]2021年から2023年に対応するファイルをダウンロードし、同じネーミング条約を使用した場合、次の出力を期待する必要があります。
print ( files )
[ 'chicago_crime_2022.csv' , 'chicago_crime_2023.csv' , 'chicago_crime_2021.csv' ]次に、すべてのファイルを読み取り、ロードし、パンダデータフレームに追加します。
chicago_crime = pd . concat (( pd . read_csv ( path + "/" + f ) for f in files ), ignore_index = True )
chicago_crime . headファイルを正しくロードした場合は、次の出力を期待する必要があります。
< bound method NDFrame . head of ID Case Number Date Block
0 12589893 JF109865 01 / 11 / 2022 03 : 00 : 00 PM 087 XX S KINGSTON AVE
1 12592454 JF113025 01 / 14 / 2022 03 : 55 : 00 PM 067 XX S MORGAN ST
2 12601676 JF124024 01 / 13 / 2022 04 : 00 : 00 PM 031 XX W AUGUSTA BLVD
3 12785595 JF346553 08 / 05 / 2022 09 : 00 : 00 PM 072 XX S UNIVERSITY AVE
4 12808281 JF373517 08 / 14 / 2022 02 : 00 : 00 PM 055 XX W ARDMORE AVE
... ... ... ... ...
648826 26461 JE455267 11 / 24 / 2021 12 : 51 : 00 AM 107 XX S LANGLEY AVE
648827 26041 JE281927 06 / 28 / 2021 01 : 12 : 00 AM 117 XX S LAFLIN ST
648828 26238 JE353715 08 / 29 / 2021 03 : 07 : 00 AM 010 XX N LAWNDALE AVE
648829 26479 JE465230 12 / 03 / 2021 08 : 37 : 00 PM 000 XX W 78 TH PL
648830 11138622 JA495186 05 / 21 / 2021 12 : 01 : 00 AM 019 XX N PULASKI RD
IUCR Primary Type
0 1565 SEX OFFENSE
1 2826 OTHER OFFENSE
2 1752 OFFENSE INVOLVING CHILDREN
3 1544 SEX OFFENSE
4 1562 SEX OFFENSE
... ... ...
648826 0110 HOMICIDE
648827 0110 HOMICIDE
648828 0110 HOMICIDE
648829 0110 HOMICIDE
648830 1752 OFFENSE INVOLVING CHILDREN
...
648828 41.899709 - 87.718893 ( 41.899709327 , - 87.718893208 )
648829 41.751832 - 87.626374 ( 41.751831742 , - 87.626373808 )
648830 41.915798 - 87.726524 ( 41.915798196 , - 87.726524412 ) 注:このチュートリアルを作成するとき、2023年の部分データが利用可能でした。 3つのファイルを追加すると、表示されるよりも多くの行(648830行)になります。
Pythonコードに入る前に、迅速なエンジニアリングがどのように機能するか、およびChatGPT(および一般的に任意のLLM)が最良の結果を生み出す方法を一時停止して確認しましょう。このセクションでは、ChatGPT Webインターフェイスを使用します。
統計および機械学習モデルの主要な要因の1つは、出力品質が入力品質に依存することです。有名なフレーズが言うように -ジャンクイン、ジャンクアウト。同様に、LLM出力の品質は、プロンプトの品質に依存します。
たとえば、逮捕で終わった症例の数を数えたいと思います。
次のプロンプトを使用する場合:
Create an SQL query that counts the number of records that ended up with an arrest.
ChatGptからの出力は次のとおりです。
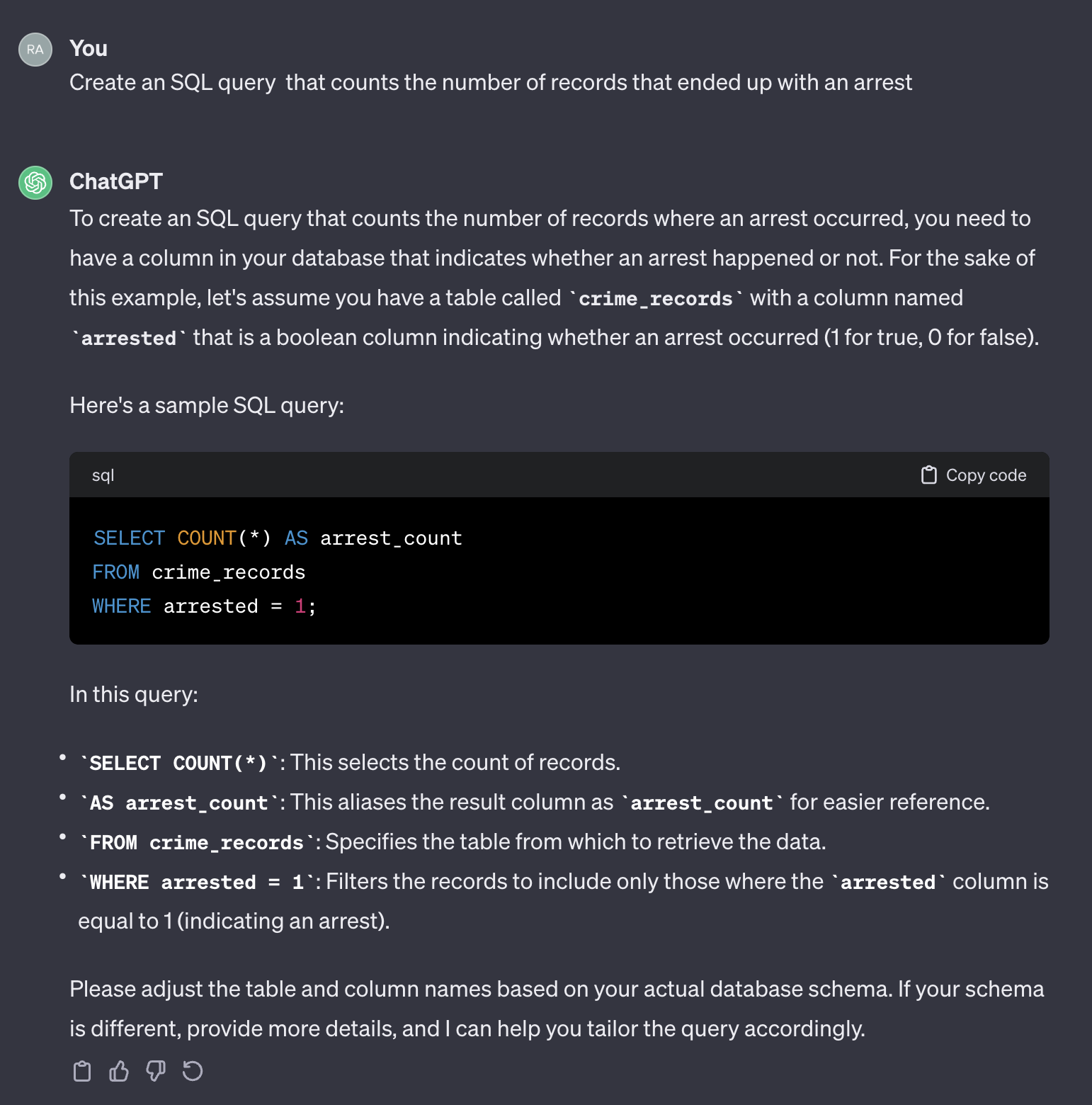
ChatGptが一般的な応答を提供することは注目に値します。一般的に正しいですが、自動化されたプロセスで使用することは実用的ではない場合があります。まず、応答のフィールド名は、クエリする必要がある実際のテーブルのフィールド名と一致しません。第二に、逮捕結果を表すフィールドは、整数( 0または1 )の代わりにブール( trueまたはfalse )です。
その意味で、ChatGptは人間のように振る舞います。 Stack Overflowやその他の同様のプラットフォームなどのコーディングフォームに同じ質問を投稿することにより、人間からより正確な答えを受け取ることはまずありません。テーブルの特性に関するコンテキストや追加情報を提供していないことを考えると、ChatGptがフィールド名とその価値を推測することを期待することは不合理です。コンテキストは、プロンプトの重要な要因です。この点を説明するために、ChATGPTが次のプロンプトをどのように処理するかを見てみましょう。
I have a table named chicago_crime with the crime records in Chicago City since 2021. The Arrest field defines if the case ended up with arrest or not, and it is a boolean (true or false).
I want to create an SQL query that counts the number of records that ended up with an arrest.
ChatGptからの出力は次のとおりです。
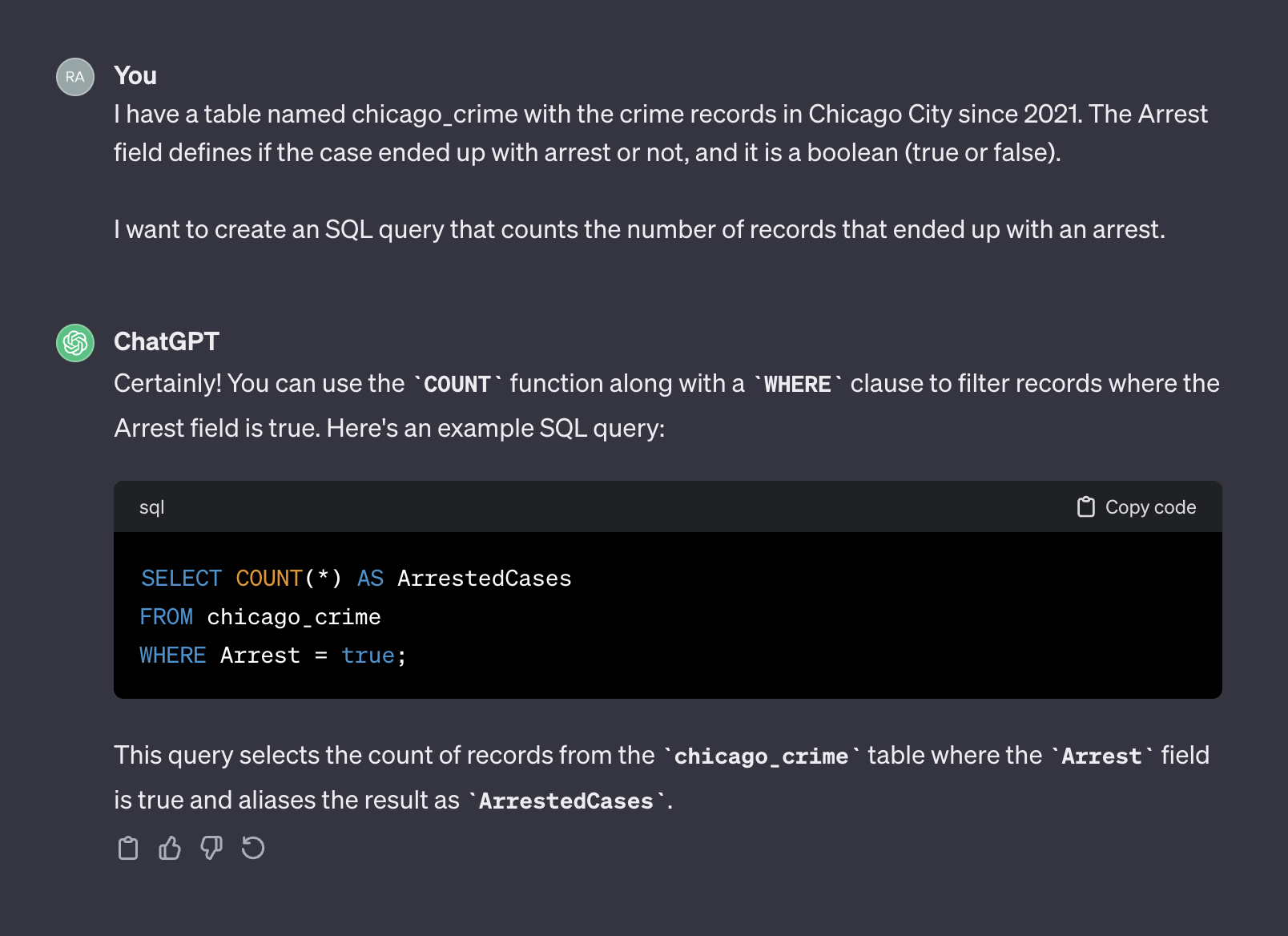
今回は、コンテキストを追加した後、ChatGPTはそのまま使用できる正しいクエリを返しました。一般に、テキストジェネレーターを使用する場合、プロンプトには、コンテキストとリクエストの2つのコンポーネントを含める必要があります。上記のプロンプトでは、最初の段落はプロンプトのコンテキストを表します。
I have a table named chicago_crime with the crime records in Chicago City since 2021. The Arrest field defines if the case ended up with arrest or not, and it is a boolean (true or false).
2番目の段落は、リクエストを表します。
I want to create an SQL query that counts the number of records that ended up with an arrest.
OpenAI APIは、コンテキストをsystemとして参照し、 userとしてリクエストします。
OpenAI APIドキュメントは、SQLコードを生成するように要求するときに、 systemとuserコンポーネントをプロンプトに設定する方法についての推奨事項を提供します。
System
Given the following SQL tables, your job is to write queries given a user’s request.
CREATE TABLE Orders (
OrderID int,
CustomerID int,
OrderDate datetime,
OrderTime varchar(8),
PRIMARY KEY (OrderID)
);
CREATE TABLE OrderDetails (
OrderDetailID int,
OrderID int,
ProductID int,
Quantity int,
PRIMARY KEY (OrderDetailID)
);
CREATE TABLE Products (
ProductID int,
ProductName varchar(50),
Category varchar(50),
UnitPrice decimal(10, 2),
Stock int,
PRIMARY KEY (ProductID)
);
CREATE TABLE Customers (
CustomerID int,
FirstName varchar(50),
LastName varchar(50),
Email varchar(100),
Phone varchar(20),
PRIMARY KEY (CustomerID)
);
User
Write a SQL query which computes the average total order value for all orders on 2023-04-01.
次のセクションでは、上記のOpenAI例を使用して、それを汎用テンプレートに一般化します。
前のセクションでは、迅速なエンジニアリングの重要性と、良好なコンテキストを提供することでLLM応答の精度をどのように改善できるかについて説明しました。さらに、SQLコード生成のためにOpenAIが推奨するプロンプト構造を見ました。このセクションでは、これらの原則に基づいてSQL生成のプロンプトを作成するプロセスを一般化することに焦点を当てます。目標は、テーブル名とユーザーの質問を受信し、それに応じてプロンプトを作成するPython関数を構築することです。たとえば、前にロードしたテーブルchicago_crimeテーブルの場合、前のセクションで尋ねた質問は、以下のプロンプトを作成する必要があります。
Given the following SQL table, your job is to write queries given a user’s request.
CREATE TABLE chicago_crime (ID BIGINT, Case Number VARCHAR, Date VARCHAR, Block VARCHAR, IUCR VARCHAR, Primary Type VARCHAR, Description VARCHAR, Location Description VARCHAR, Arrest BOOLEAN, Domestic BOOLEAN, Beat BIGINT, District BIGINT, Ward DOUBLE, Community Area BIGINT, FBI Code VARCHAR, X Coordinate DOUBLE, Y Coordinate DOUBLE, Year BIGINT, Updated On VARCHAR, Latitude DOUBLE, Longitude DOUBLE, Location VARCHAR)
Write a SQL query that returns - How many cases ended up with arrest?
迅速な構造から始めましょう。 OpenAI形式を採用し、次のテンプレートを使用します。
system_template = """
Given the following SQL table, your job is to write queries given a user’s request. n
CREATE TABLE {} ({}) n
"""
user_template = "Write a SQL query that returns - {}" system_template 2つの要素を受け取った場合:
このチュートリアルでは、DuckDBライブラリを使用して、SQLテーブルであるため、Pandasのデータフレームを処理し、 duckdb.sql関数を使用してテーブルのフィールド名と属性を抽出します。たとえば、 chicago_crimeテーブルフィールド情報を抽出するには、 DESCRIBE sqlコマンドを使用してみましょう。
duckdb . sql ( "DESCRIBE SELECT * FROM chicago_crime;" )以下の表を返すはずです。
┌──────────────────────┬─────────────┬─────────┬─────────┬─────────┬─────────┐
│ column_name │ column_type │ null │ key │ default │ extra │
│ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │
├──────────────────────┼─────────────┼─────────┼─────────┼─────────┼─────────┤
│ ID │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Case Number │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Date │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Block │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ IUCR │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Primary Type │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Description │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Location Description │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Arrest │ BOOLEAN │ YES │ NULL │ NULL │ NULL │
│ Domestic │ BOOLEAN │ YES │ NULL │ NULL │ NULL │
│ Beat │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ District │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Ward │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Community Area │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ FBI Code │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ X Coordinate │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Y Coordinate │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Year │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Updated On │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Latitude │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Longitude │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Location │ VARCHAR │ YES │ NULL │ NULL │ NULL │
├──────────────────────┴─────────────┴─────────┴─────────┴─────────┴─────────┤
│ 22 rows 6 columns │
└────────────────────────────────────────────────────────────────────────────┘注:必要な情報 - 列名とその属性は、最初の2つの列で使用できます。したがって、これらの列を解析し、次の形式に結合する必要があります。
Column_Name Column_Attribute
たとえば、 Case Number列は次の形式に転送する必要があります。
Case Number VARCHAR
以下のcreate_message関数は、上記のロジックを使用してテーブル名と質問を取得し、プロンプトを生成するプロセスを調整します。
def create_message ( table_name , query ):
class message :
def __init__ ( message , system , user , column_names , column_attr ):
message . system = system
message . user = user
message . column_names = column_names
message . column_attr = column_attr
system_template = """
Given the following SQL table, your job is to write queries given a user’s request. n
CREATE TABLE {} ({}) n
"""
user_template = "Write a SQL query that returns - {}"
tbl_describe = duckdb . sql ( "DESCRIBE SELECT * FROM " + table_name + ";" )
col_attr = tbl_describe . df ()[[ "column_name" , "column_type" ]]
col_attr [ "column_joint" ] = col_attr [ "column_name" ] + " " + col_attr [ "column_type" ]
col_names = str ( list ( col_attr [ "column_joint" ]. values )). replace ( '[' , '' ). replace ( ']' , '' ). replace ( ' ' ' , '' )
system = system_template . format ( table_name , col_names )
user = user_template . format ( query )
m = message ( system = system , user = user , column_names = col_attr [ "column_name" ], column_attr = col_attr [ "column_type" ])
return mこの関数は、プロンプトテンプレートを作成し、プロンプトsystemとuserコンポーネント、列名と属性を返します。たとえば、逮捕質問の数を実行しましょう。
query = "How many cases ended up with arrest?"
msg = create_message ( table_name = "chicago_crime" , query = query )これは戻ります:
print ( msg . system )
Given the following SQL table , your job is to write queries given a user ’ s request .
CREATE TABLE chicago_crime ( ID BIGINT , Case Number VARCHAR , Date VARCHAR , Block VARCHAR , IUCR VARCHAR , Primary Type VARCHAR , Description VARCHAR , Location Description VARCHAR , Arrest BOOLEAN , Domestic BOOLEAN , Beat BIGINT , District BIGINT , Ward DOUBLE , Community Area BIGINT , FBI Code VARCHAR , X Coordinate DOUBLE , Y Coordinate DOUBLE , Year BIGINT , Updated On VARCHAR , Latitude DOUBLE , Longitude DOUBLE , Location VARCHAR )
print ( msg . user )
Write a SQL query that returns - How many cases ended up with arrest ?
print ( msg . column_names )
0 ID
1 Case Number
2 Date
3 Block
4 IUCR
5 Primary Type
6 Description
7 Location Description
8 Arrest
9 Domestic
10 Beat
11 District
12 Ward
13 Community Area
14 FBI Code
15 X Coordinate
16 Y Coordinate
17 Year
18 Updated On
19 Latitude
20 Longitude
21 Location
Name : column_name , dtype : object
print ( msg . column_attr )
0 BIGINT
1 VARCHAR
2 VARCHAR
3 VARCHAR
4 VARCHAR
5 VARCHAR
6 VARCHAR
7 VARCHAR
8 BOOLEAN
9 BOOLEAN
10 BIGINT
11 BIGINT
12 DOUBLE
13 BIGINT
14 VARCHAR
15 DOUBLE
16 DOUBLE
17 BIGINT
18 VARCHAR
19 DOUBLE
20 DOUBLE
21 VARCHAR
Name : column_type , dtype : object create_message関数の出力は、OpenAI API ChatCompletion.create関数引数に適合するように設計されています。これについては、次のセクションで確認します。
このセクションでは、Openai Pythonライブラリの機能に焦点を当てています。 Openaiライブラリは、Openai Rest APIへのシームレスなアクセスを可能にします。ライブラリを使用してAPIに接続し、プロンプトでGet Requestsを送信します。
APIをopenai.api_key関数に送信して、APIに接続することから始めましょう。
openai . api_key = os . getenv ( 'OPENAI_KEY' )注: osライブラリのgetenv関数を使用して、OpenAI_Key Environment変数をロードしました。または、APIキーを直接フィードすることもできます。
openai . api_key = "YOUR_OPENAI_API_KEY"OpenAI APIは、異なる機能を備えたさまざまなLLMへのアクセスを提供します。 Openai.model.list関数を使用して、利用可能なモデルのリストを取得できます。
openai . Model . list ()それを素敵な形式に変換するには、 pandasデータフレームに包むことができます。
openai_api_models = pd . DataFrame ( openai . Model . list ()[ "data" ])
openai_api_models . head次の出力を期待する必要があります。
<bound method NDFrame.head of id object created owned_by
0 text-search-babbage-doc-001 model 1651172509 openai-dev
1 gpt-4 model 1687882411 openai
2 curie-search-query model 1651172509 openai-dev
3 text-davinci-003 model 1669599635 openai-internal
4 text-search-babbage-query-001 model 1651172509 openai-dev
.. ... ... ... ...
65 gpt-3.5-turbo-instruct-0914 model 1694122472 system
66 dall-e-2 model 1698798177 system
67 tts-1-1106 model 1699053241 system
68 tts-1-hd-1106 model 1699053533 system
69 gpt-3.5-turbo-16k model 1683758102 openai-internal
[70 rows x 4 columns]>
ユースケースであるテキスト生成については、GPT3モデルの改善であるgpt-3.5-turboモデルを使用します。 gpt-3.5-turboモデルは、更新され続ける一連のモデルを表します。デフォルトでは、モデルバージョンが指定されていない場合、APIは最新の安定したリリースを指摘します。このチュートリアルを作成するとき、デフォルトの3.5モデルは4,096トークンを使用してgpt-3.5-turbo-0613であり、2021年9月までのデータでトレーニングされました。
プロンプトでGETリクエストを送信するには、 ChatCompletion.create関数を使用します。この関数には多くの議論があり、次の議論を使用します。
model - 使用するモデルID、こちらから入手可能な完全なリストmessages - これまでの会話を含むメッセージのリスト(たとえば、プロンプト)temperature - サンプリング温度レベルを設定することにより、プロセス出力のランダム性または決定論を管理します。温度レベルは0〜2の値を受け入れます。引数値が高くなると、出力がよりランダムになります。逆に、引数値が0に近づくと、出力がより決定的になります(再現性)max_tokens完了時に生成するトークンの最大数API DocumentAitonで利用可能な関数引数の完全なリスト。
以下の例では、APIを使用して、ChatGPT Webインターフェイス(つまり、図5)で使用されているプロンプトと同じプロンプトを使用します。 create_message関数を使用してプロンプトを生成します。
query = "How many cases ended up with arrest?"
prompt = create_message ( table_name = "chicago_crime" , query = query )上記のプロンプトmessages ChatCompletion.createの構造に変換しましょう。
message = [
{
"role" : "system" ,
"content" : prompt . system
},
{
"role" : "user" ,
"content" : prompt . user
}
]次に、 ChatCompletion.create関数を使用して、プロンプト(つまり、 messageオブジェクト)をAPIに送信します。
response = openai . ChatCompletion . create (
model = "gpt-3.5-turbo" ,
messages = message ,
temperature = 0 ,
max_tokens = 256 ) temperature引数を0に設定して、高い再現性を確保し、テキスト完了のトークンの数を256に制限します。この関数は、テキスト完了、メタデータ、およびその他の情報でJSONオブジェクトを返します。
print ( response )
< OpenAIObject chat . completion id = chatcmpl - 8 PzomlbLrTOTx1uOZm4WQnGr4JwU7 at 0xffff4b0dcb80 > JSON : {
"id" : "chatcmpl-8PzomlbLrTOTx1uOZm4WQnGr4JwU7" ,
"object" : "chat.completion" ,
"created" : 1701206520 ,
"model" : "gpt-3.5-turbo-0613" ,
"choices" : [
{
"index" : 0 ,
"message" : {
"role" : "assistant" ,
"content" : "SELECT COUNT(*) FROM chicago_crime WHERE Arrest = true;"
},
"finish_reason" : "stop"
}
],
"usage" : {
"prompt_tokens" : 137 ,
"completion_tokens" : 12 ,
"total_tokens" : 149
}
}応答インディーを使用して、SQLクエリを抽出できます。
sql = response [ "choices" ][ 0 ][ "message" ][ "content" ]
print ( sql ) ' SELECT COUNT(*) FROM chicago_crime WHERE Arrest = true; ' duckdb.sql関数を使用してSQLコードを実行します。
duckdb . sql ( sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 77635 │
└──────────────┘次のセクションでは、すべての手順を一般化し、機能化します。
前のセクションでは、プロンプト形式を導入し、 create_message関数を設定し、 ChatCompletion.create関数の機能を確認しました。このセクションでは、すべてを縫い合わせます。
ChatCompletion.create関数から返されたSQLコードについて注意すべきことの1つは、変数が引用符で戻らないことです。これは、クエリの変数名が2つ以上の単語を組み合わせた場合に問題になる可能性があります。たとえば、引用符を使用せずにクエリ内のchicago_crimeのCase NumberやPrimary Typeなどの変数を使用すると、エラーが発生します。
以下のヘルパー関数を使用して、返されたクエリには次のことを持っていない場合、クエリの変数に引用符を追加します。
def add_quotes ( query , col_names ):
for i in col_names :
if i in query :
l = query . find ( i )
if query [ l - 1 ] != "'" and query [ l - 1 ] != '"' :
query = str ( query ). replace ( i , '"' + i + '"' )
return ( query )関数入力は、クエリと対応するテーブルの列名です。列名をループし、クエリ内で一致している場合は引用符を追加します。たとえば、 ChatCompletion.create関数出力から解析したSQLクエリで実行できます。
add_quotes ( query = sql , col_names = prompt . column_names )
'SELECT COUNT(*) FROM chicago_crime WHERE "Arrest" = true;' Arrest変数に引用符が追加されたことに気付くことができます。
これまでに導入した3つの機能を活用するlang2sql関数を導入できるようになりました - create_message 、 ChatCompletion.create 、およびadd_quotesユーザーの質問をSQLコードに変換します。
def lang2sql ( api_key , table_name , query , model = "gpt-3.5-turbo" , temperature = 0 , max_tokens = 256 , frequency_penalty = 0 , presence_penalty = 0 ):
class response :
def __init__ ( output , message , response , sql ):
output . message = message
output . response = response
output . sql = sql
openai . api_key = api_key
m = create_message ( table_name = table_name , query = query )
message = [
{
"role" : "system" ,
"content" : m . system
},
{
"role" : "user" ,
"content" : m . user
}
]
openai_response = openai . ChatCompletion . create (
model = model ,
messages = message ,
temperature = temperature ,
max_tokens = max_tokens ,
frequency_penalty = frequency_penalty ,
presence_penalty = presence_penalty )
sql_query = add_quotes ( query = openai_response [ "choices" ][ 0 ][ "message" ][ "content" ], col_names = m . column_names )
output = response ( message = m , response = openai_response , sql = sql_query )
return outputこの関数は、入力として、 ChatCompletion.create関数のChatCompletion.Createのコアパラメーターを入力として受信し、プロンプト、API応答、および解析されたクエリを使用してオブジェクトを返します。たとえば、前のセクションで使用した同じクエリをlang2sql関数で再実行してみましょう。
query = "How many cases ended up with arrest?"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )出力オブジェクトからSQLクエリを抽出できます。
print ( response . sql ) SELECT COUNT ( * ) FROM chicago_crime WHERE " Arrest " = true;前のセクションで受け取った結果に関して出力をテストできます。
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 77635 │
└──────────────┘次に、質問に追加の複雑さを追加し、2022年に逮捕された事件を尋ねましょう。
query = "How many cases ended up with arrest during 2022"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )ご覧のとおり、モデルは関連するフィールドをYearとして正しく識別し、正しいクエリを生成しました。
print ( response . sql )SQLコード:
SELECT COUNT ( * ) FROM chicago_crime WHERE " Arrest " = TRUE AND " Year " = 2022 ;テーブルのクエリのテスト:
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 27805 │
└──────────────┘以下は、特定の変数によるグループ化を必要とする簡単な質問の例です。
query = "Summarize the cases by primary type"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )
print ( response . sql )応答出力から、この場合のSQLコードが正しいことがわかります。
SELECT " Primary Type " , COUNT ( * ) as TotalCases
FROM chicago_crime
GROUP BY " Primary Type "これはクエリの出力です。
duckdb . sql ( response . sql ). show ()
┌───────────────────────────────────┬────────────┐
│ Primary Type │ TotalCases │
│ varchar │ int64 │
├───────────────────────────────────┼────────────┤
│ MOTOR VEHICLE THEFT │ 54934 │
│ ROBBERY │ 25082 │
│ WEAPONS VIOLATION │ 24672 │
│ INTERFERENCE WITH PUBLIC OFFICER │ 1161 │
│ OBSCENITY │ 127 │
│ STALKING │ 1206 │
│ BATTERY │ 115760 │
│ OFFENSE INVOLVING CHILDREN │ 5177 │
│ CRIMINAL TRESPASS │ 11255 │
│ PUBLIC PEACE VIOLATION │ 1980 │
│ · │ · │
│ · │ · │
│ · │ · │
│ ASSAULT │ 58685 │
│ CRIMINAL DAMAGE │ 75611 │
│ DECEPTIVE PRACTICE │ 46377 │
│ NARCOTICS │ 13931 │
│ BURGLARY │ 19898 │
...
├───────────────────────────────────┴────────────┤
│ 31 rows ( 20 shown ) 2 columns │
└────────────────────────────────────────────────┘最後になりましたが、LLMは、部分変数名を提供する場合でも、コンテキスト(例えば、どの変数)を識別できます。
query = "How many cases is the type of robbery?"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )
print ( response . sql )以下のSQLコードを返します:
SELECT COUNT ( * ) FROM chicago_crime WHERE " Primary Type " = ' ROBBERY ' ;これはクエリの出力です。
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 25082 │
└──────────────┘このチュートリアルでは、数行のPythonコードを使用してSQLコードジェネレーターを構築し、Openai APIを利用する方法を実証しました。結果のSQLコードの成功には、プロンプトの品質が重要であることがわかりました。プロンプトが提供するコンテキストに加えて、フィールド名はフィールドの特性に関する情報を提供して、LLMがユーザーの質問にフィールドの関連性を特定できるようにする必要があります。
このチュートリアルは、単一のテーブル(たとえば、テーブル間で結合されない)での作業に限定されていましたが、OpenAIで利用可能なLLMなどの一部のLMは、複数のテーブルの作業や正しい結合操作の識別など、より複雑なケースを処理できます。 LANG2SQL関数を調整して複数のテーブルを処理することは、次のステップになる可能性があります。
このチュートリアルは、Creative Commons Attribution-NonCommercial-Sharealike 4.0国際ライセンスの下でライセンスされています。


