super json mode
1.0.0
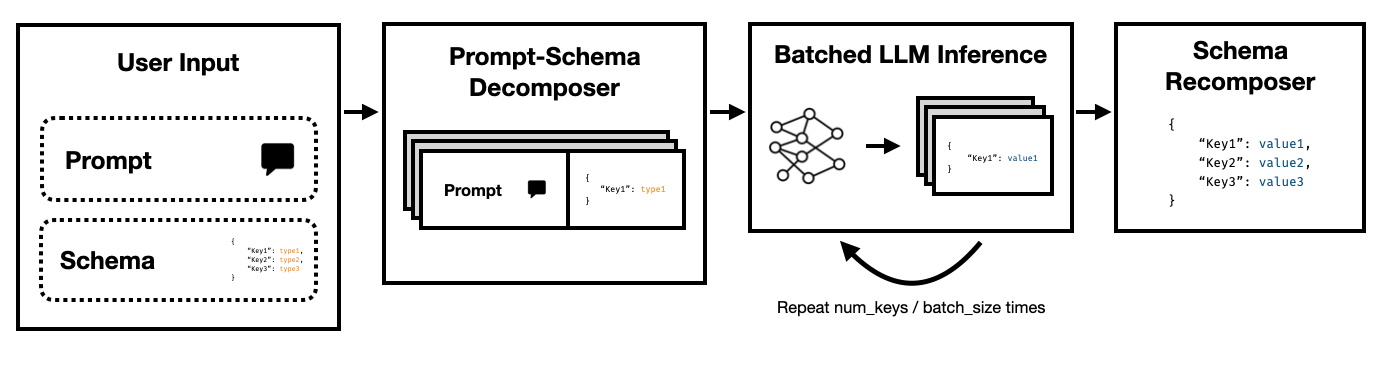
Super JSONモードは、ターゲットスキーマをアトミックコンポーネントに分割し、次に並行して世代を実行することにより、LLMから構造化された出力を効率的に作成できるPythonフレームワークです。
Openaiのレガシー完了APIを介して、 Face TransformersやVLLMを抱きしめるなどのオープンソースLLMを介して、最先端のLLMSの両方をサポートしています。より多くのLLMがまもなくサポートされます!
プロンプトとHFトランスに依存している素朴なJSON世代パイプラインと比較して、スーパーJSONモードは10倍も速く出力を生成できることがわかります。また、より決定論的であり、素朴な世代と比較して解析の問題に遭遇する可能性は低くなります。
インストールは簡単です: pip install super-json-mode
JSONやYAMLなどの構造化された出力形式は、固有の平行または階層構造を持っています。
次の構造化されていない通路(GPT-4によって生成された)を考慮してください。
123 Azure Laneへようこそ、素晴らしい現代的なデザインを誇るサンフランシスコの住居であり、現在は2,500,000ドルで市場に出回っています。豪華な3,000平方フィートに広がっているこのプロパティは、洗練と快適さを組み合わせて、本当にユニークな生活体験を作り出します。
家族や専門家のための牧歌的な家である私たちの専門家には、5つの広々としたベッドルームが装備されています。ベッドルームは、十分な自然光と寛大な保管スペースを確保するために慎重に計画されています。 3つのエレガントに設計されたフルバスルームを備えたこのレジデンスは、住民の利便性とプライバシーを保証します。
壮大な入り口はあなたを広々としたリビングエリアに導き、集まりのための素晴らしい雰囲気や火の静かな夜を提供します。シェフのキッチンには、最先端の電化製品、カスタムキャビネット、美しい花崗岩のカウンタートップが含まれており、料理が大好きな人にとっては夢です。
address 、 square footage 、 number of bedrooms 、 number of bathrooms 、LLMを使用したpriceを抽出する場合は、説明に従ってスキーマを記入するようにモデルに依頼することができます。
潜在的なスキーマ(Pydanticオブジェクトから生成されたものなど)は次のようになります。
{
"address": {
"type": "string"
},
"price": {
"type": "number"
},
"square_feet": {
"type": "integer"
},
"num_beds": {
"type": "integer"
},
"num_baths": {
"type": "integer"
}
}
そして、有効な出力は次のように見えるかもしれません:
{
"address": "123 Azure Lane",
"price": 2500000,
"square_feet": 3000,
"num_beds": 5,
"num_baths": 3
}
明らかなアプローチは、スキーマをプロンプトにネストし、モデルに記入するように依頼することです。これは現在、ほとんどのチームが現在LLMSを使用して非構造化テキストから構造化された出力を抽出している方法です。
ただし、これは3つの理由で非効率的です。
これらの各キーが互いに独立していることに注意してください。 Super JSONモードは、スキーマ内のすべてのキー価値ペアを個別の問い合わせとして扱うことにより、迅速な並列性を利用します。たとえば、 addressを既に生成せずにnum_bathsを抽出できます!
ゼロからJSONを生成するようにモデルを要求すると、ブレースやキー名のような予測可能な構文のトークン(およびその時の時間)は、すでに出力で予想されています。これは、レイテンシを改善するために使用できる世代の強力な事前です。
LLMSは恥ずかしいほど並行しており、バッチで実行されているクエリは、シリアル順序よりもはるかに高速です。したがって、複数のクエリでスキーマを分割できます。 LLMは、各独立キーのスキーマを並行して埋め、1回のパスではるかに少ないトークンを放出し、より速い推論時間を可能にします。
次のコマンドを実行します。
pip install super-json-mode
conda create --name superjsonmode python=3.10 -y
conda activate superjsonmode
git clone https://github.com/varunshenoy/super-json-mode
cd superjsonmode
pip install -r requirements.txt
スーパーJSONモードを非常に使いやすくしようとしました。より多くの例とvLLM使用については、 examplesフォルダーを参照してください。
OpenAIおよびgpt-3-instruct-turbo使用してください:
from superjsonmode . integrations . openai import StructuredOpenAIModel
from pydantic import BaseModel
import time
model = StructuredOpenAIModel ()
class Character ( BaseModel ):
name : str
genre : str
age : int
race : str
occupation : str
best_friend : str
home_planet : str
prompt_template = """{prompt}
Please fill in the following information about this character for this key. Keep it succinct. It should be a {type}.
{key}: """
prompt = """Luke Skywalker is a famous character."""
start = time . time ()
output = model . generate (
prompt ,
extraction_prompt_template = prompt_template ,
schema = Character ,
batch_size = 7 ,
stop = [ " n n " ],
temperature = 0 ,
)
print ( f"Total time: { time . time () - start } " )
# Total Time: 0.409s
print ( output )
# {
# "name": "Luke Skywalker",
# "genre": "Science fiction",
# "age": "23",
# "race": "Human",
# "occupation": "Jedi Knight",
# "best_friend": "Han Solo",
# "home_planet": "Tatooine",
# }Huggingface TransformersでMistral 7bを使用してください:
from transformers import AutoTokenizer , AutoModelForCausalLM
from superjsonmode . integrations . transformers import StructuredOutputForModel
from pydantic import BaseModel
device = "cuda"
model = AutoModelForCausalLM . from_pretrained ( "mistralai/Mistral-7B-Instruct-v0.2" ). to ( device )
tokenizer = AutoTokenizer . from_pretrained ( "mistralai/Mistral-7B-Instruct-v0.2" )
# Create a structured output object
structured_model = StructuredOutputForModel ( model , tokenizer )
passage = """..."""
class QuarterlyReport ( BaseModel ):
company : str
stock_ticker : str
date : str
reported_revenue : str
dividend : str
prompt_template = """[INST]{prompt}
Based on this excerpt, extract the correct value for "{key}". Keep it succinct. It should have a type of `{type}`.[/INST]
{key}: """
output = structured_model . generate ( passage ,
extraction_prompt_template = prompt_template ,
schema = QuarterlyReport ,
batch_size = 6 )
print ( json . dumps ( output , indent = 2 ))
# {
# "company": "NVIDIA",
# "stock_ticker": "NVDA",
# "date": "2023-10",
# "reported_revenue": "18.12 billion dollars",
# "dividend": "0.04"
# } スーパーJSONモードを改善できる機能がたくさんあります。ここにいくつかのアイデアがあります。
定性的出力分析:パフォーマンスベンチマークを実行しましたが、スーパーJSONモードの定性的出力を判断するためのより厳密なアプローチを考え出す必要があります。
構造化されたサンプリング:理想的には、JSonformerと同様に、タイプの制約を実施するためにLLMのロジットをマスクする必要があります。すでにこれを行うパッケージがいくつかあり、それらが並列化されたJSON世代パイプラインを統合するか、スーパーJSONモードに構築する必要があります。
依存関係グラフのサポート:スーパーJSONモードには非常に明らかな障害ケースがあります。キーが別のキーに依存している場合。 thoughtとresponse 2つのキーを備えたJSON Blobを考えてみましょう。この種の望ましい出力は、大規模な言語モデルを使用したチェーンに一般的であり、 responseがthoughtに依存していることは非常に明確です。親の出力が完了し、子スキーマアイテムに渡されるように、依存関係とバッチプロンプトのグラフを渡すことができるはずです。
ローカルモデルのサポート:スーパーJSONモードは、バッチサイズが一般的に1であるローカル状況で最適に機能します。投機的デコードと同様に、バッチを悪用してレイテンシを減らすことができます。 llama.cppは、ローカルモデル + CPU推論のプレミアフレームワークです。可能であれば、オラマを使用してこれを実装したいと思います。
TRT-LLMサポート:VLLMは素晴らしく使いやすいですが、理想的にはTRT-LLMのようなはるかにパフォーマンスのあるフレームワークと統合しています。
あなたがあなたの仕事に役立つライブラリを見つけたなら、このレポを引用してください。
@misc{ShenoyDerhacobian2024,
author = {Shenoy, Varun and Derhacobian, Alex},
title = {Super JSON Mode: A Framework for Accelerated Structured Output Generation},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/varunshenoy/super-json-mode}}
}
このプロジェクトは、CS 229:Systems for Machine Learning用に構築されました。このプロジェクト全体の指導に感謝します。


