
[関連する推奨事項: JavaScript ビデオ チュートリアル、Web フロントエンド]
どのようなプログラミング言語を使用する場合でも、文字列は重要なデータ型です。JavaScript JavaScript列について詳しく学ぶには、私に従ってください。
文字列は文字で構成される文字列です。C とJava Cしたことがある場合は、文字自体も独立した型になる可能性があることを知っているはずです。ただし、 JavaScript単一の文字タイプはなく、長さ1の文字列のみがあります。
JavaScript文字列は固定UTF-16エンコーディングを使用します。プログラムの作成時にどのようなエンコーディングを使用しても、影響を受けません。
、一重引用符、二重引用符、バックティックの 3 つの方法があります。
let single = 'abcdefg';//一重引用符 let double = "asdfghj";//二重引用符 let backti = `zxcvbnm`;//バックティックの
一重引用符と二重引用符は同じステータスを持ち、区別しません。
文字列の書式設定
バッククォートを使用すると、文字列の追加を使用する代わりに${...}を使用して文字列をエレガントに書式設定できます。
let str = `私は ${Math.round(18.5)} 歳です。`;console.log(str);コードの実行結果:

複数行の文字列
バッククォートを使用すると、文字列を複数行にまたがることもできるため、複数行の文字列を記述する場合に非常に便利です。
let ques = `Is the author handsome? A. とてもハンサムです。 B. とてもハンサムです。 C. 超ハンサム;`;console.log(ques);
コードの実行結果:
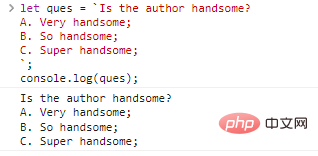
何の問題もないように見えませんか?ただし、これは一重引用符と二重引用符を使用して実現することはできません。
let ques = '作者はハンサムですか?nA. とてもハンサムです;nC.非常にハンサムです;'; console.log(ques);
上記のコードには、プログラミング プロセスで最も一般的な特殊文字nが含まれています。
キャラクターn 、マルチライン文字列を出力するための単一の引用符と二重引用符をサポートしています。エンジンが文字列を出力すると、 nに遭遇すると、別のラインで出力され続け、マルチライン文字列が実現されます。
n 2 文字であるように見えますが、 文字列内のエスケープ文字であり、エスケープ文字によって変更された文字は特殊文字になるため、1 文字の位置のみを占めます。
特殊文字リスト
| 特殊文字の | 説明 | |
|---|---|---|
n | 出力テキストの新しい行を開始するために使用される改行文字。 | |
r | carriage return character moves the cursor to the beginning of the line. In Windows systems, rn is used to represent a line break, which means that the cursor needs to go to the beginning of the line first, and then新しい行に変更される前に、次の行に移動します。他のシステムではn直接使用できます。 | |
' " | Single and double quotation marks, mainly because single and double quotation marks are special characters. If we want to use single and double quotation marks in a string, we must escape them. | |
\ | Backslash, also because | |
b f v | バックスペース、ページ送り、垂直ラベル - | |
XX Unicode | xXX | XX としてエンコードされた 16 進 Unicode 文字です|
: x7A z ( zの 16 進Unicodeエンコードは7A ) を意味します。 | ||
uXXXX | XXXXの 16 進Unicode文字としてエンコードされます。たとえば、 u00A9は © | |
( 1-6 16 進文字u{X...X} | UTF-32 | 意味します。エンコーディングはX...XのUnicode記号です。 |
例:
console.log('I'ma students.');// 'console.log(""I love U. "");/ / "console.log("\n は改行文字です。");// nconsole.log('u00A9')// ©console.log('u{1F60D} ');//コードexecution results:
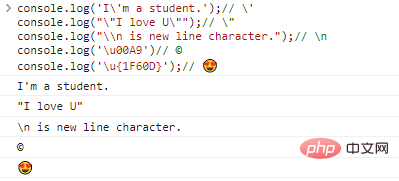
エスケープ文字が存在するため、対応するエンコーディングが見つかる限り、理論的には任意の文字を出力できます。
'および"を使用しないでください
。単一の引用符で巧妙に使用したり、ダブル引用符内で単一の引用を使用したり、バックテック内で1つの引用符とダブル引用符を直接使用したりできます。たとえば、エスケープ文字を使用しないでください。
console.log( "私は学生です。"); // double quotes console.log( '""が使用されている')内で単一の引用符を使用します。 //単一Quotes Console.log( `'"が使用されている)内で二重引用符を使用します。 //反引号中使用单双引号
代码执行结果如下:
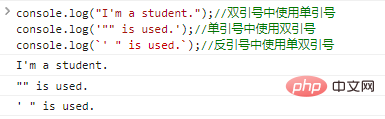
文字列の.lengthプロパティを使用して、文字列の長さを取得できます。
console.log("HelloWorldn".length);//11 nここで、n は 1 文字のみを占めます。
「基本型のメソッド」の章では、
JavaScriptの基本型にプロパティとメソッドがある理由について説明しました。まだ覚えていますか?
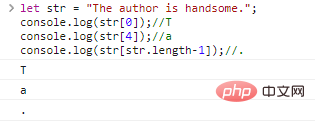
字符串是字符组成的串,我们可以通过[字符下标]访问单个的字符,字符下标从0开始:
let str = "The author is handsome."; console.log(str[0]);//Tconsole.log(str[4]);//aconsole.log(str[str.length-1]);//.
代码执行结果:
charAt(post)関数を使用して文字を取得することもできます。
let str = "作者はハンサムです。";console.log(str.charAt(0)); //Tconsole.log(str.charAt(4)); //aconsole.log(str.charAt(str.length-1));//。
この 2 つの実行結果はまったく同じですが、唯一の違いは、範囲外の文字にアクセスする場合です。
let str = "01234"; console.log(str [9]); // undefinedConsole.log(str.Charat(9)); // ""(空の文字列
)
for ..of
'01234'){
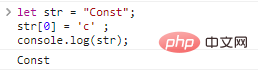
console.log(c);}JavaScriptの文字列は、一度定義すると変更できません。
let str = "Const";str[0] = 'c' ;console.log(str)
;結果:
別の文字列を取得したい場合は、新しい文字列を作成するしかありません:
let
str = "Const";str = str.replace('C','c');console.log(str); have changed the characters String, in fact the original string has not been changed, what we get is the new string returned by the replace method.
文字列のケースを変換するか、文字列内の単一文字のケースを変換します。
次の例に示すように、これら 2 つの文字列のメソッドは比較的単純です。
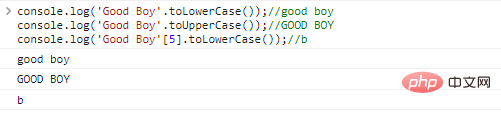
console.log('Good Boy'.toLowerCase());//good
Boyconsole.log( 'Good Boy'.Touppercase()); // Good
BOYconsole.log('Good Boy'[5].toLowerCase());//bコードの実行結果:
The .indexOf(substr,idx) function starts from the idx position of the string, searches for the position of the substring substr , and returns the subscript of the first character of the成功した場合はサブストリング、または失敗した場合は-1 。
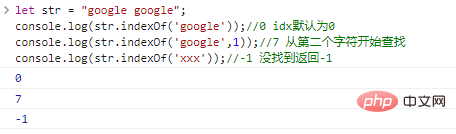
let str = "google google";console.log(str.indexOf('google'));
//0 idx のデフォルトは 0console.log(str.indexOf('google',1));
//7 console.log(str.indexOf('xxx')); を 2 文字目から検索します。
//-1 が見つからない場合は、-1 のコード実行結果が返されます。
文字列内のすべての部分文字列の位置をクエリしたい場合は、ループを使用できます。
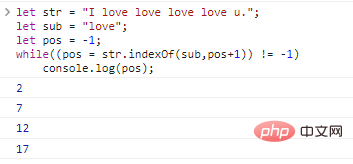
let str = "I love love love love u.";let sub = "love";let pos = -1;while((pos) = str.indexOf (sub,pos+1)) != -1)
console.log
(pos);
.lastIndexOf(substr,idx)部分文字列を逆方向に検索し、最初に最後に一致する文字列を見つけます:
let str = "google google";console.log(str.lastIndexOf('google'));//7 idx のデフォルトは 0これは、 indexOf()とlastIndexOf()メソッドは、クエリが失敗した場合に-1を返し、 ~-1 === 0ためです。つまり、 ~の使用は、クエリ結果が-1ではない場合にのみ true となるため、次のようにすることができます。
let str = "google google";if(~indexOf('google',str)){
...}通常、構文の特徴が明確に反映できない構文の使用は、可読性に影響を与えるため推奨しません。幸いなことに、上記のコードは、古いコードを読むときに誰もが混乱しないように、コードの古いバージョンにのみ表示されます。
補足:
~ビット単位の否定演算子です。例: 10 進数2の 2 進数形式は0010で、~2の 2 進数形式は1101(補数)、つまり-3です。簡単に理解すると、
~n-(n+1)と同等です。例:~2 === -(2+1) === -3
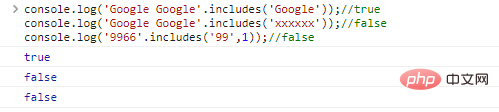
.includes(substr,idx) substrが文字列内にあるかどうかを判断するために使用されます。 idxはクエリの開始位置です
console.log('Google Google'.includes('Google'));//trueconsole.log( 'Google Google'. includes('xxxxxx'));//falseconsole.log('9966'.includes('99',1));//false code execution results:
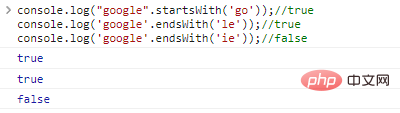
.startsWith('substr')と.endsWith('substr')はそれぞれ、文字列がsubstrで始まるか終わるかを決定します
console.log("google".startsWith('go'));//trueconsole.log('google' .endsWith('le'));//trueconsole.log('google'.endsWith('ie'));//false code execution result:
.substr() 、. .substring() 、. .slice()はすべて、弦のサブストリングを取得するために使用されますが、それらの使用法は異なります。
.substr(start,len)
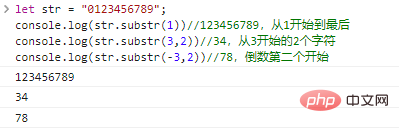
startから始まるlen文字で構成される文字列を返します。 lenを省略すると、元の文字列の末尾までインターセプトされます。 start可以为负数,表示从后往前第start个字符。
let str = "0123456789"; console.log(str.substr(1))// 123456789、1からend console.log(str.substr(3,2))// 34、3 3文字から2回目console.log(str.substr(-3,2))//78, the penultimate start
code execution result:
.slice(start,end)
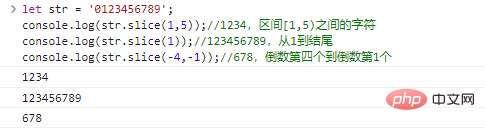
startから開始し、 endに終了します(排他的)ストリングを返します。 start和end可以为负数,表示倒数第start/end个字符。
let str = '0123456789';console.log(str.slice(1,5));//1234, 間隔 [1,5) 間の文字 console.log(str.slice(1));//123456789 , from 1 to the end console.log(str.slice(-4,-1));//678, the fourth to last
code execution results:
.substring(start,end)
0end > start.slice()とほぼ同じです
。
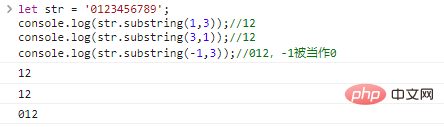
let str = '0123456789'; console.log(str .substring(1,3));//12console.log(str.substring(3,1));//12console.log(str.substring(-1, 3)); // 012、-1は、0のコード実行結果を作成するものとして扱われます
。
3 つの違いを比較してください。
| メソッドの | 説明 | パラメータ.slice |
|---|---|---|
.slice(start,end) | [start,end) | は負の値にすることができます。substring |
.substr(start,len) | ||
.substring(start,end) | 0 | [start,end) |
starts from start |
| negative | len |
methods for len, so it is naturally difficult to choose. It is recommended to remember
.slice(), which is more flexible than the other two.
我们在前文中已经提及过字符串的比较,字符串按照字典序进行排序,每个字符背后都是一个编码, ASCII编码就是一个重要的参考。
例:
console.log( 'a'> 'z'); //
真の文字間の比較は、本質的に文字を表すエンコーディング間の比較です。 JavaScript uses UTF-16 to encode strings. Each character is a 16 bit code. If you want to know the nature of the comparison, you need to use .codePointAt(idx) to get the character encoding:
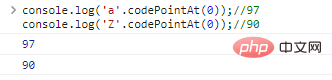
console.log('a '.codePointAt( 0));//97console.log('Z'.codePointAt(0));//90コードの実行結果:
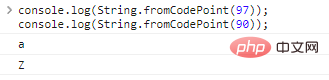
String.fromCodePoint(code)を使用して、エンコードを文字に変換します。console.log
(
string.fromcodepoint(97)); console.log(String.FromCodePoint(90));
このプロセスは、次のように、エスケープ文字uを使用して達成できます。console.log
( ' u005a'); // z、005aは90 console.log( ' u0061'); // a、 0061これは97の16進表です。
範囲でエンコードされた文字を探索しましょう[65,220] :
str = ''; for(i = 65; i <= 220; i ++){
str+=String.fromCodePoint(i);}console.log(str);コード実行部分の結果は次のとおりです。

上の写真にはすべての結果が表示されないので、行って試してみてください。
str1 < str2JavaScript .localeCompare() str1.localeCompare(str2) ECMA-402に基づいています
str1
>
str1==
str1 > str2を返しますstr1 == str2a z
が
いくつかの特別な執筆aを持っているáです。
!
現時点では、 .localeCompare()メソッドを使用する必要があります:
console.log('á'.localeCompare('z'));//-1str.trim()文字列の前後の空白文字を削除します。 string, str.trimStart() , str.trimEnd()先頭と末尾のスペースを削除します
let str = " 999 "; //999
str.repeat(n)を繰り返します。文字列をn回;
let str = ' 6';console.log(str.repeat(3));//666
str.replace(substr,newstr)最初の部分文字列を置換し、 str.replaceAll()使用してすべてを置換します。 substrings;
let str = '9 +9';console.log(str.replace('9','6'));//6+9console.log(str.replaceAll('9','6')) ;//6+6is still There are many other methods and we can visit the manual for more knowledge.
JavaScript文字列のエンコードにUTF-16使用します。つまり、1 つの文字を表すのに 2 バイト ( 16ビット) が使用されます。ただし、 16ビット データは65536文字しか表現できません。一般的な文字は当然含まれていませんが、珍しい文字(中国語)、 emoji 、珍しい数学記号などについては十分ではありません。
この場合、特殊文字を表すには、拡張して長い桁 ( 32ビット) を使用する必要があります。例:
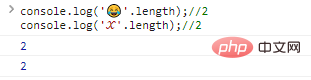
console.log(''.length);//2console.log('?'.length);//2コード実行結果:
这么做的结果是,我们无法使用常规的方法处理它们,如果我们单个输出其中的每个字节,会发生什么呢?
console.log(''[0]);console.log(''[1]);代码执行结果:
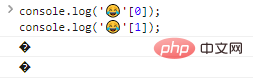
可以看到,单个输出字节是不能识别的。
好在String.fromCodePoint()和.codePointAt()两个方法是可以处理这种情况的,这是因为二者是最近才加入的。古いバージョンのJavaScriptでは、エンコーディングと文字の変換にString.fromCharCode()メソッドと.charCodeAt()メソッドのみを使用できますが、これらは特殊文字には適していません。
我们可以通过判断一个字符的编码范围,判断它是否是一个特殊字符,从而处理特殊字符。文字のコードが0xd800~0xdbffの間にある場合、それは32ビット文字の最初の部分であり、その 2 番目の部分は0xdc00~0xdfffの間にある必要があります。
举个例子:
console.log(''.charCodeAt(0).toString(16));//d83
dconsole.log( '?'。CharCodeat(1).ToString(16)); // DE02コード実行結果:

には、多くの文字ベースのバリエーションがあります。たとえば、文字a àáâäãåāの基本的な特徴になります。これらのバリアント記号のすべてが、バリエーションの組み合わせが多すぎるため、 UTF-16エンコーディングに保存されているわけではありません。
すべてのバリアントの組み合わせをサポートするために、プログラミング プロセス中に、基本文字と「 Unicode記号」を使用して特殊文字を表現することもできます。
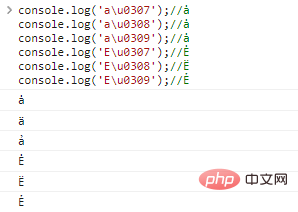
console.log('au0307 ' ); //ȧ
console.log( 'a u0308'); //ȧ
console.log('au0309');//ŧ
console.log( 'e u0307'); //ė
console.log( 'e u0308'); // e
console.log( 'e u0309'); //ẻコード実行結果:
基本的な文字には、複数の装飾があります。たとえば、
console.log( 'e u0307 u0323'); console.log( 'e u0323 u0307'); //ẹnocode
実行結果:
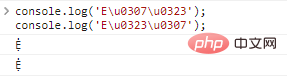
ここで問題が発生します。装飾が複数ある場合、装飾の順序は異なりますが、実際に表示される文字は同じです。
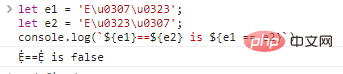
これら2つの表現を直接比較すると、誤った結果が得られます。E1
= 'e u0307 u0323'とします。
e2 = 'e u0323 u0307';
console.log( `$ {e1} == $ {e2}は$ {e1 == e2}`)コード実行結果:
この状況を解決するために、文字列をユニバーサル ** 形式に変換できる** Unicode正規化アルゴリズムがあり、これはstr.normalize()によって実装されます
。
e2 = 'e u0323 u0307';
console.log(`${e1}==${e2} is ${e1.normalize() == e2.normalize()}`)
コード実行の結果:

[関連する推奨事項:JavaScriptビデオチュートリアル、Webフロントエンド]
上記は、JavaScript文字列の一般的な基本方法の詳細な内容です。PHP中国のウェブサイトの他の関連記事に注意してください。