
この記事の内容を学ぶ前に、まず非同期の概念を理解する必要があります。最初に強調すべきことは、非同期と並列には本質的な違いがあるということです。
並列処理は一般に並列コンピューティングを指します。これは、複数の命令が同じCPUの複数のコア、複数のCPU 、または複数の物理ホスト、さらには複数のネットワークで実行されることを意味します。
同期とは、一般に、あらかじめ決められた順序でタスクを実行することを指し、前のタスクが完了した場合にのみ、次のタスクが実行されます。
同期に対応する非同期とは、 CPU現在のタスクを一時的に保留し、最初に次のタスクを処理し、前のタスクのコールバック通知を受信した後、前のタスクに戻って実行を継続することを意味します。 2番目のスレッドに参加します。
おそらく、並列処理、同期処理、非同期処理を図で説明する方がわかりやすいでしょう。処理する必要がある 2 つのタスク A と B があるとします。並列処理、同期処理、および非同期処理の方法は、次のとおりです。次の図:
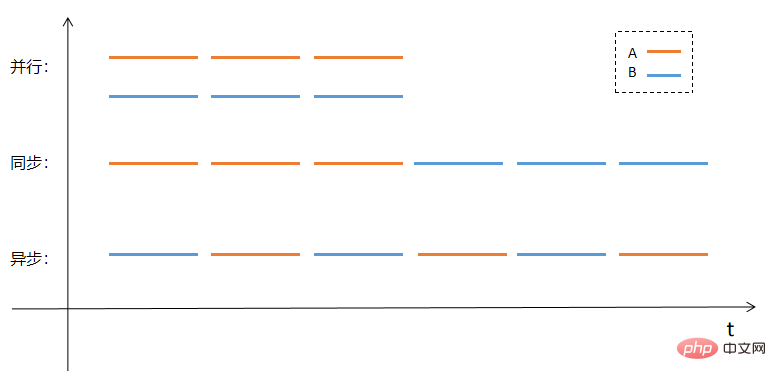
JavaScriptは多くの非同期関数が用意されており、これらの関数を使用すると、タスク (関数) の実行をすぐに開始できますが、タスクは後で完了します。はわかりません。
たとえば、 setTimeout関数は非常に典型的な非同期関数です。さらに、 fs.readFileとfs.writeFileも非同期関数です。
ファイル コピー関数copyFile(from,to)カスタマイズするなど、非同期タスク ケースを自分で定義できます。
const fs = require('fs')function copyFile(from, to) {
fs.readFile(from, (err, data) => {
if (エラー) {
コンソールログ(エラーメッセージ)
戻る
}
fs.writeFile(to, data, (err) => {
if (エラー) {
コンソールログ(エラーメッセージ)
戻る
}
console.log('コピーが完了しました')
})
関数 copyFile は、
copyFileパラメータfromからファイル データを読み取り、次にパラメータtoが指すファイルにデータを書き込みます。
次のようにcopyFileを呼び出すことができます:
copyFile('./from.txt','./to.txt')//ファイルをコピーしますこの時点でcopyFile(...)の後に他のコードがある場合、プログラムはコピーしません。 wait copyFileの実行は終了しますが、プログラムはファイル コピー タスクがいつ終了するかを気にしません。
copyFile('./from.txt','./to.txt')//次のコードは、上記のコードの実行が終了するのを待ちません...この時点では、すべてが正常であるように見えますが、 copyFile(...)関数の後にファイル./to.txtの内容に直接アクセスするとどうなりますか?
これは、次のように、コピーされたコンテンツを読み取りません。
copyFile('./from.txt','./to.txt')fs.readFile('./to.txt',(err,data)= >{
...})プログラムを実行する前に./to.txtファイルが作成されていない場合は、次のエラーが発生します:
PS E:CodeNodedemos�3-callback> node .index.js 終了した コピーが完了しました PS E:CodeNodedemos�3-callback> ノード .index.js エラー: ENOENT: no such file or directory, open 'E:CodeNodedemos�3-callbackto.txt'Copy completed
./to.txtが存在しても、コピーされた内容を読み取ることはできません。
この現象の原因は、 copyFile(...)が非同期で実行されるため、プログラムがcopyFile(...)関数を実行した後、コピーの完了を待たずに直接下方向に実行するため、ファイルが破損することです。 ./to.txtが存在しないエラー、またはファイルの内容が空です (ファイルが事前に作成されている場合) エラーが表示されます。
コールバック関数の非同期関数の具体的な実行終了時刻は決定できません。たとえば、 readFile(from,to)関数の実行終了時刻は、 fromのファイルのサイズに依存する可能性が高くなります。
では、問題は、どのようにしてcopyFile実行の終わりを正確に特定し、 toファイルの内容を読み取ることができるかということです。
これにはコールバック関数を使用する必要があります。次のようにcopyFile関数を変更できます。
function copyFile(from, to, callback) {
fs.readFile(from, (err, data) => {
if (エラー) {
コンソールログ(エラーメッセージ)
戻る
}
fs.writeFile(to, data, (err) => {
if (エラー) {
コンソールログ(エラーメッセージ)
戻る
}
console.log('コピーが完了しました')
callback()//コピー操作が完了するとコールバック関数が呼び出されます})
このように、ファイルのコピーが完了した直後にいくつかの操作を実行する必要がある場合は、これらの操作をコールバック関数に書き込むことができます。
function copyFile(from, to, callback) {
fs.readFile(from, (err, data) => {
if (エラー) {
コンソールログ(エラーメッセージ)
戻る
}
fs.writeFile(to, data, (err) => {
if (エラー) {
コンソールログ(エラーメッセージ)
戻る
}
console.log('コピーが完了しました')
callback()//コピー操作が完了するとコールバック関数が呼び出されます})
})}copyFile('./from.txt', './to.txt', function () {
//コールバック関数を渡し、「to.txt」ファイルの内容を読み取り、出力 fs.readFile('./to.txt', (err, data) => {
if (エラー) {
コンソールログ(エラーメッセージ)
戻る
}
console.log(data.toString())
})}) ./from.txtファイルを準備している場合は、上記のコードを直接実行できます:
PS E:CodeNodedemos�3-callback> node .index.js コピーが完了しました コミュニティ「Xianzong」に参加して、私と一緒に不滅を育ててください。コミュニティのアドレス: http://t.csdn.cn/EKf1h
このプログラミング方法は、「コールバックベース」の非同期プログラミング スタイルと呼ばれ、非同期で実行される関数はコールバック パラメーターを提供する必要があります。タスク終了後に呼び出すために使用されます。
このスタイルはJavaScriptプログラミングで一般的です。たとえば、ファイル読み取り関数fs.readFileとfs.writeFileはすべて非同期関数です。
コールバック関数は、非同期作業が完了した後、後続の処理を正確に処理できます。複数の非同期操作を順番に実行する必要がある場合は、コールバック関数をネストする必要があります。
ケースシナリオ:
ファイル A とファイル B を順番に読み取るためのコード実装:
fs.readFile('./A.txt', (err, data) => {
if (エラー) {
コンソールログ(エラーメッセージ)
戻る
}
console.log('ファイル A の読み取り: ' + data.toString())
fs.readFile('./B.txt', (err, データ) => {
if (エラー) {
コンソールログ(エラーメッセージ)
戻る
}
console.log("ファイル B を読み取ります: " + data.toString())
})})実行効果:
PS E:CodeNodedemos�3-callback> node .index.js ファイル A: 不滅のセクトを読むことは無限に良いことですが、誰かが欠けています。 ファイル B: 不滅のセクトに参加したい場合は、
コールバックを通じて
リンク http://t.csdn.cn/H1faI を持っている必要があります。ファイル A の後に、ファイル B がすぐに読み取られます。
ファイル B の後にファイル C の読み取りを続けたい場合はどうすればよいでしょうか?これには、引き続きコールバックをネストする必要があります。
fs.readFile('./A.txt', (err, data) => {//First callback if (err) {
コンソールログ(エラーメッセージ)
戻る
}
console.log('ファイル A の読み取り: ' + data.toString())
fs.readFile('./B.txt', (err, data) => {//2 番目のコールバック if (err) {
コンソールログ(エラーメッセージ)
戻る
}
console.log("ファイル B を読み取ります: " + data.toString())
fs.readFile('./C.txt',(err,data)=>{//3 番目のコールバック...
})
})})つまり、複数の非同期操作を順番に実行したい場合は、複数レベルのネストされたコールバックが必要になります。これは、レベルの数が少ない場合には効果的ですが、ネスト回数が多すぎると、いくつかの問題が発生します。という疑問が生じます。
コールバック規約
実際、 fs.readFileのコールバック関数のスタイルは例外ではなく、 JavaScriptの一般的な規約です。将来的には多数のコールバック関数をカスタマイズする予定なので、この規則に従って、適切なコーディング習慣を身に付ける必要があります。
規則では、
callbackの最初のパラメータはエラーのために予約されています。エラーが発生すると、 callback(err)が呼び出されます。callback(null, result1, result2,...)が呼び出されます。上記の規則に基づいて、コールバック関数にはエラー処理と結果受信の 2 つの機能があります。たとえば、 fs.readFile('...',(err,data)=>{})のコールバック関数はこの規則に従います。
さらに深く掘り下げなければ、コールバックに基づく非同期メソッド処理は、これを処理する非常に完璧な方法のように思えます。問題は、非同期動作が次々と行われる場合、コードは次のようになることです。
fs.readFile('./a.txt',(err,data)=>{
if(エラー){
コンソールログ(エラーメッセージ)
戻る
}
//結果の読み取り操作 fs.readFile('./b.txt',(err,data)=>{
if(エラー){
コンソールログ(エラーメッセージ)
戻る
}
//結果の読み取り操作 fs.readFile('./c.txt',(err,data)=>{
if(エラー){
コンソールログ(エラーメッセージ)
戻る
}
//結果の読み取り操作 fs.readFile('./d.txt',(err,data)=>{
if(エラー){
コンソールログ(エラーメッセージ)
戻る
}
...
})
})
})})上記のコードの実行内容は
呼び出しの数が増えると、コードのネスト レベルがますます深くなり、より多くの条件ステートメントが含まれるようになります。その結果、コードが常に右にインデントされ、読みにくくなり、読みにくくなります。維持する。
この右への継続的な成長 (右へのインデント) 現象を、私たちは「コールバック地獄」または「破滅のピラミッド」と呼んでいます。
fs.readFile('a.txt',(err,data)=>{
fs.readFile('b.txt',(err,data)=>{
fs.readFile('c.txt',(err,data)=>{
fs.readFile('d.txt',(err,data)=>{
fs.readFile('e.txt',(err,data)=>{
fs.readFile('f.txt',(err,data)=>{
fs.readFile('g.txt',(err,data)=>{
fs.readFile('h.txt',(err,data)=>{
...
/*
地獄への門 ===>
*/
})
})
})
})
})
})
})})上記のコードは非常に規則的であるように見えますが、これは単なる理想的な状況にすぎません。通常、ビジネス ロジックには多数の条件文、データ処理操作、その他のコードがあり、現在の美しい順序が破壊されます。コードの変更は保守が困難です。
幸いなことに、 JavaScript複数のソリューションを提供しており、 Promise最良のソリューションです。