前のセクションで Web ページのすべての情報をクロールしました。次に、HTML コードで必要なコンテンツを見つける必要があります。したがって、問題に従って Web サイトに入り、Web ページ内の情報を解析する必要があります。
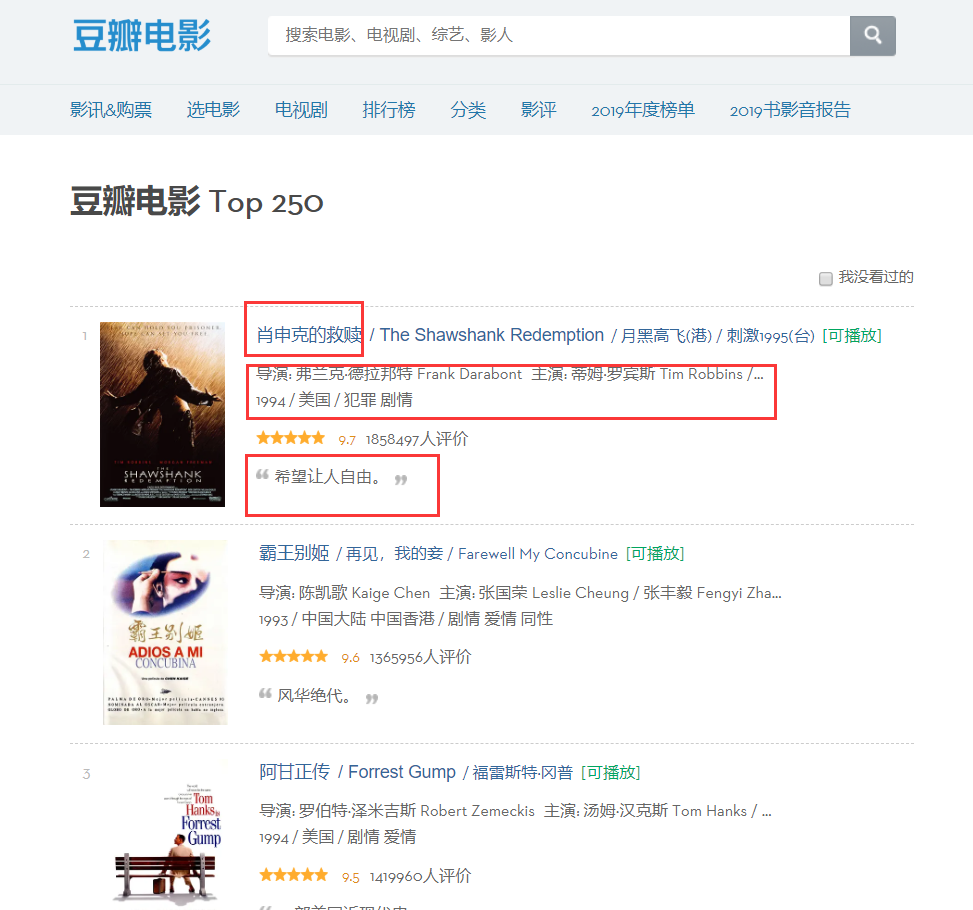
ページから、クロールする必要がある情報がさまざまなパーティションに存在することがわかります。そのため、ページの要素を確認しましょう。ページを右クリックして Web ページのソース コードを確認するか、F12 キーを押します。

Web ページを分析する前に、まず解析後の保存方法を指定します。ここではリストを使用してすべての情報を保存します。次に、リスト内の各項目が辞書に対応し、各辞書が複数の種類の情報に対応します。
movie=[]#最初にすべての情報を保存するリストを定義します
分析を通じて、タイトルの位置が「hd」という名前の「div」の下の最初の「a」の最初の「span」であることが判明したため、次のコードを通じて各映画の名前をロックできます。辞書に。
moviename=each.find('div',class_='hd').a.span.text.strip()movie['title']=moviename#辞書の項目同様に、ディレクター名のソース コードも位置に基づいて見つけることができますが、このソース コードには多くの情報が含まれているため、正規表現を使用してフィルタリングする必要があります。
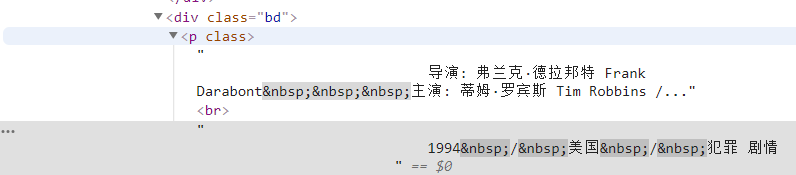
info=each.find('div',class_='bd').p.text.strip()まず、このタグの下にあるすべてのコンテンツを検索し、次に正規表現を使用して無関係な情報を除外します。
info=info.replace('n',)#キャリッジリターンをフィルタリング info=info.replace(,)#スペースをフィルタリング info=info.replace(xa0,)#改行しない空白文字をフィルタリング Director=re.findall( r '[監督:].+[主演:]',info)[0]director=director[3:len(director)-6]次に、それを辞書の項目として定義します。
movie['director']=director#辞書の項目
映画のタイプもこの「p」タグ内にあることがわかり、この情報も正規表現を通じて直接取得します。
lot=re.findall(r'[0-9]*[/].+[/].+',info)[0]plot=plot[1:]plot=plot[plot.index('/') +1:]plot=plot[plot.index('/')+1:]movie['plot']=plot#辞書の項目として追加最後に評価情報をロックします。
star=each.find('div',class_='star')star=star.find('span',class_='rated_num').text.strip()次に、それを辞書の形式で保存し続けます。
映画['スター']=スター
最後に、この辞書をリストに追加し、出力を繰り返し処理します。
movie.append(movie)#辞書をリストに追加しますinmovies:#出力を走査します print(i)
importreimportrequestsfrombs4importBeautifulSoupforiinrange(1):headers={#ブラウザをシミュレートして 'user-agent' にアクセスします:'Mozilla/5.0(WindowsNT6.1;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/52.0.2743.82Safari/537.36' , 'ホスト':'movie.douban.com'}res='https://movie.douban.com/top250?start='+str(25*i)#25 回 r=requests.get(res,headers = headers,timeout=10)#タイムアウトを設定しますSoup=BeautifulSoup(r.text,html.parser)#解析方法を設定します。他の方法も使用できます。 div_list=soup.find_all('div',class_='item')movies=[]foreachindiv_list:movie={}moviename=each.find('div',class_='hd').a.span.text.strip ()movie['title']=movienamerank=each.find('div',class_='pic').em.text.strip()movie['rank']=rankinfo=each.find('div', class_='bd').p.text.strip()info=info.replace('n',)info=info.replace(,)info=info.replace(xa0,)director=re.findall( r'[監督:].+[主演:]',info)[0]director=director[3:len(director)-6]movie['director']=directorrelease_date=re.findall(r'[0- 9]{4}',info)[0]映画['release_date']=release_dateplot=re.findall(r'[0-9]*[/].+[/].+',info)[0]プロット=プロット[1:]プロット=プロット[プロット.インデックス('/')+1:]プロット=プロット[プロット.インデックス('/')+1:]映画['プロット']=プロットスター=それぞれ。 find('div',class_='star')star=star.find('span',class_='rated_num').text.strip()movie['star']=starmovies.append(movie)foriinmovies:print (私)コンソール:

この例では、主に、Web ページのソース コード内で対応する情報を見つける方法を学習します。次のセクションでは、BeautifulSoup を使用して情報を迅速に見つけ、それを正規表現と組み合わせて情報の照合を完了します。このデータはデータベースに保存されます。