AI 界では、チューリング賞受賞者のヤン・レクン氏は典型的な外れ値です。
多くの技術専門家は、現在の技術的路線に沿ってAGIの実現は時間の問題であると固く信じているが、ヤン・レクン氏は繰り返し異議を唱えている。
同僚との激しい議論の中で、彼は、現在の主流のテクノロジーの道では私たちをAGIに導くことはできず、現在のAIのレベルでさえ猫ほど優れたものではないと何度も述べました。
チューリング賞受賞者、メタ主任 AI 科学者、ニューヨーク大学教授など。これらの輝かしい肩書と最前線での豊富な実務経験により、私たちの誰もがこの AI 専門家の洞察を無視することはできません。

それでは、ヤン・ルカン氏はAIの将来についてどう考えているのでしょうか?最近の公開演説で、彼は自分の見解をもう一度詳しく述べました。AIはテキスト トレーニングのみに依存して人間レベルに近い知能に到達することは決してできません。
いくつかの見解は次のとおりです。
1. 将来、人々は一般的にスマートグラスや他のタイプのスマートデバイスを着用し、個人の創造性と効率性を向上させるための個人用インテリジェント仮想チームを形成するためのアシスタントシステムを内蔵するようになるでしょう。
2. インテリジェント システムの目的は、人間に取って代わることではなく、人間がより効率的に作業できるように人間の知能を強化することです。
3. ペットの猫でさえ、AI システムが構築できるよりも複雑なモデルを脳内に持っています。
4. FAIR は基本的に言語モデルに焦点を当てなくなり、次世代 AI システムの長期目標に向かって進みます。
5. AI システムは、テキスト データのみのトレーニングでは人間レベルに近い知能を達成することはできません。
6. Yann Lecun は、生成モデル、確率モデル、対照学習、強化学習を放棄し、代わりに JEPA アーキテクチャとエネルギーベースのモデルを採用することを提案しました。これらの方法は AI の開発を促進する可能性が高いと考えられています。
7. 機械は最終的には人間の知性を超えるでしょうが、機械は目標主導型であるため、制御されることになります。
興味深いことに、スピーチが始まる前にエピソードがありました。
司会者が LeCun を紹介したとき、彼は彼を Facebook AI Research Institute (FAIR)の主任 AI 科学者と呼びました。
この点に関して、ルカン氏は講演前に、FAIRの「F」はもはやFacebookを表すものではなく、「 Fundamental 」を意味すると明言した。
以下のスピーチの原文はAPPSOによって編集され、編集されています。最後に、元のビデオのリンクが添付されています: https://www.youtube.com/watch?v=4DsCtgtQlZU
AI は猫ほど世界を理解しているわけではありません
それでは、人間レベルの AI について、どのようにしてそこに到達するのか、そしてなぜそこに到達できないのかについてお話します。
まず、人間レベルのAIが本当に必要です。
なぜなら、将来的には、私たちのほとんどがスマートグラスやその他の種類のデバイスを着用するようになるからです。私たちはこれらのデバイスと通信することになり、これらのシステムはアシスタント、おそらくは複数のアシスタント、場合によってはアシスタントのスイート全体をホストすることになります。
これにより、私たち一人ひとりが本質的に、私たちのために働くインテリジェントな仮想チームを持つことになります。
したがって、誰もが「上司」になりますが、この「従業員」は生身の人間ではありません。私たちはこのようなシステムを構築する必要がありますが、これは基本的に人間の知性を強化し、人々をより創造的かつ効率的にするためです。

しかしそのためには、世界を理解し、物事を記憶し、直感と常識を持ち、人間と同じレベルで推論して計画を立てることができる機械が必要です。
ただし、現在の AI システムにはこれらの機能が備わっていないという支持者の声を聞いたことがあるかもしれません。したがって、私たちは時間をかけて世界をモデル化する方法を学び、世界がどのように機能するかについてのメンタルモデルを作成する必要があります。
事実上すべての動物にはそのようなモデルがあります。あなたの猫には、どの AI システムでも構築または設計できるよりも複雑なモデルが必要です。

現在の言語モデル(LLM)にはない永続的なメモリを備えたシステム、今日のシステムでは実行できない複雑な一連のアクションを計画できるシステム、および制御可能で安全なシステムが必要です。
そこで、私は目標駆動型AIと呼ばれるアーキテクチャを提案します。私はこれについて約 2 年前にビジョンペーパーを書き、出版しました。 FAIRの多くの人々がこの計画を実現するために懸命に働いています。
FAIR は過去にさらに多くのアプリケーション プロジェクトに取り組んできましたが、Meta は AI 製品に注力するために 1 年半前にジェネレーティブ AI (Gen AI)と呼ばれる製品部門を設立しました。
彼らは応用研究開発を行っているため、FAIR は現在、次世代 AI システムの長期目標に向けて方向転換しています。私たちは基本的に言語モデルに焦点を当てなくなりました。
大規模言語モデル(LLM)を含む AI の成功、特に過去 5 ~ 6 年間の他の多くのシステムの成功は、もちろん自己教師あり学習を含むさまざまなテクニックに依存しています。

自己教師あり学習の中核は、特定のタスク用にシステムをトレーニングするのではなく、入力データを適切な方法で表現しようとすることです。これを達成する 1 つの方法は、損傷と再構築による回復です。
したがって、テキストの一部を取り出して、いくつかの単語を削除したり、他の単語を変更したりすることで、それを破損することができます。このプロセスは、テキスト、DNA 配列、タンパク質、その他あらゆるもの、さらにはある程度の画像にも使用できます。次に、大規模なニューラル ネットワークをトレーニングして、完全な入力、つまり破損していないバージョンを再構築します。
これは、元の信号を再構築しようとするため、生成モデルです。
つまり、赤いボックスはコスト関数のようなものですよね?入力 Y と再構成された出力 y の間の距離を計算します。これは、学習プロセス中に最小化されるパラメーターです。このプロセスでは、システムは入力の内部表現を学習し、その後のさまざまなタスクに使用できます。
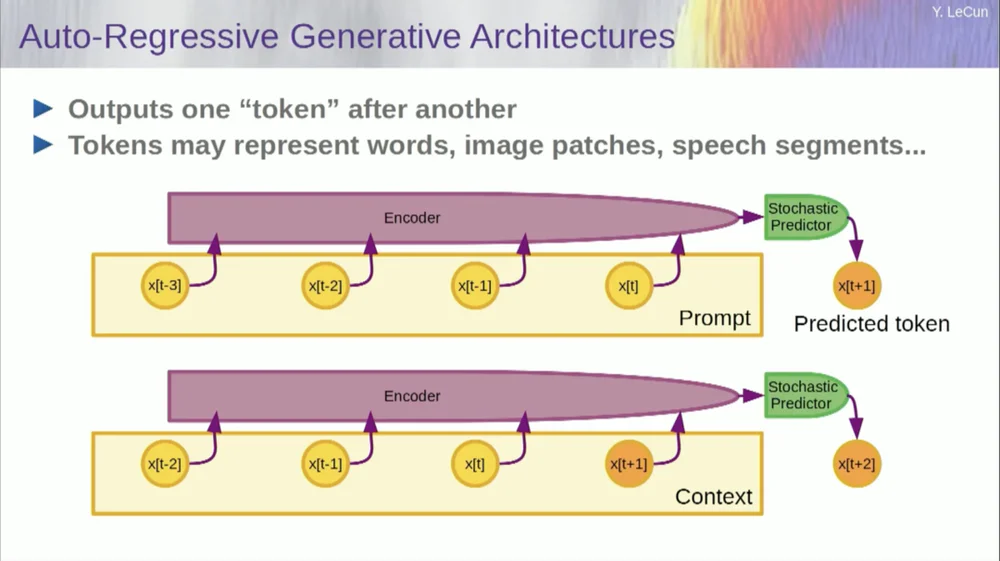
もちろん、これを使用してテキスト内の単語を予測することもできます。これが自己回帰予測の機能です。
言語モデルはこれの特殊なケースであり、項目、トークン、または単語を予測するときに、その左側にある他のトークンのみを参照できるようにアーキテクチャが設計されています。
未来を見ることはできません。システムを正しくトレーニングし、テキストを表示し、テキスト内の次の単語または次のトークンを予測するように依頼すると、システムを使用して次の単語を予測できます。次に、その次の単語を入力に追加して 2 番目の単語を予測し、それを入力に追加して 3 番目の単語を予測します。
これは自己回帰予測です。
これは LLM が行うことです。新しい概念ではありません。シャノンの時代から存在し、はるか昔の 50 年代に遡ります。しかし、変化は、現在では大規模なニューラル ネットワーク アーキテクチャが存在することです。大量のデータとそこから特徴が現れるようになるでしょう。
しかし、この種の自己回帰予測にはいくつかの大きな制限があり、通常の意味での本当の推論はここにはありません。
さらにもう 1 つの制限は、これが離散オブジェクト、シンボル、トークン、単語など、基本的には離散化できるものの形式のデータに対してのみ機能することです。
人間レベルの知能に到達するという点では、私たちはまだ何か重要な点を見逃しています。
ここで必ずしも人間レベルの知能について話しているわけではありませんが、あなたの猫や犬でさえ、現在の AI システムでは到達できない驚くべき偉業を達成することができます。

10 歳の子供なら誰でも、一度にテーブルを片づけたり、食器洗い機に水を入れることを学ぶことができますよね。練習とかそんな必要ないですよね?
17歳の少年が運転を覚えるには約20時間の練習が必要だ。
私たちはまだレベル5の自動運転車を持っていませんし、テーブルを片付けたり食器洗い機に水を入れることができる家庭用ロボットも当然ありません。
AI はテキストだけでトレーニングしても人間レベルの知能に近づくことはありません
つまり、AI システムを使用してこれらのことを実行できるはずの重要な何かが本当に欠けているのです。
私たちはモラヴェックのパラドックスと呼ばれるものに遭遇し続けています。これは、私たちにとって些細なことのように見え、知的であるとさえ考えられないものは、実際には機械で行うのは非常に困難であり、操作言語のような高レベルの複雑な抽象的思考が可能であるようです。機械にとっては非常に単純であり、チェスや囲碁などにも同じことが当てはまります。
おそらく理由の 1 つはこれです。
大規模言語モデル(LLM)は通常、20 兆のトークンでトレーニングされます。
トークンは基本的に平均して単語の 4 分の 3 です。したがって、合計 1.5×10^13 ワードになります。各トークンは約 3B で、通常、これには 6×1013 バイトが必要です。
私たちがこれを読むには、数十万年かかるでしょう?これは基本的に、インターネット上のすべての公開テキストを組み合わせたものです。

しかし、4 歳児の場合、合計 16,000 時間起きていることを考えてください。私たちの脳には200万本の視神経線維が入っています。各神経線維は 1 秒あたり約 1B、おそらく 1 秒あたり 0.5 バイトの速度でデータを送信します。一部の推定では、これは 1 秒あたり 30 億になる可能性があります。
それは問題ではありません、とにかく桁違いです。
このデータ量は約 10 の 14 乗バイトであり、LLM とほぼ同じ桁です。つまり、4 年間で、4 歳児は、インターネット全体で公開されているテキストでトレーニングされた最大の言語モデルと同じくらい多くの視覚データを見たことになります。
このデータを出発点として使用すると、いくつかのことがわかります。
まず、これは、単にテキストでトレーニングしただけでは人間レベルの知能に近づくことは決してできないことを示しています。これは決して起こりません。
次に、視覚情報は非常に冗長であり、各視神経線維は 1 秒あたり 1B の情報を送信しますが、これは網膜の光受容体と比較してすでに 100 対 1 に圧縮されています。
私たちの網膜には約 6,000 万から 1 億個の光受容体があります。これらの光受容体は、網膜前面のニューロンによって 100 万本の神経線維に圧縮されます。つまり、すでに 100 対 1 の圧縮が行われています。そして脳に届くまでに情報は約50倍に拡張されます。
つまり、私が測定しているのは圧縮された情報ですが、それでも非常に冗長です。そして、冗長性は実際に自己教師あり学習に必要なものです。自己教師あり学習では、データが高度に圧縮されている場合、つまりデータがランダムなノイズになっている場合、冗長なデータから有用なことのみを学習できます。
何かを学ぶには冗長性が必要です。データの基礎となる構造を学ぶ必要があります。したがって、ビデオを見たり現実世界で生活したりすることで、常識や物理学を学ぶシステムを訓練する必要があります。
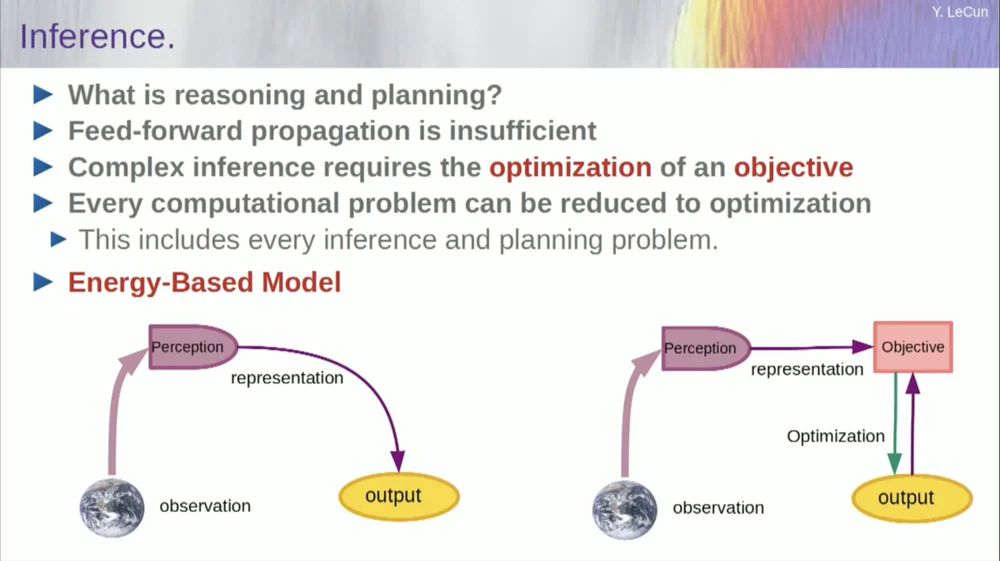
私の言葉の順序は少しわかりにくいかもしれませんが、主にこの目標駆動型の人工知能アーキテクチャとは何なのかを説明したいと思います。推論プロセスがニューラル ネットワークの一連の層を通過するだけでなく、実際に最適化アルゴリズムを実行するという点で、LLM やフィードフォワード ニューロンとは大きく異なります。
概念的にはこんな感じです。
フィードフォワード プロセスは、観察が知覚システムを介して実行されるプロセスです。たとえば、一連のニューラル ネットワーク層があり、出力を生成する場合、単一の入力に対して出力は 1 つしかありませんが、多くの場合、知覚については複数の可能な出力解釈が存在する可能性があります。機能を計算するだけでなく、単一の入力に対して複数の出力を提供するマッピング プロセスが必要です。これを実現する唯一の方法は、暗黙的な関数を使用することです。
基本的に、この目標フレームワークの右側にある赤いボックスは、基本的に入力とその提案された出力の間の互換性を測定し、入力と最も互換性のある出力値を見つけて出力を計算する関数を表します。この目標はある種のエネルギー関数であり、出力を変数としてこのエネルギーを最小化していると想像できます。
複数の解決策があり、それらの複数の解決策を処理する何らかの方法がある場合があります。これは人間の知覚システムにも当てはまります。特定の認識に対して複数の解釈がある場合、脳は自動的にそれらの解釈を循環します。したがって、この種のことが実際に起こるという証拠がいくつかあります。
さて、アーキテクチャの話に戻りましょう。したがって、最適化による推論のこの原則を利用してください。以下は、人間の心の仕組みについての仮定です。あなたは世界を観察します。知覚システムは世界の現状を把握します。しかしもちろん、それはあなたが現在認識できる世界の状態についてのアイデアを与えるだけです。
世界の他の地域の状況について、いくつかの思い出があるかもしれません。これを記憶の内容と組み合わせて、世界のモデルに組み込むことができます。
モデルとは何ですか?世界モデルは、世界で自分がどのように行動するかを示すメンタル モデルです。そのため、自分が取る可能性のある一連の行動を想像することができ、世界モデルを使用すると、それらの一連の行動が世界に及ぼす影響を予測できます。
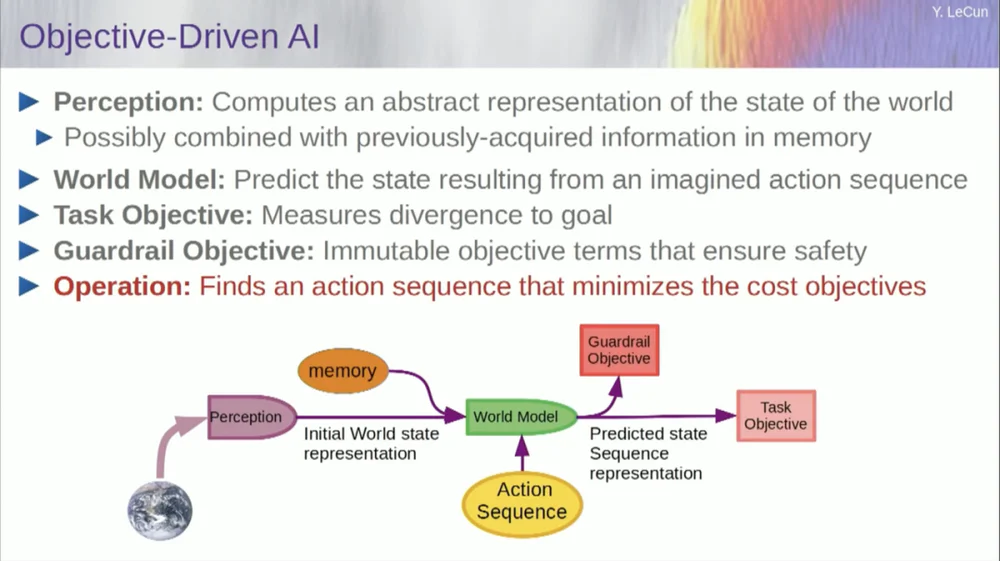
つまり、緑色のボックスは、世界の最終状態がどのようになるか、または世界で起こると予測する軌跡全体を予測する一連の仮説的なアクションを入力する世界モデルを表しています。
それを一連の目的関数と組み合わせます。 1 つの目標は、目標がどの程度達成されているか、タスクが完了したかどうか、および場合によっては安全マージンとして機能する他の一連の目標を測定することであり、基本的には、軌跡がたどったか、実行されたアクションがロボットに危険を及ぼさない程度を測定します。または機械の周りの人などが待機します。
したがって、推論プロセス(学習についてはまだ話していません)は単なる推論であり、これらの目標を最小化する一連のアクションを見つけること、これらの目標を最小化する一連のアクションを見つけることで構成されます。これが推論のプロセスです。
したがって、これは単なるフィードフォワードプロセスではありません。個別のオプションを検索することでこれを行うこともできますが、それは効率的ではありません。より良いアプローチは、これらすべてのボックスが微分可能であることを確認し、それらを介して勾配を逆伝播し、勾配降下法を介してアクションのシーケンスを更新することです。

さて、このアイデアは実際には新しいものではなく、60 年以上、おそらくはさらに古くから存在しています。まず、この種の推論に世界モデルを使用する利点について話しましょう。利点は、学習を必要とせずに新しいタスクを完了できることです。
私たちは時々これを行います。新しい状況に直面したとき、私たちはそれについて考え、自分の行動がもたらす結果を想像し、 (それが何であれ)目標を達成するための一連の行動をとります。そのタスクを達成するために学ぶ必要はありません。 、計画を立てることができます。つまり、基本的には計画です。
ほとんどの推論形式は最適化に要約できます。したがって、最適化による推論のプロセスは、ニューラル ネットワークの複数の層を単に実行するよりも本質的に強力です。先ほども述べたように、最適化による推論という考え方は 60 年以上前から存在しています。
最適制御理論の分野では、これをモデル予測制御と呼びます。
ロケット、飛行機、ロボットなど、制御したいシステムのモデルがあります。ワールド モデルを使用して、一連の制御コマンドの効果を計算することを想像してみてください。
次に、動きが望ましい結果を達成できるように、このシーケンスを最適化します。古典的なロボット工学におけるすべての動作計画はこの方法で行われ、それは何も新しいことではありません。ここでの新規性は、私たちが世界のモデルを学習し、知覚システムが適切な抽象表現を抽出することです。
さて、このシステムの実行方法の例に入る前に、これらすべてのコンポーネントを備えた全体的な AI システムを構築できます: ワールド モデル、当面のタスク用に構成できるコスト関数、最適化モジュール(つまり、真の最適化、世界モデルのアクションの最適なシーケンスを決定する特定のモジュールの発見、短期記憶、知覚システムなど。
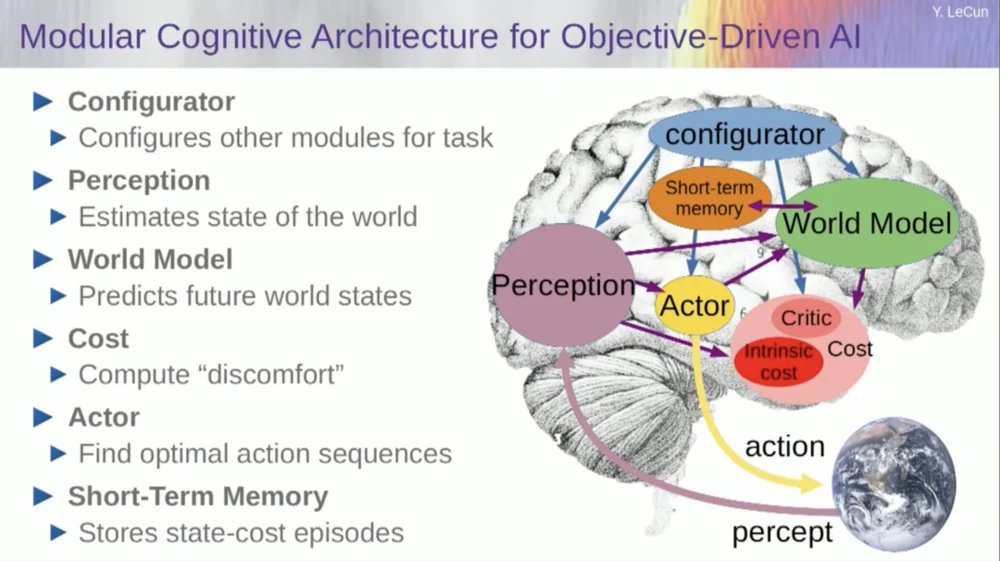
それで、これはどのように機能するのでしょうか?アクションが単一のアクションではなく、一連のアクションであり、世界モデルが実際には、時間 T での世界の状態と考えられるアクションを考慮して、時間 T+1 での世界の状態を予測するように指示するシステムである場合。
この状況で 2 つのアクションのシーケンスがどのような影響を与えるかを予測したいとします。これを達成するために、ワールド モデルを複数回実行できます。
初期ワールド状態表現を取得し、アクションにゼロの仮定を入力し、モデルを使用して次の状態を予測し、次にアクション 1 を実行し、次の状態を計算し、コストを計算して、バックプロパゲーションと勾配ベースの最適化手法を使用して、 2 つのアクションのコストを最小限に抑えるものを見つけます。これがモデル予測制御です。
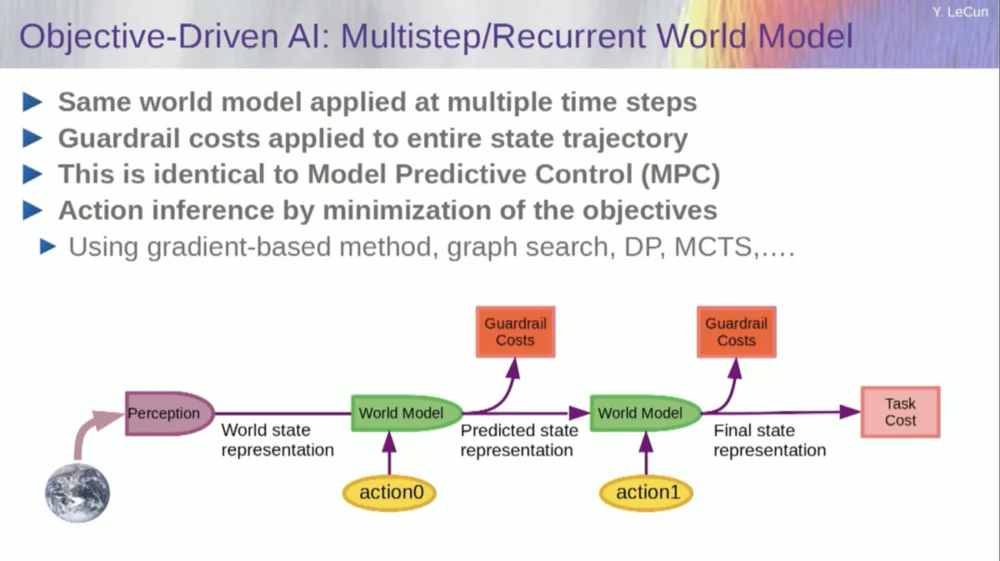
さて、世界は完全に決定的ではないため、世界のモデルに適合させるために潜在変数を使用する必要があります。潜在変数は基本的に、一連のデータ内で切り替えることができる、または分布から引き出すことができる変数であり、観測と互換性のある複数の予測間での世界モデルの切り替えを表します。
さらに興味深いのは、インテリジェント システムは現在、人間や動物でさえも実行できること、つまり階層的計画を実行できないことです。
たとえば、ニューヨークからパリへの旅行を計画している場合、世界についての理解、自分の身体、そしておそらくここからパリまでの全体構成についてのアイデアを利用して、旅行全体を計画することができます。低レベルの筋肉の移動。
右?パリに行く前にしなければならないすべてのことの10ミリ秒あたりの筋肉制御ステップ数を合計すると、それは膨大な数になります。つまり、階層的な計画方法で計画を立てるのです。非常に高いレベルから始めて、「分かった、パリに行くには、まず空港に行って飛行機に乗らなければならない」と言うのです。
空港へはどうやって行けばいいですか?私がニューヨーク市にいて、階下に行ってタクシーを拾わなければならないとしましょう。どうやって階下に行くのですか?椅子から立ち上がって、ドアを開けて、エレベーターまで歩いて、ボタンを押さなければなりません。どうすれば椅子から立ち上がることができますか?
ある時点で、物事を低レベルの筋肉制御アクションとして表現する必要がありますが、私たちは全体を低レベルの方法で計画しているのではなく、階層的な計画を行っています。

AI システムを使用してこれを行う方法はまだ完全に未解決であり、手がかりはありません。
これは、知的な行動にとって重要な要件であると思われます。
では、階層的な計画が可能で、さまざまな抽象レベルで機能する世界モデルをどのように学習すればよいのでしょうか?これに近いものを示した人は誰もいません。これは大きな課題です。画像は先ほど述べた例を示しています。
では、この世界モデルを今どのようにトレーニングすればよいのでしょうか?なぜなら、これは確かに大きな問題だからです。
私は、赤ちゃんが世界についての基本的な概念を何歳で学ぶかを調べようとしています。彼らは直感的な物理学や物理的直観などをどのようにして学ぶのでしょうか?これは、言語や相互作用などの学習を始めるずっと前に起こります。
したがって、顔追跡のような機能は実際には非常に早い段階で実現されます。生物の動き、つまり生物と無生物の区別も初期に現れます。同じことがオブジェクトの恒常性にも当てはまります。これは、オブジェクトが別のオブジェクトによって隠されている場合でも存続するという事実を指します。
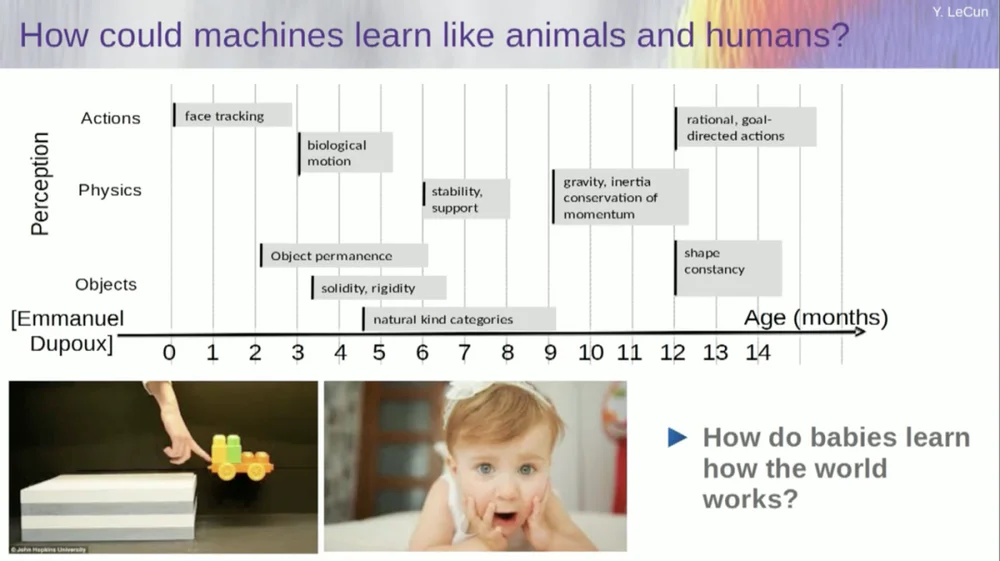
赤ちゃんは自然に学習するため、物に名前を付ける必要はありません。彼らは椅子、テーブル、猫が違うことを知るでしょう。重力、慣性、保存、運動量などの安定性や支持などの概念は、実際には生後 9 か月頃まで現れません。
これには長い時間がかかります。したがって、生後 6 か月の赤ちゃんに左のシナリオを見せると、カートが台の上にあり、台から押し出すと、カートが空中に浮かんでいるように見えます。生後6か月の赤ちゃんはこれに気づきますが、生後10か月の赤ちゃんは「こんなことはあってはならない、物体が落ちるべきだ」と感じるでしょう。
何か予期せぬことが起こったとき、それはあなたの「世界のモデル」が間違っていることを意味します。死ぬ可能性があるので注意してください。
したがって、ここで行う必要がある学習の種類は、以前に説明した学習の種類と非常に似ています。
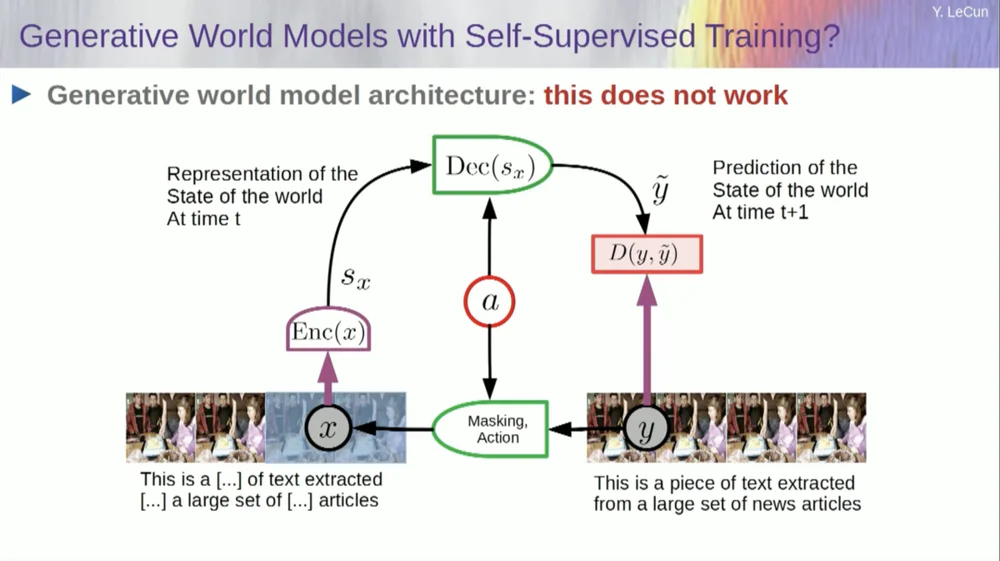
入力を取得し、何らかの方法で破損させ、欠落部分を予測するために大規模なニューラル ネットワークをトレーニングします。テキストで何が起こるかを予測するためにニューラル ネットワークを訓練するのと同じように、ビデオで何が起こるかを予測するようにシステムを訓練すれば、おそらくそれらのシステムは常識を学習できるでしょう。
残念ながら、私たちはこれを10年間試みてきましたが、完全に失敗していました。ビデオ内のピクセルを予測しようとするだけで、実際に一般知識を学習できるシステムにはまだ近づいていません。
見栄えの良いビデオを予測するシステムをトレーニングできます。ビデオ生成システムの例は数多くありますが、内部的には物理世界の良いモデルではありません。彼らとはそんなことはできません。
そうですね、生成モデルを使用して個人に何が起こるかを予測し、システムが魔法のように世界の構造を理解するという考えは完全に失敗です。
過去 10 年間、私たちは多くのアプローチを試してきました。
考えられる未来はたくさんあるので、失敗します。テキストのような離散空間では、単語の文字列の後にどの単語が続くかを予測でき、辞書内の可能性のある単語の確率分布を生成できます。しかし、ビデオ フレームに関しては、ビデオ フレームの確率分布を表す適切な方法がありません。実際、この作業は完全に不可能です。

この部屋のビデオを撮りましたよね?私はカメラを持ってその部分を撮影し、ビデオを停止しました。私はシステムに次に何が起こるかを尋ねました。残りの部屋を予測できるかもしれません。壁があり、そこに人が座っており、その密度はおそらく左側のものと同様になるでしょう。しかし、各人がどのように見えるかの詳細をすべてピクセルレベルで正確に予測することは絶対に不可能です。 、世界のテクスチャ、部屋の正確なサイズ。
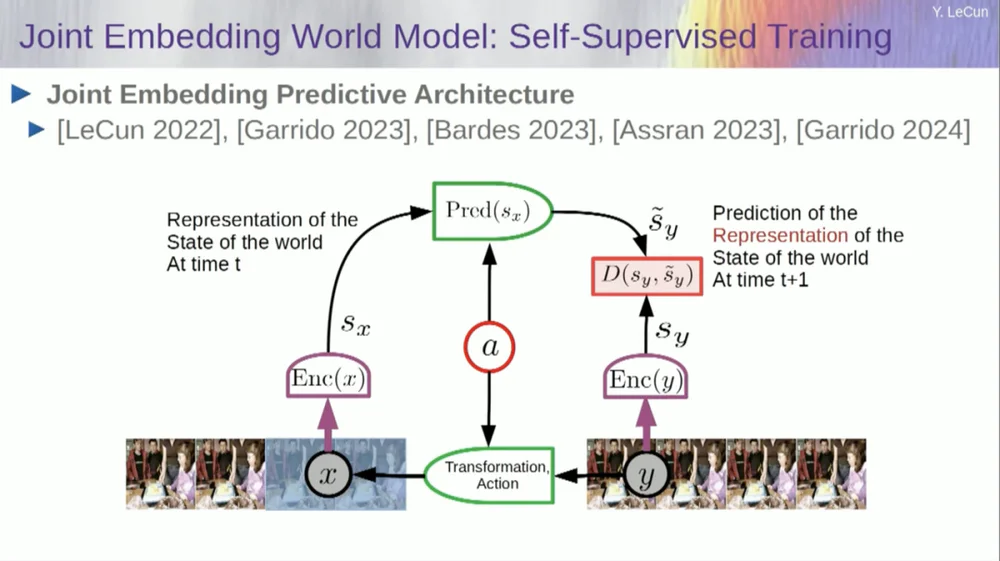
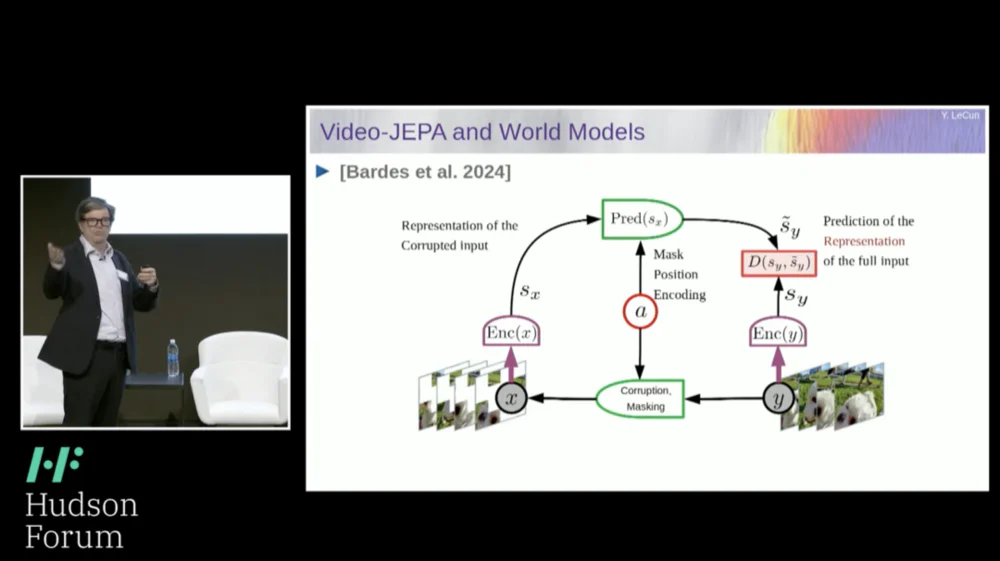
そこで、私が提案するソリューションは、Joint Embedding Prediction Architecture (JEPA)です。
このアイデアは、ピクセルの予測を放棄し、代わりに世界がどのように機能するかの抽象的な表現を学習し、この表現空間内で予測を行うことです。それがアーキテクチャ、つまり結合埋め込み予測アーキテクチャです。これら 2 つの埋め込みはそれぞれ X (破損したバージョン)と Y を受け取り、エンコーダーによって処理され、X の表現に基づいて Y の表現を予測するようにシステムがトレーニングされます。
ここで問題は、予測誤差を最小限に抑えるために勾配降下法やバックプロパゲーションだけを使用してそのようなシステムを訓練すると、崩壊してしまうことです。定数表現を学習するため、予測は非常に単純になりますが、有益ではなくなります。
したがって、覚えておいていただきたいのは、予測を再構築しようとするオートエンコーダー、生成アーキテクチャ、マスクされたオートエンコーダーなどと、表現空間で予測を行う結合埋め込みアーキテクチャとの違いです。
私は、未来はこれらの共同埋め込みアーキテクチャにあると考えています。また、優れた画像表現を学ぶための最良の方法は共同編集アーキテクチャを使用することであるという多くの経験的証拠を持っています。
再構成を通じて画像表現を学習する試みはどれも貧弱でうまく機能しません。多くの大規模プロジェクトが機能すると主張していますが、実際は機能せず、右側のアーキテクチャで最高のパフォーマンスが得られます。
さて、考えてみると、これがまさに私たちの知性の本質です。つまり、現象の適切な表現を見つけて予測できるようにすること、それがまさに科学の本質なのです。
本物。考えてみてください。惑星の軌道を予測したい場合、惑星は非常に複雑な物体であり、巨大であり、天候、温度、密度などのあらゆる種類の特性を持っています。
惑星は複雑な物体ですが、惑星の軌道を予測するには、3 つの位置座標と 3 つの速度ベクトルの 6 つの数値を知るだけで済み、他に何もする必要はありません。これは、予測力の本質は、私たちが観察しているものを適切に表現できるかどうかにあることを示す、非常に重要な例です。

では、そのようなシステムをどのようにトレーニングすればよいのでしょうか?
したがって、システムのクラッシュを防ぐ必要があります。これを行う 1 つの方法は、エンコーダによって出力された表現の情報内容を測定し、情報内容を最大化し、負の情報を最小化しようとするある種のコスト関数を使用することです。トレーニング システムは、その表現空間における予測誤差を最小限に抑えながら、同時に入力からできるだけ多くの情報を抽出する必要があります。
システムは、可能な限り多くの情報を抽出することと、予測不可能な情報を抽出しないこととの間で何らかのトレードオフを見つけます。予測を行うことができる適切な表現空間が得られます。
では、どうやって情報を測定するのでしょうか?ここで事態は少し奇妙になります。これは飛ばします。
機械は人間の知性を超え、安全かつ制御可能になるでしょう
実際には、トレーニング、エネルギーベースのモデル、エネルギー関数を通じてこれを数学的に理解する方法がありますが、それについて説明する時間はありません。
基本的に、私はここでいくつかの異なることを伝えています。JEPAアーキテクチャを支持して生成モデルを放棄し、エネルギーベースのモデルを支持して確率モデルを放棄し、対照学習手法と強化学習を放棄します。私はこれを10年間言い続けています。
これらは、今日の機械学習の最も人気のある 4 つの柱です。なので、今はあまり人気がないのかもしれません。
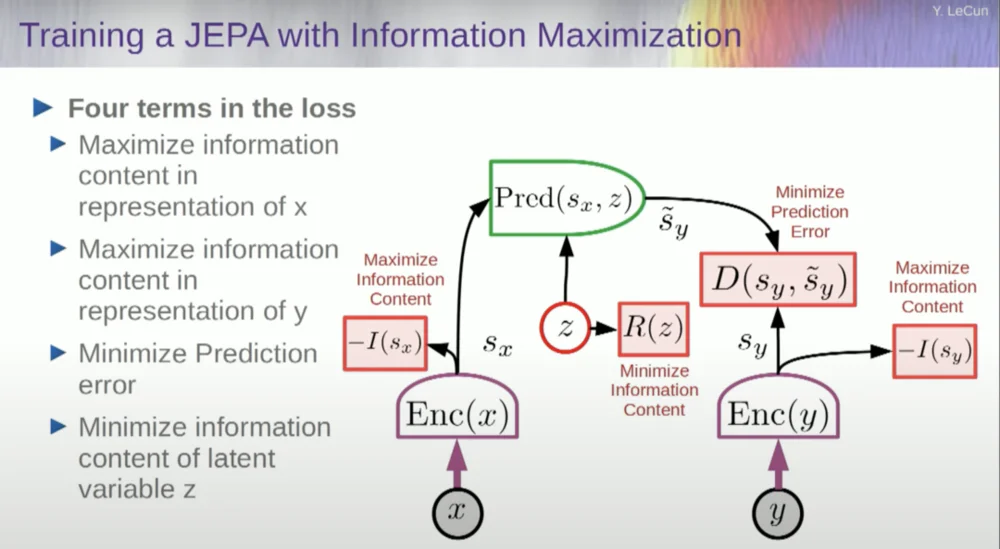
1 つのアプローチは、エンコーダーからの情報コンテンツを測定して、情報コンテンツを推定することです。
これを実現するには現在 6 つの異なる方法があります。実際、ニューヨーク大学の同僚が考案した MCR と呼ばれる方法があり、システムがクラッシュして定数が生成されるのを防ぎます。
エンコーダーから変数を取得し、これらの変数の標準偏差がゼロでないことを確認します。これをコスト関数に入れて、重みが検索され、変数が崩壊して定数にならないことを確認できます。これは比較的簡単です。
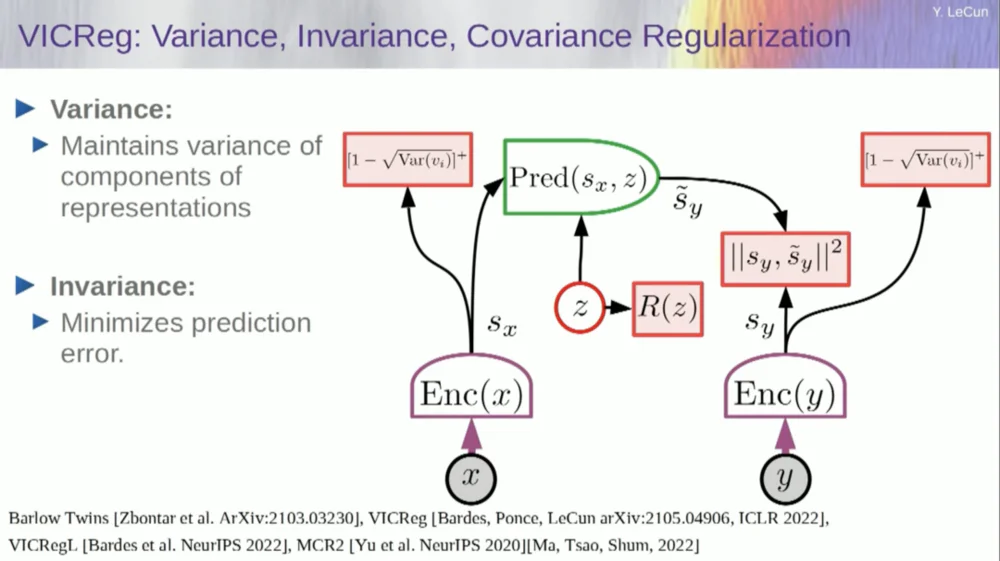
現在の問題は、システムが「不正」を行い、すべての変数を同等または高度に相関させることができることです。したがって、これらの変数の関連性を確保するには、これらの変数の共分散行列を最小化するために必要な非対角項という別の項を追加する必要があります。
もちろん、これでは十分ではありません。変数は依然として依存している可能性がありますが、関連性はありません。したがって、SX の次元を高次元空間 VX に拡張する別の方法を採用し、この空間に分散共分散正則化を適用して、要件が確実に満たされるようにします。
ここでもう 1 つのトリックがあります。最大化しているのは情報量の上限であるためです。実際の情報量も上限の最大化に従うようにしたい。必要なのは下限値であり、下限値を押し上げて情報が増加します。残念ながら、下限に関する情報がないか、少なくとも下限を計算する方法がわかりません。
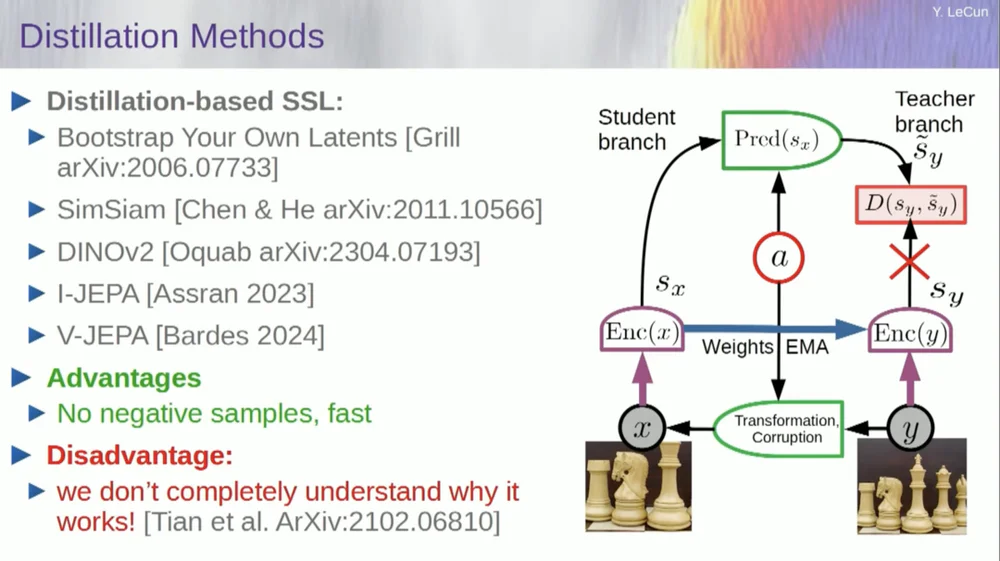
「蒸留スタイル法」と呼ばれる 2 番目の方法セットがあります。
この方法は不思議な方法で機能します。誰が何をしているのか正確に知りたければ、ここグリルに座っている男に尋ねるべきです。
彼はこれについて非常によく定義した個人的なエッセイを持っています。その中心となるアイデアは、他の部分に勾配を逆伝播させることなくモデルの 1 つの部分のみを更新し、興味深い方法で重みを共有することです。この点に関する論文も数多くあります。
このアプローチは、完全に自己教師型のシステムをトレーニングして適切な画像表現を生成する場合に効果的です。画像の破棄はマスキングによって行われ、ビデオに対して行った最近の作業によって、アクション認識ビデオなどの下流タスクで使用するために適切なビデオ表現を抽出するシステムをトレーニングできるようになりました。ビデオの大部分をマスキングしてこのプロセスを通じて予測を行うと、表現空間でこの蒸留トリックを使用して崩壊を防ぐことがわかります。これはうまくいきます。
したがって、もし私たちがこのプロジェクトに成功し、物理世界を推論し、計画し、理解できるシステムを完成させれば、これが将来の私たちのすべてのやり取りの様子になるでしょう。
すべてが適切に機能するようになるには、数年、場合によっては 10 年かかるでしょう。マーク・ザッカーバーグは、どれくらい時間がかかるかを私に尋ね続けます。それが成功すれば、デジタル世界とのすべてのやり取りを仲介するシステムができることになります。彼らは私たちの質問にすべて答えてくれます。
彼らは長い間私たちとともにいて、本質的に人類のすべての知識の宝庫を形成するでしょう。これはインターネットのようなインフラストラクチャのようなものだと感じます。これは製品というよりはインフラストラクチャです。
これらの AI プラットフォームはオープンソースである必要があります。 IBM と Meta は、オープンソースの人工知能プラットフォームを推進する Artificial Intelligence Alliance と呼ばれるグループに参加しています。これらの AI システムには多様性が必要なので、これらのプラットフォームをオープンソースにする必要があります。

私たちは彼らに世界中のすべての言語、すべての文化、すべての価値観を理解してもらう必要がありますが、米国の西海岸や東海岸の企業が製造した単一のシステムだけではそれを理解することはできません。州。これは世界中からの貢献に違いありません。
もちろん、財務モデルのトレーニングには非常に費用がかかるため、これを実行できる企業はわずかです。 Meta のような企業が基礎となるモデルをオープンソースとして提供できれば、世界はそれを自社の目的に合わせて微調整することができます。これは、Meta と IBM が採用した哲学です。

したがって、オープンソース AI は単に良いアイデアであるだけでなく、文化の多様性、さらには民主主義の維持にも必要なのです。
トレーニングと微調整は、クラウドソーシングを通じて、またはスタートアップや他の企業のエコシステムによって行われます。
AI スタートアップ エコシステムの成長を促進しているものの 1 つは、これらのオープンソース AI モデルの可用性です。一般的な人工知能に到達するにはどれくらい時間がかかりますか?わかりませんが、数年から数十年かかる可能性があります。

その過程では多くの変化があり、解決しなければならない問題はまだ多くあります。これはほぼ間違いなく、私たちが思っているよりも難しいでしょう。これは 1 日にして起こるものではなく、徐々に段階的に進化していきます。
つまり、いつか私たちが一般的な人工知能の秘密を発見し、機械をオンにすると即座に超知能を手に入れ、私たち全員が超知能によって一掃されるというわけではありません。いいえ、そうではありません。
機械は人間の知性を超えるでしょうが、目標駆動型であるため制御下に置かれることになります。私たちは彼らに目標を設定し、彼らはそれを達成します。私たちの多くと同じように、ここにいるのは産業界や学術界のリーダーです。
私たちは自分たちよりも賢い人々と一緒に仕事をしていますし、私ももちろんそうしています。私より賢い人がたくさんいるからといって、彼らが支配したり乗っ取りたいわけではありません。それが問題の真実です。もちろん、これにはリスクがありますが、それについては後で議論することにします、ありがとうございました。