科学研究効率化アーティファクト OpenScholar がリリースされ、科学研究者の文献レビュー体験が完全に変わります。 Downcodes のエディターは、この AI 主導の科学研究ツールを提供します。これには、4 億 5,000 万件のオープンアクセス論文と 2 億 3,700 万件の記事段落の埋め込みがあり、科学研究の質問に関連する文書を迅速かつ正確に除外し、参考文献に対する完全な回答を生成できます。 OpenScholar は強力であるだけでなく、自ら学習して改善し、回答の質を継続的に向上させ、最終的には最も完璧な科学研究結果を提示することができます。また、より小型で効率的なモデルをトレーニングするために使用することもでき、科学研究の分野に革命的な変化をもたらします。
文献をレビューするために夜更かしして論文を書いていませんか? AI2 の科学研究の専門家が、この科学研究の効率化ツールを使ってあなたを救います!公園を散歩しているように!
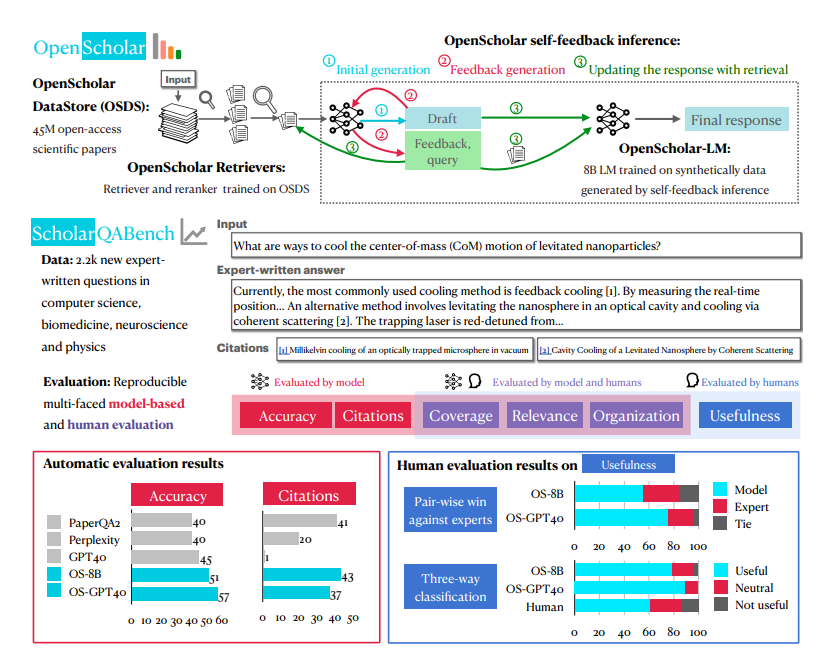
OpenScholar の最大の秘密兵器は、4 億 5,000 万件のオープンアクセス論文と 2 億 3,700 万件の埋め込み記事パラグラフを備えた OpenScholar-Datastore (OSDS) と呼ばれるシステムです。このような強力な知識ベースにより、OpenScholar はさまざまな科学研究の問題に簡単に対処できます。
科学研究の問題に遭遇すると、OpenScholar はまず、その問題に関連する論文の段落を OSDS からすばやくフィルタリングするために、強力なツールであるサーチャーと並べ替え機能を送信します。次に、言語モデル (LM) には、リファレンスに対する完全な回答が含まれています。さらに強力なのは、OpenScholar が自然言語フィードバックに基づいて回答を改善し続け、満足するまで不足している情報を補足することです。
OpenScholar は、それ自体が強力であるだけでなく、より小型で効率的なモデルのトレーニングにも役立ちます。研究者らは、OpenScholar のプロセスを使用して大量の高品質トレーニング データを生成し、このデータを使用して OpenScholar-8B と呼ばれる 80 億パラメータの言語モデルや他の検索モデルをトレーニングしました。
OpenScholar の戦闘効果を包括的にテストするために、研究者たちは SCHOLARQABENCH と呼ばれる新しいテスト アリーナも特別に作成しました。このアリーナでは、クローズド分類、多肢選択、長文生成などのさまざまな科学文献レビュー タスクが設定され、コンピューター サイエンス、生物医学、物理学、神経科学などの複数の分野をカバーしています。コンテストの公平性と正義を確保するために、SCHOLARQABENCH は専門家によるレビュー、自動指標、ユーザー エクスペリエンス テストなどの多面的な評価方法も使用しています。
何度も激しい競争を繰り広げた結果、OpenScholar がついに頭角を現しました! 実験結果では、人間の専門家をも上回る優れたパフォーマンスを示しました。この画期的な結果は、科学研究の分野に革命をもたらし、科学者に困難を別れさせるでしょう。科学の謎を探求することに焦点を当てた文学作品レビュー!
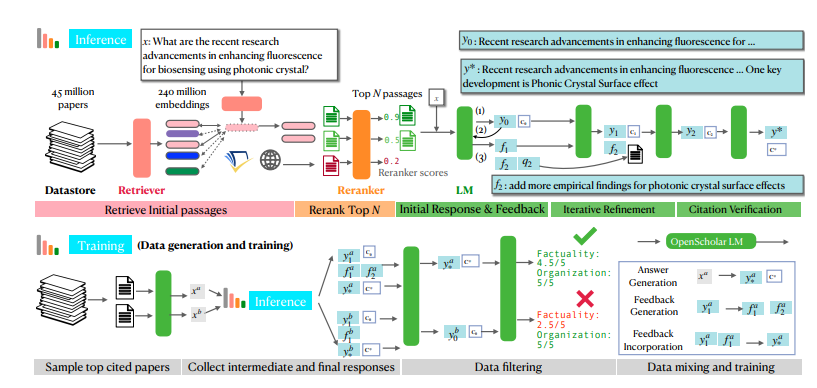
OpenScholar の強力な機能は、主に、その独自の自己フィードバック検索強化推論メカニズムから恩恵を受けます。簡単に言うと、まず自分自身に質問をし、次に自分自身の答えに基づいて答えを継続的に改善し、最終的に最も完璧な答えを提示します。すごいと思いませんか?
具体的には、OpenScholar の自己フィードバック推論プロセスは、最初の回答の生成、フィードバックの生成、フィードバックの統合の 3 つのステップに分かれています。 まず、言語モデルは、取得された記事の一節に基づいて最初の回答を生成します。次に、厳しい試験官のように、回答を自己批判し、欠点を特定し、「回答には質疑応答タスクの実験結果のみが含まれています。他の種類のタスクの結果を補足してください」などの自然言語フィードバックを生成します。 。 最後に、言語モデルは、このフィードバックに基づいて関連文献を再検索し、すべての情報を統合して、より完全な答えを生成します。
小さいながらも同様に強力なモデルをトレーニングするために、研究者らはまた、OpenScholar の自己フィードバック推論プロセスを使用して、大量の高品質のトレーニング データを生成しました。 彼らはまずデータベースから最も引用された論文を選択し、次にこれらの論文の要約に基づいていくつかの情報クエリの質問を生成し、最後に OpenScholar の推論プロセスを使用して高品質の回答を生成しました。これらの回答とそのプロセスで生成されるフィードバック情報は、貴重なトレーニング データを構成します。 研究者らは、このデータを既存の一般的なドメイン命令の微調整データおよび科学的なドメイン命令の微調整データと混合して、OpenScholar-8B と呼ばれる 80 億パラメータ言語モデルをトレーニングしました。
OpenScholar および他の同様のモデルのパフォーマンスをより完全に評価するために、研究者らは SCHOLARQABENCH と呼ばれる新しいベンチマークも作成しました。 このベンチマークには、コンピュータ サイエンス、物理学、生物医学、神経科学の 4 つの分野をカバーする専門家によって書かれた 2,967 件の文献レビュー質問が含まれています。各質問には専門家によって書かれた長い回答があり、専門家が回答を完了するまでに平均して約 1 時間かかります。 SCHOLARQABENCH はまた、自動化されたメトリクスと手動評価を組み合わせた多面的な評価アプローチを採用し、モデルによって生成された回答の品質のより包括的な尺度を提供します。
実験結果は、SCHOLARQABENCH での OpenScholar のパフォーマンスが他のモデルをはるかに上回り、いくつかの側面では人間の専門家をも上回っていることを示しています。たとえば、コンピューター サイエンスの分野では、OpenScholar-8B の正答率は GPT-4o よりも 5% 高く、GPT-4o よりも 5% 高いです。 GPT-4o よりも 7% 高いです。 さらに、OpenScholar によって生成された回答の引用精度は人間の専門家のそれに匹敵しますが、GPT-4o は 78 ~ 90% もの高さで何もないところから作成されています。
OpenScholar の登場は、間違いなく科学研究の分野に大きな恩恵をもたらします。科学研究者は時間と労力を大幅に節約できるだけでなく、文献レビューの質と効率も向上します。近い将来、OpenScholar は科学研究者にとって欠かせないアシスタントになると信じています。
論文アドレス: https://arxiv.org/pdf/2411.14199
プロジェクトアドレス:https://github.com/AkariAsai/OpenScholar
全体として、OpenScholar は、その強力な機能と効率的なパフォーマンスにより、科学研究者に前例のない利便性をもたらし、科学研究の効率を大幅に向上させました。 単なるツールではなく、科学研究分野における革命でもあり、今後の発展と応用が期待されます。