プリンストン大学とイェール大学の最新の研究結果をDowncodes編集長が解説します!この研究では、大規模言語モデル (LLM) の「思考連鎖 (CoT)」推論機能を深く調査し、CoT 推論が論理ルールの単純な適用ではなく、記憶、確率、および理論などの複数の要素の複雑な融合であることを明らかにしました。ノイズ推理。研究者らはシフト暗号クラッキングタスクを選択し、GPT-4、Claude3、Llama3.1の3つのLLMの詳細な分析を実施し、最終的にCoT推論効果に影響を与える3つの重要な要素を発見し、LLMの推論メカニズムを提案しました。新しい洞察。
プリンストン大学とイェール大学の研究者らは最近、大規模言語モデル (LLM) の「思考連鎖 (CoT)」推論機能に関するレポートを発表し、CoT 推論の秘密を明らかにしました。それは、論理ルールに基づく純粋な記号推論ではなく、メモリ、確率、ノイズ推論などの複数の要素を組み合わせます。
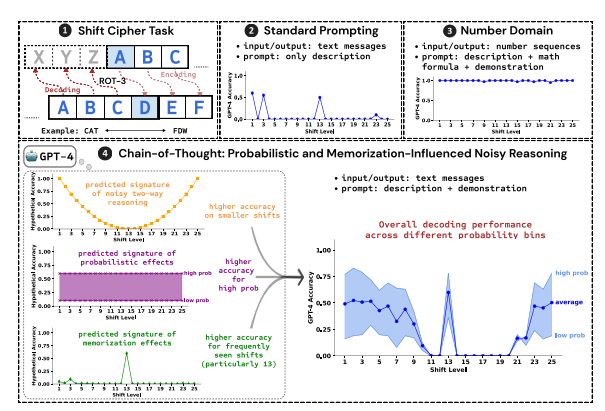
研究者らは、シフト暗号の解読をテスト タスクとして使用し、GPT-4、Claude3、Llama3.1 の 3 つの LLM のパフォーマンスを分析しました。シフト暗号は、各文字をアルファベットの固定桁数だけ前方にシフトした文字に置き換える単純なエンコードです。たとえば、アルファベットを 3 桁進めると、CAT は FDW になります。
研究結果によると、CoT 推論効果に影響を与える 3 つの主要な要素は次のとおりです。
確率的: LLM は、推論ステップによって確率が低い答えが得られる場合でも、確率が高い出力を生成することを好みます。たとえば、推論ステップが STAZ を指しているが、STAY の方が一般的な単語である場合、LLM は「自己修正」して STAY を出力する可能性があります。
メモリ: LLM は、事前トレーニング中に大量のテキスト データを記憶します。これは、CoT 推論の精度に影響します。たとえば、rot-13 は最も一般的なシフト暗号であり、rot-13 の LLM の精度は他のタイプのシフト暗号よりも大幅に高くなります。
ノイズ推論: LLM の推論プロセスは完全に正確ではありませんが、ある程度のノイズが存在します。シフト暗号のシフト量が増加すると、復号に必要な中間ステップも増加し、ノイズ推論の影響が顕著になり、LLM の精度が低下します。
研究者らはまた、LLM の CoT 推論が自己条件付けに依存していること、つまり、LLM は後続の推論ステップのコンテキストとしてテキストを明示的に生成する必要があることも発見しました。 LLM がテキストを出力せずに「静かに考える」ように指示されると、その推論能力は大幅に低下します。 さらに、デモンストレーション ステップの有効性は CoT 推論にほとんど影響を与えず、たとえデモンストレーション ステップにエラーがあったとしても、LLM の CoT 推論効果は依然として安定しています。
この研究は、LLM の CoT 推論が完全な記号推論ではなく、メモリ、確率、ノイズ推論などの複数の要素を組み込んでいることを示しています。 LLM は、CoT 推論プロセス中にメモリ マスターと確率マスターの両方の特性を示します。この研究は、LLM の推論機能をより深く理解するのに役立ち、将来的により強力な AI システムを開発するための貴重な洞察を提供します。
論文アドレス: https://arxiv.org/pdf/2407.01687
この研究レポートは、大規模言語モデルの「思考連鎖」推論メカニズムを理解するための貴重な参考資料を提供するとともに、将来の AI システムの設計と最適化に新たな方向性を提供します。 Downcodes の編集者は、今後も人工知能分野の最先端の発展に注目し、よりエキサイティングなコンテンツをお届けしていきます。