大規模なクラウド コンピューティング環境では、わずかなパフォーマンスの低下でも、リソースの膨大な浪費につながる可能性があります。 Meta は、これらの微妙なパフォーマンスの問題を効果的に検出して解決するという課題に直面しています。この目的を達成するために、Meta AI チームは FBDetect を開発しました。これは、運用環境での非常に小さなパフォーマンスの低下を 0.005% の精度で検出できるシステムです。 Downcodes の編集者が FBDetect の動作原理と驚くべき結果を詳しく紹介します。
大規模なクラウド インフラストラクチャの管理では、わずかなパフォーマンスの低下でも、大幅なリソースの浪費につながる可能性があります。たとえば、Meta のような企業では、アプリケーションの 0.05% の速度低下は重要ではないように思えるかもしれませんが、数百万台のサーバーが同時に実行されている場合、このわずかな遅延により、最大で数千台のサーバーが無駄になる可能性があります。したがって、これらの軽微なパフォーマンスの低下をタイムリーに発見して解決することは、Meta にとって大きな課題です。

この問題を解決するために、Meta AI は、0.005% という最小のパフォーマンス低下を捕捉できる実稼働環境向けのパフォーマンス低下検出システムである FBDetect を立ち上げました。 FBDetect は約 800,000 の時系列を監視でき、数百のサービスと数百万のサーバーが関与するスループット、レイテンシー、CPU およびメモリの使用状況などの複数の指標をカバーします。 FBDetect は、サーバー クラスター全体にわたるスタック トレース サンプリングなどの革新的な技術を採用することで、サブルーチン レベルの微妙なパフォーマンスの違いを捕捉できます。
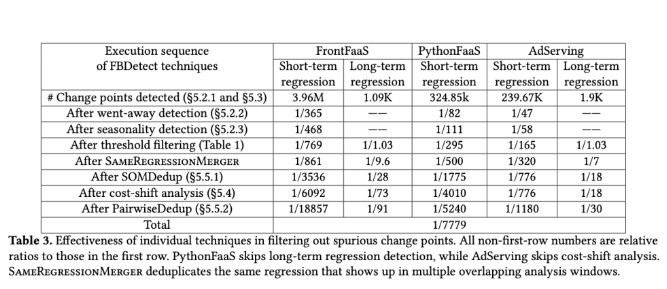
FBDetect は主にサブルーチン レベルのパフォーマンス分析に焦点を当てており、これにより検出の難易度が 0.05% のアプリケーション レベルの回帰から、より簡単に識別できる 5% のサブルーチン レベルの変化まで軽減されます。このアプローチによりノイズが大幅に軽減され、変更の追跡がより現実的になります。
FBDetect の技術的核心は 3 つの主要な側面で構成されます。まず、サブルーチン レベルでの回帰検出を通じてパフォーマンス データの分散を削減し、小さな回帰を時間内に特定できるようにします。次に、システムはサーバー クラスター全体でスタック トレース サンプリングを実行し、大規模環境でのパフォーマンス分析と同様に、各サブルーチンのパフォーマンスを正確に測定します。最後に、FBDetect は検出された回帰ごとに根本原因分析を実行して、回帰が一時的な問題、コストの変更、または実際のコードの変更によって引き起こされたものであるかどうかを判断します。
実際の運用環境での 7 年間のテストを経て、FBDetect は強力な干渉防止機能を備え、誤った回帰信号を効果的に除去できます。このシステムの導入により、開発者が調査する必要があるインシデントの数が大幅に削減されるだけでなく、メタ インフラストラクチャの効率も向上します。 FBDetect は、小さな回帰を検出することで、Meta が年間約 4,000 台のサーバーでリソースを浪費することを回避するのに役立ちます。
数百万台のサーバーを備えた Meta のような大企業では、パフォーマンス低下の検出が特に重要です。 FBDetect は、その高度な監視機能により、軽度のリグレッションの特定率を向上させるだけでなく、潜在的な問題をタイムリーに解決するための効果的な根本原因分析方法を開発者に提供し、インフラストラクチャ全体の効率的な運用を促進します。
論文の入り口: https://tangchq74.github.io/FBDetect-SOSP24.pdf
FBDetect の成功事例は、大企業に貴重な経験を提供し、将来のパフォーマンス監視システムの開発に新たな方向性をもたらします。その効率的なリソース利用と正確な回帰検出機能は、業界で参照および学習する価値があります。このような革新的なテクノロジーがさらに登場し、企業がクラウド インフラストラクチャをより適切に管理および最適化できるようになることが期待されます。