Downcodes の編集者は、中国の研究チームが最大の公開マルチモーダル AI データセット「Infinity-MM」の作成に成功し、このデータセットに基づいて優れたパフォーマンスを備えた小型モデル Aquila-VL-2B のトレーニングに成功したことを知りました。このモデルは複数のベンチマーク テストで優れた結果を達成し、AI モデルのパフォーマンス向上における合成データの大きな可能性を実証しました。 Infinity-MM データセットには、画像の説明や視覚的な指示データなどのさまざまな種類のデータが含まれており、その生成プロセスでは RAM++ や MiniCPM-V などのオープンソース AI モデルが利用され、データの品質と多様性を確保するためにマルチレベルの処理が行われます。 Aquila-VL-2B モデルは、LLaVA-OneVision アーキテクチャに基づいており、言語モデルとして Qwen-2.5 を使用します。
最近、中国の複数の機関の研究チームが、現在最大の公開マルチモーダル AI データセットの 1 つである「Infinity-MM」データセットの作成に成功し、優れたパフォーマンスを備えた小型の新しいモデル - Aquila-VL-2B をトレーニングしました。 。
データセットには主に 4 つの主要カテゴリのデータが含まれています。1,000 万件の画像説明、2,440 万件の一般的な視覚的指示データ、600 万件の厳選された高品質の指示データ、GPT-4 およびその他の AI モデルによって生成された 300 万件のデータです。
生成面では、研究チームは既存のオープンソース AI モデルを活用しました。まず、RAM++ モデルが画像を分析して重要な情報を抽出し、その後、関連する質問と回答を生成します。さらに、チームは生成されたデータの品質と多様性を確保するために特別な分類システムを構築しました。
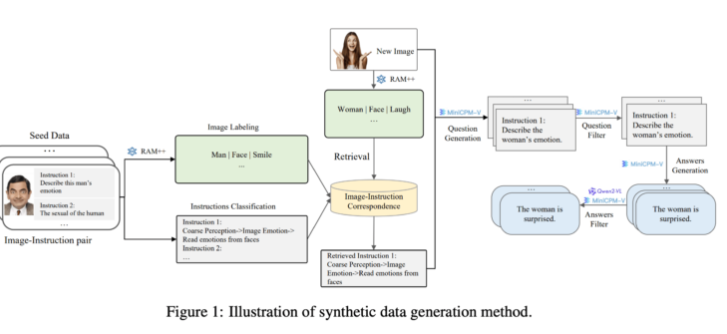
この合成データ生成方法では、マルチレベル処理方法を使用し、RAM++ モデルと MiniCPM-V モデルを組み合わせて、画像認識、命令分類、応答生成を通じて AI システムに正確なトレーニング データを提供します。
Aquila-VL-2B モデルは、LLaVA-OneVision アーキテクチャに基づいており、言語モデルとして Qwen-2.5 を使用し、画像処理に SigLIP を使用します。モデルのトレーニングは 4 つの段階に分かれており、徐々に複雑さが増していきます。最初の段階では、モデルは基本的な画像とテキストの関連付けを学習します。その後の段階では、一般的な視覚タスク、特定の命令の実行、そして最後に合成された生成データの統合が含まれます。画像解像度もトレーニング中に徐々に向上します。
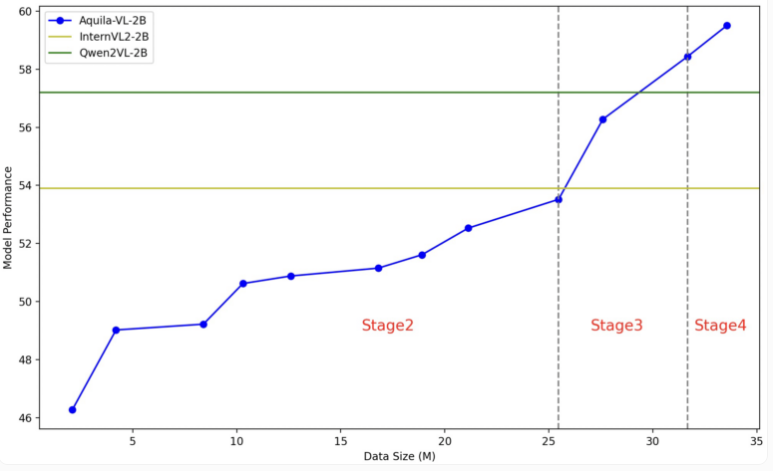
このテストでは、Aquila-VL-2B が、わずか 20 億個のパラメーターで、マルチモーダル MMStar ベースのテストで 54.9% のスコアを獲得し、最高の結果を達成しました。さらに、このモデルは数学的タスクで特に優れたパフォーマンスを示し、MathVista テストで 59% のスコアを獲得し、同様のシステムをはるかに上回りました。
一般的な画像理解テストでも、Aquila-VL-2B は HallusionBench スコア 43%、MMBench スコア 75.2% と良好なパフォーマンスを示しました。研究者らは、合成的に生成されたデータの追加によりモデルのパフォーマンスが大幅に向上し、この追加データを使用しなければモデルの平均パフォーマンスは 2.4% 低下したであろうと述べています。
今回、研究チームはデータセットとモデルを研究コミュニティに公開することを決定し、トレーニングプロセスでは主にNvidia A100GPUと中国のローカルチップを使用しました。 Aquila-VL-2B の立ち上げの成功は、オープンソース モデルが AI 研究における従来のクローズド ソース システムの傾向に徐々に追いつきつつあることを示しており、特に合成トレーニング データの利用において良好な見通しが示されています。
Infinity-MM 論文入口: https://arxiv.org/abs/2410.18558
Aquila-VL-2B プロジェクトの入り口: https://huggingface.co/BAAI/Aquila-VL-2B-llava-qwen
Aquila-VL-2B の成功は、AI 分野における中国の技術力を証明するだけでなく、オープンソース コミュニティに貴重なリソースを提供します。その効率的なパフォーマンスとオープンな戦略により、マルチモーダル AI テクノロジーの開発が促進され、将来的にはより多くの分野での応用が期待されます。