最近、AI ラージ言語モデル (LLM) アプリケーションの人気により、ハードウェア分野での競争が激化しています。 AMD は最新の Strix Point APU シリーズを発売しました。その Ryzen AI プロセッサは、Intel の Lunar Lake シリーズをはるかに上回るパフォーマンスで、LLM タスクの処理に大きな利点を示しています。 Downcodes のエディターを使用すると、Strix Point APU シリーズのパフォーマンスとその背後にある技術革新を深く理解できます。
最近、AMD は最新の Strix Point APU シリーズをリリースし、AI 大規模言語モデル (LLM) アプリケーションにおけるこのシリーズの優れたパフォーマンスが強調され、Intel の Lunar Lake シリーズ プロセッサをはるかに上回りました。 AI ワークロードの需要が高まるにつれ、ハードウェアの競争はますます激化しています。市場に応えて、AMD は、より高いパフォーマンスとより低い遅延を目指して、モバイル プラットフォーム向けに設計された AI プロセッサを発売しました。
AMDは、ix PointシリーズのRyzen AI300プロセッサは、AI LLMタスクを処理する際に1秒あたりに処理されるトークンの数を大幅に増やすことができ、IntelのCore Ultra258Vと比較して、Ryzen AI9375のパフォーマンスが27%向上したと述べた。 Core Ultra7V は L Lake シリーズの中で最速のモデルではありませんが、そのコアとスレッド数はハイエンドの Lunar Lake プロセッサに近く、この分野での AMD 製品の競争力を示しています。
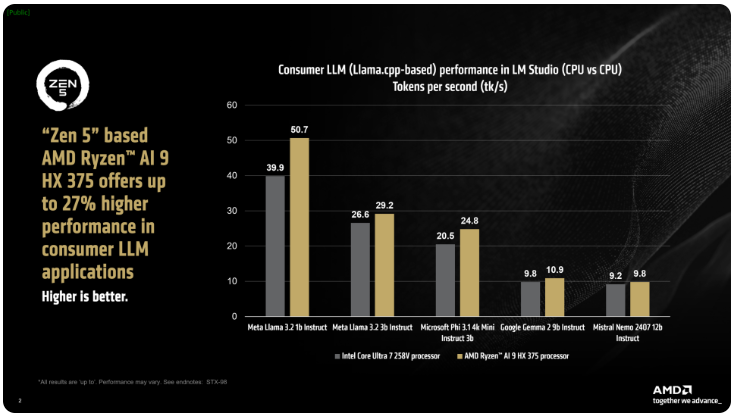
AMD の LM Studio ツールは、llama.cpp フレームワークに基づく消費者向けアプリケーションであり、大規模な言語モデルの使用を簡素化するように設計されています。このフレームワークは x86 CPU のパフォーマンスを最適化します。LLM の実行に GPU は必要ありませんが、GPU を使用すると処理をさらに高速化できます。テストによると、Ryzen AI9HX375 は Meta Llama3.21b 命令モデルで 35 分の 1 低いレイテンシーを達成でき、1 秒あたり 50.7 トークンを処理できます。これに対し、Core Ultra7258V はわずか 39.9 トークンです。
それだけでなく、Strix Point APU には、RDNA3.5 アーキテクチャに基づく強力な Radeon 統合グラフィックス カードも装備されており、ulkan API を通じてタスクを iGPU にオフロードして、LLM のパフォーマンスをさらに向上させることができます。 Ryzen AI300 プロセッサーは、可変グラフィックス メモリー (VGM) テクノロジーを使用して、メモリー割り当てを最適化し、エネルギー効率を向上させ、最終的に最大 60% のパフォーマンス向上を達成します。
比較テストでは、AMD は Intel AI Playground プラットフォームで同じ設定を使用し、Ryzen AI9HX375 が Microsoft Phi3.1 では Core Ultra7258V よりも 87% 高速であり、Mistral7b Instruct0.3 モデルでは 13% 高速であることがわかりました。それでも、Lunar Lake シリーズの主力製品である Core Ultra9288V と比較すると、結果はさらに興味深いものになります。現在、AMD は、より多くの非技術ユーザーが簡単に使い始められるようにすることを目的として、LM Studio を通じて大規模な言語モデルの使用をより一般的にすることに重点を置いています。
AMD Strix Point APU シリーズの発売は、AI プロセッサー分野における競争のさらなる激化を示すものであり、将来の AI アプリケーションがより強力なハードウェア サポートを持つことを示しています。パフォーマンスとエネルギー効率の向上により、ユーザーはよりスムーズで強力な AI エクスペリエンスを実現します。 Downcodes の編集者は、今後もこの分野の最新動向に注目し、読者にさらに刺激的なレポートをお届けしていきます。