マルチモーダル大規模言語モデル (MLLM) にとって、超長時間ビデオの理解は常に困難な問題であり、既存のモデルではコンテキストの最大長を超えるビデオ データを処理することが難しく、情報の減衰と高い計算コストも大きな課題となっています。 Downcodes の編集者は、Zhiyuan Research Institute といくつかの大学が、1 時間レベルのビデオ理解の問題を効率的に処理するように設計された Video-XL と呼ばれる超長時間の視覚言語モデルを提案していることを知りました。このモデルの中核となるテクノロジーは「視覚コンテキスト潜在要約」です。これは、LLM のコンテキスト モデリング機能を巧みに利用して、牛 1 頭を丸ごとビーフ エッセンスのボウルに凝縮するのと同じように、長い視覚表現をよりコンパクトな形式に圧縮して、モデルを作成します。重要な情報をより効率的に吸収します。
現在、マルチモーダル大規模言語モデル (MLLM) はビデオ理解の分野で大きな進歩を遂げていますが、非常に長いビデオを処理することは依然として課題です。 これは、MLLM が通常、最大コンテキスト長を超える数千のビジュアル トークンを処理するのに苦労し、トークンの集約によって引き起こされる情報の減衰が発生するためです。 同時に、多数のビデオタグも高い計算コストをもたらします。
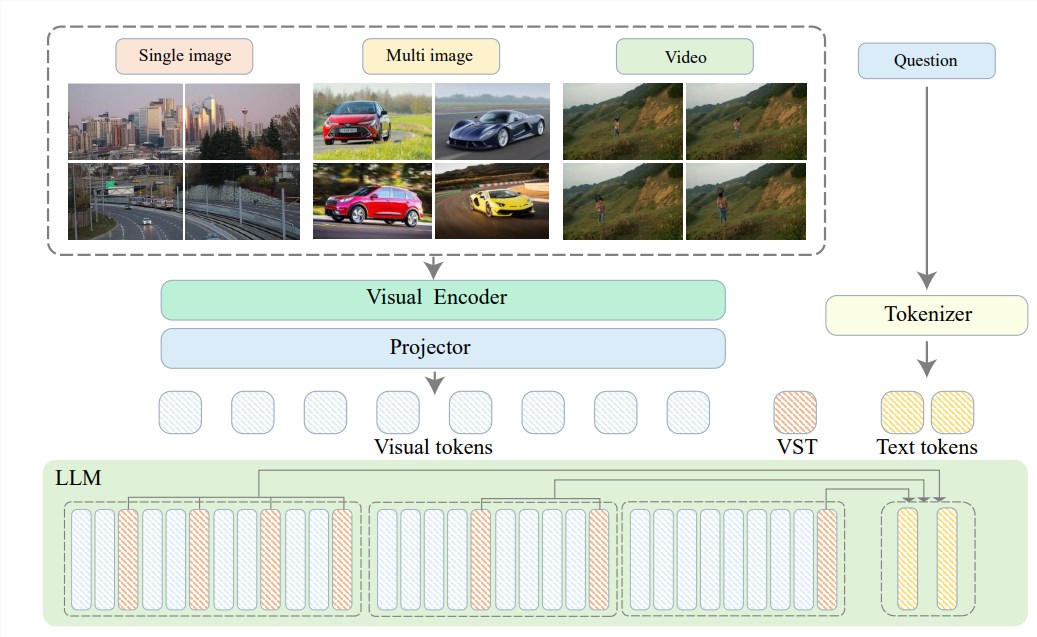
これらの問題を解決するために、知源研究所は上海交通大学、中国人民大学、北京大学、北京郵電大学などの大学と協力して、超高解像度システムであるVideo-XLを提案しました。長時間にわたるビデオ言語モデルを効率的に理解します。 Video-XL の中核は「視覚コンテキスト潜在要約」テクノロジーにあり、LLM の固有のコンテキスト モデリング機能を活用して、長い視覚表現をよりコンパクトな形式に効果的に圧縮します。
簡単に言うと、牛一頭をボウルのビーフエッセンスに凝縮するのと同じように、ビデオ コンテンツをより合理化された形式に圧縮することで、モデルが消化、吸収しやすくなります。
この圧縮技術は効率を向上させるだけでなく、ビデオの重要な情報を効果的に保存します。ご存知のように、長いビデオには多くの冗長な情報が詰め込まれていることがよくあります。たとえば、長くて臭いおばあさんの足布のようなものです。 Video-XL は、この無駄な情報を正確に削除し、重要な部分のみを保持することができるため、長いビデオ コンテンツを理解する際にモデルが道に迷うことがなくなります。
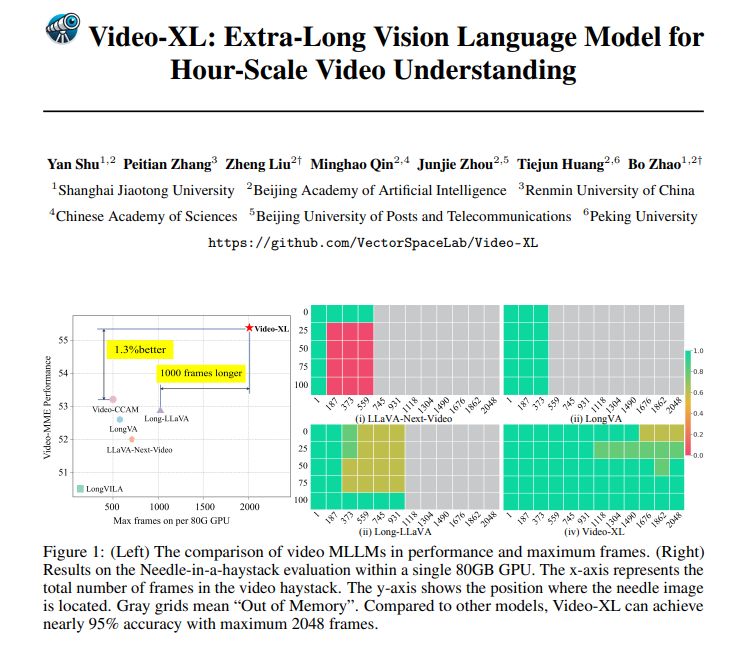
Video-XL は理論的に優れているだけでなく、実際にも非常に有能です。 Video-XL は、複数の長時間ビデオ理解ベンチマーク、特に VNBench テストで優れた結果を達成しており、その精度は既存の最良の方法よりも 10% 近く高くなります。
さらに驚くべきことに、Video-XL は効率と有効性の間で驚くべきバランスを実現しており、「干し草の山の中の針」評価で 95% 近くの精度を維持しながら、単一の 80GB GPU で 2048 フレームのビデオを処理できます。
Video-XL には幅広い用途の可能性もあります。一般的な長いビデオを理解できることに加えて、映画の要約、監視の異常検出、広告配置の認識などの特定のタスクも実行できます。
これは、今後、映画を視聴するときに長いプロットに耐える必要がなくなることを意味します。Video-XL を直接使用して効率的な概要を生成し、時間と労力を節約したり、監視映像を監視して異常なイベントを自動的に特定したりすることができます。これは手動追跡よりもはるかに効率的です。
プロジェクトアドレス: https://github.com/VectorSpaceLab/Video-XL
論文: https://arxiv.org/pdf/2409.14485
Video-XL は、超長時間ビデオの理解の分野で画期的な進歩を遂げ、効率と精度の完璧な組み合わせにより、将来の幅広いアプリケーションの可能性を秘めており、期待に値します。