大規模なモデルのトレーニングには時間と労力がかかり、いかに効率を高めてエネルギー消費を削減するかが AI 分野の重要な課題となっています。 Transformer の事前トレーニングのデフォルトのオプティマイザーである AdamW は、ますます大規模になるモデルに徐々に対応できなくなります。 Downcodes のエディターでは、中国のチーム C-AdamW が開発した新しいオプティマイザーについて学習します。その「慎重な」戦略により、トレーニングの速度と安定性を確保しながらエネルギー消費を大幅に削減し、大規模なモデルのトレーニングに大きなメリットをもたらします。変革を起こすために。
AIの世界では、奇跡を起こすために一生懸命働くことが鉄則のようです。モデルが大きければ大きいほど、より多くのデータが得られ、より強力なコンピューティング能力が得られ、インテリジェンスの聖杯に近づくように見えます。しかし、この急速な発展の裏には、コストとエネルギー消費に対する大きな圧力もあります。
AI トレーニングをより効率的にするために、科学者は、モデルのパラメーターを継続的に最適化し、最終的に最良の状態に到達するように導くコーチのような、より強力なオプティマイザーを探してきました。 AdamW は、Transformer の事前トレーニングのデフォルトのオプティマイザーとして、長年にわたり業界のベンチマークであり続けています。しかし、モデルのスケールがますます大きくなるにつれ、AdamW もその機能に対応できなくなってきたように見え始めました。
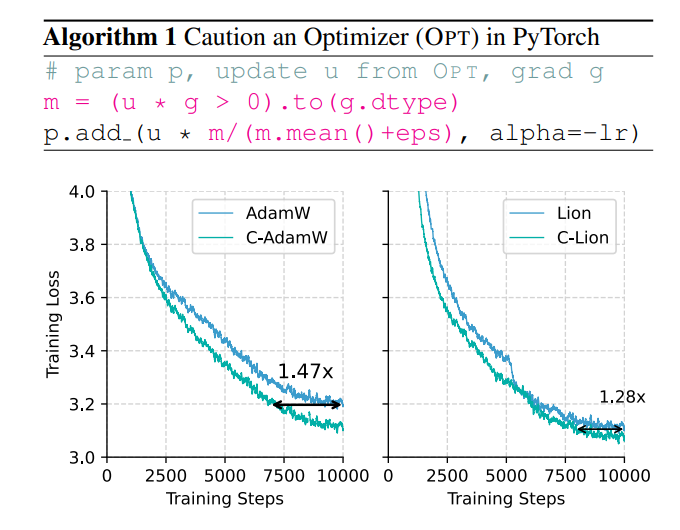
エネルギー消費を抑えながらトレーニング速度を上げる方法はないでしょうか? 心配しないでください。全員が中国人のチームが秘密兵器 C-AdamW を持ってやって来ました!
C-AdamW のフルネームは Cautious AdamW、中国語名は Cautious AdamW です。とても仏教っぽく聞こえませんか? はい、C-AdamW の中心的な考え方は、行動する前によく考えることです。

モデルのパラメーターが、いつも走り回りたがる元気な子供のグループに似ていると想像してください。 AdamW は熱心な教師のような存在で、生徒たちを正しい方向に導こうと努めています。しかし、子供たちは興奮しすぎて間違った方向に走り、時間とエネルギーを無駄にしてしまうことがあります。
このとき、C-AdamW は鋭い目を持つ賢い長老のようなもので、更新の方向が正しいかどうかを正確に識別できます。方向が間違っている場合、C-AdamW はモデルがさらに間違った道を進むのを防ぐために断固として停止を要求します。
この慎重な戦略により、更新ごとに損失関数が効果的に削減され、モデルの収束が高速化されます。実験結果は、C-AdamW が Llama と MAE の事前トレーニングでトレーニング速度を 1.47 倍に向上させることを示しています。
さらに重要なのは、C-AdamW は追加の計算オーバーヘッドをほとんど必要とせず、既存のコードを 1 行変更するだけで実装できることです。つまり、開発者は C-AdamW をさまざまなモデル トレーニングに簡単に適用でき、そのスピードと情熱を楽しむことができます。
C-AdamW の優れた点は、Adam のハミルトニアン関数を保持し、Lyapunov 解析の下での収束保証を破壊しないことです。これは、C-AdamW が高速であるだけでなく、その安定性も保証されており、トレーニングのクラッシュなどの問題が発生しないことを意味します。
もちろん、仏教徒だからといって進取的でないというわけではありません。研究チームは、C-AdamWのパフォーマンスをさらに向上させるために、より豊富なϕ関数を探索し、パラメータ空間ではなく特徴空間にマスクを適用し続けると述べた。
C-AdamW が深層学習の分野で新たな人気者となり、大規模モデルのトレーニングに革命的な変化をもたらすことは予見できます。
論文アドレス: https://arxiv.org/abs/2411.16085
GitHub:
https://github.com/kyleliang919/C-Optim
C-AdamW の登場は、大規模モデルのトレーニング効率とエネルギー消費の問題を解決するための新しいアイデアを提供します。その高い効率性、安定性、使いやすさにより、アプリケーションとして非常に有望です。 C-AdamWは今後さらに多くの分野で応用可能となり、AI技術の継続的な発展を促進することが期待されます。 Downcodes の編集者は、今後も関連する技術の進歩に注目していきますので、ご期待ください。