AI テクノロジーの急速な発展に伴い、視覚言語モデルの需要は日に日に高まっていますが、その高いコンピューティング リソース要件により、通常のデバイスでの適用は制限されています。 Downcodes の編集者は、本日、SmolVLM と呼ばれる軽量のビジュアル言語モデルを紹介します。これは、ラップトップやコンシューマ グレードの GPU など、リソースが限られたデバイス上で効率的に実行できます。 SmolVLM の登場により、より多くのユーザーが高度な AI テクノロジーを体験する機会が得られ、使用の敷居が下がり、開発者にとってはより便利な研究ツールが提供されました。
近年、視覚や言語のタスクに機械学習モデルを適用する需要が高まっていますが、ほとんどのモデルは膨大なコンピューティング リソースを必要とし、個人のデバイスでは効率的に実行できません。特にラップトップ、コンシューマ GPU、モバイル デバイスなどの小型デバイスは、ビジュアル言語タスクを処理する際に大きな課題に直面しています。
Qwen2-VL を例に挙げると、優れたパフォーマンスを備えていますが、ハードウェア要件が高く、リアルタイム アプリケーションでの使いやすさが制限されています。したがって、より少ないリソースで実行できる軽量モデルを開発することが重要なニーズになっています。
Hugging Face は最近、デバイス側推論用に特別に設計された 2B パラメーター視覚言語モデルである SmolVLM をリリースしました。 SmolVLM は、GPU メモリ使用量とトークン生成速度の点で他の同様のモデルよりも優れています。その主な特徴は、ラップトップやコンシューマーグレードの GPU などの小型デバイス上で、パフォーマンスを犠牲にすることなく効率的に実行できることです。 SmolVLM は、パフォーマンスと効率の間の理想的なバランスを見つけ、以前の同様のモデルでは克服することが困難であった問題を解決します。
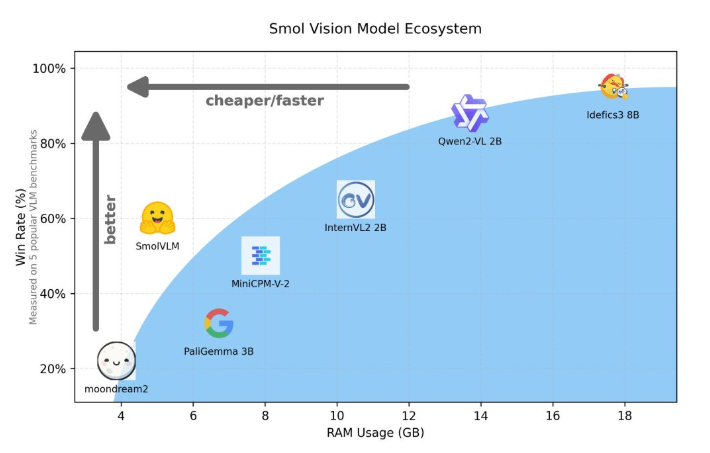
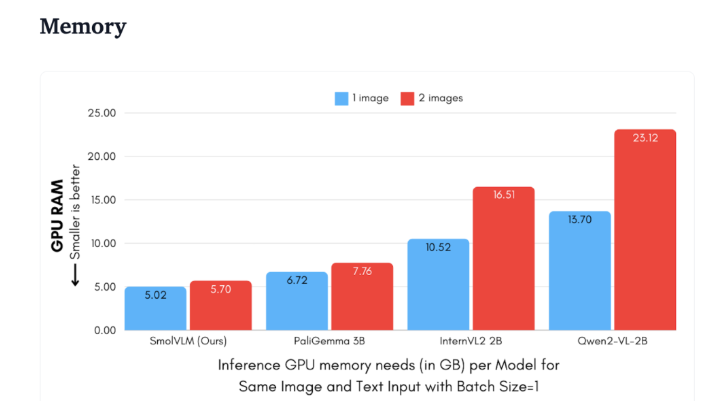
Qwen2-VL2B と比較して、SmolVLM は最適化されたアーキテクチャのおかげで 7.5 ~ 16 倍高速にトークンを生成し、軽量な推論が可能になります。この効率性はエンド ユーザーに実際的なメリットをもたらすだけでなく、ユーザー エクスペリエンスも大幅に向上します。
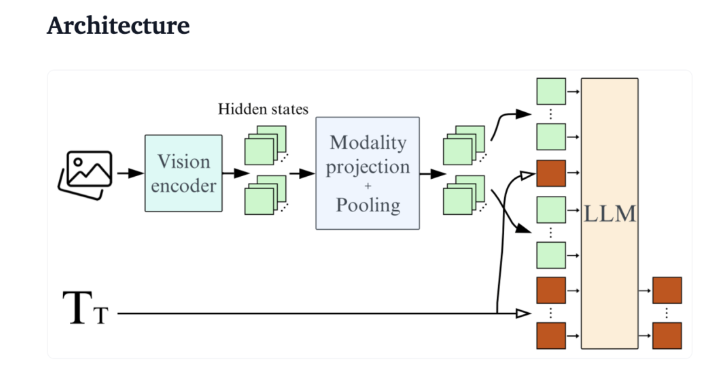
技術的な観点から見ると、SmolVLM は効率的なデバイス側推論をサポートする最適化されたアーキテクチャを備えています。ユーザーは Google Colab 上で簡単に微調整を行うこともできるため、実験や開発の敷居が大幅に下がります。
SmolVLM はメモリ フットプリントが小さいため、以前は同様のモデルをホストできなかったデバイスでもスムーズに実行できます。 50 フレームの YouTube ビデオをテストした場合、SmolVLM は 27.14% のスコアを獲得して良好なパフォーマンスを示し、リソース消費量の点でより多くのリソースを消費する 2 つのモデルを上回り、その強力な適応性と柔軟性を示しました。
SmolVLM は、視覚言語モデルの分野における重要なマイルストーンです。このリリースにより、複雑なビジュアル言語タスクを日常のデバイスで実行できるようになり、現在の AI ツールの重要なギャップが埋められます。
SmolVLM は速度と効率に優れているだけでなく、開発者や研究者に、高価なハードウェア費用をかけずに視覚言語処理を促進する強力なツールを提供します。 AI テクノロジーの人気が高まるにつれ、SmolVLM のようなモデルにより、強力な機械学習機能がより利用しやすくなります。
デモ:https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
全体として、SmolVLM は軽量ビジュアル言語モデルの新しいベンチマークを設定し、その効率的なパフォーマンスと便利な使用により、AI テクノロジーの普及と開発が大きく促進されます。 私たちは、将来的に同様のイノベーションがさらに増え、AI テクノロジーがより多くの人々に恩恵をもたらすことを期待しています。