近年、大規模な言語モデルの学習コストは高止まりしており、AIの開発を制限する重要な要因となっています。トレーニングのコストを削減し、効率を向上させる方法が業界の焦点になっています。 Downcodes の編集者は、ハーバード大学とスタンフォード大学の研究者による最新の論文の解釈を提供します。この論文では、場合によってはモデルのトレーニング精度を調整することでトレーニング コストを効果的に削減する「精度を意識した」スケーリング ルールが提案されています。場合によっては、モデルのパフォーマンスも向上する可能性があります。この興味深い研究を詳しく見てみましょう。
人工知能の分野では、規模が大きいほど能力も向上するようです。より強力な言語モデルを追求するため、大手テクノロジー企業はモデル パラメーターとトレーニング データを必死に積み上げていますが、コストも上昇していることに気づきました。言語モデルをトレーニングするための費用対効果が高く効率的な方法はないでしょうか?
ハーバード大学とスタンフォード大学の研究者らは最近、モデルトレーニングの精度が言語モデルトレーニングの「コストコード」を解くことができる隠し鍵のようなものであることを発見した論文を発表した。
モデル精度とは簡単に言うと、計算プロセスで使用されるモデルのパラメーターと桁数を指します。従来の深層学習モデルは通常、学習に 32 ビット浮動小数点数 (FP32) を使用しますが、近年、ハードウェアの発展に伴い、16 ビット浮動小数点数 (FP16) や 8 ビット浮動小数点数 (FP16) など、より精度の低い数値型が使用されます。ビット整数 (INT8) トレーニングはすでに可能です。
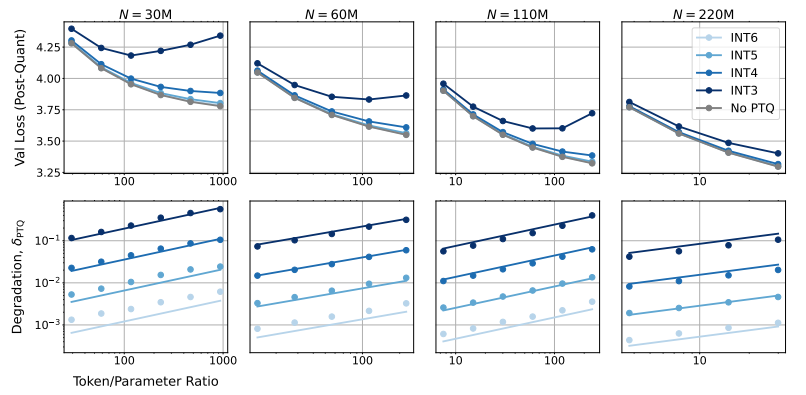
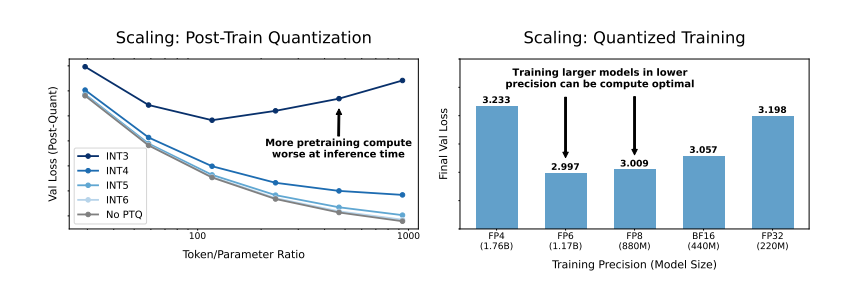
では、モデルの精度を下げるとモデルのパフォーマンスにどのような影響があるのでしょうか? これがまさにこの論文が探求したい問題です。研究者らは、多数の実験を通じて、さまざまな精度の下でのモデルのトレーニングと推論のコストとパフォーマンスの変化を分析し、「精度を意識した」スケーリング ルールの新しいセットを提案しました。
彼らは、精度を低くしてトレーニングすると、モデルの「有効パラメータ数」が効果的に減少し、それによってトレーニングに必要な計算量が削減されることを発見しました。これは、同じ計算予算でより大規模なモデルをトレーニングできること、または同じスケールでより低い精度を使用して多くの計算リソースを節約できることを意味します。
さらに驚くべきことに、研究者らは、場合によっては、より低い精度でトレーニングすると実際にモデルのパフォーマンスが向上することも発見しました。たとえば、「トレーニング後の量子化」が必要な場合、モデルがトレーニング段階でより低い精度を使用する場合、モデルは量子化後の精度の低下に対してより堅牢になるため、推論段階でより優れたパフォーマンスを示します。
では、モデルをトレーニングするにはどの精度を選択すべきでしょうか? 研究者らは、スケーリング ルールを分析することで、いくつかの興味深い結論に達しました。
従来の 16 ビット精度のトレーニングは最適ではない可能性があります。 彼らの調査では、7 ~ 8 桁の精度がよりコスト効率の高いオプションである可能性があることが示唆されています。
また、超低精度 (4 桁など) のトレーニングを盲目的に追求することも賢明ではありません。 精度が非常に低い場合、モデルの有効パラメータの数が急激に減少するため、パフォーマンスを維持するにはモデルのサイズを大幅に増やす必要があり、その結果、計算コストが増加します。
最適なトレーニング精度は、モデルのサイズが異なると異なる場合があります。 Llama-3 や Gemma-2 シリーズなど、多くの「オーバートレーニング」を必要とするモデルの場合、より高い精度でトレーニングする方がコスト効率が高い場合があります。
この研究は、言語モデルのトレーニングの理解と最適化について新しい視点を提供します。これは、精度の選択は静的ではなく、特定のモデル サイズ、トレーニング データ量、アプリケーション シナリオに基づいて検討する必要があることを示しています。
もちろん、この研究にはいくつかの制限があります。たとえば、彼らが使用したモデルは比較的小規模であり、実験結果はより大規模なモデルに直接一般化できない可能性があります。さらに、彼らはモデルの損失関数のみに焦点を当てており、下流タスクでのモデルのパフォーマンスは評価していませんでした。
それにもかかわらず、この研究は依然として重要な意味を持っています。これにより、モデルの精度、モデルのパフォーマンス、トレーニング コストの間の複雑な関係が明らかになり、将来的により強力で経済的な言語モデルを設計およびトレーニングするための貴重な洞察が得られます。
論文: https://arxiv.org/pdf/2411.04330
全体として、この研究は大規模な言語モデルのトレーニングのコストを削減するための新しいアイデアと方法を提供し、将来の AI 開発に重要な参考値を提供します。 Downcodes の編集者は、モデルの精度研究のさらなる進歩を期待しており、よりコスト効率の高い AI モデルの構築に貢献します。