AI とリアルタイムで対話することは、人工知能の分野、特にマルチモーダルな情報を統合し、会話の流暢性を維持する上で大きな課題です。既存の AI システムの多くは、リアルタイムの会話の流暢さ、文脈の理解、マルチモーダルの理解に依然として欠陥があり、実際の応用が制限されています。 Downcodes の編集者は、これらの問題を解決するために設計されたオープンソースのマルチモーダル モデル シリーズである Fixie AI によって発売された Ultravox v0.4.1 を紹介します。
人工知能の応用において、AI とのリアルタイム対話をどのように実現するかは、開発者や研究者が常に直面する大きな課題でした。中でも、マルチモーダル情報 (テキスト、画像、音声など) を統合して一貫した対話システムを形成することは、特に複雑です。

GPT-4 のような高度な大規模言語モデルではある程度の進歩が見られますが、多くの AI システムはリアルタイムの会話の流暢さ、コンテキスト認識、マルチモーダル理解を達成することが依然として困難であり、実際のアプリケーションでの有効性が制限されています。さらに、これらのモデルの計算要件により、広範なインフラストラクチャのサポートがなければ、リアルタイムの展開が非常に困難になります。
これらの問題を解決するために、Fixie AI は、AI とのリアルタイム対話を可能にするように設計された一連のマルチモーダル オープン ソース モデルである Ultravox v0.4.1 を立ち上げました。
Ultravox v0.4.1 は、複数の入力形式 (テキスト、画像など) を処理する機能を備えており、GPT-4 などのクローズド ソース モデルの代替を提供することを目的としています。このエディションでは、言語の熟練度だけでなく、さまざまなメディア タイプ間での流暢でコンテキストを意識した会話を可能にすることにも焦点を当てています。
オープンソース プロジェクトとして、Fixie AI は Ultravox を使用して、世界中の開発者や研究者がカスタマー サポートからエンターテイメントまでさまざまなアプリケーションに適した最先端の会話テクノロジーに平等にアクセスできるようにしたいと考えています。
Ultravox v0.4.1 モデルは、最適化されたトランスフォーマー アーキテクチャに基づいており、複数の種類のデータを並行して処理できます。クロスモーダル アテンションと呼ばれる手法を使用することで、これらのモデルは、さまざまなソースからの情報を同時に統合して解釈できます。
これは、ユーザーが AI に画像を表示し、関連する質問をし、情報に基づいた回答をリアルタイムで得ることができることを意味します。 Fixie AI は、開発者が簡単にアクセスして実験できるように、Hugging Face でこれらのオープン ソース モデルをホストし、実際のアプリケーションでのシームレスな統合を促進する詳細な API ドキュメントを提供します。
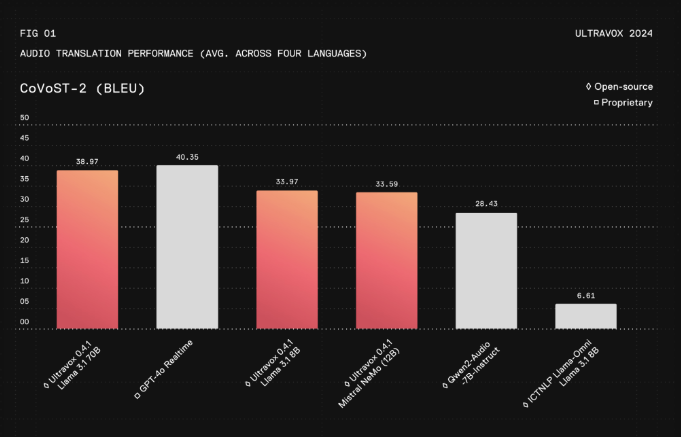
最近の評価データに基づくと、Ultravox v0.4.1 は、同等の精度とコンテキストの理解を維持しながら、応答遅延の大幅な短縮を実現し、主要な商用モデルよりも約 30% 高速です。このモデルのクロスモーダル機能により、画像とテキストを組み合わせて医療分野で包括的な分析を行ったり、教育分野で豊富なインタラクティブ コンテンツを提供したりするなど、複雑なユースケースに優れています。
Ultravox のオープン性により、コミュニティ主導の開発が可能になり、柔軟性が強化され、透明性が促進されます。 Ultravox は、このモデルの導入に必要な計算負荷を軽減することで、特に中小企業や独立系開発者にとって、高度な会話型 AI をより利用しやすくし、リソースの制約によって以前に作られていた障壁を打ち破ります。
プロジェクトページ:https://www.ultravox.ai/blog/ultravox-an-open-weight-alternative-to-gpt-4o-realtime
モデル: https://huggingface.co/fixie-ai
全体として、Ultravox v0.4.1 は、開発者に強力で簡単にアクセスできるリアルタイム マルチモーダル対話 AI モデルを提供し、そのオープンソースの性質と効率的なパフォーマンスにより、人工知能分野の発展が促進されることが期待されています。 詳細については、プロジェクト ページと Hugging Face をご覧ください。