Downcodes の編集者は、非営利の AI 研究機関である Ai2 が最近、その「Open Language Model」(OLMo) シリーズの第 2 世代である新しい OLMo2 シリーズの言語モデルをリリースしたことを知りました。 OLMo2 は完全なオープンソース コードの概念を遵守しており、そのトレーニング データ、ツール、コードは完全にオープンです。これは今日の AI 分野において特に重要であり、オープンソース AI の開発における新たな高みを表しています。 「オープン」であると主張する他のモデルとは異なり、OLMo2 はオープンソース イニシアチブの定義に厳密に従い、オープンソース AI の厳格な基準を満たし、AI コミュニティに強力な技術サポートと貴重な学習リソースを提供します。
非営利の AI 研究団体である Ai2 はこのほど、同団体が立ち上げた「Open Language Model」(OLMo) シリーズの第 2 世代モデルである新しい OLMo2 シリーズをリリースしました。 OLMo2 のリリースは、AI コミュニティに強力な技術サポートを提供するだけでなく、完全にオープン ソース コードによるオープン ソース AI の最新の開発を表します。
Meta の Llama シリーズなど、現在市場に出ている他の「オープン」言語モデルとは異なり、OLMo2 はオープンソース イニシアチブの厳密な定義を満たしています。つまり、開発に使用されるトレーニング データ、ツール、コードは公開されており、誰でもアクセスできます。使用。 Open Source Initiative の定義に従って、OLMo2 は、今年 10 月に完成した「オープンソース AI」標準に対する組織の要件を満たしています。
Ai2 はブログで、共有リソースを通じてオープンソース コミュニティでのイノベーションと発見を促進することを目的として、OLMo2 の開発プロセス中、すべてのトレーニング データ、コード、トレーニング プラン、評価方法、中間チェックポイントが完全にオープンだったと述べました。 Ai2 は、「データ、ソリューション、調査結果をオープンに共有することで、新しい手法や革新的なテクノロジーを発見するためのリソースをオープンソース コミュニティに提供したいと考えています。」と述べています。
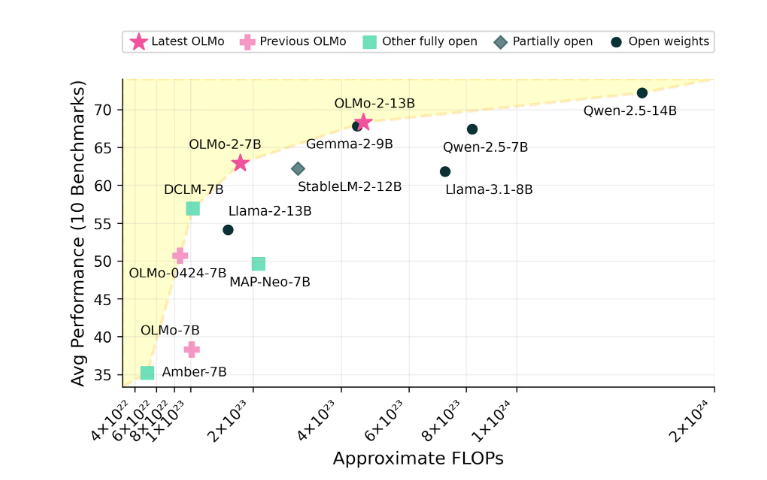
OLMo2 シリーズには 2 つのバージョンがあり、1 つは 70 億のパラメータを備えた OLMo7B で、もう 1 つは 130 億のパラメータを備えた OLMo13B です。パラメーターの数はモデルのパフォーマンスに直接影響し、パラメーターが多いバージョンでは通常、より複雑なタスクを処理できます。 OLMo2 は一般的なテキスト タスクで優れたパフォーマンスを発揮し、質問への回答、文書の要約、コードの作成などのタスクを完了できました。

画像出典注:画像はAIによって生成され、画像はサービスプロバイダーMidjourneyによって許可されています
OLMo2 をトレーニングするために、Ai2 は 5 兆個のトークンを含むデータセットを使用しました。トークンは言語モデルの最小単位であり、100 万トークンは約 750,000 単語に相当します。トレーニング データには、高品質の Web サイト、学術論文、Q&A ディスカッション掲示板、合成数学のワークブックからのコンテンツが含まれており、モデルの効率と精度を確保するために慎重に選択されています。
Ai2 は OLMo2 のパフォーマンスに自信を持っており、Meta の Llama3.1 などのオープンソース モデルとパフォーマンスで競合していると主張しています。 Ai2 は、OLMo27B のパフォーマンスは Llama3.18B をも上回り、現在最も強力な完全オープン言語モデルの 1 つになったと指摘しました。すべての OLMo2 モデルとそのコンポーネントは、Ai2 公式 Web サイトから無料でダウンロードでき、Apache2.0 ライセンスに従っています。つまり、これらのモデルは研究だけでなく商用アプリケーションにも使用できます。
OLMo2 のオープンソースの性質により、AI 分野におけるオープンな協力とイノベーションが大幅に促進され、研究者や開発者に幅広い開発スペースが提供されます。 OLMo2 が今後さらなるブレークスルーとアプリケーションをもたらすことを楽しみにしています。